您现在的位置是:首页 >其他 >mapreduce打包提交执行wordcount案例网站首页其他
mapreduce打包提交执行wordcount案例
简介mapreduce打包提交执行wordcount案例
文章目录
一、源代码
1. WordCountMapper类
package org.example.wordcounttemplate;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
//新建输出文本对象(输出的key类型)
private Text text = new Text();
//新建输出IntWritable对象(输出的value类型)
private IntWritable intWritable = new IntWritable( 1);
/**
* 重写map方法
* @param key 文本的索引
* @param value 文本值
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取拆分后的一行文本
//mysql mysql value value value
String line = value.toString();
//根据分隔符进行单词拆分
String[] words = line.split( " ");
//循环创建键值对
for (String word : words){
//输出key值设置
text.set (word) ;
//进行map输出
//igeek igeek -> <igeek ,1> <igeek,1>
context.write(text,intWritable);
}
}
}
2. WordCountReducer类
package org.example.wordcounttemplate;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> {
//输出value对象
private IntWritable valueOut = new IntWritable();
/**
* 重写reduce方法
* @param key 单词值
* @param values 单词出现的次数集合
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//每个单词出现的次数
int sum= 0;
//<igeek,(1,1)>
for (IntWritable value : values){
//累计单词出现的数量
sum += value.get();
}
//进行封装
valueOut.set(sum);
// reduce输出
context.write(key, valueOut);
}
}
3. WordCountDriver类
package org.example.wordcounttemplate;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 充当mapreduce任务的客户端,用于提交任务
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息,获取job对象实例
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
// 2.关联本Driver得jar路径
job.setJarByClass(WordCountDriver.class);
// 3.关联map和reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4.设置map得输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出得kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6.设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7.提交job
boolean result=job.waitForCompletion(true);
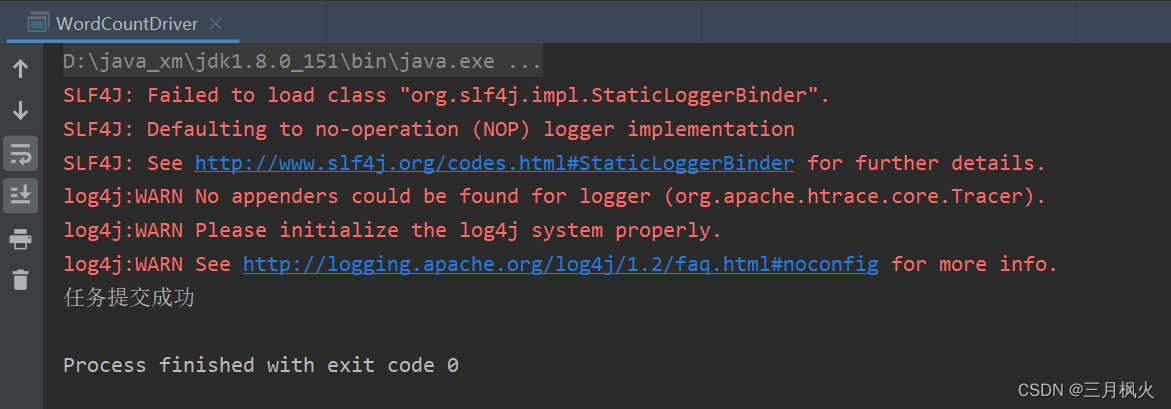
System.out.println(result?"任务提交成功":"任务提交失败");
}
}
4. pom.xml
重点是更改添加打包插件依赖
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mapreduce_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>mapreduce_demo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
二、相关操作和配置
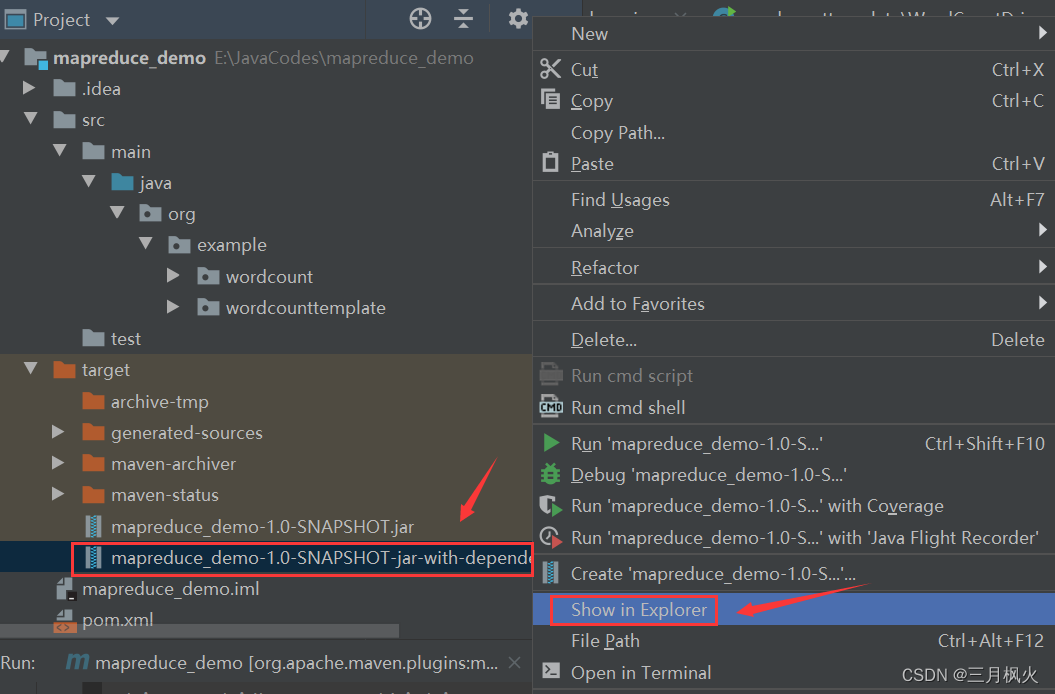
1. 项目打包
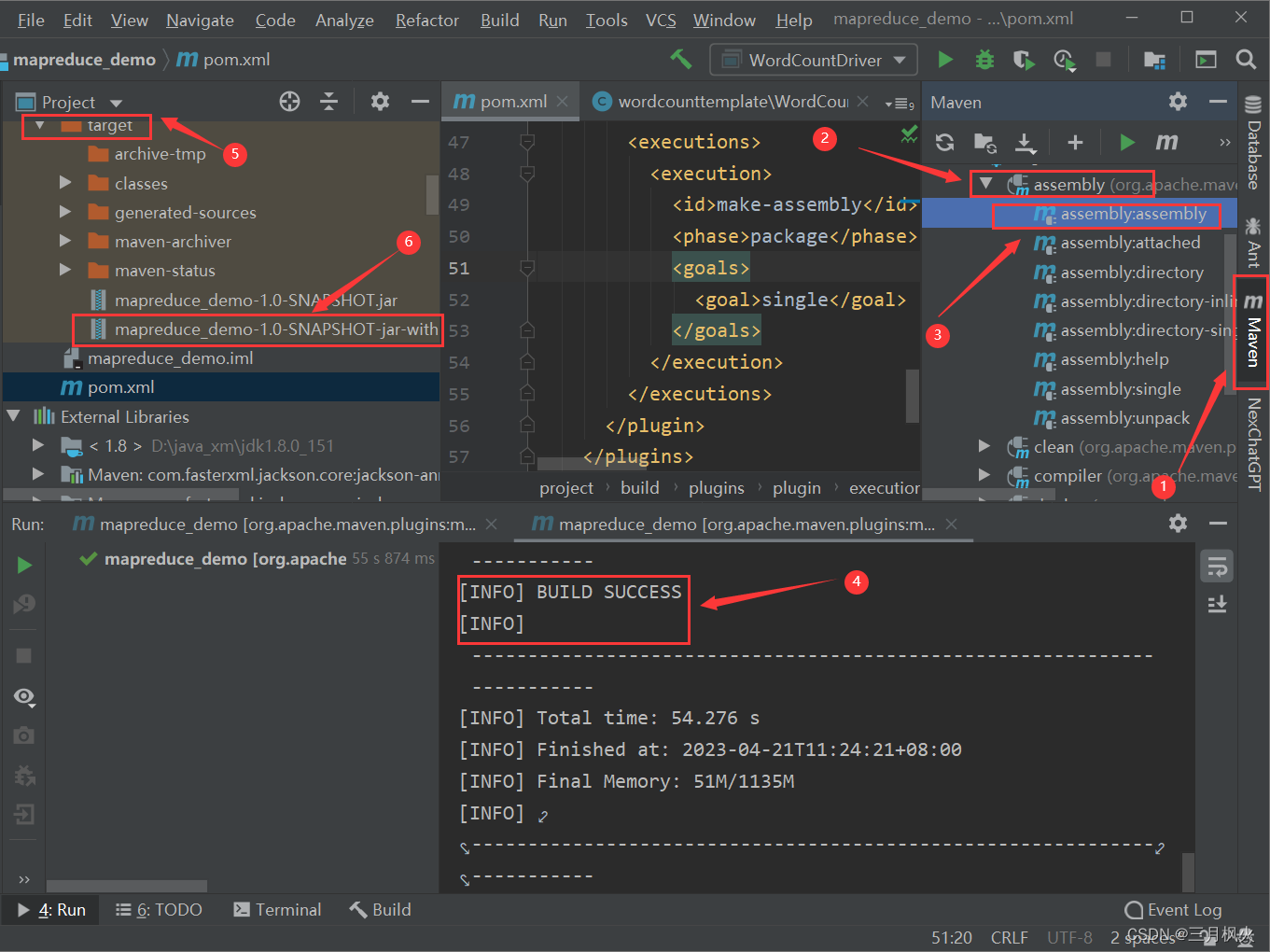
2. 带参测试
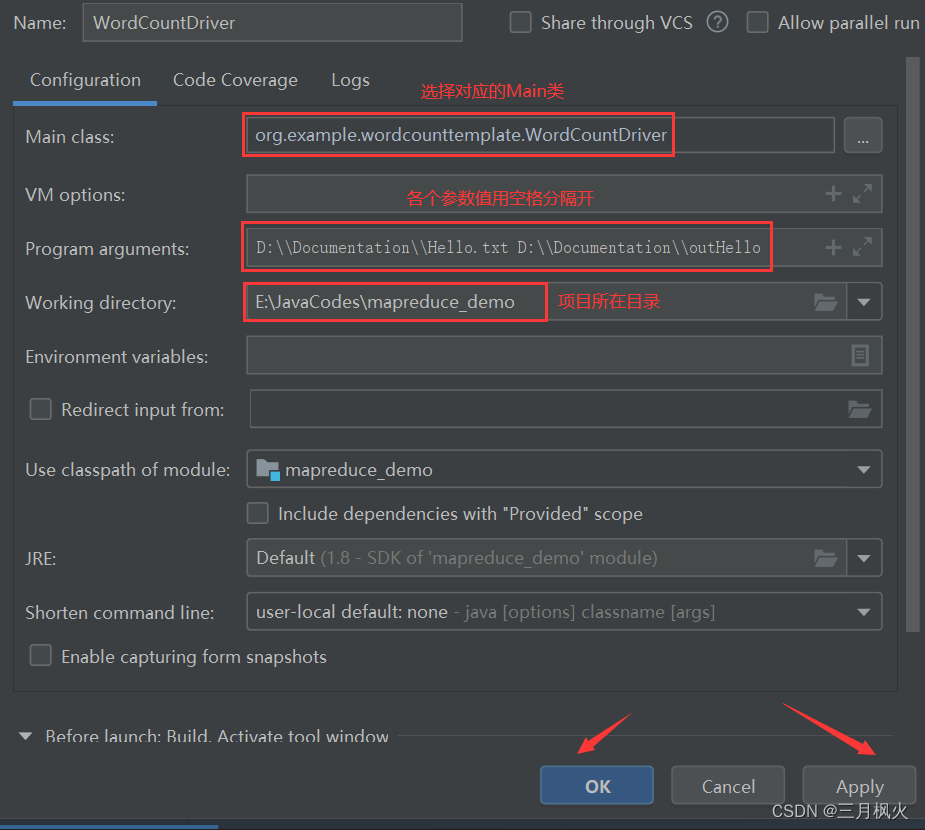
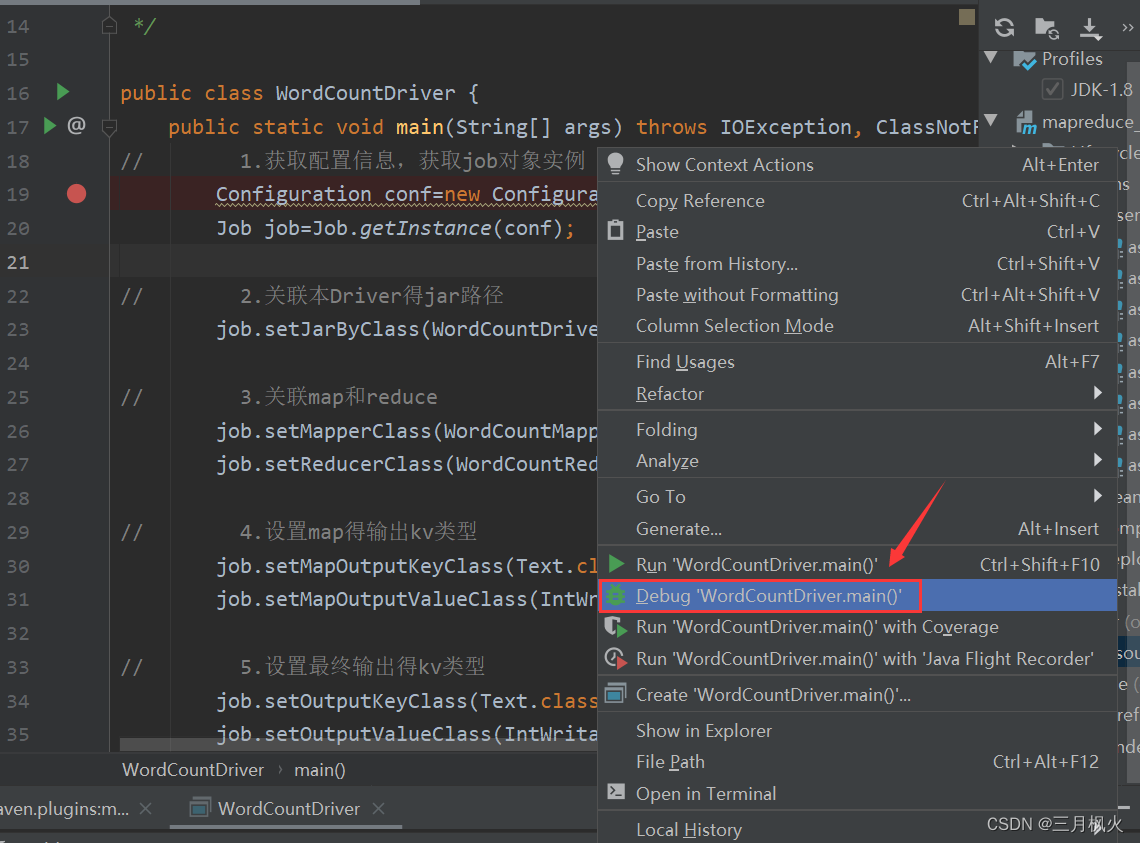
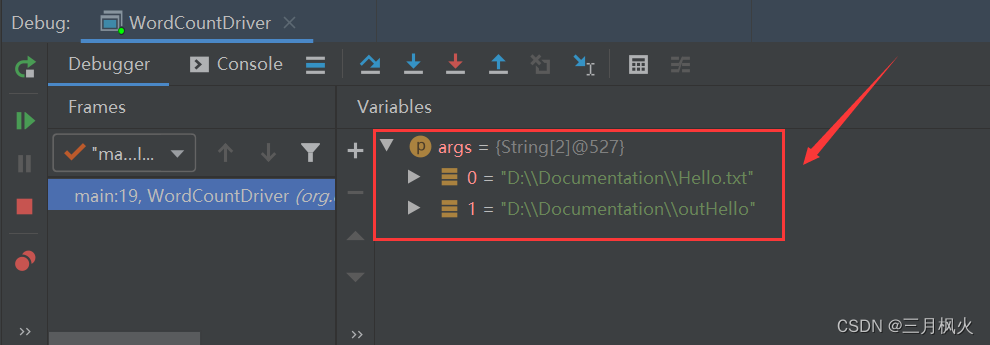
在本地执行成功:
3. 上传打包后的jar包和测试文档
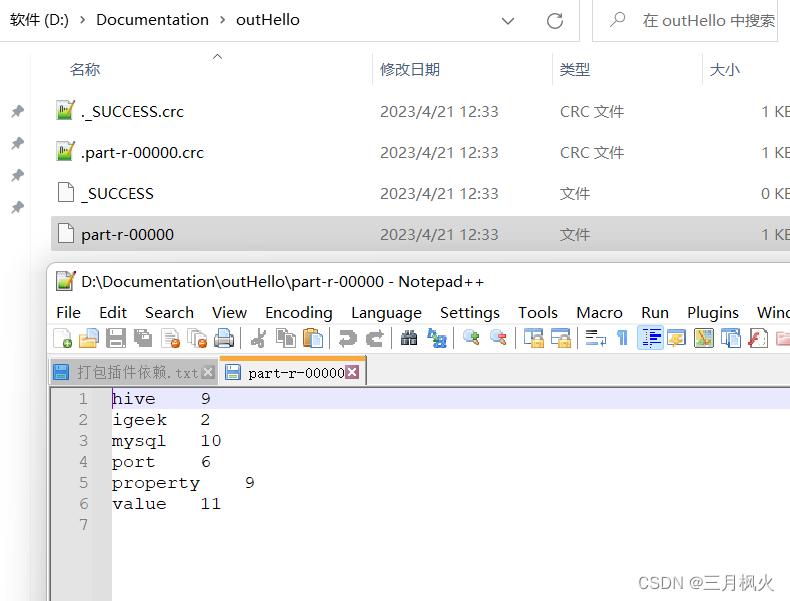
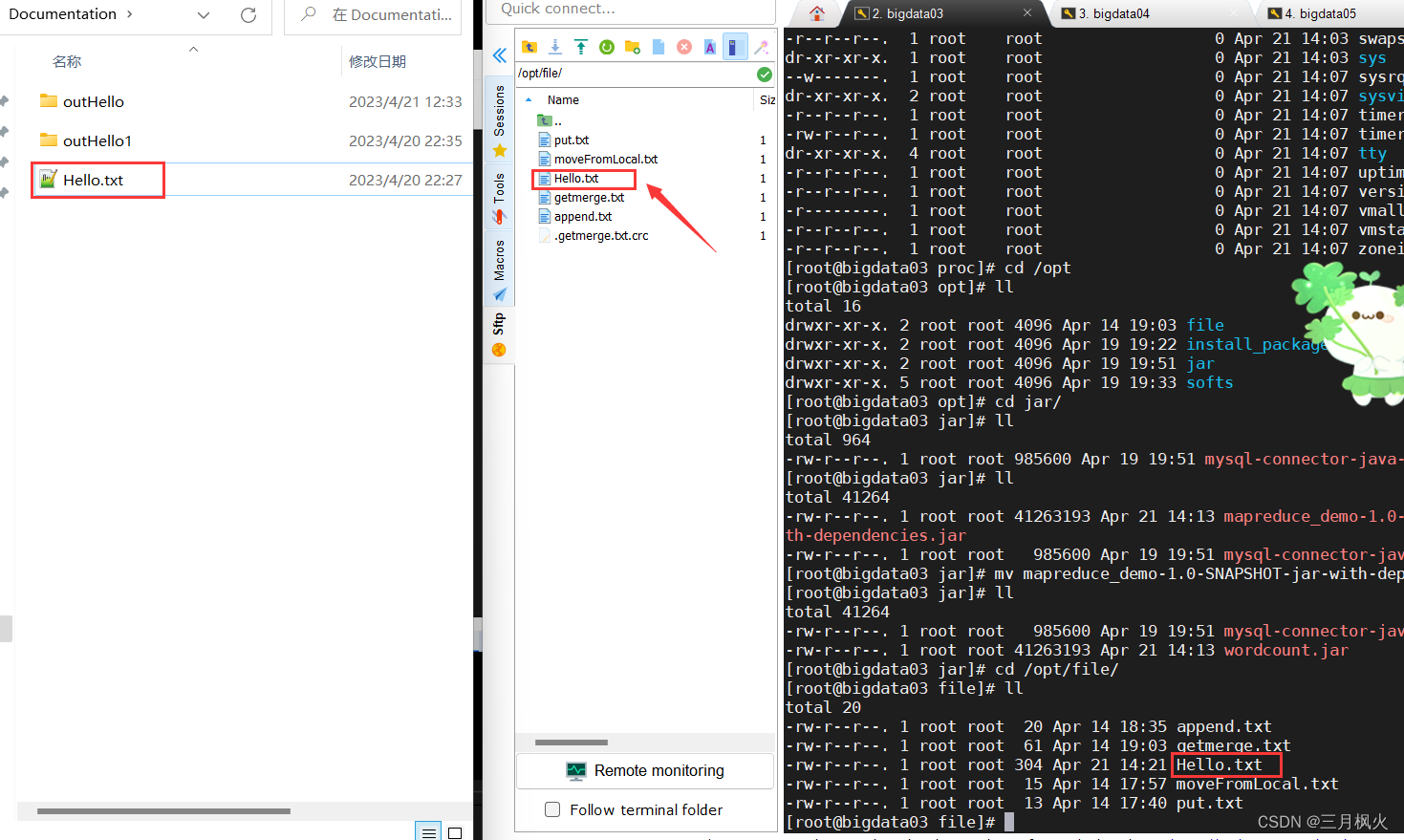
上传打包后的带依赖jar包(第二个)和测试文档Hello.txt 到linux系统及hdfs上
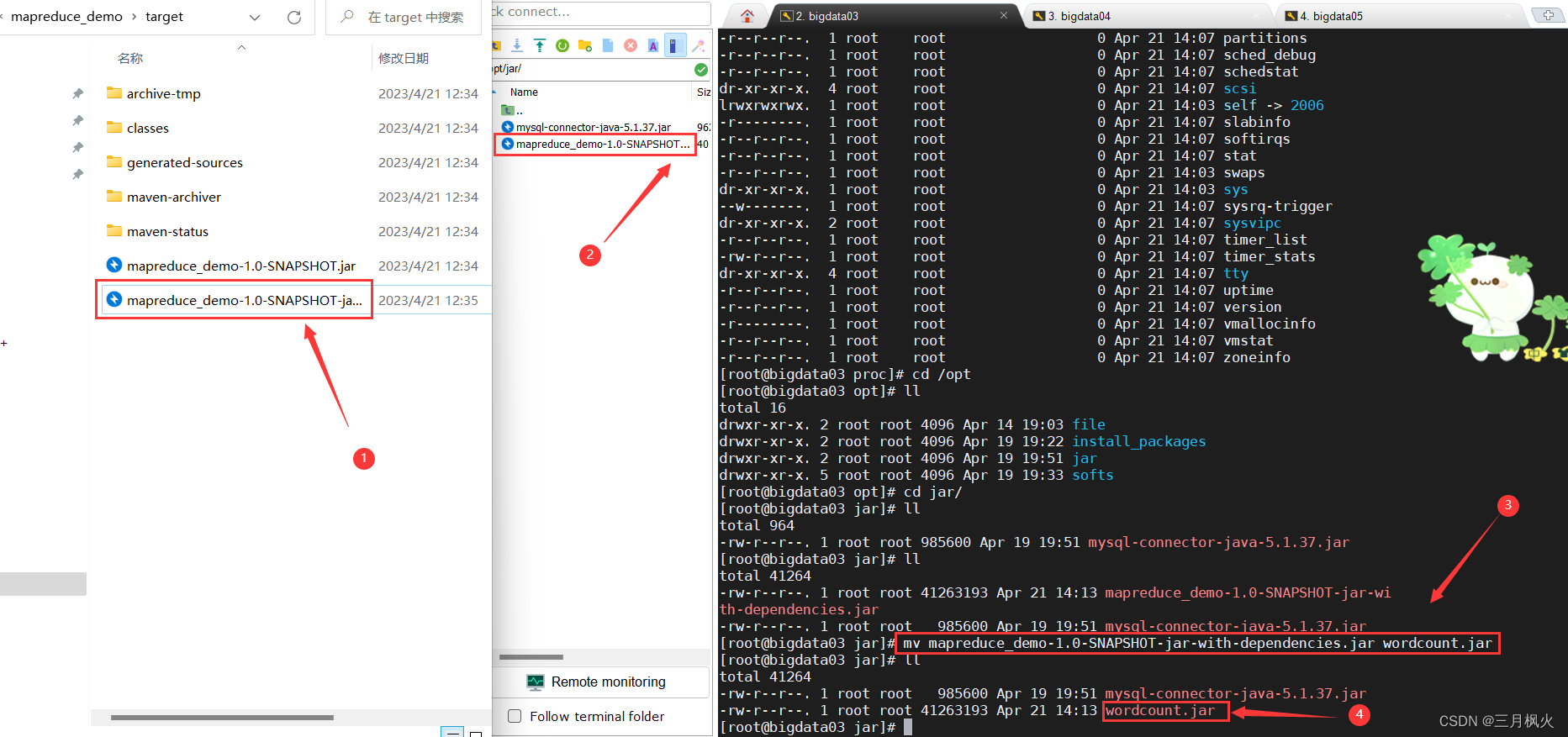
cd /opt/jar/
ll
jar包改名:
mv mapreduce_demo-1.0-SNAPSHOT-jar-with-dependencies.jar wordcount.jar
ll
cd /opt/file/
ll
4. 增大虚拟内存
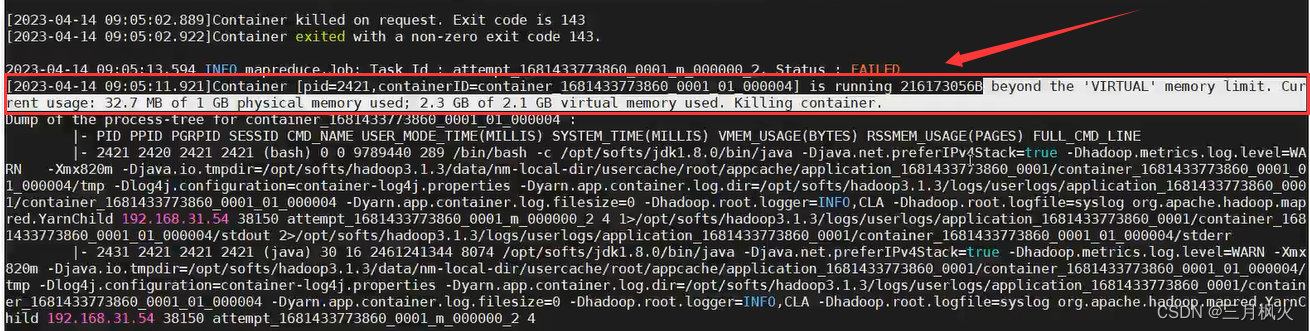
进行MapReduce操作时,可能会报溢出虚拟内存的错误
beyond the 'VIRTUAL’memory limit.
Current usage: 32.7 MB of 1 GB physical memory used;
2.3 GB of 2.1 GB virtual memory used. Killing container.
解决:
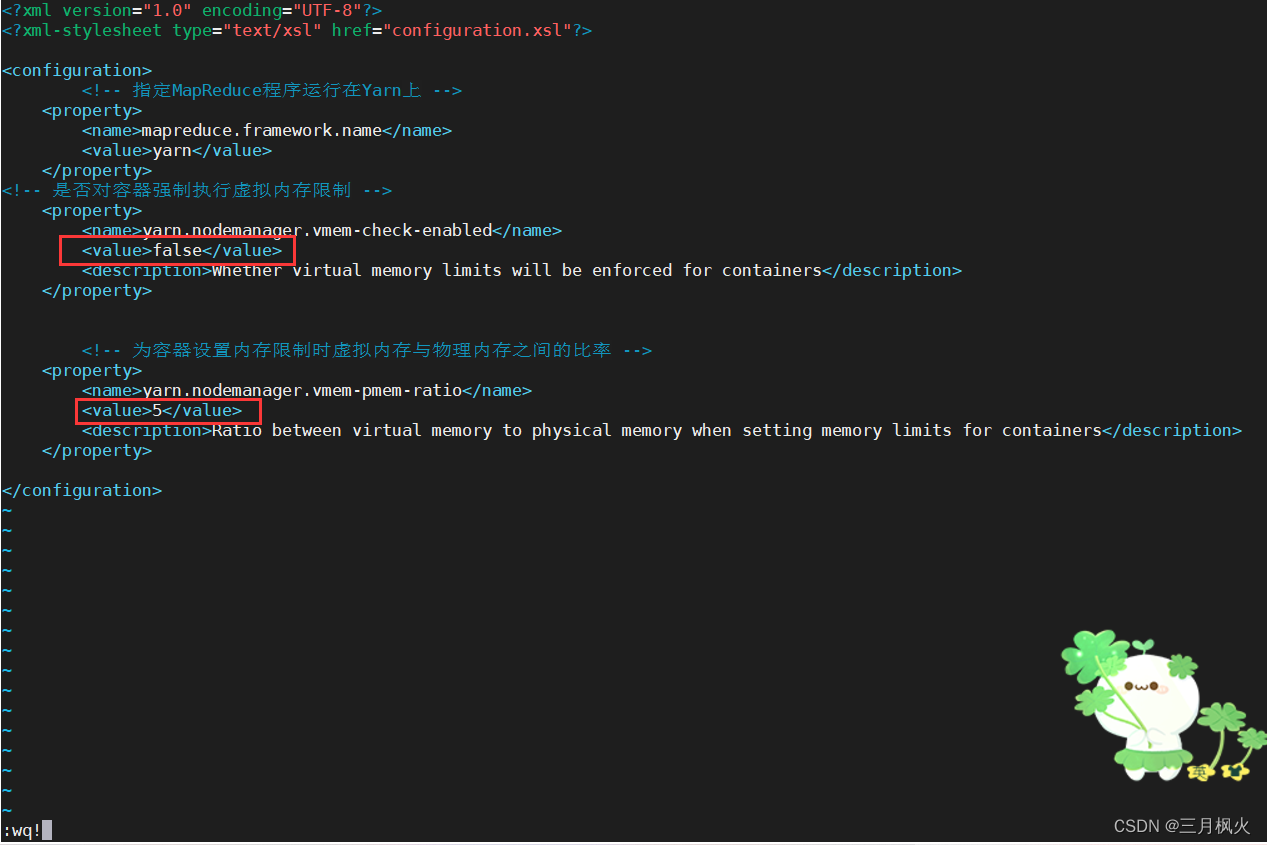
在mapred-site.xml中添加如下内容
<!-- 是否对容器强制执行虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
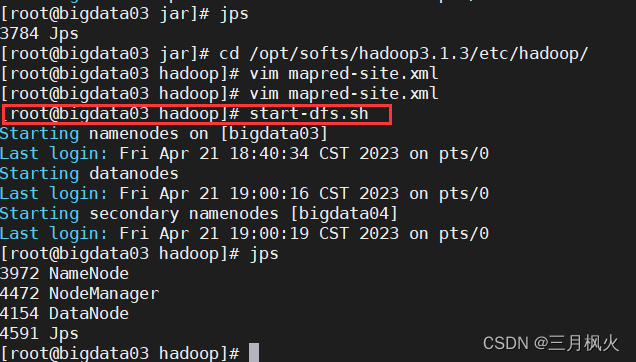
cd /opt/softs/hadoop3.1.3/etc/hadoop/
vim mapred-site.xml
分发到另外两台服务器虚拟机
scp mapred-site.xml root@bigdata04:/opt/softs/hadoop3.1.3/etc/hadoop/
scp mapred-site.xml root@bigdata05:/opt/softs/hadoop3.1.3/etc/hadoop/
5.启动集群
[root@bigdata03 hadoop]# start-dfs.sh
[root@bigdata05 ~]# start-yarn.sh
6.在hdfs上创建输入文件夹和上传测试文档Hello.txt
hadoop fs -ls /
hadoop fs -mkdir /input
hadoop fs -put Hello.txt /input
hadoop fs -ls /input
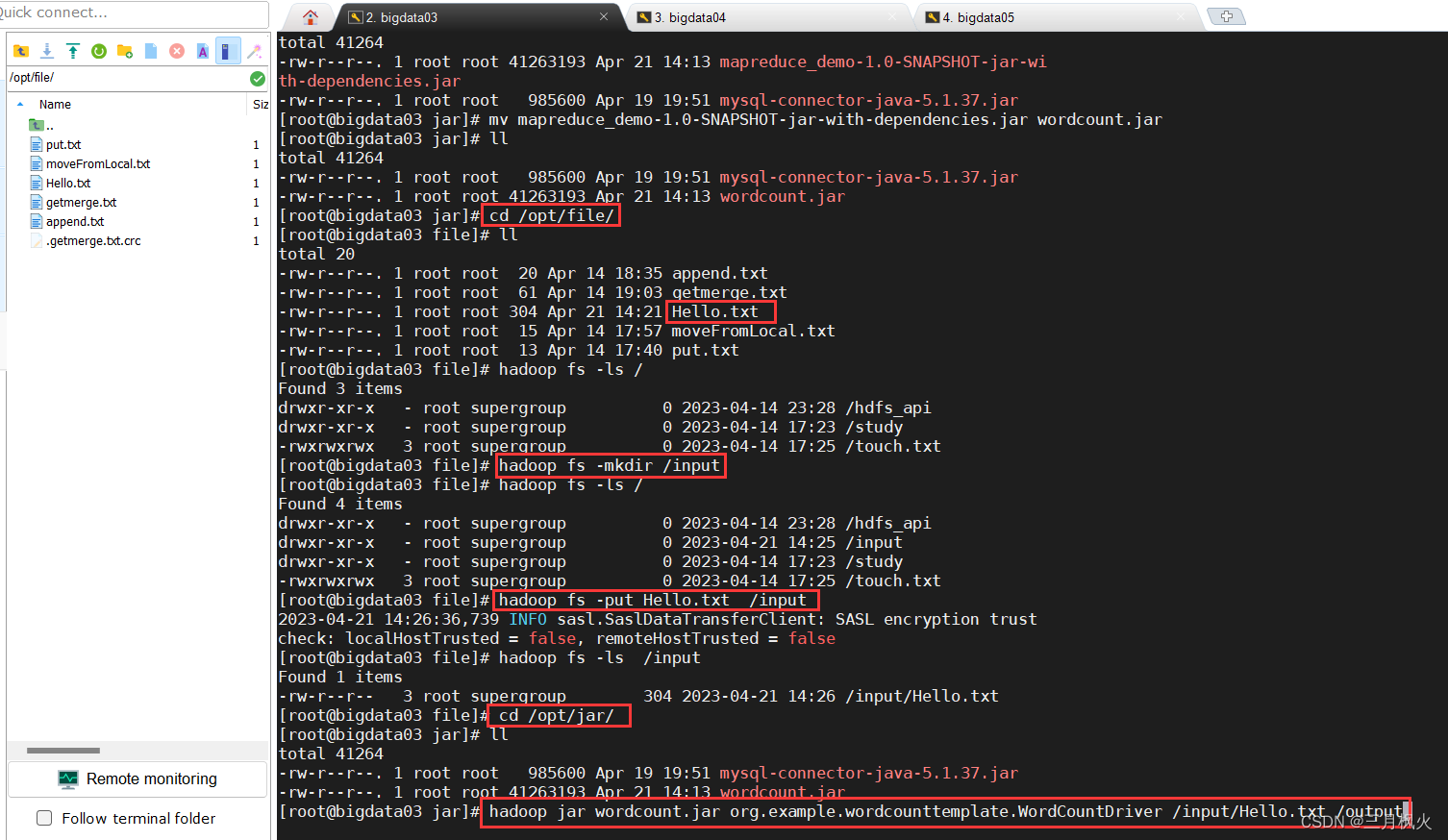
7. 利用jar包在hdfs实现文本计数
cd /opt/jar/
ll
hadoop jar wordcount.jar org.example.wordcounttemplate.WordCountDriver /input/Hello.txt /output
注意:输出目录需不存在,让他执行命令时自行创建
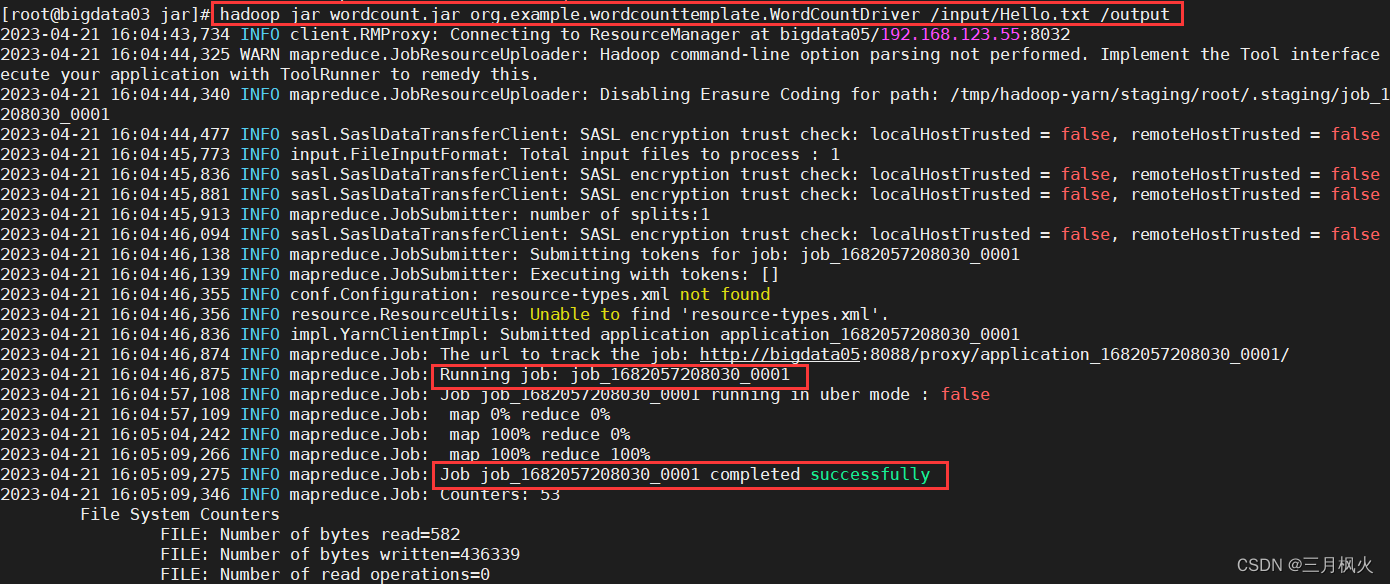
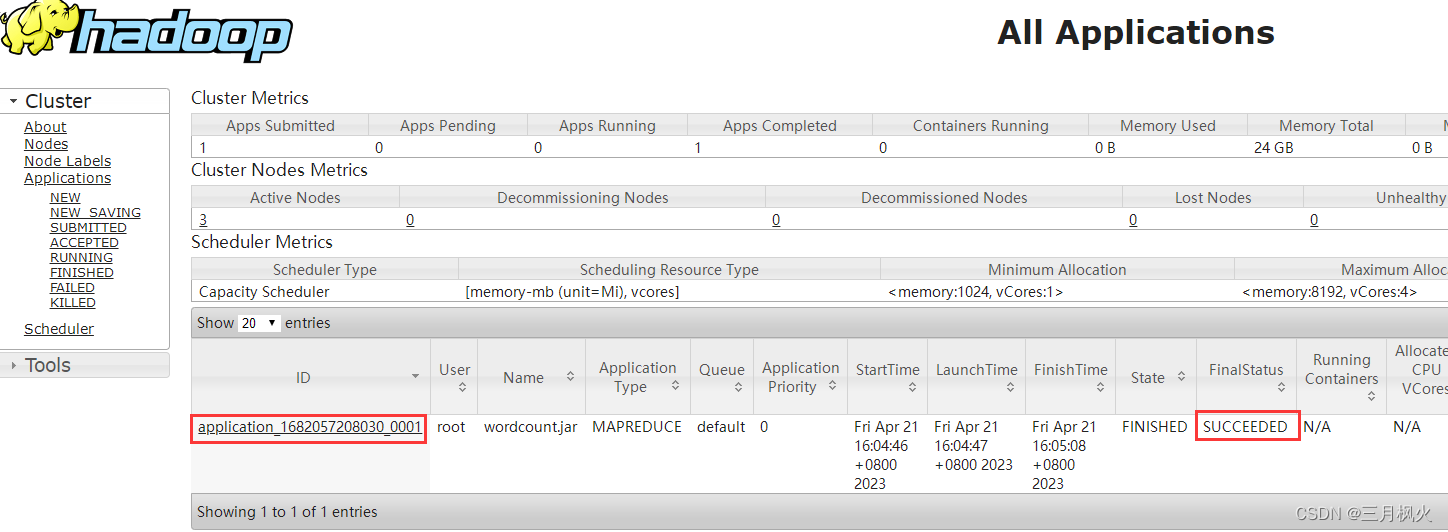
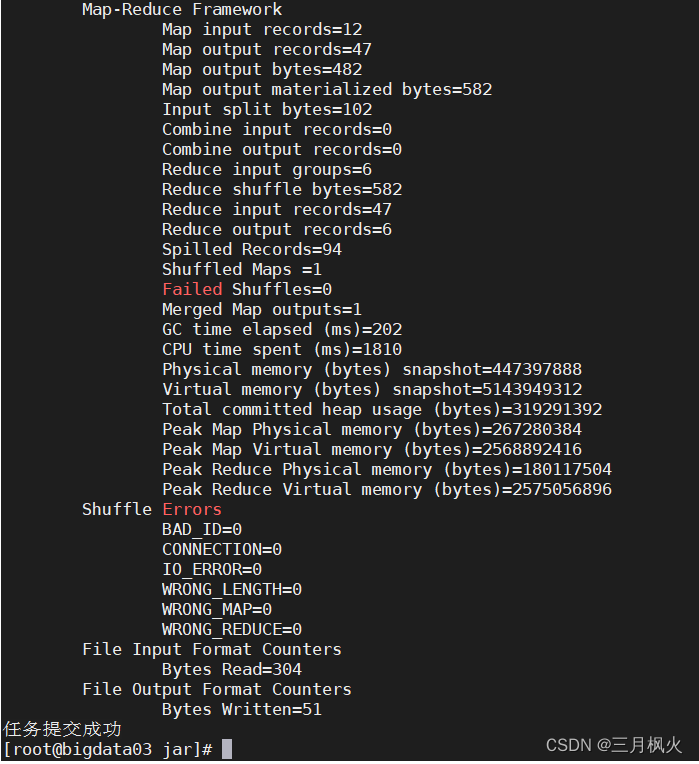
8. 查看计算统计结果
hadoop fs -ls /output
hadoop fs -cat /output/part-r-00000
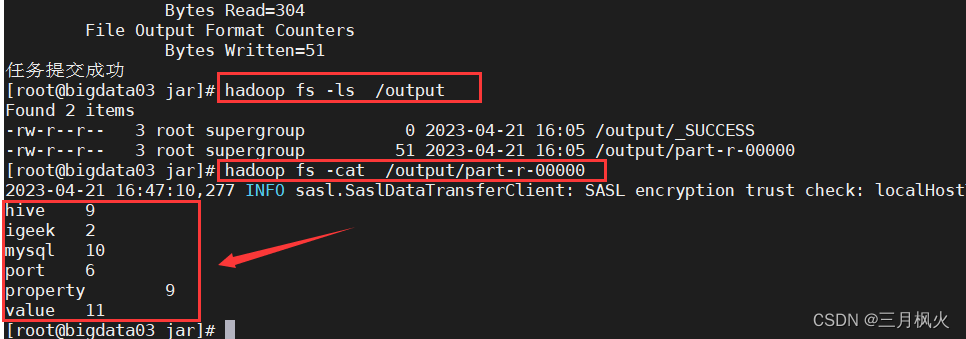
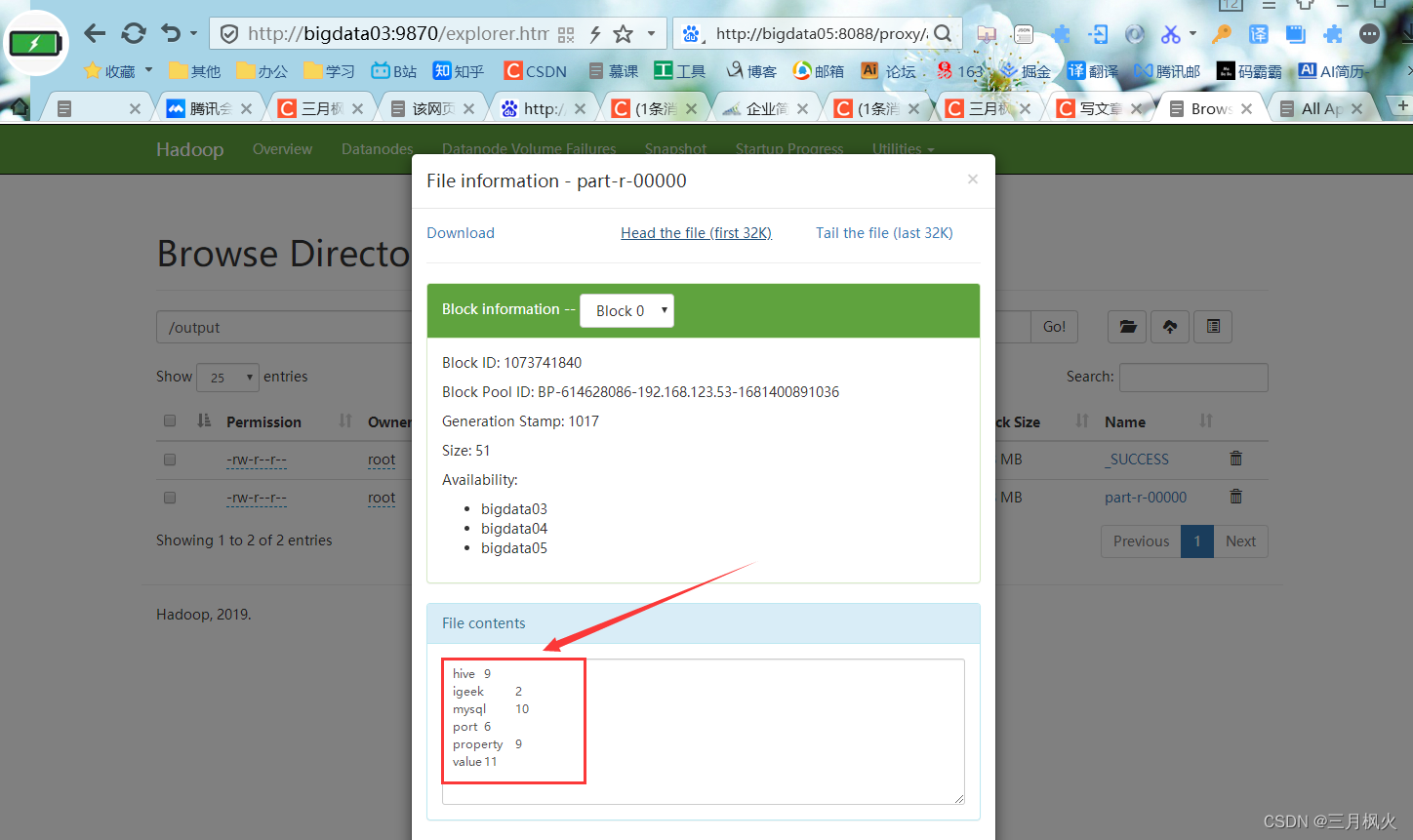
对照文章:
大数据作业4(含在本地实现wordcount案例)
https://blog.csdn.net/m0_48170265/article/details/130029532?spm=1001.2014.3001.5501
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结