您现在的位置是:首页 >技术交流 >Hadoop之Hive网站首页技术交流
Hadoop之Hive
文章目录
一、Hive简介
1.1 Hive 基本概念
Hive是一个基于Hadoop的数据仓库架构,使用SQL语句读、写和管理大型分布式数据集。Hive可以将SQL语句转化MapReduce(或Apache Spark和Apache Tez)任务执行,大大降低了Hadoop的使用门槛,减少了开发MapReduce程序的时间成本。
可以将Hive理解为一个客户端工具,其提供了一种类SQL查询语言,称为 HiveQL
1.2 Hive架构图
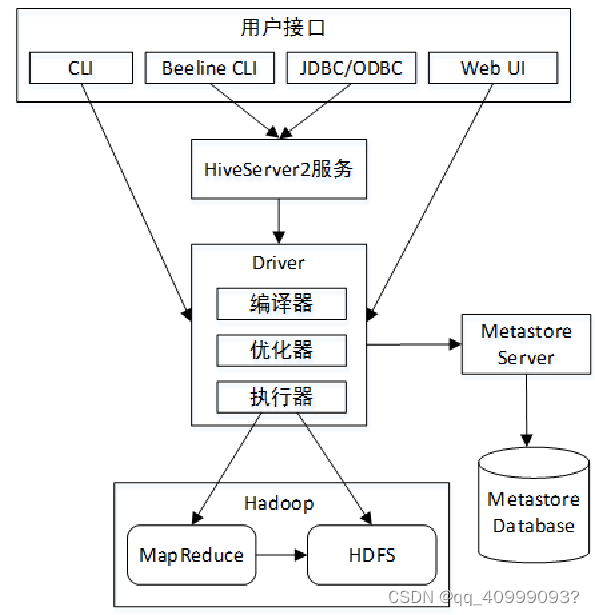
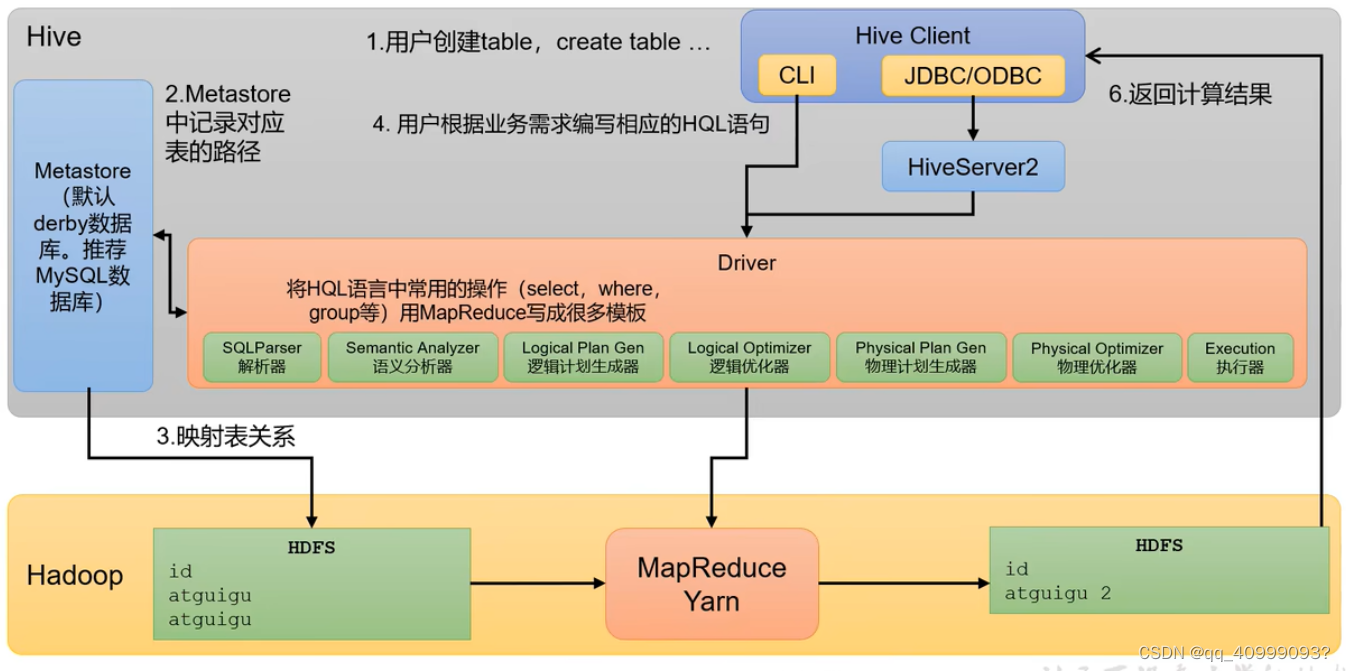
用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command lineinterface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器:完成 HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
执行引擎:Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎
1.3 Hive数据模型
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。
Hive中的数据可以在粒度级别上分为三类:
Table 表
Partition分区
Bucket 分桶
Hive作为一个数据仓库。默认数据库default。
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse
二、Hive安装配置
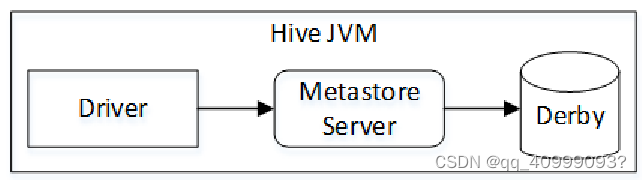
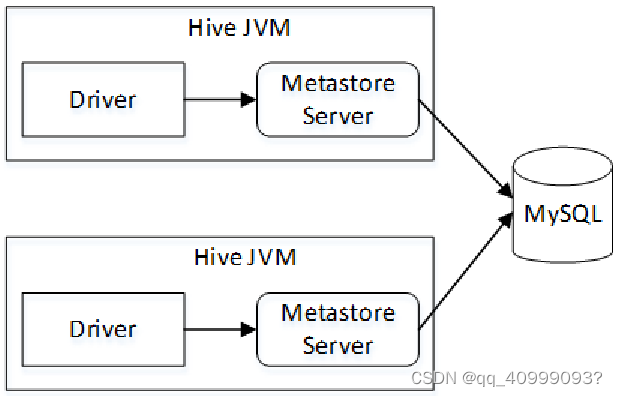
Hive根据Metastore Server的位置不同可以分为三种运行模式:内嵌模式、本地模式和远程模式。
Hive基于Hadoop,Hive只需在Hadoop集群的其中一个节点安装即可,而不需要搭建Hive集群。
2.1 内嵌模式
#安装
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/modules/
#环境变量
vim /etc/profile
......
export HIVE_HOME=/opt/modules/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
......
source /etc/profile
hive --version
#关联Hadoop
#拷贝Hive安装目录下的conf/hive-env.sh.template文件为hive-env.sh,
export HADOOP_HOME=/opt/modules/hadoop-3.3.4
#创建数据仓库目录
$ hadoop fs -mkdir /tmp
$ hadoop fs -mkdir -p /user/hive/warehouse
#初始化元数据信息
schematool -dbType derby –initSchema
#启动Hive CLI
hive
2.2 配置元数据到mysql
mysql 安装配置
https://blog.csdn.net/qq_35911309/article/details/122266247
新建Hive元数据库
mysql -uroot -p’123456’
mysql> create database metastore;#hive_db或不配置时建
mysql> quit;
#初始化元数据库表
TBLS COLUMNS_V2 SDS…
2.3本地模式
mysql-connector-j-8.0.32.jar驱动包下载
#MySQL的驱动包到Hive lib目录下
cp mysql-connector-j-8.0.32-1.el7.noarch.rpm /opt/modules/apache-hive-3.1.3-bin/lib/
#配置hive
vim hive-site.xml
......
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--MySQL数据库连接信息 -->
<property><!--连接MySQL的驱动类 -->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property><!--MySQL连接地址,此处连接远程数据库,可根据实际情况进行修改 -->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://centos1:3306/hive_db?createDatabaseIfNotExist=true</value>
</property>
<property><!--MySQL用户名 -->
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property><!--MySQL密码 -->
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
......
#初始化原数据
schematool -dbType mysql –initSchema
#启动
hive
2.4远程模式
远程模式将Metastore
Server分离了出来,作为一个单独的进程,并且可以部署多个,运行于不同的机器上。这样的模式,将数据库层完全置于防火墙后,使客户端访问时不需要数据库凭据(用户名和密码),提高了可管理性和安全性。

(1)安装Hive客户端
#在本地模式基础上,centos01节点中执行以下命令,将Hive安装文件拷贝到centos2节点:
scp -r apache-hive-3.1.3-bin/ root@centos2:/opt/modules/
(2)修改centos2节(客户端) hive-site.xml
<!--Hive数据仓库在HDFS中的存储目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--是否启用本地服务器连接Hive,false为非本地模式,即远程模式-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--Hive服务端Metastore Server连接地址,默认监听端口9083-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://centos1:9083</value>
</property>
(3)启动Metasotre Server 在centos1 节点执行
hive --service metastore &
# 控制台输出2023-04-16 15:48:34: Starting Hive Metastore Server
测试:
centos1节点(服务端)
hive> CREATE TABLE stu2(id INT,name STRING);
centos2节点(H客户端)查看Hive中的所有表:
hive> SHOW TABLES;
2.5 Hive JDBC Hiverserver2

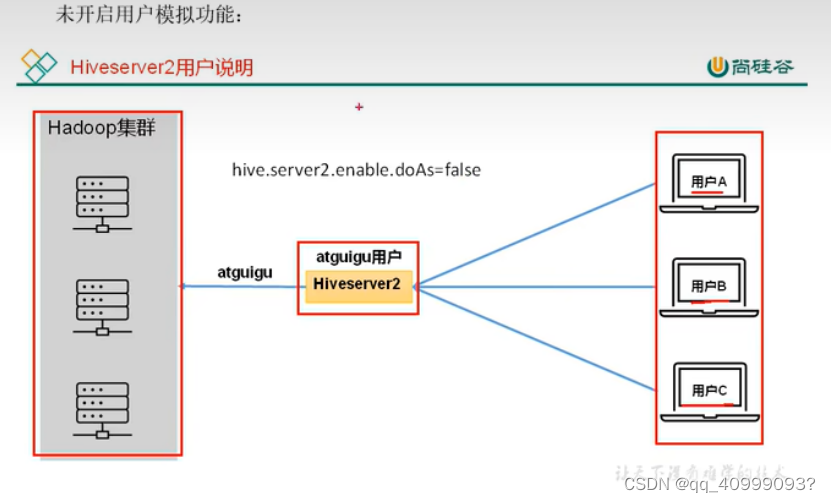
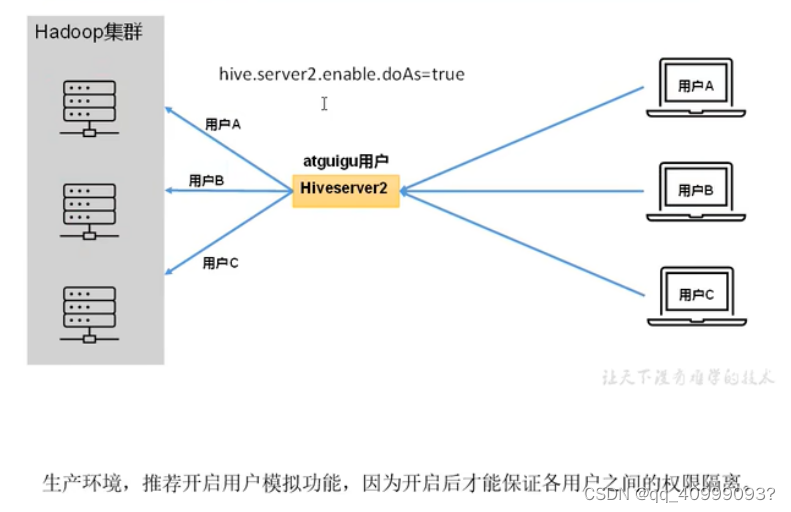
2.5.1远程模式下使用Beeline CLI
#centos1节点修改Hadoop配置文件core-site.xml
......
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
......
# 将core-site.xml 同步到Hadoop集群其他节点。就可以用root用户在CLI中连接Hive
# 启动HiveServer2 centos1
hive --service hiveserver2 &
#启动Beeline CLI cenots2
bin/beeline
# 连接HiveSver2服务
beeline> !connect jdbc:hive2://centos1:10000
centos1
http://192.168.10.101:10002/ hive-web_-ui 默认端口10002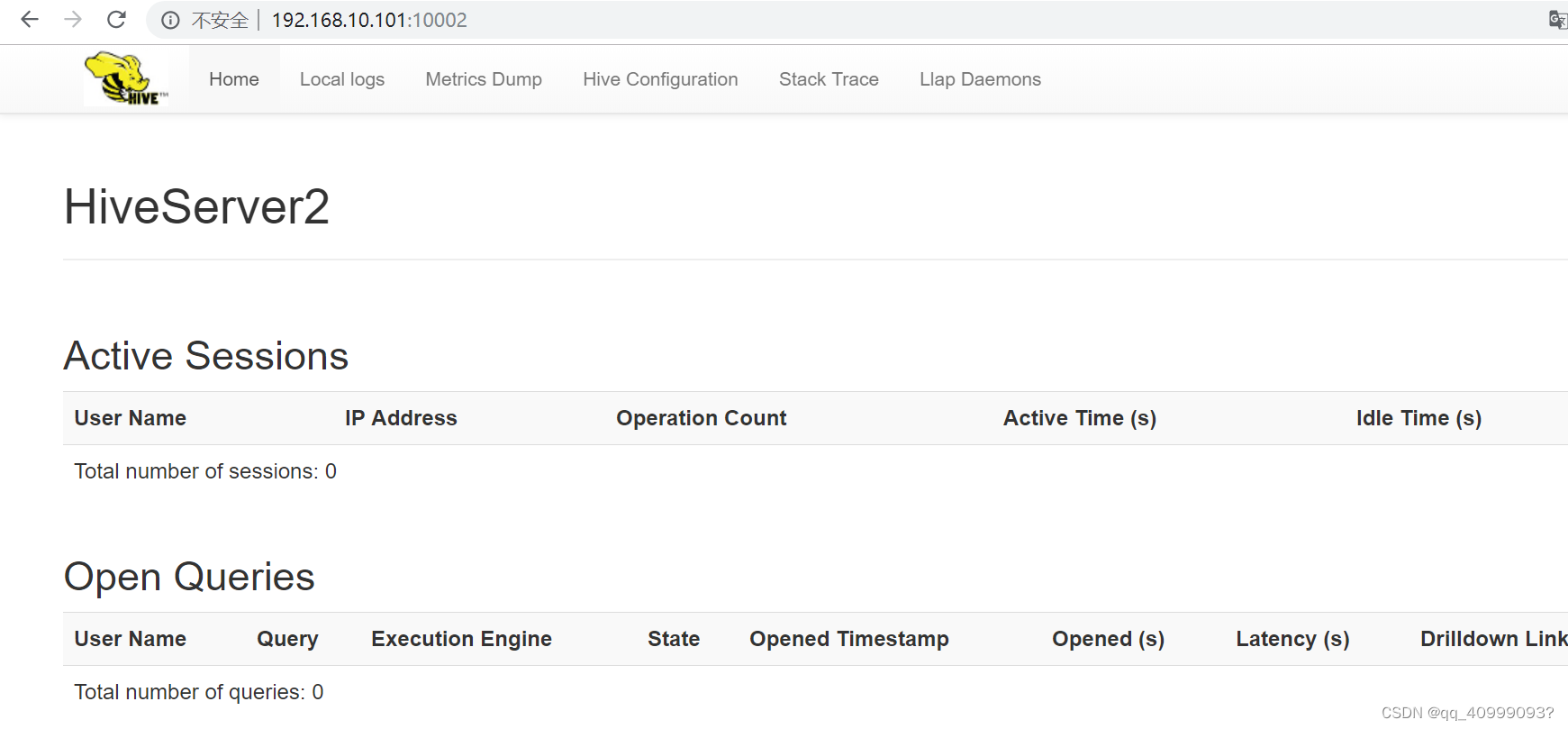
centos2 链接默认端口10000,默认密码为空,用户为启动配置用户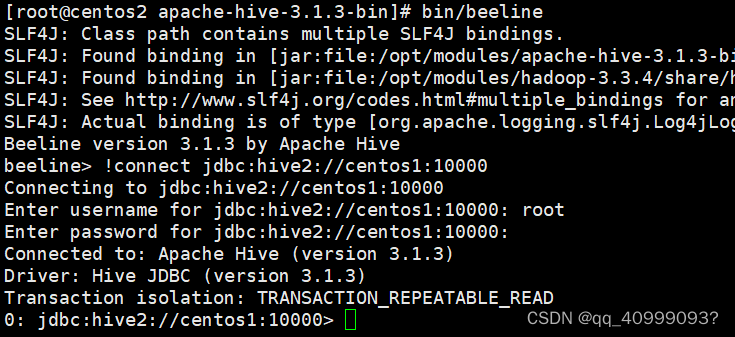
在BeelineCLI 界面执行相关HiveQL了
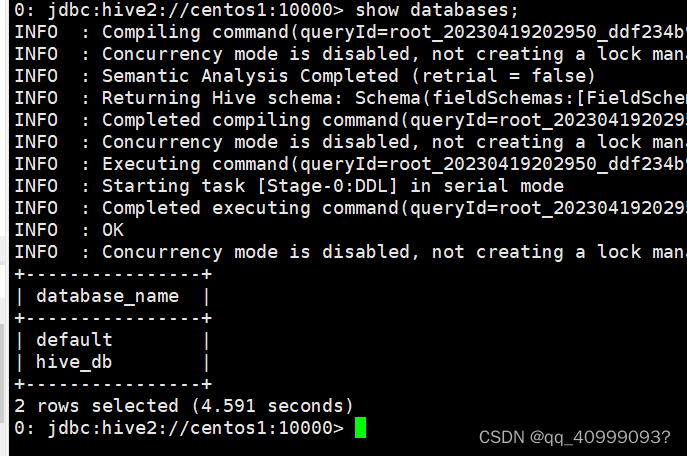
2.5.2 DataGrip图形化客户端
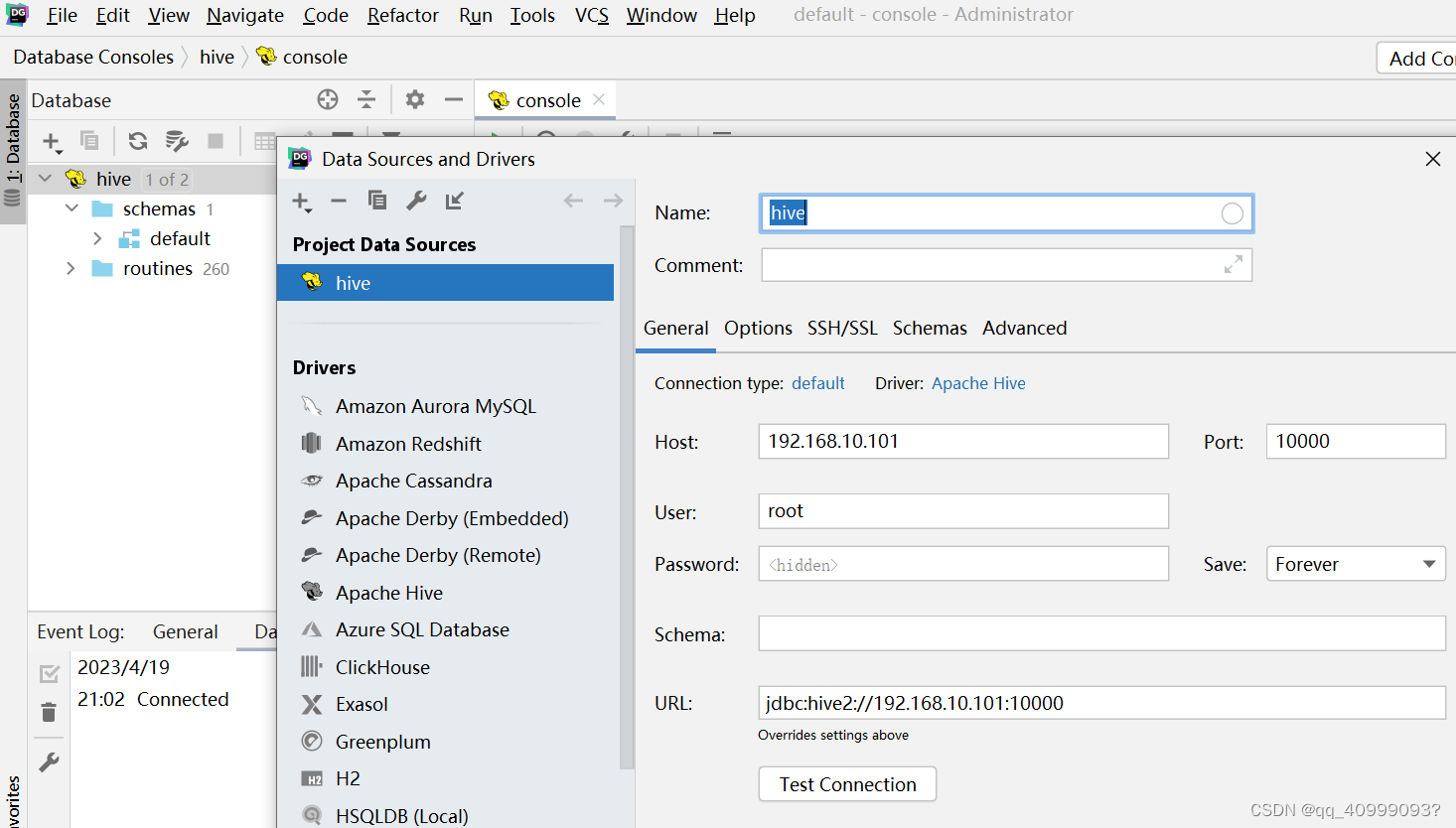
2.6 Hive常见属性配置
vim hive-site.xml
......
#数据仓库位置:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--在Hive提示符中包含当前数据库-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--在查询输出中打印列的名称-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
......
#日志文件 默认存放于/tmp/${username}/hive.log
vim hive-log4j2.properties
......
property.hive.log.dir = /home/hadoop
......






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结