您现在的位置是:首页 >技术交流 >【神经网络】tenorflow实验11--人工神经网络(2)网站首页技术交流
【神经网络】tenorflow实验11--人工神经网络(2)
1. 实验目的
①掌握梯度下降法的优化算法;
②能够使用tf.keras构建Sequential模型,完成多分类任务。
2. 实验内容
①下载MNIST数据集,建立神经网络模型,实现对MNIST手写数字数据集的识别,调整超参数和训练参数,并以可视化的形式输出模型训练的过程和结果;
②下载Fashion MNIST数据集,建立神经网络模型,实现对Fashion MNIST数据集的分类,调整超参数和训练参数,并以可视化的形式输出模型训练的过程和结果。
3.实验过程
题目一:
使用神经网络模型,实现对MNIST手写数字数据集的识别,并测试模型性能,记录和分析结果。
要求:
(1)编写代码实现上述功能;
(2)记录实验过程和结果:
调整超参数和训练参数,使模型在测试集达到最优的性能,并以恰当的方式记录和展示实验过程和结果。
(3)分析和总结:
这个模型中的超参数有哪些?训练参数有哪些?结合训练过程,说明它们对模型性能的影响。
(4)保存上述训练好的模型,并使用它对自制的手写数字图像的识别(自制的手写数字图像见期中试题题目二)。
① 代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
plt.rcParams['font.family'] = "SimHei"
#导入mnist的训练集和测试集
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
img_testx = test_x
img_testy = test_y
#对属性进行归一化,使取值范围在0-1之间,同时转换为tensor张量,标签值转换为张量,0-9的整数
X_train,X_test = tf.cast(train_x / 255.0,tf.float32),tf.cast(test_x / 255.0,tf.float32)
Y_train,Y_test = tf.cast(train_y , tf.int16),tf.cast(test_y,tf.int16)
X_img = X_test
#建立Sequential模型,使用add方法添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) #Flatten不进行计算,将输入的二维数组转换为一维数组,进行形状转换
model.add(tf.keras.layers.Dense(128,activation="relu")) #添加隐含层,隐含层是全连接层,128个结点,激活函数使用relu函数
model.add(tf.keras.layers.Dense(10,activation="softmax"))#添加输出层,输出层是全连接层,激活函数是softmax函数
#配置训练方法
#优化器使用adam,损失函数使用稀疏交叉熵损失函数,准确率使用稀疏分类准确率函数
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
## 训练模型
## 使用训练集中的数据训练,从中划分20%作为测试数据,用在每轮训练后评估模型的性能,每个小批量使用64条数据,训练5轮
model.fit(X_train,Y_train,batch_size=64,epochs=5,validation_split=0.2)
model.save_weights("result.h5")
#使用测试集评估模型
model.evaluate(X_test,Y_test,verbose=2)
#使用模型预测随机5个数据
for i in range(5):
num = np.random.randint(1,10000)
plt.subplot(1,5,i+1)
plt.axis("off")
plt.imshow(test_x[num],cmap="gray")
# argmax取出值最大的索引,predict中参数的数据范围和维数与训练集一致
y_pred = np.argmax(model.predict(tf.convert_to_tensor(X_test[num].numpy().reshape(1,28,28))))#使用argmax函数得到预测值
plt.title("原值="+str(test_y[num])+"
预测值:"+str(y_pred))
plt.show()
#使用模型预测自己的手写数据集
img_arr = []
for i in range(10):
img = Image.open(r"D:WorkSpacepythonProjectqizhongpicture\%d.png" % i)
img_temp = np.array(img)
img_arr.append(img_temp)
for i in range(5):
num = np.random.randint(1,10000)
plt.subplot(1,5,i+1)
plt.axis("off")
plt.imshow(img_testx[num],cmap = "gray")
#argmax取出值最大的索引,predict中参数的数据范围和维数与训练集一致
#y_pred = np.argmax(model.predict([[X_test[num]]]))
#tensor = tf.convert_to_tensor(X_test[num].numpy().reshape(1,28*28))
y_pred = np.argmax(model.predict(tf.convert_to_tensor(X_img[num].numpy().reshape(1,28,28))))
plt.title("原值=" + str(img_testy[num]) + "
预测值:" + str(y_pred))
plt.show()
② 结果记录
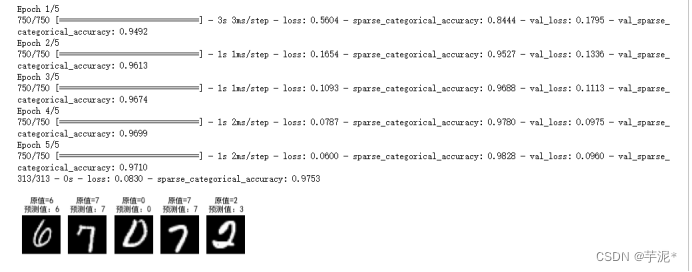
③ 实验总结
题目二:
使用神经网络模型,实现对Fashion MNIST数据集的分类,并测试模型性能,记录和分析结果。
要求:
(1)编写代码实现上述功能;
(2)记录实验过程和结果:
调整超参数,综合考虑准确率、交叉熵损失、和训练时间等,使模型在测试集达到最优的性能,并以恰当的方式记录和展示实验结果。
(3)分析和总结:
这个模型中的超参数有哪些?简要说明你寻找最佳超参数的过程,并对结果进行分析和总结。
① 代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "SimHei"
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_x,train_y),(test_x,test_y) = fashion_mnist.load_data()
names = ['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle book']
#对属性进行归一化,使取值范围在0-1之间,同时转换为tensor张量,标签值转换为张量,0-9之间的整数
X_train,X_test = tf.cast(train_x / 255.0,tf.float32),tf.cast(test_x / 255.0,tf.float32)
Y_train,Y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
#建立Sequential模型,使用add方法添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) #Flatten不进行计算,将输入的二维数组转换为一维数组
model.add(tf.keras.layers.Dense(128,activation="relu")) #添加隐含层,隐含层是全连接层,128个结点,激活函数使用relu函数
model.add(tf.keras.layers.Dense(10,activation="softmax")) #添加输出层,输出层是全连接层,激活函数是softmax函数
#配置训练方法
#优化器使用adam,损失函数使用稀疏交叉熵损失函数,准确率使用稀疏分类准确率函数
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
#训练模型
#使用训练集中的数据训练,从中划分20%作为测试数据,用在每轮训练后评价模型的性能,每个小批量使用64条数据,训练5轮
model.fit(X_train,Y_train,batch_size=64,epochs=5,validation_split=0.2)
#使用测试集评估模型,verbose = 2表示每一轮输出一行记录
model.evaluate(X_test,Y_test,verbose=2)
#使用模型
for i in range(4):
num = np.random.randint(1,10000)
plt.subplot(1,4,i + 1)
plt.axis("off")
plt.imshow(test_x[num],cmap="gray")
y_pred = np.argmax(model.predict(test_x[num].reshape(1,28,28)))
plt.title("原值:"+names[test_y[num]]+"
预测值"+ names[y_pred])
plt.show()
② 结果记录
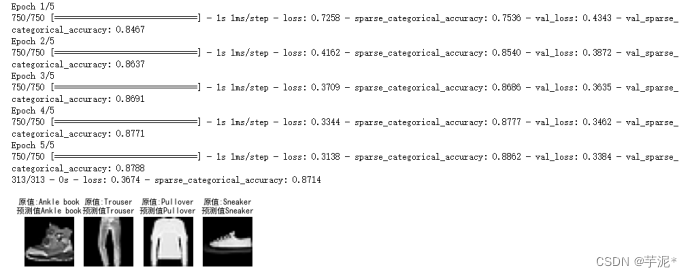
③ 实验总结
题目三:
使用低阶API实现Softmax函数和交叉熵损失函数,并使用它们修改题目二。
① 代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "SimHei"
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_x,train_y),(test_x,test_y) = fashion_mnist.load_data()
names = ['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle book']
#对属性进行归一化,使取值范围在0-1之间,同时转换为tensor张量,标签值转换为张量,0-9之间的整数
X_train,X_test = tf.cast(train_x / 255.0,tf.float32),tf.cast(test_x / 255.0,tf.float32)
Y_train,Y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
#定义Softmax函数
def softmax(x):
exp_x = tf.exp(x)
sum_exp_x = tf.reduce_sum(exp_x, axis=1, keepdims=True)
return exp_x / sum_exp_x
#定义交叉熵损失函数
def cross_entropy_loss(y_true, y_pred):
y_true = tf.cast(y_true, tf.int32)
y_true = tf.one_hot(y_true, depth=10)
return -tf.reduce_mean(tf.reduce_sum(y_true * tf.math.log(y_pred), axis=-1))
#建立Sequential模型,使用add方法添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) #Flatten不进行计算,将输入的二维数组转换为一维数组
model.add(tf.keras.layers.Dense(128,activation="relu")) #添加隐含层,隐含层是全连接层,128个结点,激活函数使用relu函数
model.add(tf.keras.layers.Dense(10)) #添加输出层,输出层是全连接层
#使用自定义的Softmax函数
model.add(tf.keras.layers.Lambda(softmax))
#配置训练方法
#优化器使用adam,损失函数使用自定义的交叉熵损失函数,准确率使用稀疏分类准确率函数
model.compile(optimizer='adam',loss=cross_entropy_loss,metrics=['sparse_categorical_accuracy'])
#训练模型
#使用训练集中的数据训练,从中划分20%作为测试数据,用在每轮训练后评价模型的性能,每个小批量使用64条数据,训练5轮
model.fit(X_train,Y_train,batch_size=64,epochs=5,validation_split=0.2)
#使用测试集评估模型,verbose = 2表示每一轮输出一行记录
model.evaluate(X_test,Y_test,verbose=2)
#使用模型
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i + 1)
plt.axis("off")
plt.imshow(test_x[num],cmap="gray")
y_pred = np.argmax(model.predict(test_x[num].reshape(1,28,28)))
plt.title("原值:"+names[test_y[num]]+"
预测值"+ names[y_pred])
plt.show()
② 实验结果

4.实验小结&讨论题
请结合题目1-3回答下述问题:
①什么是小批量梯度下降法?每个小批量中的样本数对迭代次数有何影响?
答:小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。 其思想是:每次迭代 使用 batch_size 个样本来对参数进行更新。在小批量梯度下降法中,每个批中的所有样本共同决定了本次迭代中梯度的方向。
②可以从哪些方面对梯度下降法进行优化?典型的优化方法有哪些?它们对模型训练过程有何影响?
答:从批量大小Batch Size、学习率、梯度估计三个方面进行优化。典型的算法有Momentum-动量、Nesterov-加速梯度下降法、Adagrad-自适应梯度、Adadelta、RMSprop、Adam-自适应矩估计、AdaMax、 Nadam-加速自适应矩估计、Lookahead。
③在设计神经网络时,为MNIST设计的神经网络是否可以直接应用到Fashion-MNIST上?请从数据集的图片大小,样本数以及分类数等角度解释这个现象
答:可以直接使用。Fashion-MNIST 的图片大小,训练、测试样本数及类别数与经典 MNIST完全相同。
④Fashion-MNIST创建之初希望替代MNIST数据集,比较相同的神经网络在这两个数据集上的准确率,并思考在模型评估方面,使用Fashion-MNIST数据集有什么优势?
答:MNIST数据集过于简单,可以在MNIST数据集成功的模型在别的数据集未必可以成功,不具有准确性,而Fashion-MNIST数据集更为复杂,可以更好的训练模型。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结