您现在的位置是:首页 >技术交流 >深度学习技巧应用7-K折交叉验证的实践操作网站首页技术交流
深度学习技巧应用7-K折交叉验证的实践操作
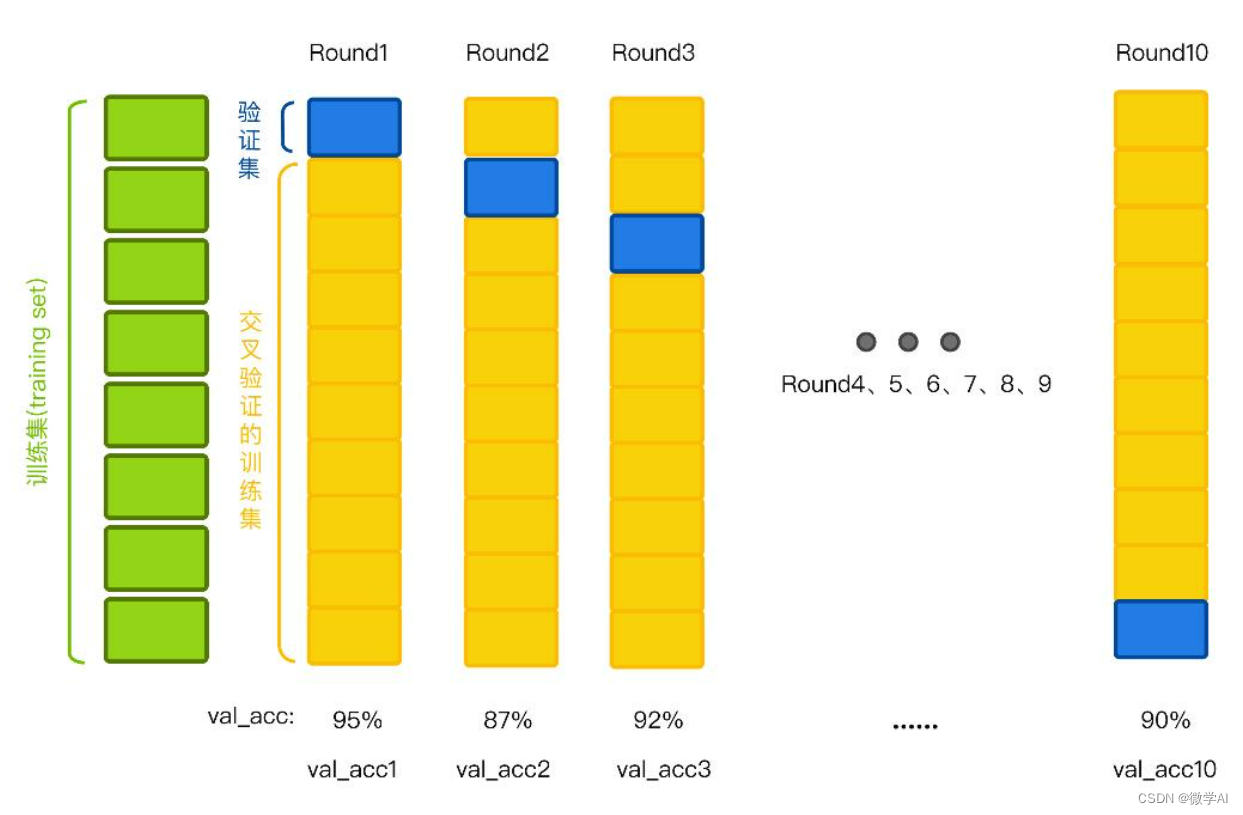
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用7-K折交叉验证的实践操作。K折交叉验证是一种机器学习中常用的模型验证和选择方式,它可以将数据集分为K个互斥的子集,其中K-1个子集作为训练集,剩下1个子集作为验证集,重复K次,每次使用不同的验证集,最终平均所有结果作为模型的性能度量。针对数据量较少的时候,我们可以采取K折交叉验证提升模型的性能。
一、K折交叉验证的步骤
1.将数据集按照预定比例分为K份。
2.分别使用其中的K-1份作为训练数据,剩下的1份作为验证数据集,进行训练和测试。
3.重复上述步骤K次,每次选用不同的验证集,最终将K次性能指标的平均值作为模型的性能度量,从而评估模型的泛化能力。
K折交叉验证通常会在模型的训练过程中使用,它可以评估模型在训练集以外的数据上的性能表现,并且可以减少因数据集随机样本而带来的偏差,提高模型泛化能力和鲁棒性。此外,K折交叉验证还可用于调整模型超参数,从而找到最佳的模型参数并提高模型性能。
二、K折交叉验证的优势
1.充分利用数据集:K折交叉验证会将数据集划分为k份,每次交叉验证时都会选用不同的训练集和验证集,这样可以充分利用数据集中的所有数据,减少因缺少数据而造成的模型过拟合。
2.减少过拟合:通过将数据集划分为k个相等的子集,K折交叉验证可以避免某些数据只出现在训练集或验证集中,从而减少因过拟合而造成的性能评估误差。
3.提高模型鲁棒性:K折交叉验证可以对模型的泛化性能进行评估,从而可以检测到模型在不同训练集上的表现,提高了模型的鲁棒性。
三、K折交叉验证的使用
1.模型评估:K折交叉验证可用于评估模型的泛化能力,评估模型在未知数据上的表现。在使用K折交叉验证时,我们通常将数据集划分为训练集和测试集,然后将训练集进行K折划分,用其中的K-1份作为训练集,剩下的1份作为验证集,训练模型并评估性能,重复K次,计算平均性能,从而评估模型的性能表现。
2.模型选择:K折交叉验证可用于选择最佳的模型,通常我们可以在多个预定义的模型中选择,将数据集进行K折划分,选用一种评估指标(如准确率、AUC等),根据性能指标的平均表现选择最优的模型。
3.超参数调整:K折交叉验证可以用于超参数的调整。超参数通常是通过交叉验证来确定的,比如在支持向量机(SVM)上,我们通常需要调整的超参数包括核函数类型、惩罚因子等等,K折交叉验证可以帮助我们通过在训练集上训练模型并在验证集上计算指标来确定超参数的最佳值。
四、K折交叉验证代码实例
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 逻辑回归模型
def LogisticModel(X,y):
# 定义模型
model = LogisticRegression()
# 定义k折交叉验证的折数
k = 5
# 使用KFold函数进行划分数据集
kfold = KFold(n_splits=k, shuffle=True)
# 进行k次训练和验证
acc = []
for train_index, test_index in kfold.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc.append(accuracy_score(y_test, y_pred))
# 计算k次验证的准确率的平均值
mean_acc = sum(acc) / k
# 输出结果
print("Accuracy:", mean_acc)
#随机森林模型
def RandomForest(X,y):
# 创建模型
model = RandomForestClassifier(n_estimators=10)
# 设置K折交叉验证的折数
kfold = KFold(n_splits=5, shuffle=True)
# 训练模型并进行K折交叉验证
scores = cross_val_score(model, X, y, cv=kfold)
#print(scores)
# 输出K折交叉验证结果的平均得分
print(f"Accuracy: {scores.mean()}")
LogisticModel(X, y)
RandomForest(X,y)代码对逻辑回归模型、随机森林模型进行K折交叉验证。运行结果:
Accuracy: 0.9666666666666668
Accuracy: 0.9466666666666667更多内容请持续关注哦!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结