您现在的位置是:首页 >其他 >【论文阅读笔记】Local Model Poisoning Attacks to Byzantine-Robust Federated Learning网站首页其他
【论文阅读笔记】Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
个人阅读笔记,如有错误欢迎指出!
会议: Usenix 2020 [1911.11815] Local Model Poisoning Attacks to Byzantine-Robust Federated Learning (arxiv.org)
问题:
模型攻击对拜占庭鲁棒性联邦学习的攻击效果尚未清楚
创新点:
1、基于不同防御方法,设计了具有针对性的模型攻击方式
2、概括了基于错误率以及基于损失函数的防御方法,测试了两种防御方法的效果。
方法:
攻击场景:training phase中对基于本地训练数据的模型在训练过程中进行攻击
攻击者的要求:控制部分参与模型中的训练参数
本地模型攻击:
主要挑战:如何将被攻击的本地模型进行改造并发送至服务器
方法:对投毒后的本地模型进行约束,转化为每轮中的优化问题
定义优化:
定义一个方向量,1表示当前梯度增加,-1表示当前梯度减小,其次定义攻击前的梯度与攻击后的梯度,那么优化问题的实质就是,使得攻击后的梯度与攻击前的梯度差别尽量大。
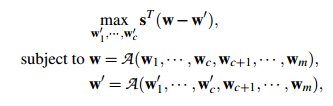
为未受到攻击时的模型,
为攻击后的模型,
为所有模型参数变化方向的列向量
攻击Krum
Krum原理是选择相近的模型作为全局模型,则可以约束使其他的本地模型都接近被攻击模型,从而达到使Krum选择攻击模型作为全局模型的目的
场景:full knowledge
优化问题的约束是高度非线性的,并且局部模型的搜索空间很大。为了求解需要做两个近似
对约束为:
,其中
为当前训练轮数中从聚合器收到的全局模型,
。具体描述了投毒模型与全局模型的差距。
令被控制的c-1个模型尽可能的接近,则只需要攻击模型与
良性模型的距离最小就会使其被Krum选中
优化目标如下:选取最大的值;使Krum选中攻击模型;攻击模型满足全局模型(previous)的距离约束;被控制的c-1个模型近似于攻击模型

上述优化问题的目标函数如下,其中为常数,
是模型参数个数,因此优化问题即为对
的优化
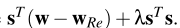
对于求解,首先定义其上界:

给定上界后,则可用二进制搜索寻找最优,先使用此上界求解模型
′的值,若没有被Krum选中,则将
减半继续。
场景:partial knowledge
攻击者不知道良性设备上的数据及模型以及模型改变的方向
方法:基于被攻击客户端的模型模拟良好设备的本地模型。
计算被攻击前的模型的均值
使用平均模型估计模型的变化方向:若收到的全局模型的参数大于本地模型的参数,则变化方向为1,否则为-1,定义估计为变化方向向量。
以被攻击前的本地模型视为良性客户端的本地模型,以此构建模型。
优化问题化简如下:如同上述方法求解模型,若最终结果仍不合适则添加另一个构建的模型进行求解。

攻击Trimmed mean
场景:full knowledge
为这一轮中良性模型中的第j个模型参数中的最大值,
为最小值
如果,则选取大于
的参数
作为c个受损工作设备上的第
个局部模型参数,否则选取任一小于
的数作为构建的模型参数。为避免被检测为异常值,
需要尽量接近
,即
取值范围为
、
中。实验中
取值为2。
场景:partial knowledge
同样,以被攻击前的模型作为良性客户端的模型以估计模型的变化方向
以被攻击前的模型作为良性客户端的模型估计以及
值。具体方法为计算均值以及标准差,并以作为高斯分布的参数,
估计为
大于
或者
,
估计为大于
或者
。
攻击Median
同Trimmed mean的攻击方法一致。
实验
数据集:MNIST,Fashion-MNIST,CH-MNIST。
采用的分类器:LR以及DNN
攻击方法比较:Gaussian attack、Back-gradient optimization based attack
联邦学习参数:

攻击效果比较:显著优于其他攻击算法

Krum在大部分情况下略于trimmed mean以及median
攻击的效果的错误率可能与数据维度有关。
与集中学习相比,联邦学习的错误率高于集中学习。与平均聚合相比,拜占庭鲁棒聚合规则提高了无攻击时的错误率,但平均聚合在存在攻击时模型无用。
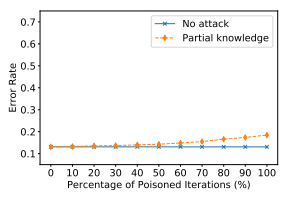
攻击者数量百分比对攻击效果的影响:一般情况下随着攻击者数量增加,攻击效果加强,标签反转攻击不明显,Gaussian attacks基本不变

非IID程度对联合学习的影响:图3显示了MNIST上不同程度的非IID的比较攻击的错误率。所有攻击(包括无攻击)的错误率随着非IID程度的增加而增加。

联邦学习参数对实验的影响:
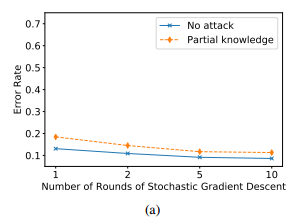
SGD训练回合数:随着回合数增加而下降
工作设备总数:攻击者固定为20%,工作设备越多攻击效果越好

每次迭代中选择的工作设备数量对我们的攻击的影响:
trimmed mean的参数:
越大模型被修剪越多,效果越差。
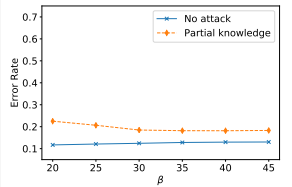
Krum中的:
越小,被投毒的模型距离越小,越可能被聚合器选中,攻击效果越好。

攻击的轮数:越多效果越好。

其他聚合策略:选择测试错误率最低的模型,攻击效果稍微降低但仍然有效。

聚合规则未知时:基于Krum的攻击能够转移到Trimmed mean以及median,基于Trimmed mean的攻击不适用与Krum,适用于median。

与反向梯度优化的攻击对比:本文的方法更加有效

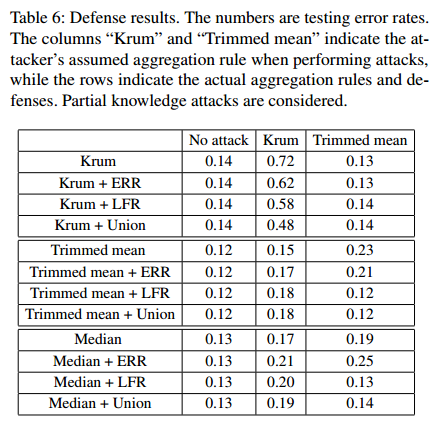
针对模型攻击的防御
防御方法:
基于错误率的拒绝防御(ERR)
防御方法:聚合器有用一个数据集用以检测错误率,计算包含客户端提交的模型以及去除提交的模型的模型错误率,分别记为以及
,则以
定义为模型对错误率的影响,聚合时删除拥有较大错误率影响的模型。
基于损失函数的拒绝防御(LFR)
防御方法:聚合器计算包含以及去除模型的交叉熵损失函数值以及
,将
定义为模型对全局模型的损失影响,聚合时删除拥有较大损失印象的模型。
上述两种方法联合(Union)
防御效果:LFR在大部分情况下比ERR有效,Union基本与LFR相同,LFR以及Union只能抵御部分防御,且进行部署防御时错误率将增加。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结