您现在的位置是:首页 >技术教程 >《Keras 3 :使用 Global Context Vision Transformer 进行图像分类》网站首页技术教程
《Keras 3 :使用 Global Context Vision Transformer 进行图像分类》
《Keras 3 :使用 Global Context Vision Transformer 进行图像分类》
作者:Md Awsafur Rahman
创建日期:2023 年 10 月 30
日最后修改时间:2023 年 10 月 30
日 描述:用于图像分类的 Global Context Vision Transformer 的实施和微调。
设置
!pip install --upgrade keras_cv tensorflow
!pip install --upgrade keras
import keras
from keras_cv.layers import DropPath
from keras import ops
from keras import layers
import tensorflow as tf # only for dataloader
import tensorflow_datasets as tfds # for flower dataset
from skimage.data import chelsea
import matplotlib.pyplot as plt
import numpy as np
介绍
在本笔记本中,我们将利用多后端 Keras 3.0 来实现 GCViT:Global Context Vision Transformer 论文 由 A Hatamizadeh 等人在 ICML 2023 上发表。的 Git 中,我们将在 用于图像分类任务的 Flower 数据集,利用官方预训练的 ImageNet 权重。这款笔记本的一大亮点是它与多个后端的兼容性: TensorFlow、PyTorch 和 JAX,展示了多后端 Keras 的真正潜力。
赋予动机
注意:在本节中,我们将了解 GCViT 的背景故事,并尝试 了解为什么提出它。
- 近年来,Transformers 在自然语言领域占据主导地位 处理 (NLP) 任务,并且具有允许 捕获长距离和短距离信息。
- 顺应这一趋势,Vision Transformer (ViT) 提议将图像补丁用作 令牌,类似于原始 Transformer 的编码器。
- 尽管卷积神经网络 (CNN) 在计算机领域历史上占据主导地位 视觉,基于 ViT 的模型已在各种 SOTA 或有竞争力的性能中显示出 计算机视觉任务。
- 然而,自我注意和缺乏的二次 [
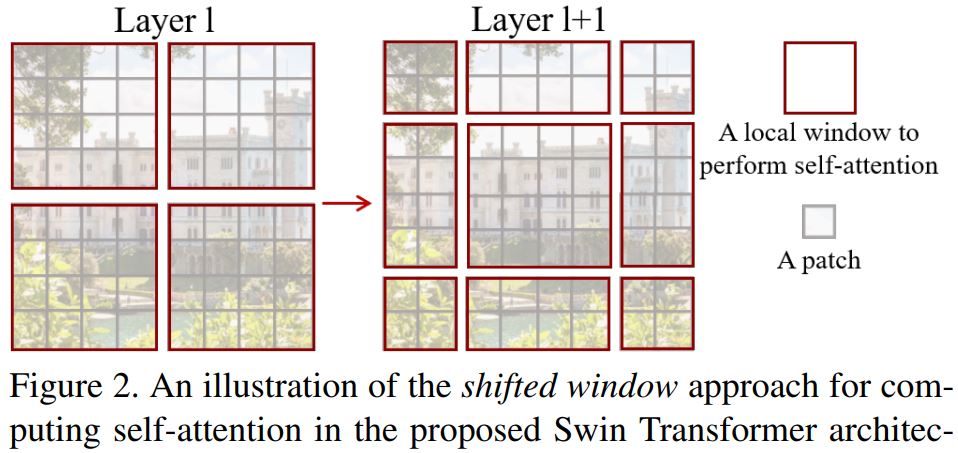
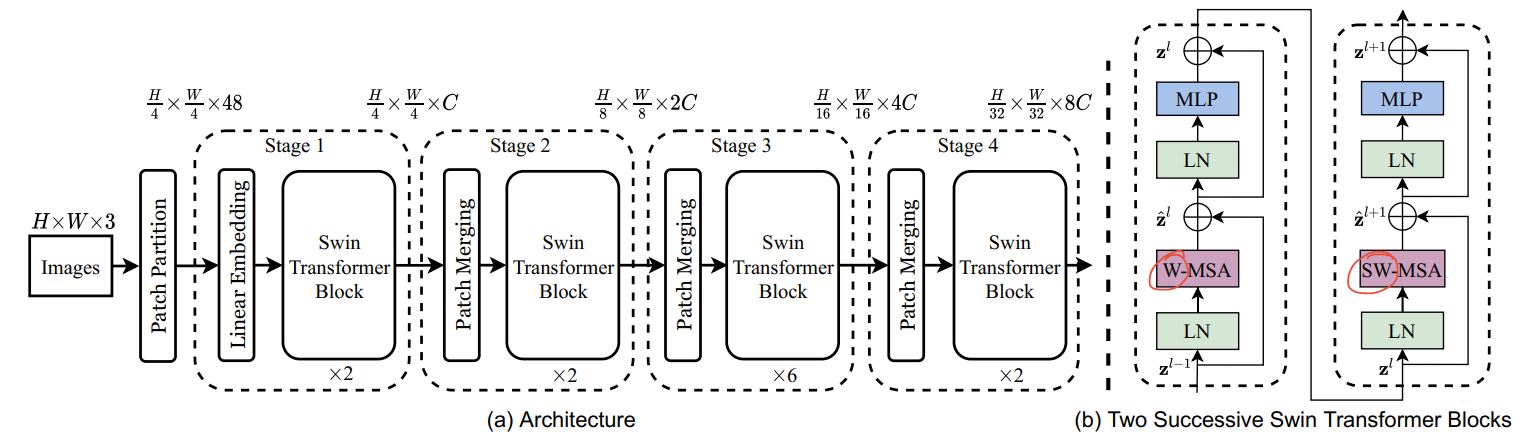
O(n^2)]计算复杂度 的多尺度信息使得 ViT 很难被视为 适用于 Compute Vision 任务(如分段和对象)的通用架构 检测,其中需要在像素级别进行密集预测。 - Swin Transformer 试图通过提出多分辨率 / 分层架构来解决 ViT 的问题,其中计算了自我注意力 在本地窗口和跨窗口连接中,例如使用 Window Shifting 用于对不同区域的交互进行建模。但有限的感受野 的本地窗口无法捕获远距离信息,且跨窗口连接 窗户移动等计划仅涵盖 每个窗口。此外,它缺乏鼓励某些翻译的归纳偏差 不变性对于通用视觉建模仍然更可取,尤其是对于 对象检测和语义分割的密集预测任务。
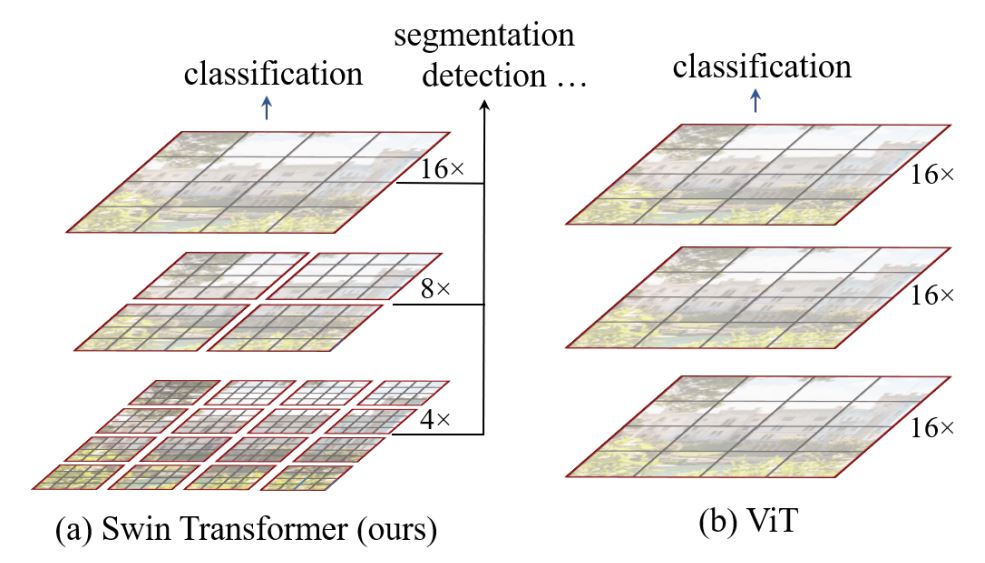
- 为了解决上述限制,提出了全局上下文 (GC) ViT 网络。
建筑
让我们快速了解一下我们的关键组件, 1. Stem/patchify 层在网络开始时处理图像。 对于这个网络,它会创建 patchs/tokens 并将它们转换为 embeddings。 2. 它是使用不同的 块。 3. 它使用 Depthwise-CNN、SqueezeAndExcitation (Squeeze-Excitation)、CNN 和 MaxPooling 生成全局令牌/补丁。所以基本上 它是一个特征提取器。 4. 它是重复模块,它关注功能和 将它们投影到某个维度。 1. 本地多头自我注意。 2. 全局多头自我注意。 3. 将向量投影到另一个维度的线性层。 5. 它与 Global Token Gen. 模块非常相似,只是它 使用 CNN 而不是 MaxPooling 对额外的 Layer 进行下采样 规范化模块。 6. 是负责分类任务的模块。 1. 它将特征转换为特征。 2. 它处理功能以决定 class。Stem/PatchEmbed:Level:Global Token Gen./FeatureExtraction:Block:Local-MSA:Global-MSA:MLP:Downsample/ReduceSize:Head:Pooling:N x 2DN x 1DClassifier:N x 1D
我已经对架构图进行了注释,使其更易于理解,
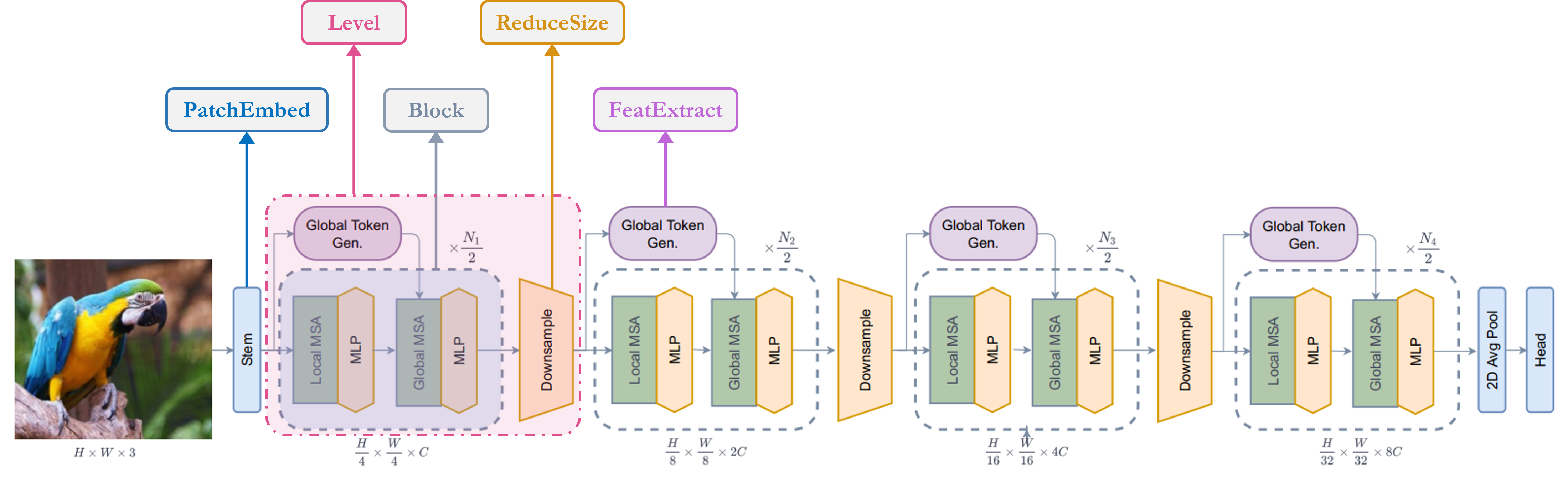
单元块
注意:这些块用于构建整篇论文中的其他模块。大多数 块要么是从其他作品中借来的,要么是 old work 的修改版本。
-
SqueezeAndExcitation: 挤压激励 (SE) 又名瓶颈模块作用 SD 频道种类 注意。它由 AvgPooling、Dense/FullyConnected (FC)/Linear、GELU 和 Sigmoid 模块组成。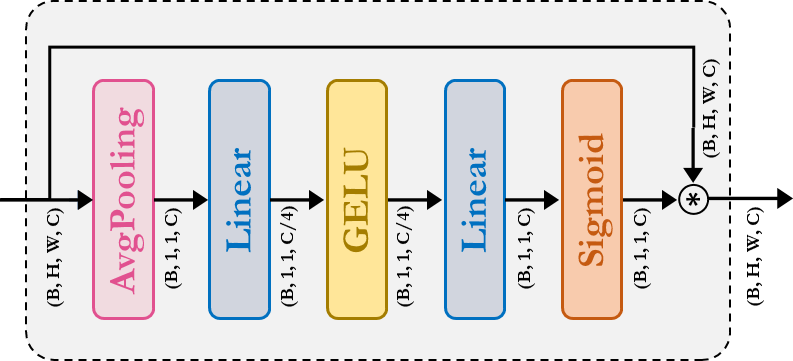
-
Fused-MBConv:这类似于 EfficientNetV2 中使用的那个。它使用 Depthwise-Conv、GELU、SqueezeAndExcitation、Conv 来提取特征 A 住宅 连接。请注意,没有为这个模块声明新模块,我们只是简单地应用 对应的模块。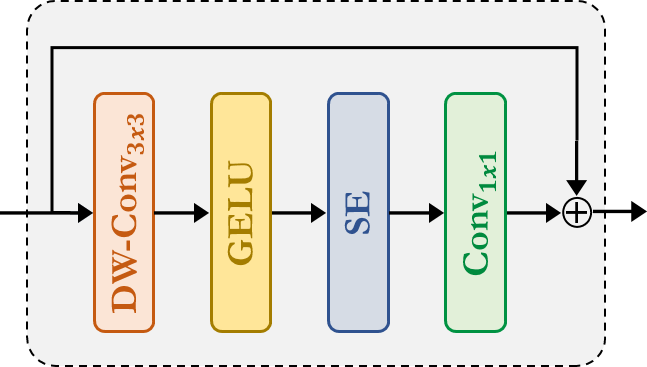
-
ReduceSize: 它是一个基于 CNN 的下采样模块,其中提到了提取功能模块,同时减少了 Strided Conv 空间维度和增加特征的通道维度,最后是 LayerNormalization 模块来归一化特征。在 paper/figure 中,此模块是 称为 Downsample 模块。我认为值得一提的是,SwniTransformer 使用 module 而不是来减少空间维度和 增加使用全连接/密集/线性模块的通道维度。 根据 GCViT 论文,使用的目的之一是添加 通过 CNN 模块的电感偏置。Fused-MBConvPatchMergingReduceSizeReduceSize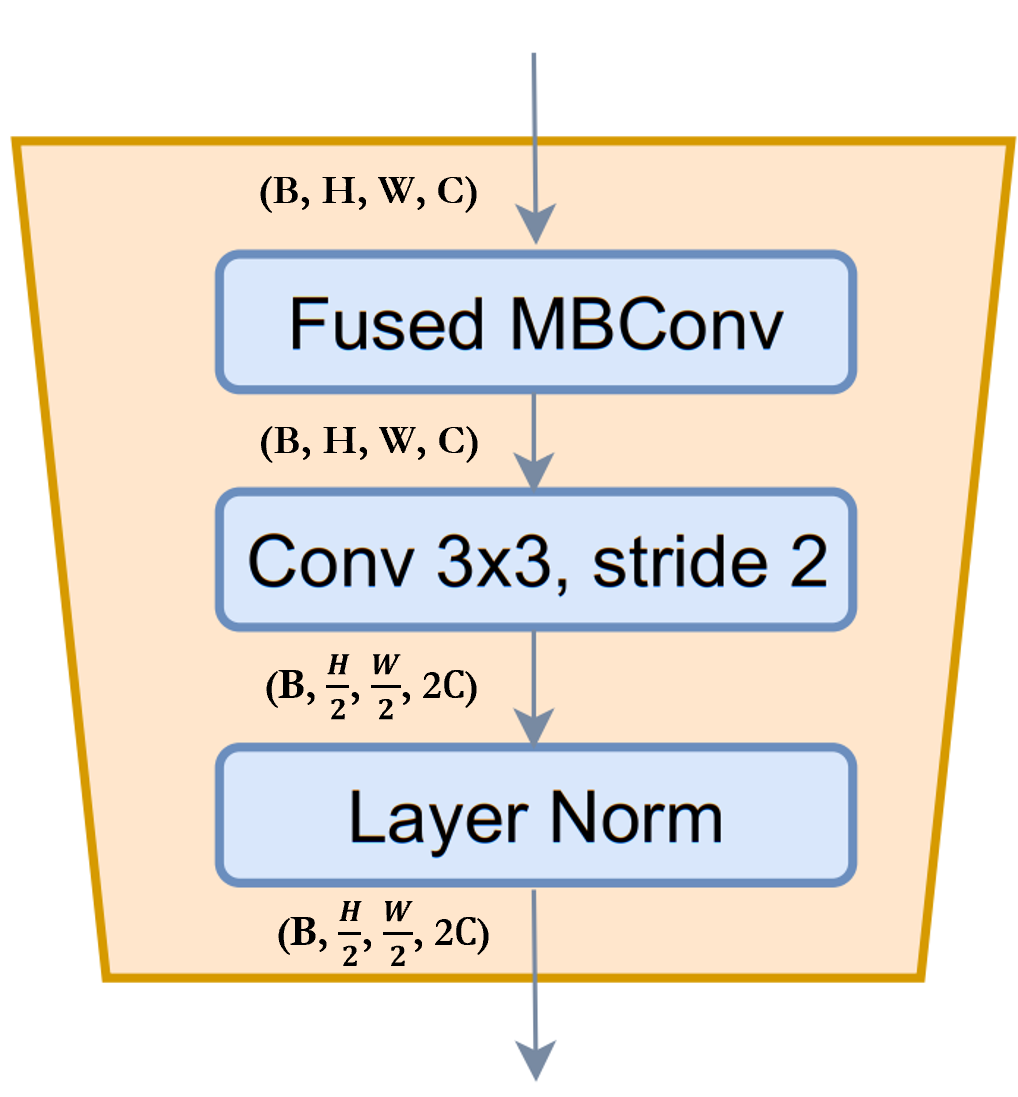
-
MLP:这是我们自己的 Multi Layer Perceptron 模块。这个 前馈/全连接/线性模块,只需将输入投影到任意 尺寸。
class SqueezeAndExcitation(layers.Layer):
"""Squeeze and excitation block.
Args:
output_dim: output features dimension, if `None` use same dim as input.
expansion: expansion ratio.
"""
def __init__(self, output_dim=None, expansion=0.25, **kwargs):
super().__init__(**kwargs)
self.expansion = expansion
self.output_dim = output_dim
def build(self, input_shape):
inp = input_shape[-1]
self.output_dim = self.output_dim or inp
self.avg_pool = layers.GlobalAvgPool2D(keepdims=True, name="avg_pool")
self.fc = [
layers.Dense(int(inp * self.expansion), use_bias=False, name="fc_0"),
layers.Activation("gelu", name="fc_1"),
layers.Dense(self.output_dim, use_bias=False, name="fc_2"),
layers.Activation("sigmoid", name="fc_3"),
]
super().build(input_shape)
def call(self, inputs, **kwargs):
x = self.avg_pool(inputs)
for layer in self.fc:
x = layer(x)
return x * inputs
class ReduceSize(layers.Layer):
"""Down-sampling block.
Args:
keepdims: if False spatial dim is reduced and channel dim is increased
"""
def __init__(self, keepdims=False, **kwargs):
super().__init__(**kwargs)
self.keepdims = keepdims
def build(self, input_shape):
embed_dim = input_shape[-1]
dim_out = embed_dim if self.keepdims else 2 * embed_dim
self.pad1 = layers.ZeroPadding2D(1, name="pad1")
self.pad2 = layers.ZeroPadding2D(1, name="pad2")
self.conv = [
layers.DepthwiseConv2D(
kernel_size=3, strides=1, padding="valid", use_bias=False, name="conv_0"
),
layers.Activation("gelu", name="conv_1"),
SqueezeAndExcitation(name="conv_2"),
layers.Conv2D(
embed_dim,
kernel_size=1,
strides=1,
padding="valid",
use_bias=False,
name="conv_3",
),
]
self.reduction = layers.Conv2D(
dim_out,
kernel_size=3,
strides=2,
padding="valid",
use_bias=False,
name="reduction",
)
self.norm1 = layers.LayerNormalization(
-1, 1e-05, name="norm1"
) # eps like PyTorch
self.norm2 = layers.LayerNormalization(-1, 1e-05, name="norm2")
def call(self, inputs, **kwargs):
x = self.norm1(inputs)
xr = self.pad1(x)
for layer in self.conv:
xr = layer(xr)
x = x + xr
x = self.pad2(x)
x = self.reduction(x)
x = self.norm2(x)
return x
class MLP(layers.Layer):
"""Multi-Layer Perceptron (MLP) block.
Args:
hidden_features: hidden features dimension.
out_features: output features dimension.
activation: activation function.
dropout: dropout rate.
"""
def __init__(
self,
hidden_features=None,
out_features=None,
activation="gelu",
dropout=0.0,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_features = hidden_features
self.out_features = out_features
self.activation = activation
self.dropout = dropout
def build(self, input_shape):
self.in_features = input_shape[-1]
self.hidden_features = self.hidden_features or self.in_features
self.out_features = self.out_features or self.in_features
self.fc1 = layers.Dense(self.hidden_features, name="fc1")
self.act = layers.Activation(self.activation, name="act")
self.fc2 = layers.Dense(self.out_features, name="fc2")
self.drop1 = layers.Dropout(self.dropout, name="drop1")
self.drop2 = layers.Dropout(self.dropout, name="drop2")
def call(self, inputs, **kwargs):
x = self.fc1(inputs)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
茎
注意:在代码中,这个模块被称为 PatchEmbed,但在纸面上,它 称为 Stem。
在模型中,我们首先使用了 module。让我们试着理解一下 模块。从方法中可以看出, 1. 该模块首先 pads 输入 2. 然后使用卷积提取带有嵌入的补丁。 3. 最后,使用 module 首先通过卷积提取特征,但 既不减少空间维度,也不增加空间维度。 4. 需要注意的重要一点是,与 ViT 或 SwinTransformer 不同,GCViT 会创建重叠的补丁。我们可以注意到,从代码 .如果我们想要不重叠的补丁,那么我们会使用相同的 和 。 5. 此模块将输入的空间维度减少 。patch_embedcallReduceSizeConv2D(self.embed_dim, kernel_size=3, strides=2, name='proj')kernel_sizestride4x
摘要:图像→填充→卷积→ (feature_extract + 下采样)
class PatchEmbed(layers.Layer):
"""Patch embedding block.
Args:
embed_dim: feature size dimension.
"""
def __init__(self, embed_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
def build(self





站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结