您现在的位置是:首页 >技术教程 >Zero-Shot, One-Shot, and Few-Shot Learning概念介绍网站首页技术教程
Zero-Shot, One-Shot, and Few-Shot Learning概念介绍
导语
本文将介绍零样本学习、一次样本学习和少样本学习的概念,它们使得机器学习模型能够在仅有有限数量的示例情况下对对象或模式进行分类和识别。
在机器学习中,我们通常需要大量的训练数据来训练模型,以便它能够准确地识别和分类新的输入。然而,在现实世界中,获取大规模标记数据集可能是昂贵和耗时的。因此,零样本学习、一次样本学习和少样本学习等技术应运而生,它们旨在解决这个问题。
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
零样本学习(Zero-Shot Learning)方法原理
零样本学习是指训练一个模型来对其从未见过的对象进行分类。其核心思想是利用另一个模型的现有知识,以获得新类别的有意义的表示。
它使用语义嵌入或基于属性的学习,以有意义的方式利用先前的知识,可以提供已知类别和未知类别之间关系的高级理解。这两者可以同时使用或独立使用。
语义嵌入是单词、短语或文档的向量表示,它们在连续向量空间中捕捉了它们之间的潜在含义和关系。这些嵌入通常是使用无监督学习算法生成的,如Word2Vec、GloVe或BERT。其目标是创建语言信息的紧凑表示,其中相似的含义用相似的向量编码。通过这种方式,语义嵌入允许对文本数据进行高效准确的比较和操作,并通过将实例投射到连续共享的语义空间中,泛化到未见过的类别。
基于属性的学习使得能够对未见类别的对象进行分类,而无需访问这些类别的任何标记示例。它将对象分解为其有意义和显著的属性,这些属性作为中间表示,使得模型能够在已见类别和未见类别之间建立对应关系。这个过程通常包括属性提取、属性预测和标签推断。
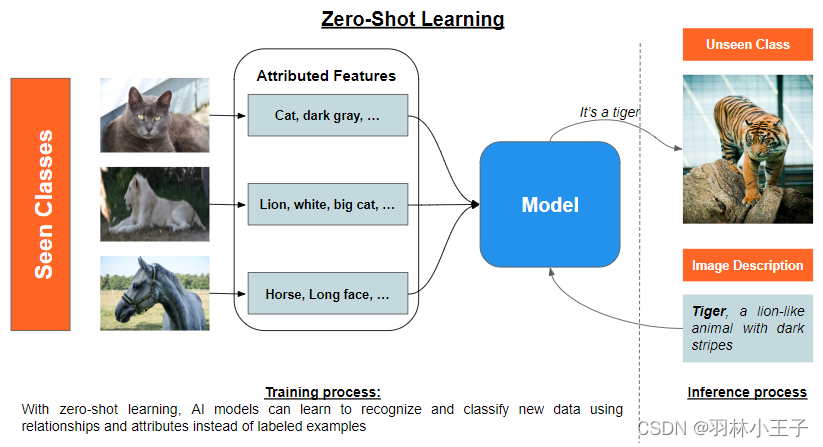
属性提取涉及为每个对象类别提取有意义和可区分的属性,以弥合低级特征和高级概念之间的差距。
属性预测涉及使用机器学习技术学习实例的低级特征和高级属性之间的对应关系,以识别特征之间的模式和关系,并泛化到新的类别。
标签推断涉及使用预测的属性和属性与未见类别标签之间的关系来预测新实例的类别标签,而无需依赖已标记的示例。
尽管零样本学习有着巨大的潜力,但仍然存在一些挑战,例如:领域适应:目标领域中实例的分布可能与源领域中的分布存在显著差异,导致对已见类别和未见类别学习的语义嵌入之间存在差异。这种领域转移可能会损害性能,因为模型可能无法在不同领域之间建立实例和属性之间的有意义对应关系。为了克服这一挑战,提出了各种领域适应技术,例如对抗性学习、特征分离和自监督学习,旨在通过调整源域和目标域中实例和属性的分布来实现分布的对齐。
一次样本学习(One-Shot Learning)方法原理
在开发传统神经网络的过程中,例如用于识别汽车,模型需要成千上万个样本,从不同角度和对比度不同的图像中捕捉,以有效区分它们。而one-shot学习采用了不同的方法。
该方法不是识别特定的汽车,而是确定图像A是否等同于图像B。这是通过将模型从先前任务的经验中获得的信息进行概括来实现的。one-shot学习主要用于计算机视觉领域。
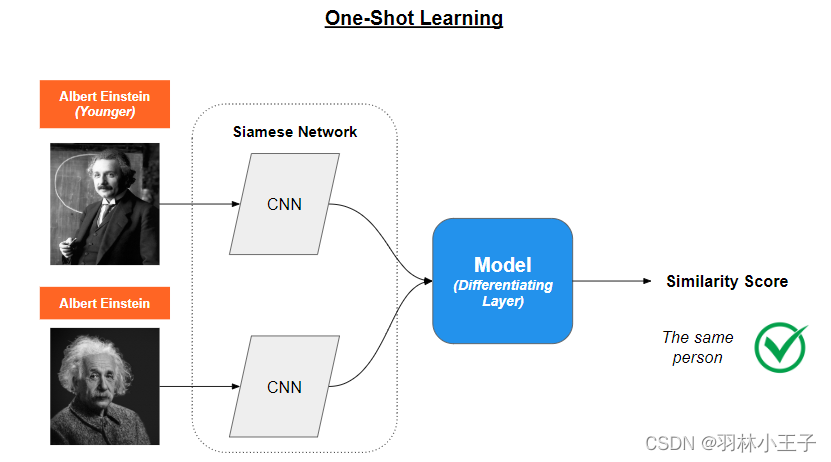
用于实现这一目标的技术包括记忆增强神经网络(Memory Augmented Neural Networks,MANNs)和连体网络(Siamese Networks)。通过独立应用这些技术,one-shot学习模型可以快速适应新任务,并且即使数据非常有限,也能表现出良好的性能,这使其非常适用于获取带标签数据成本高或耗时的实际场景。
记忆增强神经网络(MANNs)
记忆增强神经网络(MANNs)是一类先进的神经网络,旨在从很少的样本中学习,就像人类只需一个新对象的实例就能学习一样。MANNs通过具备额外的记忆组件来实现这一点,该组件可以存储和随时间访问信息。
想象一下,MANN就像一个智能机器人,它有一本笔记本。机器人可以使用它的笔记本来记住之前看到的事物,并利用这些信息来理解它遇到的新事物。这有助于机器人比普通的人工智能模型学习得更快。
连体网络(Siamese Networks)
另一方面,连体网络(Siamese Networks)是通过使用两个或多个具有共享权重的相同子网络来比较数据样本的设计。这些网络学习一个特征表示,捕捉数据样本之间的主要差异和相似之处。
想象连体网络就像一对双胞胎侦探,他们总是一起工作。他们共享相同的知识和技能,他们的工作是比较两个物品,并判断它们是相同还是不同。这些侦探观察每个物品的重要特征,然后将其发现进行比较以作出决策。
连体网络的训练分为两个阶段:验证阶段和泛化阶段。
- 在验证阶段,网络确定两个输入图像或数据点是否属于同一类别。网络使用两个相同子网络分别处理两个输入。
- 在泛化阶段,模型通过有效学习可以区分不同类别的特征表示来概括对输入数据的理解。
完成这两个阶段后,模型能够确定图像A是否对应于图像B。
one-shot学习非常有前景,因为它不需要重新训练来检测新的类别。然而,它面临着挑战,比如对内存需求较高和对计算能力的巨大需求,因为学习需要两倍的操作。
为了解决这些挑战,研究人员提出了许多改进的方法和技术。例如,通过改进模型的架构和设计,以减少内存需求和计算复杂性;使用生成对抗网络(Generative Adversarial Networks,GANs)来生成合成样本以增加数据量;采用迁移学习和领域适应技术,以便将先前学习到的知识迁移到新的任务中。
one-shot学习的发展为计算机视觉领域带来了许多潜在应用。例如,在人脸识别领域,one-shot学习可以帮助识别未在训练集中出现的人脸。在物体检测和图像分类领域,one-shot学习可以使模型更好地适应新的物体类别,而无需大量标记样本。
少样本学习(Few-Shot Learning)方法原理
最后要介绍的学习方法是少样本学习(Few-Shot Learning),它是元学习的一个子领域,旨在开发能够从少量有标签示例中学习的算法。
深度学习元学习(Deep Meta-Learning)是一种机器学习方法,旨在让机器能够学习如何快速适应新任务,而不是仅仅在已知的任务上进行训练。具体来说,元学习的目标是让机器学会如何通过有限的样本数据,快速地适应新的任务,并且能够在不同的任务之间进行泛化。元学习通过将模型的训练过程视为一个学习过程,从而使模型可以自动学习如何学习。元学习已经被广泛应用于少样本学习、迁移学习、强化学习等领域,成为了机器学习中一个备受关注的研究方向。
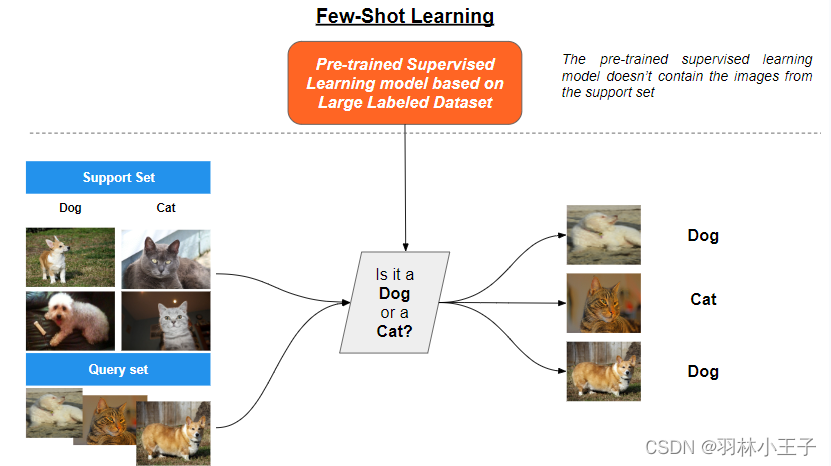
在元学习背景下,原型网络(Prototypical Networks)和模型无关元学习(Model-Agnostic Meta-Learning,MAML)是两种在少样本学习场景中取得成功的突出替代技术。
原型网络(Prototypical Networks)
原型网络是一类为少样本分类任务设计的神经网络。其核心思想是在特征空间中为每个类学习一个原型或代表性示例。通过比较新输入与学习到的原型之间的距离,进行分类。主要包括三个步骤:
- 嵌入(Embedding):网络使用神经网络编码器(如卷积神经网络(CNN)或循环神经网络(RNN))为每个输入计算一个嵌入。嵌入是捕捉输入数据显著特征的高维表示。
- 原型计算:对于每个类,网络通过对支持集的嵌入取均值来计算原型,支持集是每个类别的少量有标签示例的子集。原型表示特征空间中类别的“中心”。
- 分类:给定一个新输入,网络计算其嵌入,并计算输入的嵌入与原型之间的距离(如欧氏距离)。然后将输入分配给最近原型所属的类别。
学习过程涉及最小化损失函数,鼓励原型与其相应类别的嵌入更接近,并与其他类别的嵌入相距较远。
模型无关元学习(MAML)
MAML是一种元学习算法,旨在找到模型参数的最佳初始化,使其能够通过少量梯度步骤快速适应新任务。MAML是模型无关的,意味着它可以应用于任何使用梯度下降进行训练的模型。
MAML涉及以下步骤:
- 任务抽样:在元训练过程中,从任务分布中抽样任务,每个任务都是一个具有少量有标签示例的少样本学习问题。
- 任务特定学习:对于每个任务,使用任务的训练数据(支持集)通过少量梯度步骤对模型参数进行微调。这样就得到了具有更新参数的任务特定模型。
- 元学习:元目标是最小化所有任务的验证数据(查询集)上的任务特定损失之和。通过梯度下降更新模型的初始参数以实现此目标。
- 元测试:在元训练之后,模型可以快速地在新任务上进行微调,只需要进行几个梯度步骤,利用已学习的初始化。
MAML需要大量的计算资源,因为它涉及多个嵌套的梯度更新,这带来了挑战。其中一项挑战是任务多样性。在许多少样本学习的场景中,模型必须适应多种任务或类别,每个任务或类别只有很少的样本。这种多样性使得开发一个单一的模型或方法来有效地处理不同的任务或类别变得具有挑战性,需要进行大量的微调或适应。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结