您现在的位置是:首页 >技术杂谈 >Python篇——数据结构与算法(第五部分:数据结构)网站首页技术杂谈
Python篇——数据结构与算法(第五部分:数据结构)
简介Python篇——数据结构与算法(第五部分:数据结构)
- 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成
- 简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中
- 比如:列表、集合与字典等都是一种数据结构
- N.Wirth:“程序 = 数据结构+算法”
1、列表
- 列表(其他语言称数组)是一种基本数据类型
- 关于列表的问题:
- 列表中的元素是如何存储的?
- 列表的基本操作:按下标查找、插入元素、删除元素.......
- 这些操作的时间复杂度是多少?
- 扩展:Python的列表是如何实现的?
列表是动态存储的,长度大小不固定,可以随意地增加、删减或者改变元素
元组是静态存储的,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组
Note:
数组与列表有两点不同:
- 数组元素类型要相同
- 数组长度固定
- O(n)
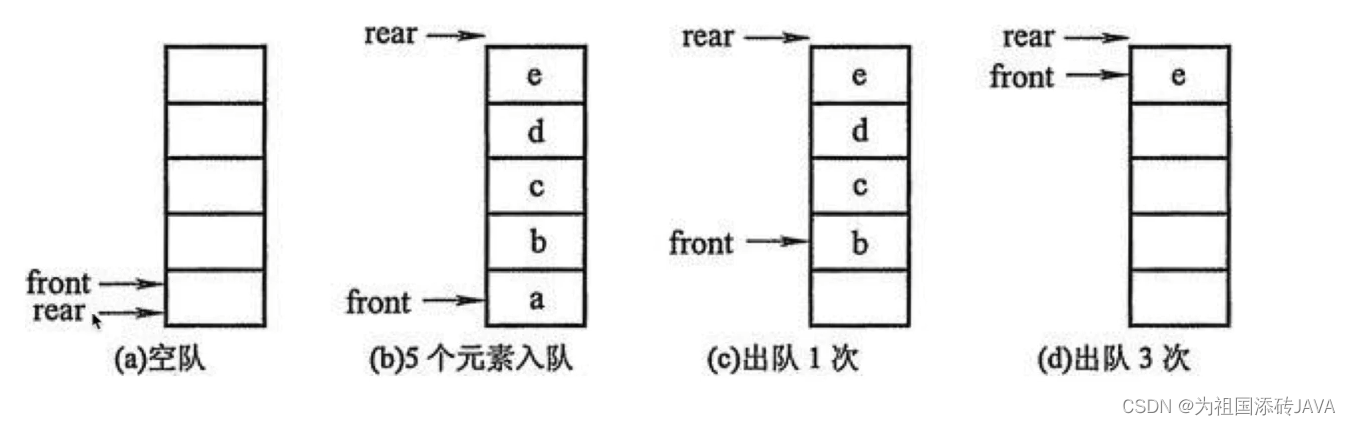
2、栈
- 栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表
- 栈的特点:后进先出(Last in first out)
- 栈的概念:栈顶、栈底
- 栈的基本操作:
- 进栈
- 出栈
- 取栈顶

Note:
一般使用列表结构就可以实现栈
- 进栈:li.append
- 出栈:li.pop
- 取栈顶:li[-1]
class Stack:
def __init__(self):
self.stack = []
def push(self, val):
self.stack.append(val)
def pop(self):
return self.stack.pop()
def get_top(self):
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
stack = Stack()
stack.push(1)
stack.push(2)
print(stack.pop())栈的应用:括号匹配问题

class Stack:
def __init__(self):
self.stack = []
def push(self, val):
self.stack.append(val)
def pop(self):
return self.stack.pop()
def get_top(self):
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
def is_empty(self):
return len(self.stack) == 0
def brace_match(string):
match = {')': '(', '}': '{', ']': '['} # 键值对
stack = Stack()
for i in string:
if i in {'(', '{', '['}:
stack.push(i)
else:
if stack.is_empty():
return False
elif stack.get_top() == match[i]:
stack.pop()
else:
return False
if stack.is_empty():
return True
else:
return False
print(brace_match('[{()}]'))
2、队列
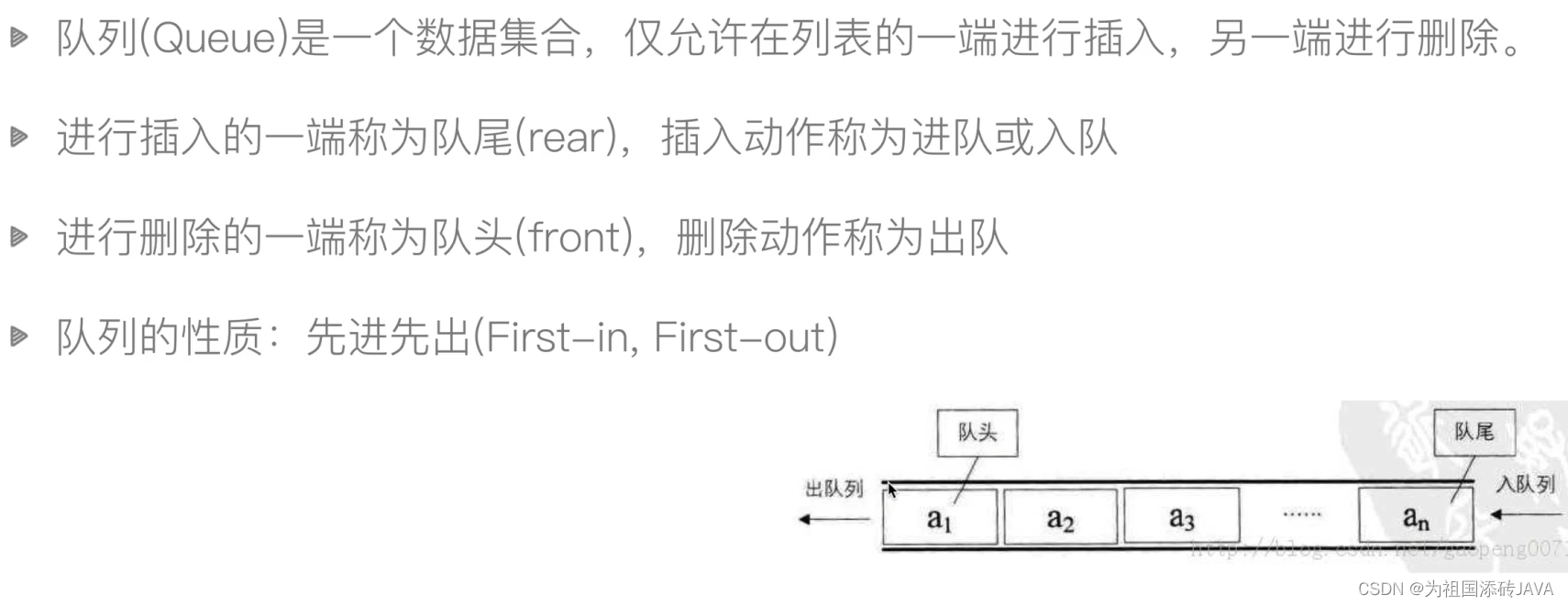
队列的实现方式:环形队列
Note:
- 为什么不用列表。因为空间浪费了。
- 为什么队满最后一个不填元素,因为将导致无法判断是队空还是队满(rear==front)
- 空队列rear==front ;满队列rear+1==front
- 循环的关键点:如何使得下标11过了之后能到0 ? 取余

总结:
- 环形队列:当队尾指针front==Maxsize-1时,在前进一个位置就自动到0(Maxsize指的是队列长度)
- 队首指针前进1:front=(front+1)%Maxsize
- 队尾指针前进1:rear=(rear+1)%Maxsize
- 队空条件:rear==front
- 队满条件:(rear+1)%Maxsize==front
class Queue:
def __init__(self, size=100):
self.queue = [0 for _ in range(100)]
self.size = size
self.rear = 0 # 队尾
self.front = 0 # 队首
def push(self, element):
'''入队'''
if not self.is_filled():
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = element
else:
raise IndexError("Queue is filled!")
def pop(self):
'''出队'''
if not self.is_empty():
self.front = (self.front + 1) % self.size
return self.queue[self.front]
else:
raise IndexError('Queue is empty!')
def is_empty(self):
'''判断队空'''
return self.rear == self.front
def is_filled(self):
'''判断队满'''
return self.front == (self.rear + 1) % self.size
q = Queue(size=5)
for i in range(4): # 0,1,2,3 ; size=5 是因为判断队满的时候留了一个空位置
q.push(i)
print(q.is_filled())
3、双向队列

内置模块
# 内置模块
# collections 为结构包
from collections import deque
q = deque([1, 2, 3, 4, 5], 5)
# 单向队列
q.append(6) # 队尾进队
print(q.popleft()) # 队首出队
# 双向队列
q.appendleft(1) # 队首进队
print(q.popleft()) # 队首出队
q.append(2) # 队尾入队
print(q.pop()) # 队尾出队结果:
2
1
2
Process finished with exit code 0Note:
- 为什么第一个的输出是“2”呢?
- 因为内置模块中如果size满了,会自动pop头元素,这里就导致我们pop的时候是元素2
应用:
如上面Note说的,如果size满了,会自动将前面的元素弹出,那么应用在哪里呢?
例如:我们先创建一个test文件,希望可以输出后面几行的内容该怎么做?
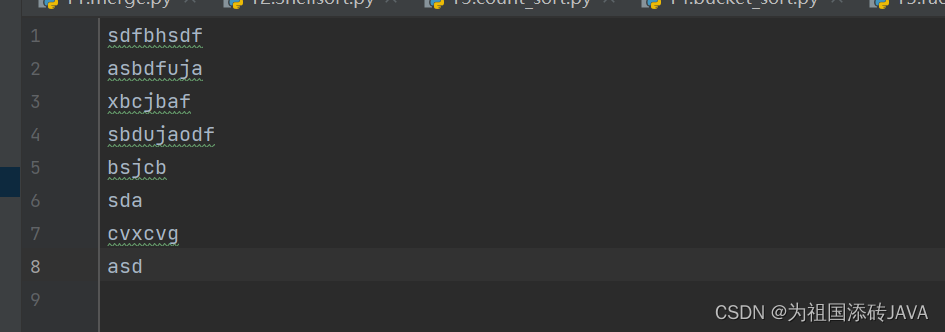
代码如下:
def tail(n):
with open('Queue2_test.txt', 'r') as f:
q = deque(f, n)
return q
print((tail(5)))结果如下:
deque(['sbdujaodf
', 'bsjcb
', 'sda
', 'cvxcvg
', 'asd
'], maxlen=5)
Process finished with exit code 0这样,就使用队列完成了对文本后面几行的输出。
4、栈和队列的应用(迷宫问题)
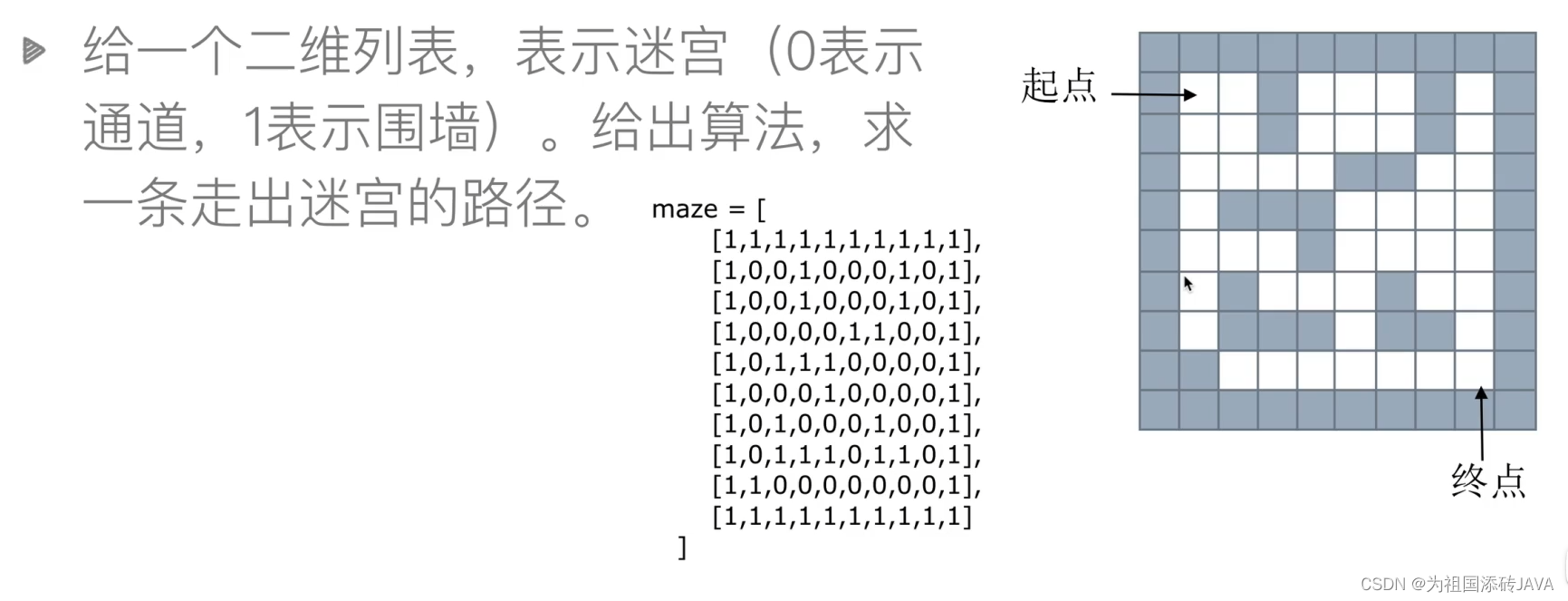
4.1栈——深度优先搜索

# 迷宫问题
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]
# 新列表存储四个方向
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1)
]
def maze_path(x1, y1, x2, y2):
'''
:param x1: 起点坐标
:param y1:
:param x2: 终点坐标
:param y2:
'''
stack = []
stack.append((x1, y1))
# 栈空表示没有通路
while (len(stack) > 0):
# 当前节点 curNode
curNode = stack[-1]
if curNode[0] == x2 and curNode[1] == y2:
# 走到终点
for p in stack:
print(p)
return True
# 上(x-1) 下(x+1) 左(y-1) 右(y+1)四个方向
for dir in dirs:
# 下一个节点
nextNode = dir(curNode[0], curNode[1])
# 如果下一个节点能走
if maze[[nextNode[0]][nextNode[1]]] == 0:
stack.append(nextNode)
maze[nextNode[0]][nextNode[1]] = 2 # 标记为已经走过了
break
# 一个都找不到
else:
maze[nextNode[0]][nextNode[1]] = 2
stack.pop()
else:
print('None path')
return False
maze_path(1, 1, 8, 8)
4.2队列——广度优先搜索

from collections import deque
# 迷宫问题
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]
# 新列表存储四个方向
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1)
]
def print_r(path):
curNode = path[-1]
realpath = []
while curNode[2] != -1:
realpath.append(curNode[0], curNode[1])
curNode = curNode[2]
# 起点
realpath.append(curNode[0:2])
realpath.reverse()
for node in realpath:
print(node)
def maze_path_queue(x1, y1, x2, y2):
queue = deque()
queue.append((x1, y1, -1))
# path用于存储出队节点,方便后面查找路径
path = []
while len(queue) > 0:
curNode = queue.popleft()
path.append(curNode)
if curNode[0] == x2 and curNode[1] == y2:
# 终点
print_r(path)
return True
for dir in dirs:
# 搜索当前节点周围节点
nextNode = dir(curNode[0], curNode[1])
if maze[nextNode[0]][nextNode[1]] == 0:
queue.append(nextNode[0], nextNode[1], len(path) - 1)
maze[nextNode[0]][nextNode[1]] = 2 # 标记已经走过
else:
return False
maze_path_queue(1, 1, 8, 8)
5、链表
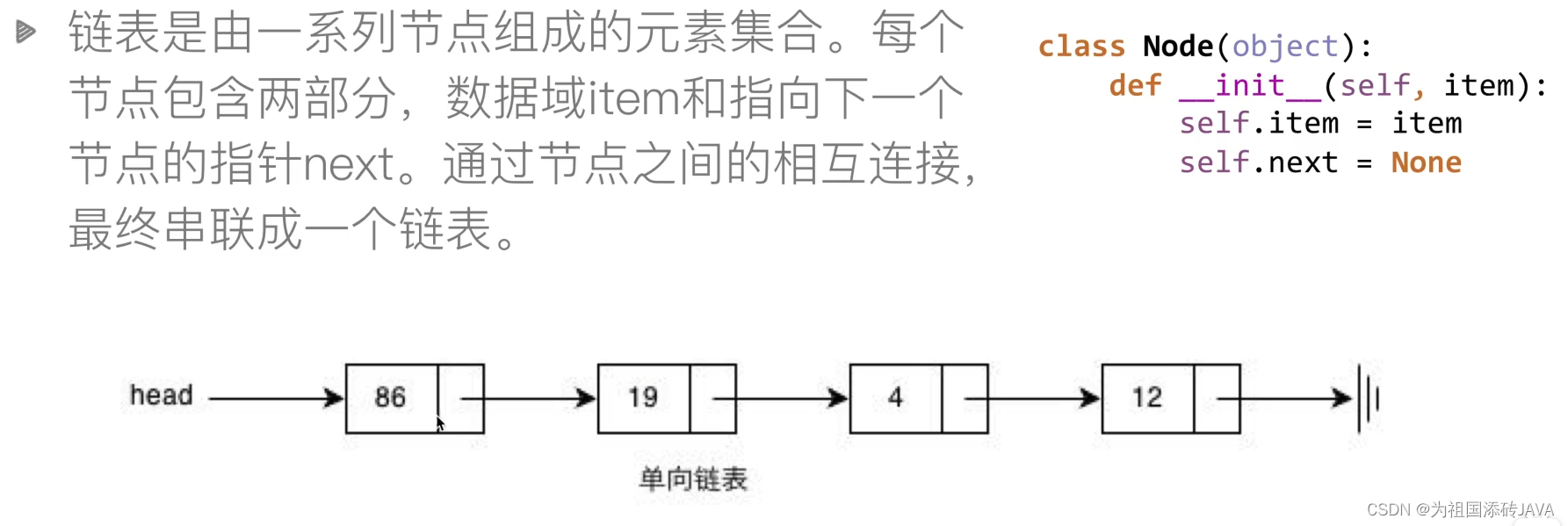
5.1创建链表
- 头插法(要知道head在哪儿)
- 尾插法(除了要知道head在哪儿,还要知道tail在哪儿)
头插法
# 链表
class Node:
def __init__(self, item):
self.item = item
self.next = None
def creat_linklist(li):
head = Node(li[0])
for i in li[1:]:
'''头插法'''
node = Node(i)
node.next = head
head = node
return head
def print_link_list(li):
while li:
print(li.item, end=',')
li = li.next
li = creat_linklist([1, 2, 3, 4])
print_link_list(li)
尾插法
# 链表
class Node:
def __init__(self, item):
self.item = item
self.next = None
def creat_linklist_head(li):
head = Node(li[0])
for i in li[1:]:
'''头插法'''
node = Node(i)
node.next = head
head = node
return head
def print_link_list(li):
while li:
print(li.item, end=',')
li = li.next
def creat_linklist_tail(li):
head = Node(li[0])
tail = head
for i in li[1:]:
node = Node(i)
tail.next = node
tail = node
return head
# li = creat_linklist_head([1, 2, 3, 4])
li1 = creat_linklist_tail([1, 2, 3, 4])
# print_link_list(li)
print_link_list(li1)
5.2链表的遍历
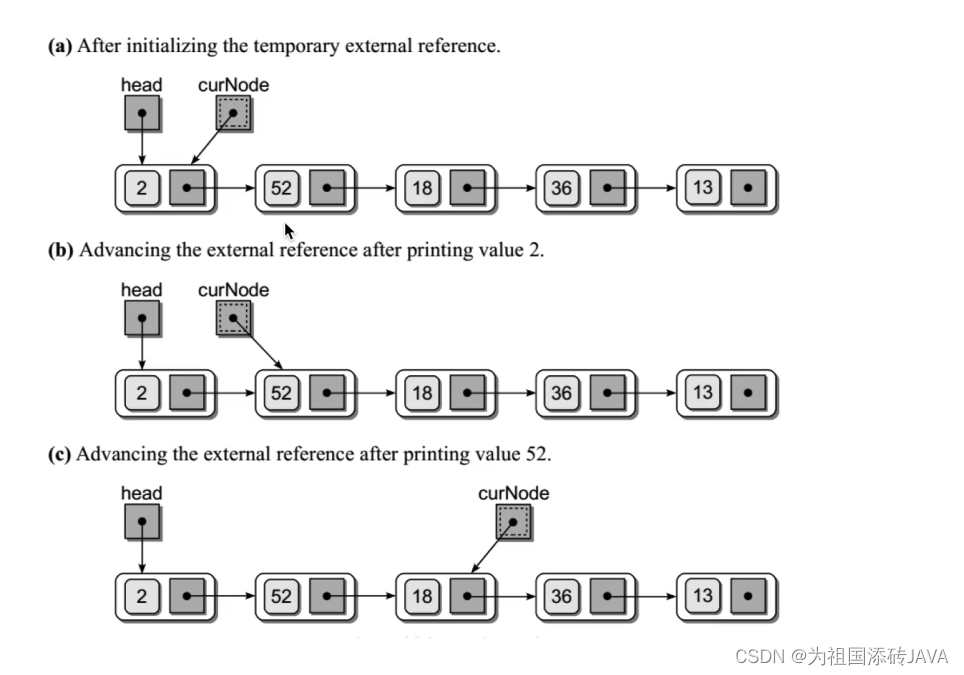
5.3链表的插入和删除
插入
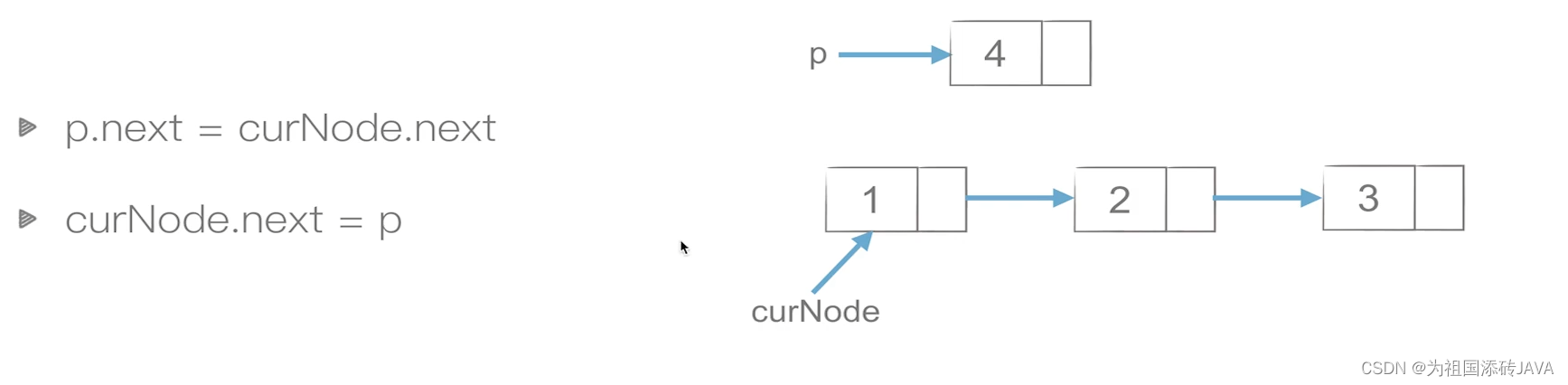
删除
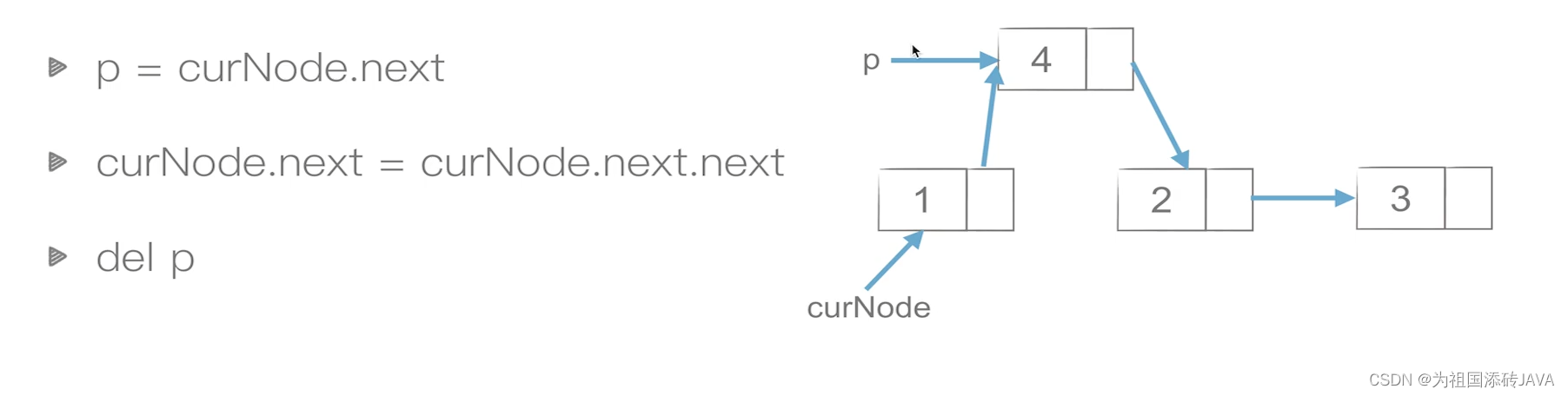
5.4双链表
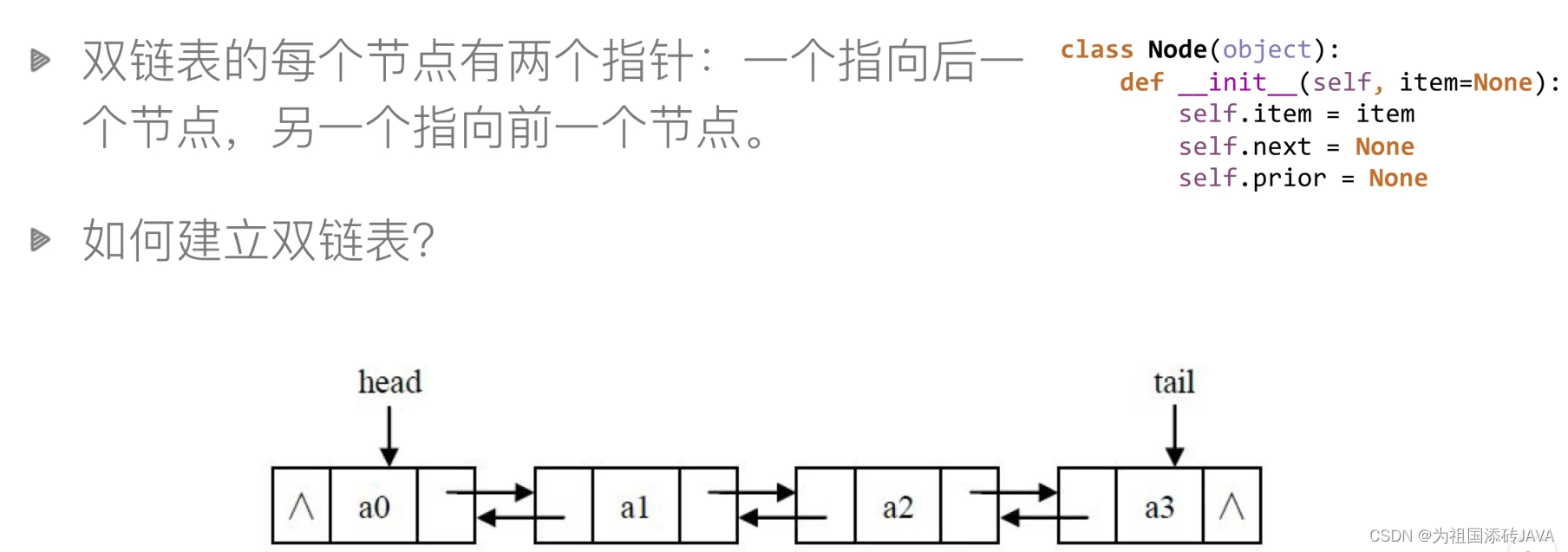
插入
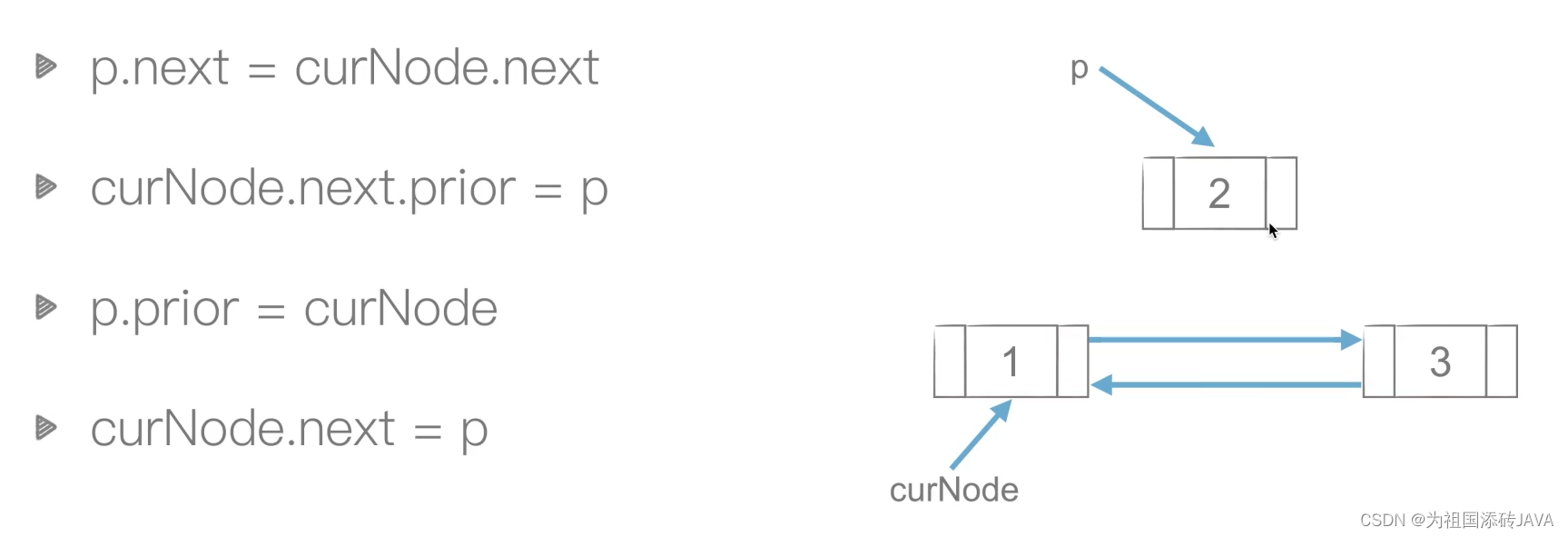
删除

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结