您现在的位置是:首页 >技术交流 >清华p-tuning | GPT也能做NLU?清华推出p-tuning方法解决GPT系列模型fine-tuning效果比BERT差问题网站首页技术交流
清华p-tuning | GPT也能做NLU?清华推出p-tuning方法解决GPT系列模型fine-tuning效果比BERT差问题
简介清华p-tuning | GPT也能做NLU?清华推出p-tuning方法解决GPT系列模型fine-tuning效果比BERT差问题
一、概述
title:GPT Understands, Too
论文地址:https://arxiv.org/abs/2103.10385
代码:https://github.com/THUDM/P-tuning
1.1 Motivation
- GPTs模型利用传统的fine-tuning技术在NLU任务上效果比较差,比同等量级的BERT效果要差。
1.2 Methods
- 提出了新的P-tuning方法,构造一个可训练的连续prompt embedding,通过在连续空间中搜索更好的提示语prompt,来提升预训练模型的NLU能力。
1.3 Conclusion
- 在知识探针检查任务LAMA上,zero shot条件下GPT复原了64%(P@1),提升了20+个点。
- 在SuperGlue任务下,GPTs系列模型取得了可比的甚至超过BERTs系列监督学习的水平。
- P-tuning也提升了BERTs系列模型few-shot和监督学习的表现,同时大幅降度prompt工程的需求。
- P-tuning在SuperGlue任务上取得了sota的few-shot表现。
二、详细内容
1. 效果对比

- 模型大小为110M时,原始Fine-tuning方法中,在SuperGlue任务中,GPT效果比BERT效果差的比较多,使用P-tuning方法后,GPT反而比BERT效果好,同时BERT模型效果也比Fine-tuning效果好。
- 模型大小为340M时,GPT效果的提升更大。
2. 模型结构
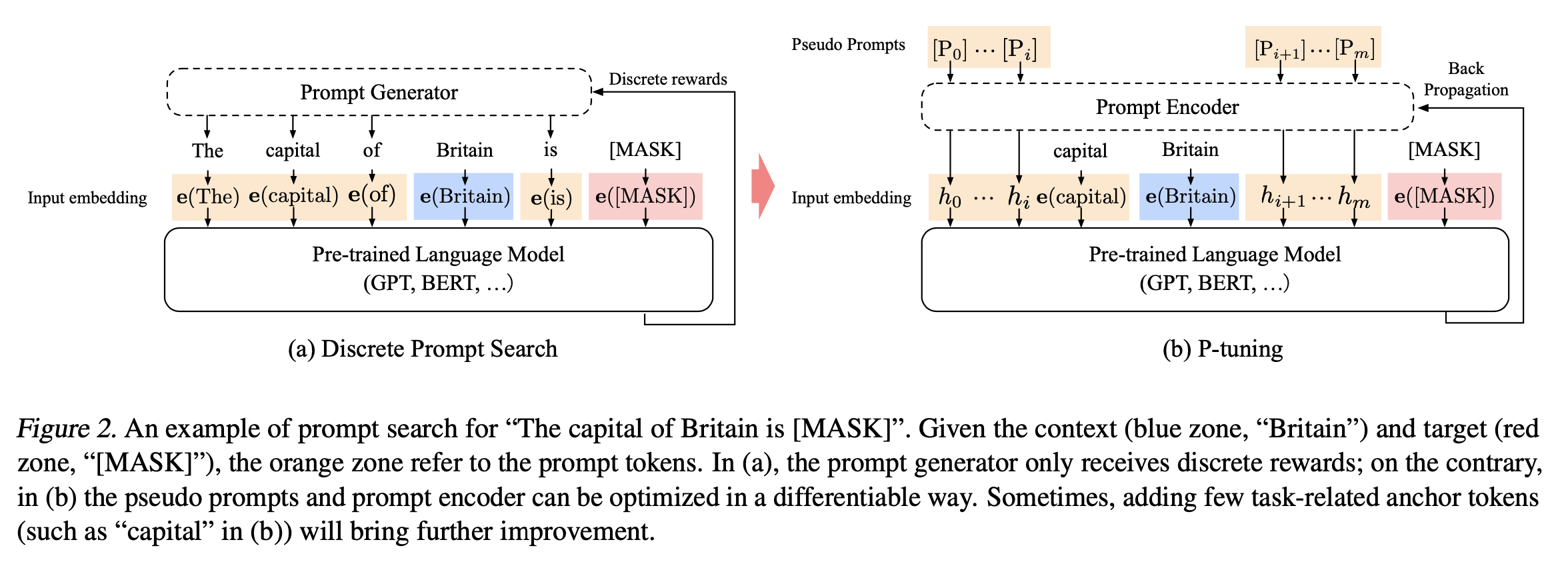
- Discrete Prompt Search(离散prompt搜索):原来的方法需要人工设置比较好的模板,来抽取得到正确的答案。
-
- context:上下文,例如Britain
- target:预测目标
- (a)黄颜色为prompt token,只能收到离散的反馈
- P-tuning
-
- 利用embedding构建pseudo prompts,可以自动搜索最佳的prompt,提升效果。
- 也可以加一下anchor tokens例如(b)中蓝色Britain提升效果。
3. LAMA数据集表现
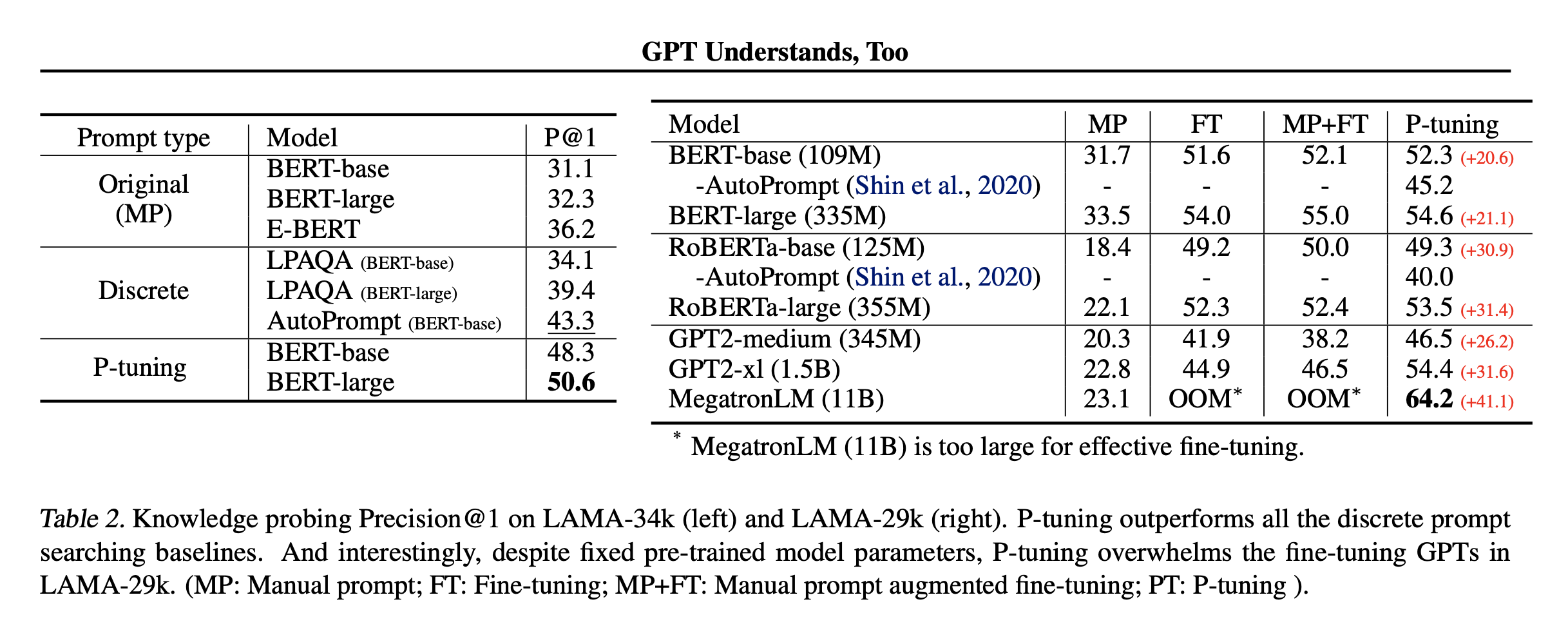
- MP:人工prompt
- FT:Fine-tuning方法,全量参数微调
- MP+FT:人工prompt+fine-tuning增强
- P- tuning:本文方法
- 结论:比所有离散prompt搜索方法都要好很多
4 SuperGlue数据集表现
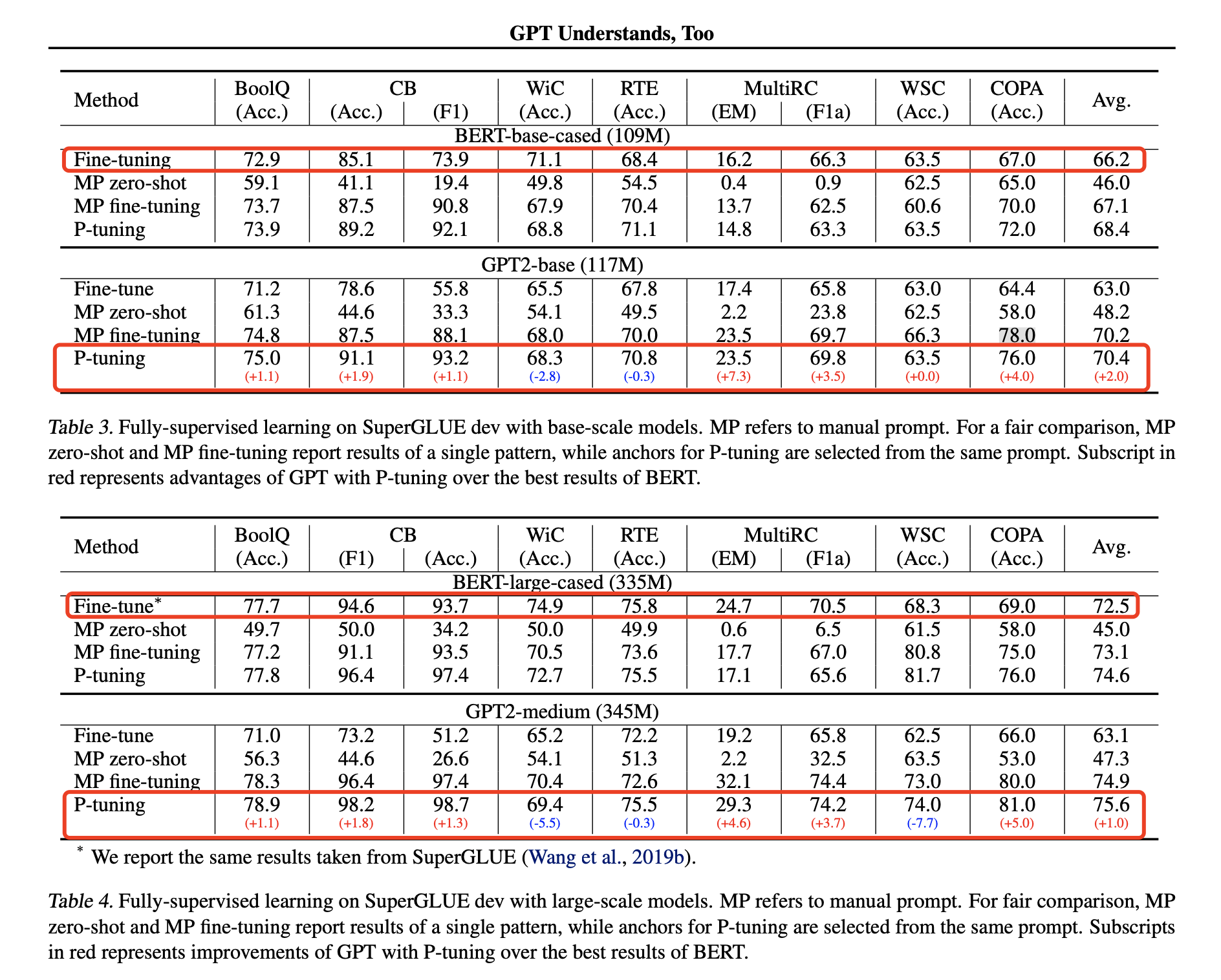
- 比较了base版本和large版本,GPT-P-tuning的效果比fine-tune版本好很多,甚至有些能超过同等尺寸BERT fine-tune效果。
5 few-shot效果

- 32 few-shot的效果也还不错,比之前的PET系列的方法都要提升不少。

- 与人工设计的prompts方法和tuned prompts方法对比,在RTE任务上表现好不少。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结