您现在的位置是:首页 >技术交流 >转载:卷积神经网络结构组成与解释网站首页技术交流
转载:卷积神经网络结构组成与解释
原文链接:卷积神经网络结构组成与解释
卷积神经网络是以卷积层为主的深度网路结构,网络结构包括有卷积层、激活层、BN层、池化层、FC层、损失层等。卷积操作是对图像和滤波矩阵做内积(元素相乘再求和)的操作。
1. 卷积层
常见的卷积操作如下:
| 卷积操作 | 解释 | 图解 |
| 标准卷积 | 一般采用3x3、5x5、7x7的卷积核进行卷积操作。 |
|
| 分组卷积 | 将输入特征图按通道均分为 x 组,然后对每一组进行常规卷积,最后再进行合并。 |
|
| 空洞卷积 | 为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,则内核元素之间没有插入空格,变为标准卷积。 |
|
| 深度可分离卷积 | 深度可分离卷积包括为逐通道卷积和逐点卷积两个过程。 |
(通道卷积,2D标准卷积)
|
| 反卷积 | 属于上采样过程,“反卷积”是将卷积核转换为稀疏矩阵后进行转置计算。 |
|
| 可变形卷积 | 指标准卷积操作中采样位置增加了一个偏移量offset,如此卷积核在训练过程中能扩展到很大的范围。 |
|
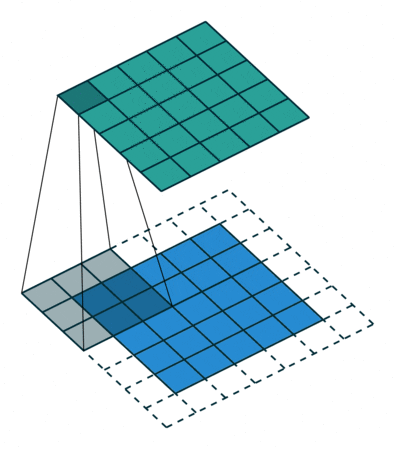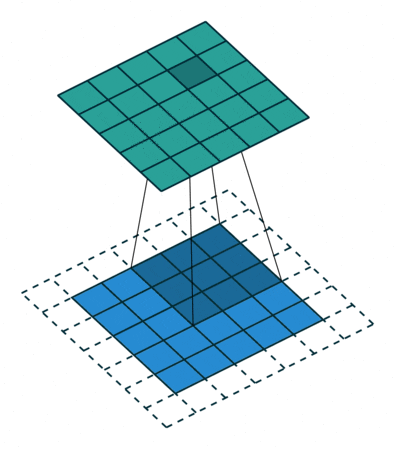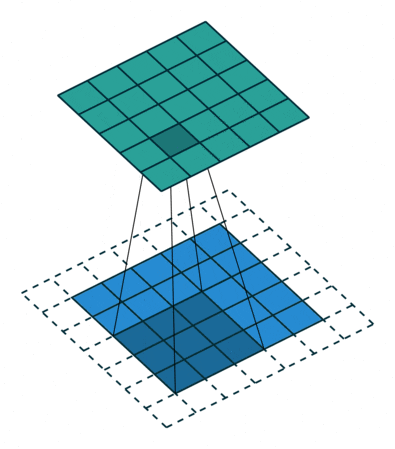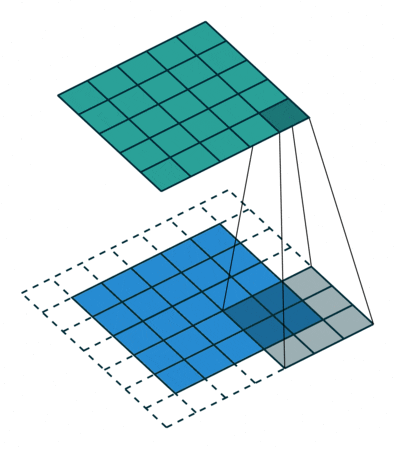
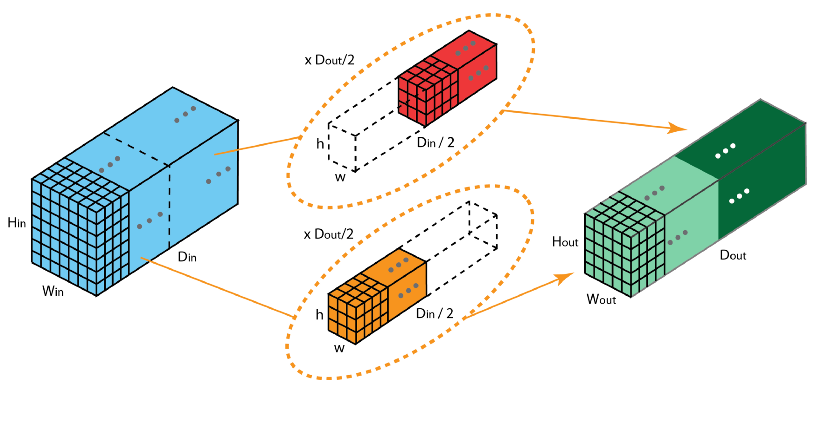

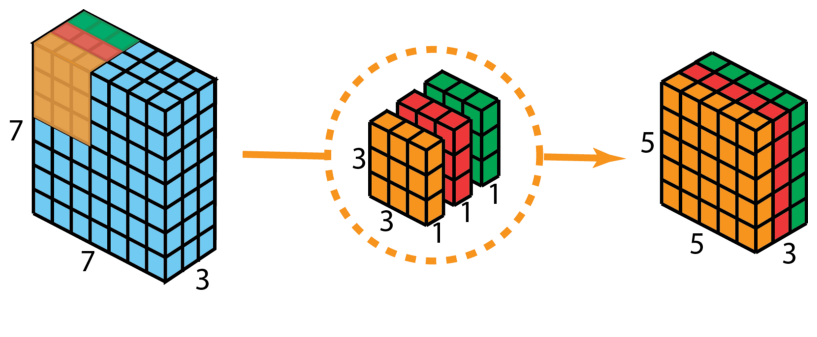



补充:
1 x 1卷积即用1 x 1的卷积核进行卷积操作,其作用在于升维与降维。升维操作常用于chennel为1(即是通道数为1)的情况下,降维操作常用于chennel为n(即是通道数为n)的情况下。
降维:通道数不变,数值改变。
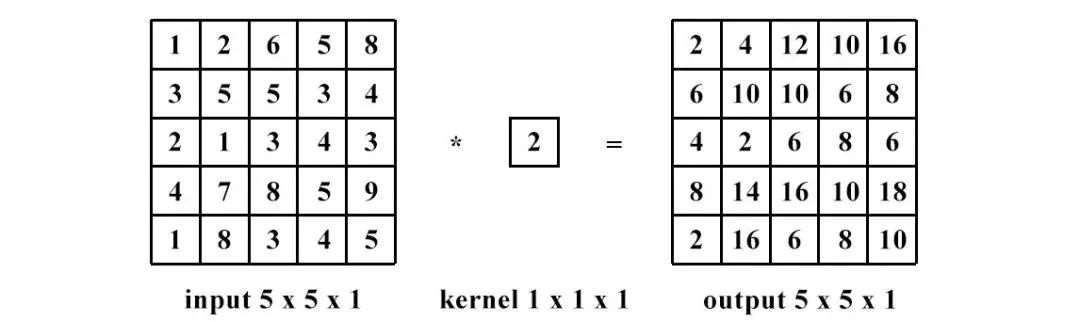
升维:通道数改变为kernel的数量(即为filters),运算本质可以看为全连接。
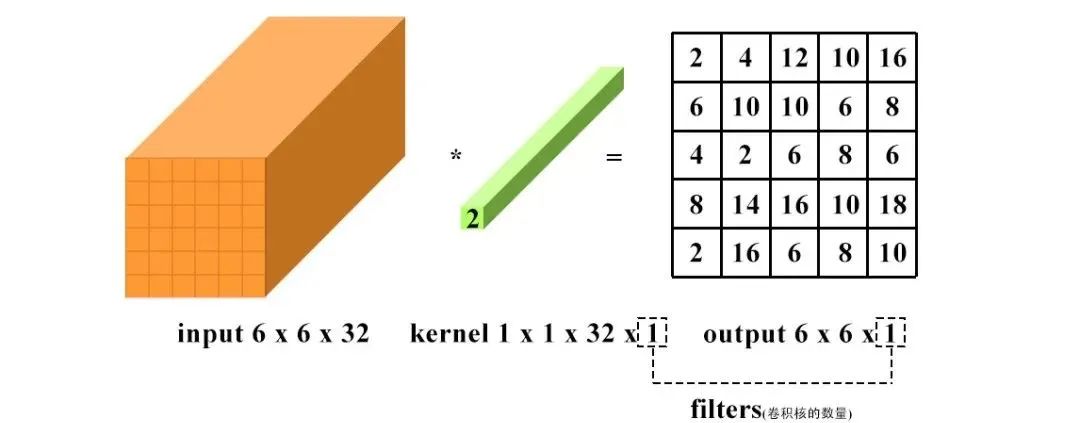
卷积计算在深度神经网络中的量是极大的,压缩卷积计算量的主要方法如下:
| 序号 | 方法 |
| 1 | 采用多个3x3卷积核代替大卷积核(如用两个3 x 3的卷积核代替5 x 5的卷积核) |
| 2 | 采用深度可分离卷积(分组卷积) |
| 3 | 通道Shuffle |
| 4 | Pooling层 |
| 5 | Stride = 2 |
| 6 | 等等 |
2. 激活层
介绍:为了提升网络的非线性能力,以提高网络的表达能力。每个卷积层后都会跟一个激活层。激活函数主要分为饱和激活函数(sigmoid、tanh)与非饱和激活函数(ReLU、Leakly ReLU、ELU、PReLU、RReLU)。非饱和激活函数能够解决梯度消失的问题,能够加快收敛速度。
常用函数:ReLU函数、Leakly ReLU函数、ELU函数等

ReLU函数

Leakly ReLU函数

ELU函数
3. BN层(BatchNorm)
介绍:通过一定的规范化手段,把每层神经网络任意神经元的输入值的分布强行拉回到均值为0,方差为1的标准正态分布。BatchNorm是归一化的一种手段,会减小图像之间的绝对差异,突出相对差异,加快训练速度。但不适用于image-to-image以及对噪声明感的任务中。
常用函数:BatchNorm2d
pytorch用法:nn.BatchNorm2d(num_features, eps, momentum, affine)
num_features:一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量。
eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5。momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数)。
affine:当设为true时,会给定可以学习的系数矩阵gamma和beta。
4. 池化层(pooling)
介绍:pooling一方面使特征图变小,简化网络计算复杂度。一方面通过多次池化压缩特征,提取主要特征。属于下采样过程。
常用函数:Max Pooling(最大池化)、Average Pooling(平均池化)等。
MaxPooling 与 AvgPooling用法:1. 当需综合特征图上的所有信息做相应决策时,通常使用AvgPooling,例如在图像分割领域中用Global AvgPooling来获取全局上下文信息;在图像分类中在最后几层中会使用AvgPooling。2. 在图像分割/目标检测/图像分类前面几层,由于图像包含较多的噪声和目标处理无关的信息,因此在前几层会使用MaxPooling去除无效信息。

补充:上采样层重置图像大小为上采样过程,如Resize,双线性插值直接缩放,类似于图像缩放,概念可见最邻近插值算法和双线性插值算法。实现函数有nn.functional.interpolate(input, size = None, scale_factor = None, mode = 'nearest', align_corners = None)和nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, output_padding = 0, bias = True)
5. FC层(全连接层)
介绍:连接所有的特征,将输出值送给分类器。主要是对前层的特征进行一个加权和(卷积层是将数据输入映射到隐层特征空间),将特征空间通过线性变换映射到样本标记空间(label)。全连接层可以通过1 x 1卷机+global average pooling代替。可以通过全连接层参数冗余,全连接层参数和尺寸相关。
常用函数:nn.Linear(in_features, out_features, bias)

补充:分类器包括线性分类器与非线性分类器。
| 分类器 | 介绍 | 常见种类 | 优缺点 |
| 线性分类器 | 线性分类器就是用一个“超平面”将正、负样本隔离开 | LR、Softmax、贝叶斯分类、单层感知机、线性回归、SVM(线性核)等 | 线性分类器速度快、编程方便且便于理解,但是拟合能力低 |
| 非线性分类器 | 非线性分类器就是用一个“超曲面”或者多个超平(曲)面的组合将正、负样本隔离开(即,不属于线性的分类器) | 决策树、RF、GBDT、多层感知机、SVM(高斯核)等 | 非线性分类器拟合能力强但是编程实现较复杂,理解难度大 |
6. 损失层
介绍:设置一个损失函数用来比较网络的输出和目标值,通过最小化损失来驱动网络的训练。网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算。
常用函数:分类问题损失(离散值:分类问题、分割问题):nn.BCELoss、nn.CrossEntropyLoss等。回归问题损失(连续值:推测问题、回归分类问题):nn.L1Loss、nn.MSELoss、nn.SmoothL1Loss等。
7. Dropout层
介绍:在不同的训练过程中随机扔掉一部分神经元,以防止过拟合,一般用在全连接层。在测试过程中不使用随机失活,所有的神经元都激活。
常用函数:nn.dropout
8. 优化器
介绍:为了更高效的优化网络结构(损失函数最小),即是网络的优化策略,主要方法如下:
| 解释 | 优化器种类 | 特点 |
| 基于梯度下降原则(均使用梯度下降算法对网络权重进行更新,区别在于使用的样本数量不同) | GD(梯度下降); SGD(随机梯度下降,面向一个样本); BGD(批量梯度下降,面向全部样本); MBGD(小批量梯度下降,面向小批量样本) | 引入随机性和噪声 |
| 基于动量原则(根据局部历史梯度对当前梯度进行平滑) | Momentum(动量法); NAG(Nesterov Accelerated Gradient) | 加入动量原则,具有加速梯度下降的作用 |
| 自适应学习率(对于不同参数使用不同的自适应学习率;Adagrad使用梯度平方和、Adadelta和RMSprop使用梯度一阶指数平滑,RMSprop是Adadelta的一种特殊形式、Adam吸收了Momentum和RMSprop的优点改进了梯度计算方式和学习率) | Adagrad; Adadelta; RMSprop; Adam | 自适应学习 |
常用优化器为Adam,用法为:torch.optim.Adam。
补充:卷积神经网络正则化是为减小方差,减轻过拟合的策略,方法有:L1正则(参数绝对值的和); L2正则(参数的平方和,weight_decay:权重衰退)。
9. 学习率
介绍:学习率作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及合适收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
常用函数:torch.optim.lr_scheduler; ExponentialLR; ReduceLROnplateau; CyclicLR等。
卷积神经网络的常见结构
常见结构有:跳连结构(ResNet)、并行结构(Inception V1-V4即GoogLeNet)、轻量型结构(MobileNetV1)、多分支结构(SiameseNet; TripletNet; QuadrupletNet; 多任务网络等)、Attention结构(ResNet+Attention)
| 结构 | 介绍与特点 | 图示 |
| 跳连结构(代表:ResNet) | 2015年何恺明团队提出。引入跳连的结构来防止梯度消失问题,今儿可以进一步加大网络深度。扩展结构有:ResNeXt、DenseNet、WideResNet、ResNet In ResNet、Inception-ResNet等 |
|
| 并行结构(代表:Inception V1-V4) | 2014年Google团队提出。不仅强调网络的深度,还考虑网络的宽度。其使用1×1的卷积来进行升降维,在多个尺寸上同时进行卷积再聚合。其次利用稀疏矩阵分解成密集矩阵计算的原理加快收敛速度。 |
|
| 轻量型结构(代表:MobileNetV1) | 2017年Google团队提出。为了设计能够用于移动端的网络结构,使用Depth-wise Separable Convolution的卷积方式代替传统卷积方式,以达到减少网络权值参数的目的。扩展结构有:MobileNetV2、MobileNetV3、SqueezeNet、ShuffleNet V1、ShuffleNet V2等 |
|
| 多分支结构(代表:TripletNet) | 基于多个特征提取方法提出,通过比较距离来学习有用的变量。该网络由3个具有相同前馈网络(共享参数)组成的,需要输入是3个样本,一个正样本和两个负样本,或者一个负样本和两个正样本。训练的目标是让相同类别之间的距离竟可能的小,让不同的类别之间距离竟可能的大。常用于人脸识别。 |
|
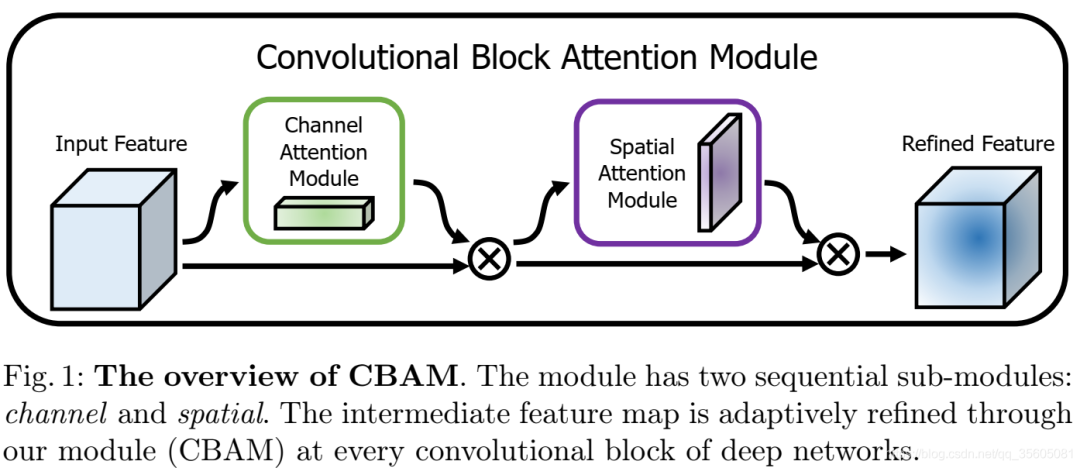
| Attention结构(代表:ResNet+Attention) | 对于全局信息,注意力机制会重点关注一些特殊的目标区域,也就是注意力焦点,进而利用有限的注意力资源对信息进行筛选,提高信息处理的准确性和效率。注意力机制有Soft-Attention和Hard-Attention区分,可以作用在特征图上、尺度空间上、channel尺度上和不同时刻历史特征上等。 |
|




参考资料链接:
入门Pytorch,从搭建一个简单的神经网络模型开始!清华大佬手把手带你基于Pytorch搭建自己的神经网络模型!_哔哩哔哩_bilibili






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结