您现在的位置是:首页 >学无止境 >【图像任务】Transformer系列.3网站首页学无止境
【图像任务】Transformer系列.3
本文介绍3篇改进Transformer以实现不同图像任务的工作:少样本医学图像分割CAT-Net(arXiv2023),高效图像重建等任务GRL(CVPR2023),轻量视觉Transformer中的局部信息思考CloFormer(arXiv2023)。
Few Shot Medical Image Segmentation with Cross Attention Transformer, arXiv2023
解读:2023港科大新作 | 新颖注意力机制有效提升医学图像小样本语义分割精度!
论文:https://arxiv.org/abs/2303.13867
代码:暂未开源
介绍
在深度学习医学图像分割领域,训练一个性能强,可以大规模部署落地的模型,往往需要大量手动标注的数据进行监督训练,其中花费的成本是非常高的。为了解决这一挑战,少样本学习(few-shot)技术有潜力从有限的几个sample中学习新类别的能力。
大多数few-shot分割方法都在学习如何学习(旨在学习元学习器),根据support图像及其相应的分割标签的知识预测query图像的分割,核心是:如何有效地将知识从support图像传递到query图像。现有的少样本分割方法主要集中在以下两个方面:
-
如何学习一个元学习器
-
如何更好地将知识从
support图像传递到query图像
尽管基于原型的方法效果已经不错,但它们通常忽略了训练过程中support和query特征之间的交互。
因此,本文提出了一种名为CAT-Net的新型网络结构,其基于交叉注意力Transformer,可以更好地捕捉support图像和query图像之间的相关性,促进support和query特征之间的相互作用,同时减少无用像素信息,提高特征表达能力和分割性能;此外,本文还提出了一个迭代训练框架,将先前的support分割结果反馈到注意力Transformer中,以有效增强并细化特征和分割结果。
CAT-Net网络

CAT-Net网络框架图,主要由三部分组成:
- 带有mask的特征提取
MIFE子网络,用于提取初始query和support特征以及query mask; - 交叉mask注意力
Transformer模块CMAT,其中query和support特征相互促进,从而提高query预测的准确性; - 迭代细化框架,顺序应用
CMAT模块以持续促进分割性能,整个框架以端到端的方式进行训练。
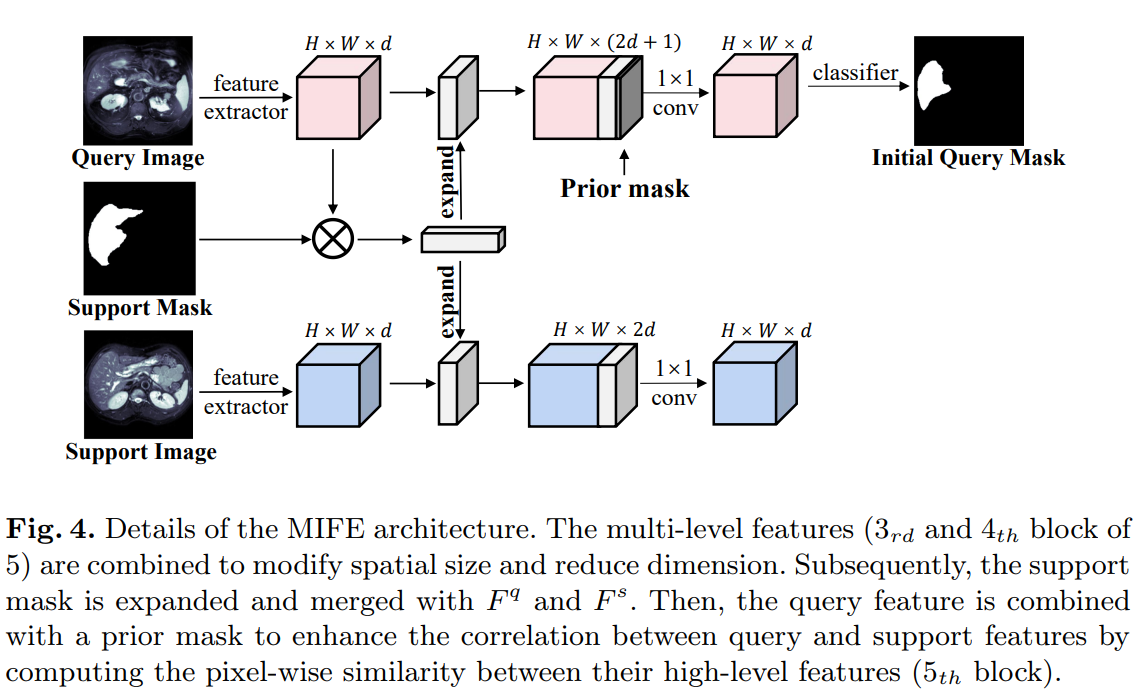
Mask Incorporated Feature Extraction(MIFE)
MIFE子网络接收query和support图像作为输入,生成它们各自的特征,以及support mask。然后,使用一个简单的分类器来预测query图像的分割结果。如图所示,
- 首先使用一个特征提取器(即ResNet-50)将query和support图像对Iq和Is映射到特征空间中,分别产生query图像的多层特征图Fq和support图像的特征图Fs。
- 将support mask与Fs进行池化,扩展后与Fq和Fs进行拼接。
- 将一个prior mask进一步与query特征进行拼接,通过像素级相似度图来增强查询和支持特征之间的相关性。
- 使用一个简单的分类器来处理查询特征,得到query mask。
Cross Masked Attention Transformer (CMAT)
CMAT模块包括三个主要组成部分:自注意力模块、交叉掩码注意力模块,和原型分割模块。其中,
- 自注意力模块用于提取查询query特征和支持support特征中的全局信息;
- 交叉掩码注意力模块用于在传递前景信息的同时消除冗余的背景信息;
- 原型分割模块用于生成查询图像的最终预测结果。
Iterative Refinement framework
该模块的设计目的是优化查询和支持特征以及查询分割掩模。因此可通过迭代优化的思路进行精细化分割,第i次迭代后的结果由以下公式给出:
![]()
每个步骤的细分可表示如下:
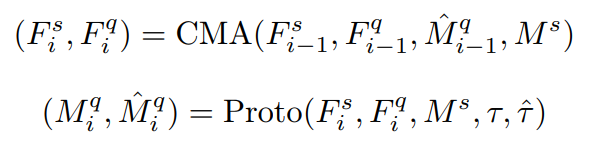
其中CMA(·)表示自注意力和交叉掩码注意力模块,Proto(·)代表原型分割模块,该公式表示通过多次迭代应用CMA和Proto模块,来获得增强的特征和优化的分割结果。
实验

消融实验
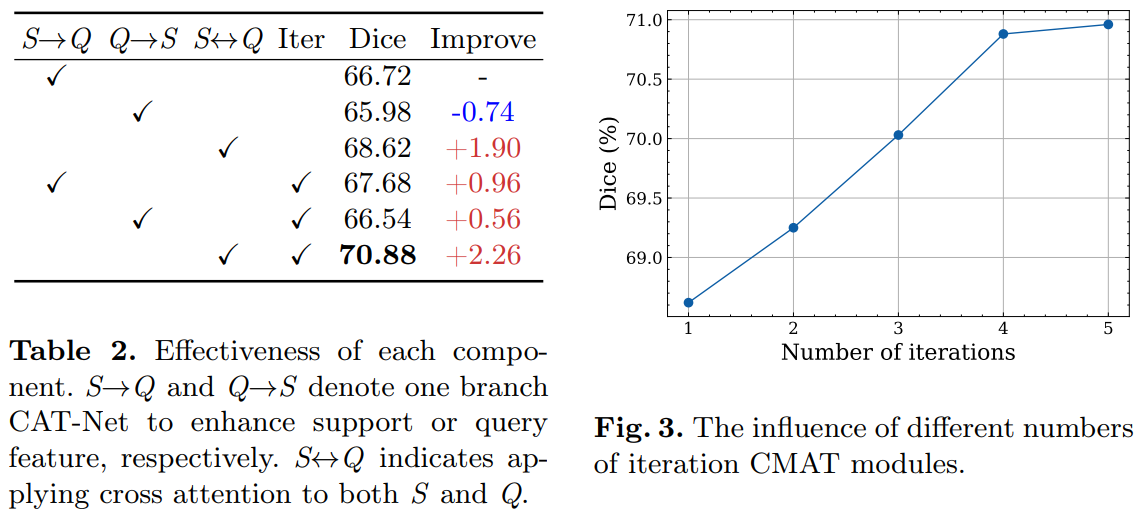
Table2 验证了网络中各个组件的有效性:S→Q和Q→S表示CAT-Net中用于增强支持或查询特征的一条支路,而S↔Q表示将交叉注意力应用于S和Q。
Table3 在不同迭代次数下使用CMAT模块的影响,增加模块数量可以提高性能,在使用5个模块时,Dice系数最大提高了2.26%。使用4个CMAT模块,效率和性能之间取得平衡。
Efficient and Explicit Modelling of Image Hierarchies for Image Restoration , CVPR2023
解读:CVPR'2023 即插即用系列! | 一种轻量高效的自注意力机制助力图像恢复网络问鼎 SOTA! (qq.com)
论文:https://arxiv.org/abs/2303.00748
代码:https://github.com/ofsoundof/GRL-Image-Restoration.git
介绍
图像恢复旨在从低质量图像恢复出高质量图像,这些低质量图像通常是由于图像退化过程(如模糊、降采样、噪声引入和JPEG压缩)导致的。因为在图像退化过程中,其重要内容信息缺失,所以图像恢复是一个具有挑战性的逆过程。因此为了恢复高质量图像,应该充分利用退化图像中展现出的丰富信息。

自然图像包含全局、区域和局部范围内的一系列特征,这些特征可以被深度神经网络用于图像恢复。 局部特征通常是一些边缘和颜色特征,由于其只跨度几个像素,所以可以使用小卷积核(例如3 x 3)进行建模捕获;对于区域特征,其通常跨度数十个像素,这一窗口区域特征通常可以覆盖一些小物体和大物体的某个部分(如上图1的粉色框),由于区域特征范围更大,因此可选择使用大卷积核进行建模,但其参数量和计算量未免过大且低效,因此带有窗口注意力机制的Transformer会是更好的选择;除了局部和区域特征之外,某些特征具有全局跨度性(图1中的青色矩形):主要体现在对称性和多尺度模式重复性(图1a),同一尺度的纹理相似性(图1b),以及大物体内容结构相似性和一致性(图1c),为了建模处理这个范围的特征,需要网络具备全局图像理解的能力。
局部和区域范围特征可以很好的建模捕获,但全局特征的建模存在两个主要的挑战:
-
首先,现有的基于卷积和窗口注意力的图像恢复网络不能通过使用单个计算模块来明确捕获长距离依赖关系,因此全局图像理解主要通过将特征通过重复的计算模块进行逐步传播来实现。
-
其次,当图像的分辨率不断提高,长距离依赖建模面临计算负担的挑战。
上述讨论引出了一系列研究问题:
-
如何高效地在高维图像中对全局范围特征进行建模以进行图像恢复?
-
如何通过单个计算模块明确地建模图像层次结构信息(局部、区域、全局),以进行高维图像恢复?
-
这种联合建模如何能够在不同的图像恢复任务中带来统一的性能改进?
为此,本文围绕以上三个研究问题,逐一提出解决方案:
- 首先,本文提出了一种基于锚点的条纹自注意力机制用于实现全局范围依赖性建模;
- 其次,提出了一种新的
Transformer网络GRL用于在单个计算模块中明确地模拟全局,区域和局部范围的依赖关系; - 最后,所提出的
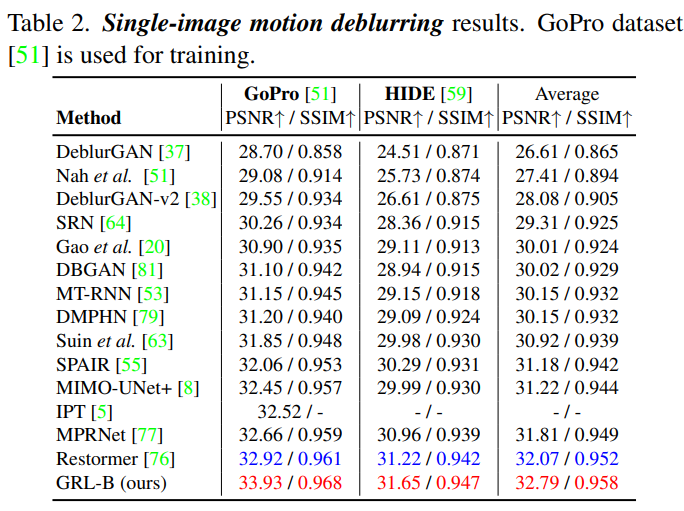
GRL网络在七类图像恢复任务中(图像超分,去噪,JPEG压缩伪影去除,去马赛克,真实图像超分,单图运动去模糊,散焦去模糊)全部表现SOTA!

GRL网络
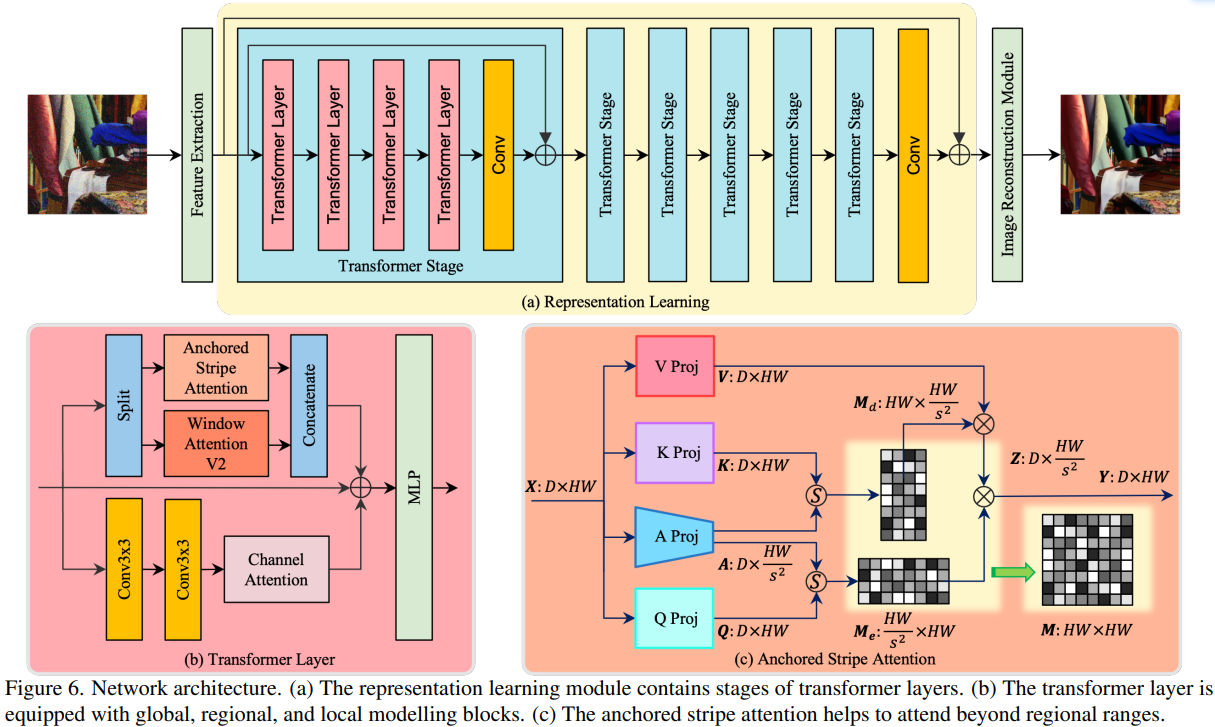
上图(a)展示了所提出的GRL网络架构图,它由多个Transformer Layer组成。上图(b)展示了Transformer Layer计算模块,它由三个子模块组成并用于建模全局,区域和局部图像结构特征,其中基于锚点的条纹自注意力机制Anchored Stripe Attention用于建模全局图像结构特征,基于窗口的自注意力机制Window Attention V2用于建模区域特征,而两个串联的3 x 3卷积再接一个通道注意力Channel Attention可用于建模出高效的局部特征。 上图(c) 展示了基于锚点的条纹自注意力机制结构图,该注意力机制可以帮助网络捕获超越区域范围(全局)的图像结构特征。
Anchored Stripe Attention
Transformer自注意力机制架构虽然可以很好的建模出长远距离依赖关系并以此捕获全局特征信息,但图像tokens数量众多导致计算量巨大。为了降低计算复杂度,所以可以在窗口区域进行自注意力,但该类基于窗口的自注意力机制受限于窗口大小,仅能捕获基于窗口区域的上下文特征信息。那么这就引出一个问题:如何在低计算量情况下,建模出超出窗口区域范围的特征呢?

上图(a)和(b)是来自两个不同分辨率的相同图片,(a)中蓝色的像素点和(b)中红色的像素点都取自相同的一个位置。图(c)表示了蓝色像素点和其它像素点的注意力图;图(d)表示了红色像素点和其它像素点的注意力图。图(c)和图(d)注意力图是非常相近的,这就是本文所说的跨尺度相似性。
通过对具有小分辨率的图像进行自注意力(小分辨率图像具有更少的tokens)来达到大分辨率图像进行自注意力的效果(基于跨尺度相似性原理),这就大大降低了计算量,而又可以有效建模出超越窗口区域范围的特征(全局特征)。
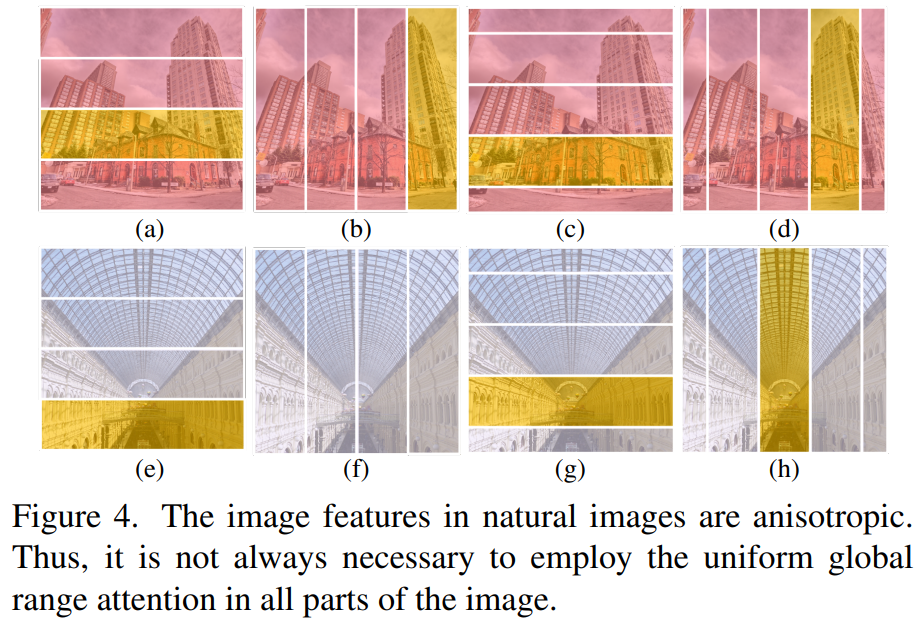
为了进一步降低计算量,作者发现了自然图像另一个重要的特性:自然图像的特征通常以非各向同性的方式出现,如上图所示,(c)和(d)中的单个物体、(h)中的多尺度相似性、(e)和(g)中的对称性等。因此,全局范围的各向同性注意力对于捕捉非各向同性图像特征是多余的。基于此,文章提出了在非各向同性条纹内进行注意力处理的方法,该注意力机制包括四种模式:水平条纹、垂直条纹、平移水平条纹和平移垂直条纹。水平和垂直条纹的注意力机制可以在Transformer网络中交替使用。通过这种注意力方式,可以在保持全局范围建模能力的同时,降低全局自注意力计算的复杂度。
因此,再结合锚点的概念,提出了锚定条纹自注意力。对于这种注意力机制,利用引入的锚点在垂直和水平条纹内进行高效自注意力计算。

实验
更多见论文

关键代码
grl.py
# https://github.com/ofsoundof/GRL-Image-Restoration/blob/main/models/common/mixed_attn_block_efficient.py
class Attention(ABC, nn.Module):
def __init__(self):
super(Attention, self).__init__()
def attn(self, q, k, v, attn_transform, table, index, mask, reshape=True):
# q, k, v: # nW*B, H, wh*ww, dim
# cosine attention map
B_, _, H, head_dim = q.shape
if self.euclidean_dist:
# print("use euclidean distance")
attn = torch.norm(q.unsqueeze(-2) - k.unsqueeze(-3), dim=-1)
else:
attn = F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1)
attn = attn_transform(attn, table, index, mask)
# attention
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = attn @ v # B_, H, N1, head_dim
if reshape:
x = x.transpose(1, 2).reshape(B_, -1, H * head_dim)
# B_, N, C
return x
class WindowAttention(Attention):
r"""Window attention. QKV is the input to the forward method.
Args:
num_heads (int): Number of attention heads.
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
pretrained_window_size (tuple[int]): The height and width of the window in pre-training.
"""
def __init__(
self,
input_resolution,
window_size,
num_heads,
window_shift=False,
attn_drop=0.0,
pretrained_window_size=[0, 0],
args=None,
):
super(WindowAttention, self).__init__()
self.input_resolution = input_resolution
self.window_size = window_size
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.shift_size = window_size[0] // 2 if window_shift else 0
self.euclidean_dist = args.euclidean_dist
self.attn_transform = AffineTransform(num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, qkv, x_size, table, index, mask):
"""
Args:
qkv: input QKV features with shape of (B, L, 3C)
x_size: use x_size to determine whether the relative positional bias table and index
need to be regenerated.
"""
H, W = x_size
B, L, C = qkv.shape
qkv = qkv.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
qkv = torch.roll(
qkv, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)
)
# partition windows
qkv = window_partition(qkv, self.window_size) # nW*B, wh, ww, C
qkv = qkv.view(-1, prod(self.window_size), C) # nW*B, wh*ww, C
B_, N, _ = qkv.shape
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # nW*B, H, wh*ww, dim
# attention
x = self.attn(q, k, v, self.attn_transform, table, index, mask)
# merge windows
x = x.view(-1, *self.window_size, C // 3)
x = window_reverse(x, self.window_size, x_size) # B, H, W, C/3
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
x = x.view(B, L, C // 3)
return x
def extra_repr(self) -> str:
return (
f"window_size={self.window_size}, shift_size={self.shift_size}, "
f"pretrained_window_size={self.pretrained_window_size}, num_heads={self.num_heads}"
)
def flops(self, N):
pass
class AnchorStripeAttention(Attention):
r"""Stripe attention
Args:
stripe_size (tuple[int]): The height and width of the stripe.
num_heads (int): Number of attention heads.
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
pretrained_stripe_size (tuple[int]): The height and width of the stripe in pre-training.
"""
def __init__(
self,
input_resolution,
stripe_size,
stripe_groups,
stripe_shift,
num_heads,
attn_drop=0.0,
pretrained_stripe_size=[0, 0],
anchor_window_down_factor=1,
args=None,
):
super(AnchorStripeAttention, self).__init__()
self.input_resolution = input_resolution
self.stripe_size = stripe_size # Wh, Ww
self.stripe_groups = stripe_groups
self.stripe_shift = stripe_shift
self.num_heads = num_heads
self.pretrained_stripe_size = pretrained_stripe_size
self.anchor_window_down_factor = anchor_window_down_factor
self.euclidean_dist = args.euclidean_dist
self.attn_transform1 = AffineTransform(num_heads)
self.attn_transform2 = AffineTransform(num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(
self, qkv, anchor, x_size, table, index_a2w, index_w2a, mask_a2w, mask_w2a
):
"""
Args:
qkv: input features with shape of (B, L, C)
anchor:
x_size: use stripe_size to determine whether the relative positional bias table and index
need to be regenerated.
"""
H, W = x_size
B, L, C = qkv.shape
qkv = qkv.view(B, H, W, C)
stripe_size, shift_size = _get_stripe_info(
self.stripe_size, self.stripe_groups, self.stripe_shift, x_size
)
anchor_stripe_size = [s // self.anchor_window_down_factor for s in stripe_size]
anchor_shift_size = [s // self.anchor_window_down_factor for s in shift_size]
# cyclic shift
if self.stripe_shift:
qkv = torch.roll(qkv, shifts=(-shift_size[0], -shift_size[1]), dims=(1, 2))
anchor = torch.roll(
anchor,
shifts=(-anchor_shift_size[0], -anchor_shift_size[1]),
dims=(1, 2),
)
# partition windows
qkv = window_partition(qkv, stripe_size) # nW*B, wh, ww, C
qkv = qkv.view(-1, prod(stripe_size), C) # nW*B, wh*ww, C
anchor = window_partition(anchor, anchor_stripe_size)
anchor = anchor.view(-1, prod(anchor_stripe_size), C // 3)
B_, N1, _ = qkv.shape
N2 = anchor.shape[1]
qkv = qkv.reshape(B_, N1, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
anchor = anchor.reshape(B_, N2, self.num_heads, -1).permute(0, 2, 1, 3)
# attention
x = self.attn(
anchor, k, v, self.attn_transform1, table, index_a2w, mask_a2w, False
)
x = self.attn(q, anchor, x, self.attn_transform2, table, index_w2a, mask_w2a)
# merge windows
x = x.view(B_, *stripe_size, C // 3)
x = window_reverse(x, stripe_size, x_size) # B H' W' C
# reverse the shift
if self.stripe_shift:
x = torch.roll(x, shifts=shift_size, dims=(1, 2))
x = x.view(B, H * W, C // 3)
return x
def extra_repr(self) -> str:
return (
f"stripe_size={self.stripe_size}, stripe_groups={self.stripe_groups}, stripe_shift={self.stripe_shift}, "
f"pretrained_stripe_size={self.pretrained_stripe_size}, num_heads={self.num_heads}, anchor_window_down_factor={self.anchor_window_down_factor}"
)
def flops(self, N):
pass
class MixedAttention(nn.Module):
r"""Mixed window attention and stripe attention
Args:
dim (int): Number of input channels.
stripe_size (tuple[int]): The height and width of the stripe.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
pretrained_stripe_size (tuple[int]): The height and width of the stripe in pre-training.
"""
def __init__(
self,
dim,
input_resolution,
num_heads_w,
num_heads_s,
window_size,
window_shift,
stripe_size,
stripe_groups,
stripe_shift,
qkv_bias=True,
qkv_proj_type="linear",
anchor_proj_type="separable_conv",
anchor_one_stage=True,
anchor_window_down_factor=1,
attn_drop=0.0,
proj_drop=0.0,
pretrained_window_size=[0, 0],
pretrained_stripe_size=[0, 0],
args=None,
):
super(MixedAttention, self).__init__()
self.dim = dim
self.input_resolution = input_resolution
self.args = args
# print(args)
self.qkv = QKVProjection(dim, qkv_bias, qkv_proj_type, args)
# anchor is only used for stripe attention
self.anchor = AnchorProjection(
dim, anchor_proj_type, anchor_one_stage, anchor_window_down_factor, args
)
self.window_attn = WindowAttention(
input_resolution,
window_size,
num_heads_w,
window_shift,
attn_drop,
pretrained_window_size,
args,
)
self.stripe_attn = AnchorStripeAttention(
input_resolution,
stripe_size,
stripe_groups,
stripe_shift,
num_heads_s,
attn_drop,
pretrained_stripe_size,
anchor_window_down_factor,
args,
)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, x_size, table_index_mask):
"""
Args:
x: input features with shape of (B, L, C)
stripe_size: use stripe_size to determine whether the relative positional bias table and index
need to be regenerated.
"""
B, L, C = x.shape
# qkv projection
qkv = self.qkv(x, x_size)
qkv_window, qkv_stripe = torch.split(qkv, C * 3 // 2, dim=-1)
# anchor projection
anchor = self.anchor(x, x_size)
# attention
x_window = self.window_attn(
qkv_window, x_size, *self._get_table_index_mask(table_index_mask, True)
)
x_stripe = self.stripe_attn(
qkv_stripe,
anchor,
x_size,
*self._get_table_index_mask(table_index_mask, False),
)
x = torch.cat([x_window, x_stripe], dim=-1)
# output projection
x = self.proj(x)
x = self.proj_drop(x)
return x
def _get_table_index_mask(self, table_index_mask, window_attn=True):
if window_attn:
return (
table_index_mask["table_w"],
table_index_mask["index_w"],
table_index_mask["mask_w"],
)
else:
return (
table_index_mask["table_s"],
table_index_mask["index_a2w"],
table_index_mask["index_w2a"],
table_index_mask["mask_a2w"],
table_index_mask["mask_w2a"],
)
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}"
def flops(self, N):
passRethinking Local Perception in Lightweight Vision Transformer, arXiv2023
解读:即插即用系列 | 清华提出最新移动端高效网络架构 CloFormer: 注意力机制与卷积的完美融合! (qq.com)
论文:https://arxiv.org/abs/2303.17803
代码:https://github.com/qhfan/CloFormer
介绍
本文主要介绍了一种轻量级Vision Transformer架构——CloFormer,用于处理移动端的图像任务。CloFormer 引入了 AttnConv,这是一种结合了注意力机制和卷积运算的模块,能够捕捉高频的局部信息。相比于传统的卷积操作,AttnConv 使用共享权重和上下文感知权重,能够更好地处理图像中不同位置之间的关系。实验结果表明,CloFormer 在图像分类、目标检测和语义分割任务中具有优越的性能。
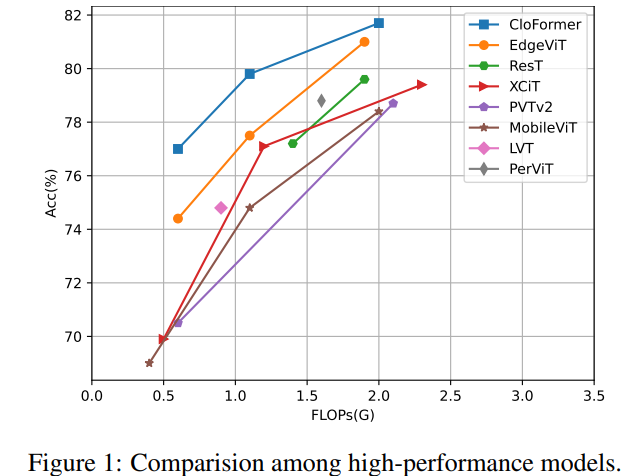
现有很多工作聚焦于探索轻量级的视觉变换器。本文从频域编码的角度认为,现有轻量级模型中,大多只关注设计稀疏注意力,以有效地处理低频全局信息,而使用相对简单的方法处理高频局部信息。具体而言,大多数模型如 EdgeViT 和 MobileViT,只是简单使用原始卷积提取局部表示,仅使用卷积中的全局共享权重处理高频本地信息。其他方法,如 LVT ,则是首先将标记展开到窗口中,然后使用窗口内的注意力获得高频信息。这些方法仅使用特定于每个 Token 的上下文感知权重进行局部感知。
虽然上述轻量级模型在多个数据集上效果显著,但没有一种方法尝试设计更有效的方法,即利用共享和上下文感知权重的优势来处理高频局部信息。基于共享权重的方法,如传统的卷积神经网络,具有平移等变性的特征。与它们不同,基于上下文感知权重的方法,如 LVT 和 NAT,具有可以随输入内容变化的权重。这两种类型的权重在局部感知中都有自己的优势。
受此启发,本文设计了一种轻量级视觉变换器——CloFormer,其利用了上下文感知的局部增强。特别地,CloFormer 采用了双分支设计结构。
局部分支
在局部分支中,本文引入了一个精心设计的 AttnConv,一种简单而有效的卷积操作符,它采用了注意力机制的风格。所提出的 AttnConv 有效地融合了共享权重和上下文感知权重,以聚合高频的局部信息。具体地,AttnConv 首先使用深度卷积(DWconv)提取局部表示,其中 DWconv 具有共享权重。然后,其使用上下文感知权重来增强局部特征。与 Non-Local 等生成上下文感知权重的方法不同,AttnConv 使用门控机制生成上下文感知权重,引入了比常用的注意力机制更强的非线性。此外,AttnConv 将卷积算子应用于 Query 和 Key 以聚合局部信息,然后计算 Q 和 K 的哈达玛积,并对结果进行一系列线性或非线性变换,生成范围在 [-1,1] 之间的上下文感知权重。值得注意的是,AttnConv 继承了卷积的平移等变性,因为它的所有操作都基于卷积。
全局分支
在全局分支中则使用了传统的注意力机制,但对 K 和 V 进行了下采样以减少计算量,从而捕捉低频全局信息。最后,CloFormer 通过简单的方法将局部分支和全局分支的输出进行融合,从而使模型能够同时捕捉高频和低频信息。总的来说,CloFormer 的设计能够同时发挥共享权重和上下文感知权重的优势,提高其局部感知的能力,使其在图像分类、物体检测和语义分割等多个视觉任务上均取得了优异的性能。
CloFormer网络
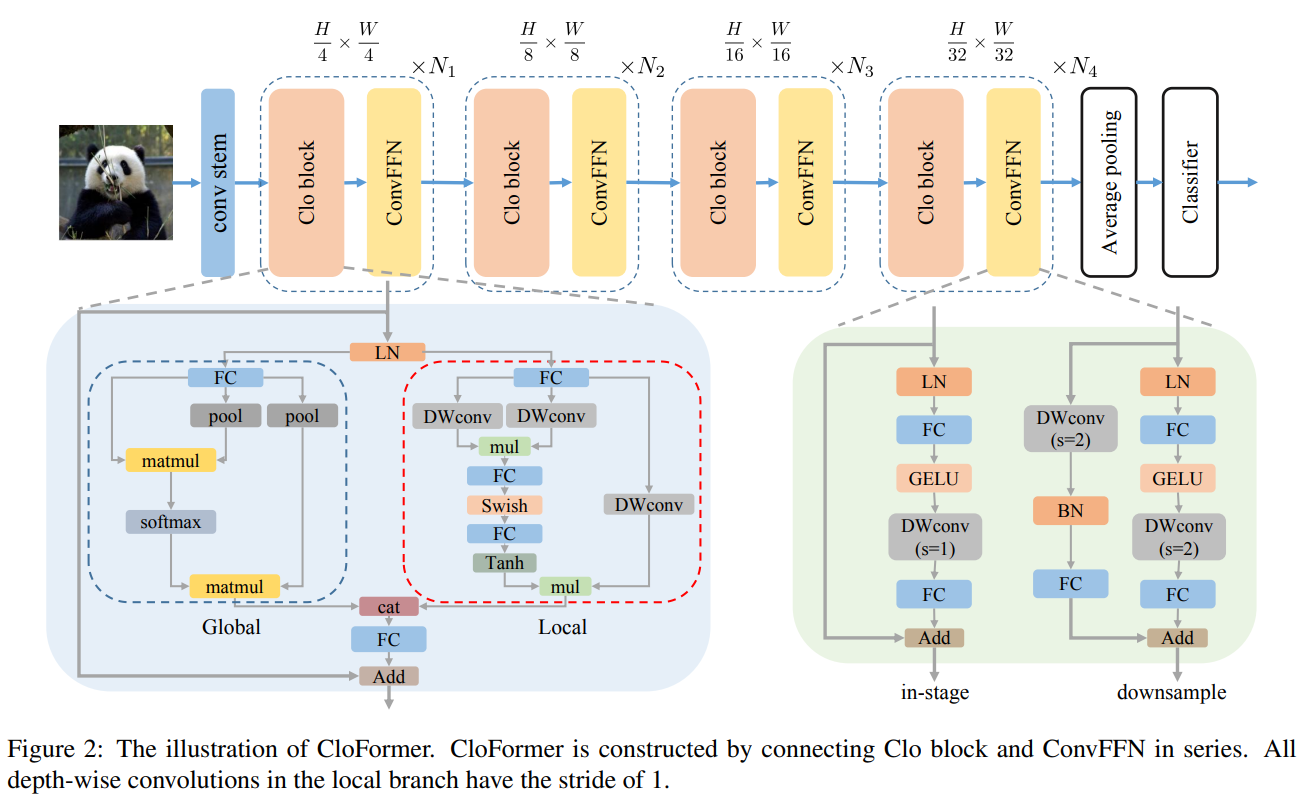
CloFormer 共包含一个卷积主干和四个 stage,每个 stage由Clo block 和 ConvFFN 组合而成的模块堆叠而成 。具体的,首先将输入图像通过卷积主干传递,以获取 token 表示。该主干由四个卷积组成,每个卷积的步长依次为2、2、1和1。接下来,tokens 经历四个 Clo 块和 ConvFFN 阶段,以提取分层特征。最后,再利用全局平均池化和全连接层生成预测结果。

ConvFFN
为了将局部信息融入 FFN 过程中,本文采用 ConvFFN 替换了常用的 FFN。ConvFFN 和常用的 FFN 的主要区别在于,ConvFFN 在 GELU 激活函数之后使用了深度卷积(DWconv),从而使 ConvFFN 能够聚合局部信息。由于DWconv 的存在,可以直接在 ConvFFN 中进行下采样而不需要引入 PatchMerge 模块。CloFormer 使用了两种ConvFFN。第一种是在阶段内的 ConvFFN,它直接利用跳跃连接。另一种是连接两个阶段的 ConvFFN,主要用于下采样操作。
Clo block
CloFormer 中的 Clo block 是非常关键的组件。每个 Clo nlock由一个局部分支和一个全局分支组成。在全局分支中,首先下采样 K 和 V,然后对 Q、K 和 V 进行标准的 attention 操作,以提取低频全局信息。
虽然全局分支能够获得全局的感受野,但在处理高频局部信息方面的能力不足。为此,CloFormer 引入局部分支,并使用 AttnConv 对高频局部信息进行处理。AttnConv 可以融合共享权重和上下文感知权重,能够更好地处理高频局部信息。因此,CloFormer 结合了全局和局部的优势。
AttnConv
AttnConv 是一个关键模块,使得所提模型能够获得高性能。它结合了一些标准的 attention 操作。具体而言,在AttnConv 中,我们首先进行线性变换以获得 Q、K和V。在进行线性变换之后,再对 V 进行共享权重的局部特征聚合。然后,基于处理后的 V 和 Q ,K 进行上下文感知的局部增强。三个步骤:
- 使用DWConv对V进行局部特征聚合;
- 使用DWConv对Q和K进行局部特征聚合,再结合Q和K生成上下文感知权重,该权重与V相乘以增强局部特征;
- 将局部分支与全局分支的特征进行拼接融合。

相比于传统卷积,AttnConv 中的上下文感知权重使得模型能够更好地适应输入内容。相比于局部自注意力机制,引入共享权重使得模型能够更好地处理高频信息,从而提高性能。此外,生成上下文感知权重的方法引入了更强的非线性性,也提高了性能。需要注意的是,AttnConv 中的所有操作都基于卷积,保持了卷积的平移等变性特性。
实验
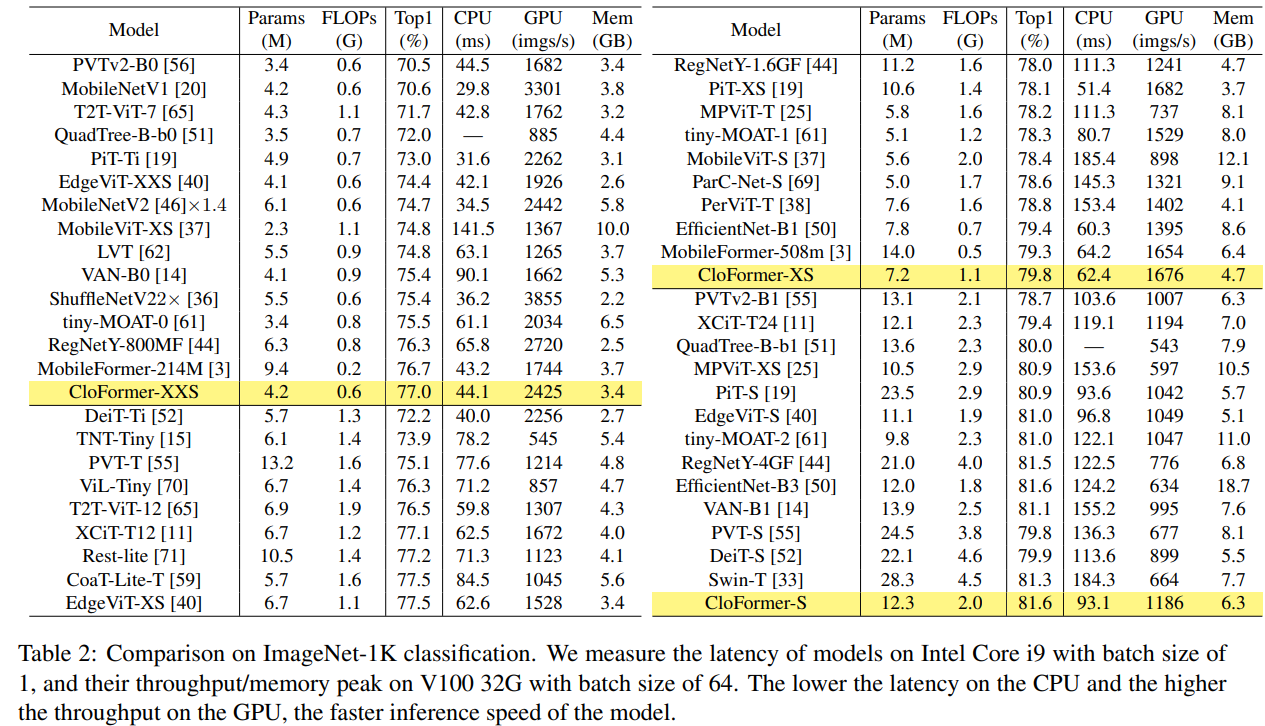
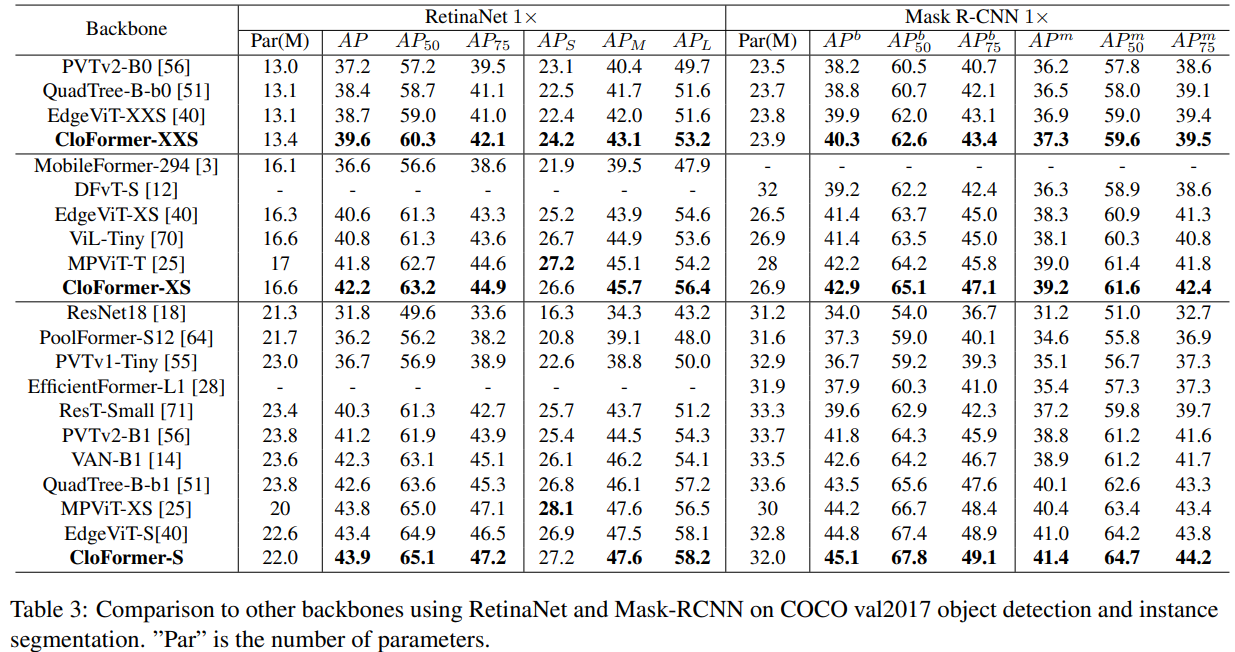


关键代码
AttnConv
# https://github.com/qhfan/CloFormer/blob/main/classification/models/blocks.py
class AttnMap(nn.Module):
def __init__(self, dim):
super().__init__()
self.act_block = nn.Sequential(
nn.Conv2d(dim, dim, 1, 1, 0),
MemoryEfficientSwish(),
nn.Conv2d(dim, dim, 1, 1, 0)
#nn.Identity()
)
def forward(self, x):
return self.act_block(x)
class EfficientAttention(nn.Module):
def __init__(self, dim, num_heads, group_split: List[int], kernel_sizes: List[int], window_size=7,
attn_drop=0., proj_drop=0., qkv_bias=True):
super().__init__()
assert sum(group_split) == num_heads
assert len(kernel_sizes) + 1 == len(group_split)
self.dim = dim
self.num_heads = num_heads
self.dim_head = dim // num_heads
self.scalor = self.dim_head ** -0.5
self.kernel_sizes = kernel_sizes
self.window_size = window_size
self.group_split = group_split
convs = []
act_blocks = []
qkvs = []
#projs = []
for i in range(len(kernel_sizes)):
kernel_size = kernel_sizes[i]
group_head = group_split[i]
if group_head == 0:
continue
convs.append(nn.Conv2d(3*self.dim_head*group_head, 3*self.dim_head*group_head, kernel_size,
1, kernel_size//2, groups=3*self.dim_head*group_head))
act_blocks.append(AttnMap(self.dim_head*group_head))
qkvs.append(nn.Conv2d(dim, 3*group_head*self.dim_head, 1, 1, 0, bias=qkv_bias))
#projs.append(nn.Linear(group_head*self.dim_head, group_head*self.dim_head, bias=qkv_bias))
if group_split[-1] != 0:
self.global_q = nn.Conv2d(dim, group_split[-1]*self.dim_head, 1, 1, 0, bias=qkv_bias)
self.global_kv = nn.Conv2d(dim, group_split[-1]*self.dim_head*2, 1, 1, 0, bias=qkv_bias)
#self.global_proj = nn.Linear(group_split[-1]*self.dim_head, group_split[-1]*self.dim_head, bias=qkv_bias)
self.avgpool = nn.AvgPool2d(window_size, window_size) if window_size!=1 else nn.Identity()
self.convs = nn.ModuleList(convs)
self.act_blocks = nn.ModuleList(act_blocks)
self.qkvs = nn.ModuleList(qkvs)
self.proj = nn.Conv2d(dim, dim, 1, 1, 0, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj_drop = nn.Dropout(proj_drop)
def high_fre_attntion(self, x: torch.Tensor, to_qkv: nn.Module, mixer: nn.Module, attn_block: nn.Module):
'''
x: (b c h w)
'''
b, c, h, w = x.size()
qkv = to_qkv(x) #(b (3 m d) h w)
qkv = mixer(qkv).reshape(b, 3, -1, h, w).transpose(0, 1).contiguous() #(3 b (m d) h w)
q, k, v = qkv #(b (m d) h w)
attn = attn_block(q.mul(k)).mul(self.scalor)
attn = self.attn_drop(torch.tanh(attn))
res = attn.mul(v) #(b (m d) h w)
return res
def low_fre_attention(self, x : torch.Tensor, to_q: nn.Module, to_kv: nn.Module, avgpool: nn.Module):
'''
x: (b c h w)
'''
b, c, h, w = x.size()
q = to_q(x).reshape(b, -1, self.dim_head, h*w).transpose(-1, -2).contiguous() #(b m (h w) d)
kv = avgpool(x) #(b c h w)
kv = to_kv(kv).view(b, 2, -1, self.dim_head, (h*w)//(self.window_size**2)).permute(1, 0, 2, 4, 3).contiguous() #(2 b m (H W) d)
k, v = kv #(b m (H W) d)
attn = self.scalor * q @ k.transpose(-1, -2) #(b m (h w) (H W))
attn = self.attn_drop(attn.softmax(dim=-1))
res = attn @ v #(b m (h w) d)
res = res.transpose(2, 3).reshape(b, -1, h, w).contiguous()
return res
def forward(self, x: torch.Tensor):
'''
x: (b c h w)
'''
res = []
for i in range(len(self.kernel_sizes)):
if self.group_split[i] == 0:
continue
res.append(self.high_fre_attntion(x, self.qkvs[i], self.convs[i], self.act_blocks[i]))
if self.group_split[-1] != 0:
res.append(self.low_fre_attention(x, self.global_q, self.global_kv, self.avgpool))
return self.proj_drop(self.proj(torch.cat(res, dim=1)))
class ConvFFN(nn.Module):
def __init__(self, in_channels, hidden_channels, kernel_size, stride,
out_channels, act_layer=nn.GELU, drop_out=0.):
super().__init__()
self.fc1 = nn.Conv2d(in_channels, hidden_channels, 1, 1, 0)
self.act = act_layer()
self.dwconv = nn.Conv2d(hidden_channels, hidden_channels, kernel_size, stride,
kernel_size//2, groups=hidden_channels)
self.fc2 = nn.Conv2d(hidden_channels, out_channels, 1, 1, 0)
self.drop = nn.Dropout(drop_out)
def forward(self, x: torch.Tensor):
'''
x: (b h w c)
'''
x = self.fc1(x)
x = self.act(x)
x = self.dwconv(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class EfficientBlock(nn.Module):
def __init__(self, dim, out_dim, num_heads, group_split: List[int], kernel_sizes: List[int], window_size: int,
mlp_kernel_size: int, mlp_ratio: int, stride: int, attn_drop=0., mlp_drop=0., qkv_bias=True,
drop_path=0.):
super().__init__()
self.dim = dim
self.mlp_ratio = mlp_ratio
self.norm1 = nn.GroupNorm(1, dim)
self.attn = EfficientAttention(dim, num_heads, group_split, kernel_sizes, window_size,
attn_drop, mlp_drop, qkv_bias)
self.drop_path = DropPath(drop_path)
self.norm2 = nn.GroupNorm(1, dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.stride = stride
if stride == 1:
self.downsample = nn.Identity()
else:
self.downsample = nn.Sequential(
nn.Conv2d(dim, dim, mlp_kernel_size, 2, mlp_kernel_size//2),
nn.SyncBatchNorm(dim),
nn.Conv2d(dim, out_dim, 1, 1, 0),
)
self.mlp = ConvFFN(dim, mlp_hidden_dim, mlp_kernel_size, stride, out_dim,
drop_out=mlp_drop)
def forward(self, x: torch.Tensor):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = self.downsample(x) + self.drop_path(self.mlp(self.norm2(x)))
return x
if __name__ == '__main__':
input = torch.randn(4, 96, 56, 56)
model = EfficientBlock(96, 192, 3, [1, 1, 1], [7, 5], 7, 7, 4, 2)
print(model(input).size())





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结