您现在的位置是:首页 >学无止境 >机器学习之支持向量机-分类、回归初体验网站首页学无止境
机器学习之支持向量机-分类、回归初体验
大家好我是木木,自从2022年11月30日OpenAI发布ChatGPT后,大模型迅速火热起来,人工智能作为当下最火的行业之一,2025年春节期间DeepSeek R1模型大火。接下来带领大家进行支持向量机-分类、回归初体验。
人工智能有三浪潮,第二个浪潮:是为了找到人工智能新的突破点,期间出现了很多的新算法,而支持向量机也是第二个阶段重要发展的技术之一。第二个阶段虽然让人工智能又火热一段时间,但是由于当时的硬件资源有限、数据量不足等问题限制再次陷入缓慢阶段
详细三浪潮可以看:浅谈人工智能3大浪潮阶段-CSDN博客
支持向量机:是一个有监督的机器学习算法,主要是解决线性可分和线性不可分问题,算法思想是:在特征空间中找一个最优超平面能够将2个类别完全正确的分开,并且2类数据的点和超平面的间隔最优。
比如:2个类别的数据做划分,如果没有要求随意只要将它们划分开即可
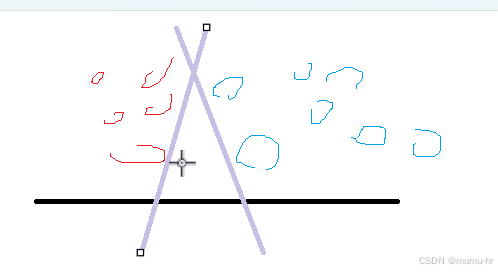
但是支持向量机可以选择一个最优的面进行划分,增强了算法的鲁棒性
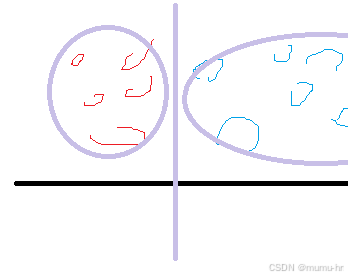
缺点:由于它会选择最优的面进行划分,那么它的计算代价很会很高,一般都是用于小样本训练推理,如果数据量太大会导致训练时间长,硬件资源提升,同时如果数据样本分布不一致,也会导致支持向量机的性能受到影响。
线性可分原理:线性可分的情况,通过超平面方程公式,找到最优的W和B,使得间隔最大化。
线性不可分原理:对于线性不可分的数据,使用核函数通过一个非线性映射将原始数据映射到高维特征空间,使得在高维空间中的数据变得线性可分。
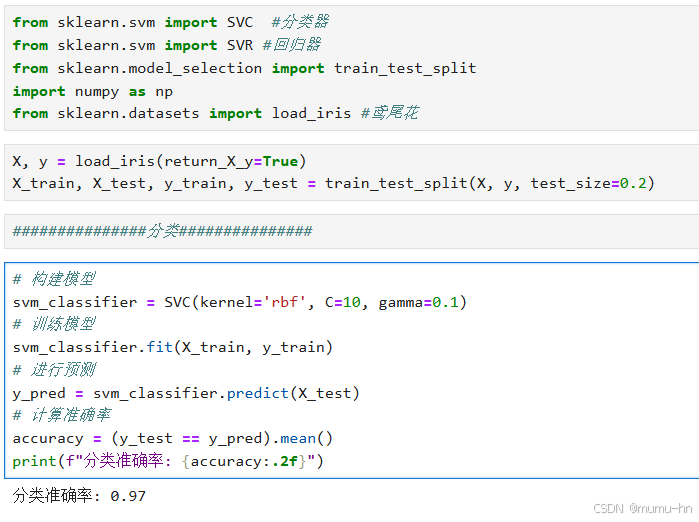
分类实现
from sklearn.svm import SVC #分类器
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.datasets import load_iris #鸢尾花
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
###############分类###############
# 构建模型
svm_classifier = SVC(kernel='rbf', C=10, gamma=0.1)
# 训练模型
svm_classifier.fit(X_train, y_train)
# 进行预测
y_pred = svm_classifier.predict(X_test)
# 计算准确率
accuracy = (y_test == y_pred).mean()
print(f"分类准确率: {accuracy:.2f}")结果输出
回归实现
from sklearn.svm import SVR #回归器
from sklearn.model_selection import train_test_split
import numpy as np
###############回归###############
X = []
y = []
with open('../../base_info/housing.data',mode='r',encoding='utf8') as f:
for line in f:
#line.strip:去掉字符串两端的空格和换行符 split() 方法将字符串按空格分隔成多个子字符串
float_line = [float(item) for item in line.strip().split()]
if float_line: # 检查列表是否不为空
X.append(float_line[: -1])
y.append(float_line[-1])
X = np.array(X)
y = np.array(y)
#切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#简单预处理
_mean = X_train.mean(axis=0) + 1e-9
_std = X_train.std(axis=0) + 1e-9
X_train = (X_train - _mean) / _std
X_test = (X_test - _mean) / _std
# 构建模型
svm_regressor = SVR(kernel='rbf', C=10, gamma=0.1)
# 训练模型
svm_regressor.fit(X_train, y_train)
# 进行预测
y_pred = svm_regressor.predict(X_test)
# 计算均方误差
mse = np.mean((y_test - y_pred) ** 2)
print(f"均方误差: {mse:.2f}")结果输出






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结