您现在的位置是:首页 >技术交流 >Transformer架构解析网站首页技术交流
Transformer架构解析
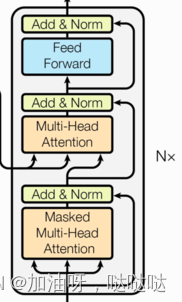
1.Transformer架构图
本文主要来自:http://nlp.seas.harvard.edu/annotated-transformer/#hardware-and-schedule
论文地址: https://arxiv.org/pdf/1810.04805.pdf
1.1 Transformer模型的作用
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务, 如机器翻译, 文本生成等. 同时又可以构建预训练语言模型,用于不同任务的迁移学习.
1.2 Transformer总体架构

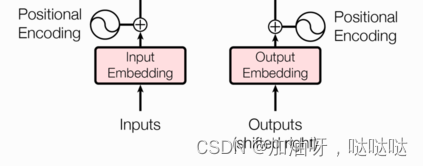
(1)输入部分
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
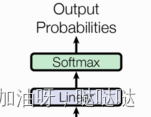
(2)输出部分
- 线性层
- softmax层
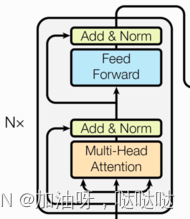
(3)编码器
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
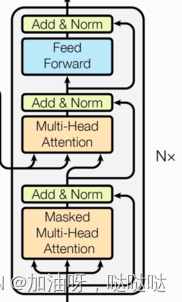
(4)解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
2.输入部分Embeddings
2.1文本嵌入层
无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示, 希望在这样的高维空间捕捉词汇间的关系.
(1)实现
- 初始化函数以
d_model, 词嵌入维度, 和vocab, 词汇总数为参数, 内部主要使用了nn中的预定层Embedding进行词嵌入. - 在forward函数中, 将输入x传入到Embedding的实例化对象中, 然后乘以一个根号下
d_model进行缩放, 控制数值大小。 - 它的输出是文本嵌入后的结果。
# torch中变量封装函数Variable.
from torch.autograd import Variable
# 定义Embeddings类来实现文本嵌入层,这里s说明代表两个一模一样的嵌入层, 他们共享参数.
# 该类继承nn.Module, 这样就有标准层的一些功能, 这里我们也可以理解为一种模式, 我们自己实现的所有层都会这样去写.
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""类的初始化函数,
d_model: 指词嵌入的维度,
vocab: 指词表的大小.
"""
# 接着就是使用super的方式指明继承nn.Module的初始化函数, 我们自己实现的所有层都会这样去写.
super(Embeddings, self).__init__()
# 之后就是调用nn中的预定义层Embedding, 获得一个词嵌入对象self.lut
self.lut = nn.Embedding(vocab, d_model)
# 最后就是将d_model传入类中
self.d_model = d_model
def forward(self, x):
""" x: 因为Embedding层是首层, 所以代表输入给模型的文本通过词汇映射后的张量
"""
# 将x传给self.lut并与根号下self.d_model相乘作为结果返回
return self.lut(x) * math.sqrt(self.d_model)
(2)测试
# 词嵌入维度是512维
d_model = 512
# 词表大小是1000
vocab = 1000
# 输入x是一个使用Variable封装的长整型张量, 形状是2 x 4
x = Variable(torch.LongTensor([[100,2,421,508],[491,998,1,221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)
print("embr:", embr)
embr: Variable containing:
( 0 ,.,.) =
35.9321 3.2582 -17.7301 ... 3.4109 13.8832 39.0272
8.5410 -3.5790 -12.0460 ... 40.1880 36.6009 34.7141
-17.0650 -1.8705 -20.1807 ... -12.5556 -34.0739 35.6536
20.6105 4.4314 14.9912 ... -0.1342 -9.9270 28.6771
( 1 ,.,.) =
27.7016 16.7183 46.6900 ... 17.9840 17.2525 -3.9709
3.0645 -5.5105 10.8802 ... -13.0069 30.8834 -38.3209
33.1378 -32.1435 -3.9369 ... 15.6094 -29.7063 40.1361
-31.5056 3.3648 1.4726 ... 2.8047 -9.6514 -23.4909
[torch.FloatTensor of size 2x4x512]
2.2 位置编码器PositionalEncoding
因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
使用不同频率的正弦和余弦函数:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos是位置, i i i 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个从 2 π 2pi 2π 到 10000 ⋅ 2 π 10000 cdot 2pi 10000⋅2π的集合级数。我们选择这个函数是因为我们假设它会让模型很容易学习对相对位置的关注,因为对任意确定的偏移k , P E p o s + k PE_{pos+k} PEpos+k可以表示为 P E p o s PE_{pos} PEpos的线性函数。
(1)实现
- 初始化函数以
d_model,dropout,max_len为参数, 分别代表d_model: 词嵌入维度,dropout: 置0比率,max_len: 每个句子的最大长度. - forward函数中的输入参数为x, 是Embedding层的输出.
- 最终输出一个加入了位置编码信息的词嵌入张量.
# 定义位置编码器类, 我们同样把它看做一个层, 因此会继承nn.Module
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""位置编码器类的初始化函数, 共有三个参数, 分别是
d_model: 词嵌入维度,
dropout: 置0比率,
max_len: 每个句子的最大长度
"""
super(PositionalEncoding, self).__init__()
# 实例化nn中预定义的Dropout层, 并将dropout传入其中, 获得对象self.dropout
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵, 它是一个0阵,矩阵的大小是max_len x d_model.
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵, 在我们这里,词汇的绝对位置就是用它的索引去表示.
# 所以我们首先使用arange方法获得一个连续自然数向量,然后再使用unsqueeze方法拓展向量维度使其成为矩阵,
# 又因为参数传的是1,代表矩阵拓展的位置,会使向量变成一个max_len x 1 的矩阵,
position = torch.arange(0, max_len).unsqueeze(1)
# 绝对位置矩阵初始化之后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中,
# 最简单思路就是先将max_len x 1的绝对位置矩阵, 变换成max_len x d_model形状,然后覆盖原来的初始位置编码矩阵即可,
# 要做这种矩阵变换,就需要一个1xd_model形状的变换矩阵div_term,我们对这个变换矩阵的要求除了形状外,
# 还希望它能够将自然数的绝对位置编码缩放成足够小的数字,有助于在之后的梯度下降过程中更快的收敛. 这样我们就可以开始初始化这个变换矩阵了.
# 首先使用arange获得一个自然数矩阵, 但是细心的同学们会发现, 我们这里并没有按照预计的一样初始化一个1xd_model的矩阵,
# 而是有了一个跳跃,只初始化了一半即1xd_model/2 的矩阵。 为什么是一半呢,其实这里并不是真正意义上的初始化了一半的矩阵,
# 我们可以把它看作是初始化了两次,而每次初始化的变换矩阵会做不同的处理,第一次初始化的变换矩阵分布在正弦波上, 第二次初始化的变换矩阵分布在余弦波上,
# 并把这两个矩阵分别填充在位置编码矩阵的偶数和奇数位置上,组成最终的位置编码矩阵.
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 这样我们就得到了位置编码矩阵pe, pe现在还只是一个二维矩阵,要想和embedding的输出(一个三维张量)相加,
# 就必须拓展一个维度,所以这里使用unsqueeze拓展维度.
pe = pe.unsqueeze(0)
# 最后把pe位置编码矩阵注册成模型的buffer,什么是buffer呢,
# 我们把它认为是对模型效果有帮助的,但是却不是模型结构中超参数或者参数,不需要随着优化步骤进行更新的增益对象.
# 注册之后我们就可以在模型保存后重加载时和模型结构与参数一同被加载.
self.register_buffer('pe', pe)
def forward(self, x):
""" x, 表示文本序列的词嵌入表示 """
# 在相加之前我们对pe做一些适配工作, 将这个三维张量的第二维也就是句子最大长度的那一维将切片到与输入的x的第二维相同即x.size(1),
# 因为我们默认max_len为5000一般来讲实在太大了,很难有一条句子包含5000个词汇,所以要进行与输入张量的适配.
# 最后使用Variable进行封装,使其与x的样式相同,但是它是不需要进行梯度求解的,因此把requires_grad设置成false.
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
# 最后使用self.dropout对象进行'丢弃'操作, 并返回结果.
return self.dropout(x)
(2)测试
# 词嵌入维度是512维
d_model = 512
# 置0比率为0.1
dropout = 0.1
# 句子最大长度
max_len=60
x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
print("pe_result:", pe_result)
pe_result: Variable containing:
( 0 ,.,.) =
-19.7050 0.0000 0.0000 ... -11.7557 -0.0000 23.4553
-1.4668 -62.2510 -2.4012 ... 66.5860 -24.4578 -37.7469
9.8642 -41.6497 -11.4968 ... -21.1293 -42.0945 50.7943
0.0000 34.1785 -33.0712 ... 48.5520 3.2540 54.1348
( 1 ,.,.) =
7.7598 -21.0359 15.0595 ... -35.6061 -0.0000 4.1772
-38.7230 8.6578 34.2935 ... -43.3556 26.6052 4.3084
24.6962 37.3626 -26.9271 ... 49.8989 0.0000 44.9158
-28.8435 -48.5963 -0.9892 ... -52.5447 -4.1475 -3.0450
[torch.FloatTensor of size 2x4x512]
(3)绘制词汇向量中特征的分布曲线
import matplotlib.pyplot as plt
# 创建一张15 x 5大小的画布
plt.figure(figsize=(15, 5))
# 实例化PositionalEncoding类得到pe对象, 输入参数是20和0
pe = PositionalEncoding(20, 0)
# 然后向pe传入被Variable封装的tensor, 这样pe会直接执行forward函数,
# 且这个tensor里的数值都是0, 被处理后相当于位置编码张量
y = pe(Variable(torch.zeros(1, 100, 20)))
# 然后定义画布的横纵坐标, 横坐标到100的长度, 纵坐标是某一个词汇中的某维特征在不同长度下对应的值
# 因为总共有20维之多, 我们这里只查看4,5,6,7维的值.
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
# 在画布上填写维度提示信息
plt.legend(["dim %d"%p for p in [4,5,6,7]])
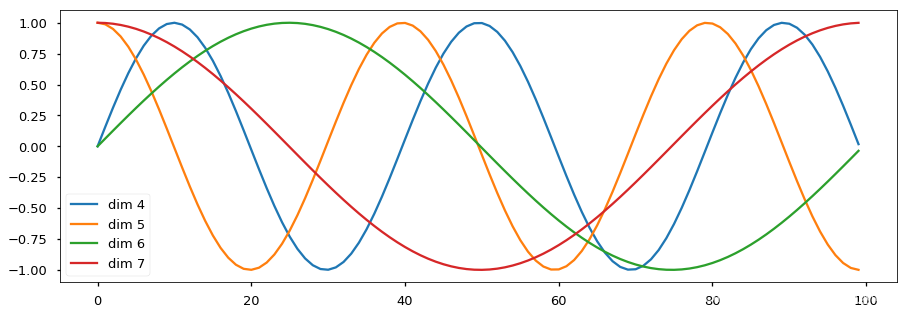
效果分析:
- 每条颜色的曲线代表某一个词汇中的特征在不同位置的含义.
- 保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化。
- 正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算。
3.编码器
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
3.1 掩码张量subsequent_mask
掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换, 它的表现形式是一个张量
掩码张量的作用:在transformer中, 掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用。
(1)实现
def subsequent_mask(size):
"""生成向后遮掩的掩码张量,
参数size是掩码张量最后两个维度的大小, 它的最后两维形成一个方阵
"""
# 在函数中, 首先定义掩码张量的形状
attn_shape = (1, size, size)
# 然后使用np.ones方法向这个形状中添加1元素,形成上三角阵, 最后为了节约空间,
# 再使其中的数据类型变为无符号8位整形unit8
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor, 内部做一个1 - 的操作,
# 在这个其实是做了一个三角阵的反转, subsequent_mask中的每个元素都会被1减,
# 如果是0, subsequent_mask中的该位置由0变成1
# 如果是1, subsequent_mask中的该位置由1变成0
return torch.from_numpy(1 - subsequent_mask)
(2)测试
# 生成的掩码张量的最后两维的大小
size = 5
sm = subsequent_mask(size)
print("sm:", sm)
tensor([[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]], dtype=torch.uint8)
(3)掩码张量的可视化
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
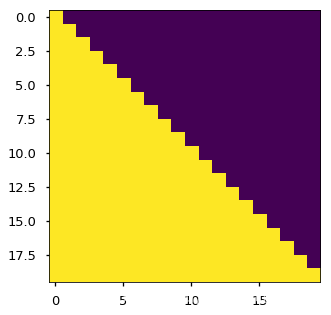
效果分析:
- 通过观察可视化方阵, 黄色是1的部分, 这里代表被遮掩, 紫色代表没有被遮掩的信息, 横坐标代表目标词汇的位置, 纵坐标代表可查看的位置;
- 我们看到, 在0的位置我们一看望过去都是黄色的, 都被遮住了,1的位置一眼望过去还是黄色, 说明第一次词还没有产生, 从第二个位置看过去, 就能看到位置1的词, 其他位置看不到, 以此类推.
3.2 注意力机制Attention
(1)什么是注意力
我们观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的), 是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果。正是基于这样的理论,就产生了注意力机制。
Attention功能可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。输出为value的加权和,其中每个value的权重通过query与相应key的兼容函数来计算。
(2)注意力计算规则
需要三个指定的输入Q(query), K(key), V(value), 然后通过公式得到注意力的计算结果, 这个结果代表query在key和value作用下的表示。而这个具体的计算规则有很多种,我这里只介绍我们用到的这一种.
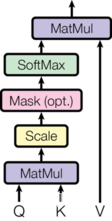
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(frac{QK^T}{sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
(3)Q, K, V的比喻解释
假如我们有一个问题: 给出一段文本,使用一些关键词对它进行描述!
为了方便统一正确答案,这道题可能预先已经给大家写出了一些关键词作为提示.其中这些给出的提示就可以看作是key, 而整个的文本信息就相当于是query,value的含义则更抽象,可以比作是你看到这段文本信息后,脑子里浮现的答案信息,这里我们又假设大家最开始都不是很聪明,第一次看到这段文本后脑子里基本上浮现的信息就只有提示这些信息,因此key与value基本是相同的,但是随着我们对这个问题的深入理解,通过我们的思考脑子里想起来的东西原来越多,并且能够开始对我们query也就是这段文本,提取关键信息进行表示. 这就是注意力作用的过程, 通过这个过程,我们最终脑子里的value发生了变化,根据提示key生成了query的关键词表示方法,也就是另外一种特征表示方法.
刚刚我们说到key和value一般情况下默认是相同,与query是不同的,这种是我们一般的注意力输入形式,但有一种特殊情况,就是我们query与key和value相同,这种情况我们称为自注意力机制,就如同我们的刚刚的例子, 使用一般注意力机制,是使用不同于给定文本的关键词表示它. 而自注意力机制,需要用给定文本自身来表达自己,也就是说你需要从给定文本中抽取关键词来表述它, 相当于对文本自身的一次特征提取.
(4)注意力机制
注意力机制是注意力计算规则能够应用的深度学习网络的载体, 除了注意力计算规则外, 还包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体。使用自注意力计算规则的注意力机制称为自注意力机制。
将particular attention称之为“缩放的点积Attention”(Scaled Dot-Product Attention")。其输入为query、key(维度是 d k d_k dk)以及values(维度是 d v d_v dv)。我们计算query和所有key的点积,然后对每个除以 d k sqrt{d_k} dk , 最后用softmax函数获得value的权重。
两个最常用的attention函数是加法attention(cite)和点积(乘法)attention。除了缩放因子 1 d k frac{1}{sqrt{d_k}} dk1 ,点积Attention跟我们的平时的算法一样。加法attention使用具有单个隐层的前馈网络计算兼容函数。虽然理论上点积attention和加法attention复杂度相似,但在实践中,点积attention可以使用高度优化的矩阵乘法来实现,因此点积attention计算更快、更节省空间。
当 d k d_k dk的值比较小的时候,这两个机制的性能相近。当 d k d_k dk比较大时,加法attention比不带缩放的点积attention性能好 (cite)。我们怀疑,对于很大的 d k d_k dk值, 点积大幅度增长,将softmax函数推向具有极小梯度的区域。(为了说明为什么点积变大,假设 q q q和 k k k是独立的随机变量,均值为0,方差为1。那么它们的点积 q ⋅ k = ∑ i = 1 d k q i k i q cdot k = sum_{i=1}^{d_k} q_ik_i q⋅k=∑i=1dkqiki, 均值为0方差为 d k d_k dk)。为了抵消这种影响,我们将点积缩小 1 d k frac{1}{sqrt{d_k}} dk1 倍。
为什么Attention中除以 ∗ ∗ d ∗ ∗ **sqrt{d}** ∗∗d∗∗** 这么重要?**
Attention的计算是在内积之后进行softmax,主要涉及的运算是 e q ⋅ k e^{q cdot k} eq⋅k,可以大致认为内积之后、softmax之前的数值在 − 3 d -3sqrt{d} −3d到 3 d 3sqrt{d} 3d这个范围内,由于d通常都至少是64,所以 e 3 d e^{3sqrt{d}} e3d比较大而 e − 3 d e^{-3sqrt{d}} e−3d比较小,因此经过softmax之后,Attention的分布非常接近一个one hot分布了,这带来严重的梯度消失问题,导致训练效果差。(例如y=softmax(x)在|x|较大时进入了饱和区,x继续变化y值也几乎不变,即饱和区梯度消失)
相应地,解决方法就有两个:
-
像NTK参数化那样,在内积之后除以 d sqrt{d} d,使q⋅k的方差变为1,对应 e 3 , e − 3 e^3,e^{−3} e3,e−3都不至于过大过小,这样softmax之后也不至于变成one hot而梯度消失了,这也是常规的Transformer如BERT里边的Self Attention的做法
-
另外就是不除以 d sqrt{d} d,但是初始化q,k的全连接层的时候,其初始化方差要多除以一个d,这同样能使得使q⋅k的初始方差变为1,T5采用了这样的做法。
(5)代码实现
- 输入就是Q,K,V以及mask和dropout, mask用于掩码, dropout用于随机置0.
- 输出有两个, query的注意力表示以及注意力张量.
def attention(query, key, value, mask=None, dropout=None):
"""注意力机制的实现,
输入分别是query, key, value, mask: 掩码张量,
dropout是nn.Dropout层的实例化对象, 默认为None
"""
# 将query的最后一个维度提取出来,代表的是词嵌入的维度
d_k = query.size(-1)
# 按照注意力公式, 将query与key的转置相乘, 这里面key是将最后两个维度进行转置,
# 再除以缩放系数根号下d_k, 这种计算方法也称为缩放点积注意力计算.
# 得到注意力得分张量scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 接着判断是否使用掩码张量
if mask is not None:
# 使用tensor的masked_fill方法, 将掩码张量和scores张量每个位置一一比较,
# 如果掩码张量处为0,则对应的scores张量用-1e9这个值来替换, 如下演示
scores = scores.masked_fill(mask == 0, -1e9)
# 对scores的最后一维进行softmax操作, 使用F.softmax方法, 第一个参数是softmax对象, 第二个是目标维度.
# 这样获得最终的注意力张量
p_attn = scores.softmax(dim=-1)
# 之后判断是否使用dropout进行随机置0
if dropout is not None:
# 将p_attn传入dropout对象中进行'丢弃'处理
p_attn = dropout(p_attn)
# 最后, 根据公式将p_attn与value张量相乘获得最终的query注意力表示, 同时返回注意力张量
return torch.matmul(p_attn, value), p_attn
(6)测试
from embedding import Embeddings
from positional_encoding import PositionalEncoding
d_model = 512
dropout = 0.1
max_len = 60
vocab = 1000
emb = Embeddings(d_model, vocab)
input = Variable(torch.LongTensor([[1,2,4,5], [4,3,2,9]]))
embr = emb(input)
print("embr: ", embr)
print(embr.shape)
pe = PositionalEncoding(d_model, dropout, max_len)
pe_res = pe(embr)
query = key = value = pe_res
attn, p_attn = attention(query, key, value)
print("attn:", attn)
print("attn shape:", attn.shape)
print("p_attn:", p_attn)
print("p_attn shape:", p_attn.shape)
attn: tensor([[[ -6.9986, -22.1325, 44.3268, ..., 0.0000, -2.9953, -3.8844],
[ 57.2318, 5.9384, 0.0000, ..., 38.5518, 0.5860, 12.5283],
[-56.2970, 0.0000, -4.3592, ..., 26.0355, -2.3129, 0.0000],
[ -2.1557, 3.4803, -36.6878, ..., 15.8174, -21.3978, -30.9041]],
[[-57.3073, -25.4691, -5.3997, ..., 26.0355, -2.3131, 14.3969],
[ 6.9673, -32.6722, 39.3464, ..., -5.4699, -10.4042, -4.4331],
[ 57.3072, 4.8757, -5.6530, ..., 38.5518, 0.5862, 0.0000],
[ 18.3028, -9.1978, 59.9258, ..., -9.5552, -45.4553, 0.0000]]],
grad_fn=<UnsafeViewBackward>)
attn shape: torch.Size([2, 4, 512])
p_attn: tensor([[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]],
[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]]], grad_fn=<SoftmaxBackward>)
p_attn shape: torch.Size([2, 4, 4])
待用mask的输出效果
query = key = value = pe_result
# 令mask为一个2x4x4的零张量
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
print("attn:", attn)
print("p_attn:", p_attn)
# query的注意力表示:
attn: Variable containing:
( 0 ,.,.) =
0.4284 -7.4741 8.8839 ... 1.5618 0.5063 0.5770
0.4284 -7.4741 8.8839 ... 1.5618 0.5063 0.5770
0.4284 -7.4741 8.8839 ... 1.5618 0.5063 0.5770
0.4284 -7.4741 8.8839 ... 1.5618 0.5063 0.5770
( 1 ,.,.) =
-2.8890 9.9972 -12.9505 ... 9.1657 -4.6164 -0.5491
-2.8890 9.9972 -12.9505 ... 9.1657 -4.6164 -0.5491
-2.8890 9.9972 -12.9505 ... 9.1657 -4.6164 -0.5491
-2.8890 9.9972 -12.9505 ... 9.1657 -4.6164 -0.5491
[torch.FloatTensor of size 2x4x512]
# 注意力张量:
p_attn: Variable containing:
(0 ,.,.) =
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
(1 ,.,.) =
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
0.2500 0.2500 0.2500 0.2500
[torch.FloatTensor of size 2x4x4]
3.3 多头注意力机制MultiHeadAttention
(1)什么是多头注意力机制
从多头注意力的结构图中,貌似这个所谓的多个头就是指多组线性变换层,其实并不是,我只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q,K,V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分,也就是只分割了最后一维的词嵌入向量。这就是所谓的多头,将每个头的获得的输入送到注意力机制中, 就形成多头注意力机制.
Multi-head attention允许模型共同关注来自不同位置的不同表示子空间的信息,如果只有一个attention head,它的平均值会削弱这个信息。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O \ where ~ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中映射由权重矩阵完成:$W^Q_i in mathbb{R}^{d_{{model}} imes d_k}
$,
W
i
K
∈
R
d
model
×
d
k
W^K_i in mathbb{R}^{d_{ ext{model}} imes d_k}
WiK∈Rdmodel×dk,
W
i
V
∈
R
d
model
×
d
v
W^V_i in mathbb{R}^{d_{ ext{model}} imes d_v}
WiV∈Rdmodel×dv和
W
i
O
∈
R
h
d
v
×
d
model
W^O_i in mathbb{R}^{hd_v imes d_{ ext{model}} }
WiO∈Rhdv×dmodel。
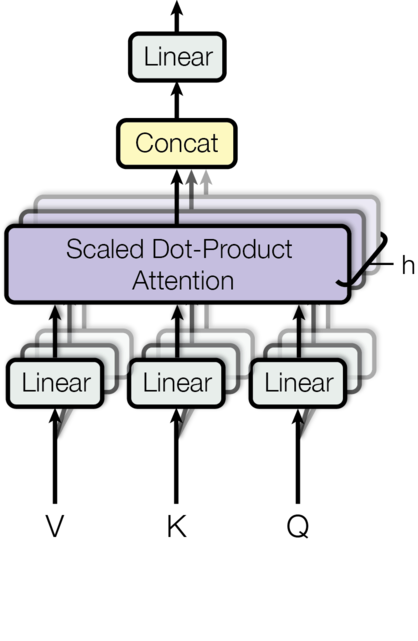
(2)多头注意力作用
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果.
(3)实现
- 因为多头注意力机制中需要使用多个相同的线性层, 首先实现了克隆函数clones.
- clones函数的输入是module,N,分别代表克隆的目标层,和克隆个数.
- clones函数的输出是装有N个克隆层的Module列表.
- 接着实现MultiHeadedAttention类, 它的初始化函数输入是h, d_model, dropout分别代表头数,词嵌入维度和置零比率.
- 它的实例化对象输入是Q, K, V以及掩码张量mask.
- 它的实例化对象输出是通过多头注意力机制处理的Q的注意力表示.
import copy
def clones(model, N):
"""
用于生成相同网络层的克隆函数,
- module表示要克隆的目标网络层,
- N代表需要克隆的数量
"""
# 在函数中, 我们通过for循环对module进行N次深度拷贝, 使其每个module成为独立的层,
# 然后将其放在nn.ModuleList类型的列表中存放.
return nn.ModuleList([copy.deepcopy(model) for _ in range(N)])
class MultiHeadAttention(nn.Module):
"""
"""
def __init__(self, head, embedding_dim, dropout=0.1):
super(MultiHeadAttention, self).__init__()
""" 多头注意力机制
- head代表头数
- embedding_dim代表词嵌入的维度,
- dropout代表进行dropout操作时置0比率,默认是0.1
"""
# 在函数中,首先使用了一个测试中常用的assert语句,判断h是否能被d_model整除,
# 这是因为我们之后要给每个头分配等量的词特征.也就是embedding_dim/head个.
assert embedding_dim % head == 0
# 得到每个头获得的分割词向量维度d_k
self.d_k = embedding_dim // head
# 传入头数head
self.head = head
# 然后获得线性层对象,通过nn的Linear实例化,
# 它的内部变换矩阵是embedding_dim x embedding_dim,
# 然后使用clones函数克隆四个,为什么是四个呢,
# 这是因为在多头注意力中,Q,K,V各需要一个,
# 最后拼接的矩阵还需要一个,因此一共是四个.
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# self.attn为None,它代表最后得到的注意力张量,现在还没有结果所以为None.
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
""" 输入参数有四个,前三个就是注意力机制需要的Q, K, V,
最后一个是注意力机制中可能需要的mask掩码张量,默认是None.
"""
# 如果存在掩码张量mask
if mask is not None:
# 使用unsqueeze拓展维度
mask = mask.unsqueeze(0)
# 接着,我们获得一个batch_size的变量,他是query尺寸的第1个数字,代表有多少条样本.
batch_size = query.size(0)
# 之后就进入多头处理环节
# 首先利用zip将输入QKV与三个线性层组到一起,然后使用for循环,
# 将输入QKV分别传到线性层中,做完线性变换后,
# 开始为每个头分割输入,这里使用view方法对线性变换的结果进行维度重塑,多加了一个维度h,代表头数,
# 这样就意味着每个头可以获得一部分词特征组成的句子,其中的-1代表自适应维度,
# 计算机会根据这种变换自动计算这里的值.然后对第二维和第三维进行转置操作,
# 为了让代表句子长度维度和词向量维度能够相邻,
# 这样注意力机制才能找到词义与句子位置的关系,
# 从attention函数中可以看到,利用的是原始输入的倒数第一和第二维.
# 这样我们就得到了每个头的输入.
query, key, value = [
model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))
]
# 得到每个头的输入后,接下来就是将他们传入到attention中,
# 这里直接调用我们之前实现的attention函数.同时也将mask和dropout传入其中.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 通过多头注意力计算后,我们就得到了每个头计算结果组成的4维张量,
# 我们需要将其转换为输入的形状以方便后续的计算,
# 因此这里开始进行第一步处理环节的逆操作,
# 先对第二和第三维进行转置,然后使用contiguous方法,
# 这个方法的作用就是能够让转置后的张量应用view方法,否则将无法直接使用,
# 所以,下一步就是使用view重塑形状,变成和输入形状相同.
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)
# 最后使用线性层列表中的最后一个线性层对输入进行线性变换得到最终的多头注意力结构的输出.
return self.linears[-1](x)
(4)测试
d_model = 512
dropout = 0.1
max_len = 60
vocab = 1000
emb = Embeddings(d_model, vocab)
input = Variable(torch.LongTensor([[1,2,4,5], [4,3,2,9]]))
embr = emb(input)
pe = PositionalEncoding(d_model, dropout, max_len)
pe_res = pe(embr)
head = 8
embedding_dim = 512
dropout = 0.2
query = key = value = pe_res
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadAttention(head, embedding_dim, dropout)
mha_res = mha(query, key, value, mask)
tensor([[[-2.3411, -0.8430, -4.1038, ..., 1.4731, -0.7992, 0.9026],
[-5.1657, -2.4703, -7.4543, ..., 0.8810, 0.3061, 0.6387],
[-4.2553, -0.1940, -6.1963, ..., -3.4095, 0.6791, -0.6660],
[-4.8889, -4.0475, -5.9836, ..., -3.4044, 0.5312, 0.7642]],
[[-4.8633, 2.5490, -6.3160, ..., -1.7124, -2.2730, 0.7630],
[-5.1141, 2.4704, -4.4557, ..., 2.4667, -0.3286, 0.8127],
[-8.8165, 1.9820, -6.3692, ..., -1.9055, 2.4552, -6.4086],
[-6.2969, 2.9008, -1.2483, ..., 0.1594, -4.0804, 0.0228]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.4 前馈全连接层PositionwiseFeedForward
在Transformer中前馈全连接层就是具有两层线性层的全连接网络.
(1)前馈全连接层作用
考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, ~ xW_1+b_1)W_2+b_2 FFN(x)=max(0, xW1+b1)W2+b2
Position就是序列中每个token,
Position-wise就是把MLP对每个token作用一次,且作用的是同一个MLP。
(2)代码实现
- 实例化参数为
d_model,d_ff,dropout, 分别代表词嵌入维度, 线性变换维度, 和置零比率. - 输入参数x, 表示上层的输出.
- 输出是经过2层线性网络变换的特征表示.
class PositionwiseFeedForward(nn.Module):
""" 实现前馈全连接层
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
"""
- d_model: 线性层的输入维度也是第二个线性层的输出维度,
因为我们希望输入通过前馈全连接层后输入和输出的维度不变.
- d_ff: 第二个线性层的输入维度和第一个线性层的输出维度.
- dropout: 置0比率
"""
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
# 首先经过第一个线性层,然后使用Funtional中relu函数进行激活,
# 之后再使用dropout进行随机置0,最后通过第二个线性层w2,返回最终结果.
return self.w2(self.dropout(self.w1(x).relu()))
(3)测试
d_model = 512
# 线性变化的维度
d_ff = 64
dropout = 0.2
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
print(mha_res.shape)
ff_result = ff(mha_res)
print(ff_result)
torch.Size([2, 4, 512])
tensor([[[-2.8747, -0.1289, -0.4966, ..., -1.2763, -2.0888, 0.3344],
[-1.2404, 0.3891, 1.3854, ..., -1.2675, -1.8324, 0.2271],
[-1.6913, 1.2393, 0.1528, ..., -0.7420, -2.5605, 0.9924],
[-3.4989, 1.4898, -0.7094, ..., -1.1352, -1.9817, 0.4473]],
[[-2.0806, 0.1014, 1.4044, ..., 0.1496, -2.4822, -1.5388],
[-3.5828, 0.3326, 1.2598, ..., 0.8470, -2.5095, 0.1296],
[-2.7594, -0.2307, 1.4870, ..., 1.1056, -2.3847, -1.6484],
[-1.1717, -1.2086, 0.6444, ..., -0.5858, -3.3344, -0.9535]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.5 规范化层LayerNorm
(1)规范化层作用
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢。 因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内.
(2)代码实现
- 实例化参数有两个,
features和eps,分别表示词嵌入特征大小,和一个足够小的数. - 输入参数x代表来自上一层的输出.
- 输出就是经过规范化的特征表示.
class LayerNorm(nn.Module):
""" 实现规范化层的类
"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
""" 初始化参数
- features: 表示词嵌入的维度,
- eps: 一个足够小的数, 在规范化公式的分母中出现,防止分母为0.默认是1e-6.
"""
# 根据features的形状初始化两个参数张量a2,和b2,第一个初始化为1张量,
# 也就是里面的元素都是1,第二个初始化为0张量,也就是里面的元素都是0,
# 这两个张量就是规范化层的参数,因为直接对上一层得到的结果做规范化公式计算,
# 将改变结果的正常表征,因此就需要有参数作为调节因子,使其即能满足规范化要求,
# 又能不改变针对目标的表征.最后使用nn.parameter封装,代表他们是模型的参数。
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"""
"""
# 在函数中,首先对输入变量x求其最后一个维度的均值,并保持输出维度与输入维度一致.
# 接着再求最后一个维度的标准差,然后就是根据规范化公式,
# 用x减去均值除以标准差获得规范化的结果,
# 最后对结果乘以我们的缩放参数,即a2,*号代表同型点乘,即对应位置进行乘法操作,
# 加上位移参数b2.返回即可.
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
(3)测试
features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
print(mha_res.shape)
ln_result = ln(x)
print(ln_result)
print(ln_result.shape)
torch.Size([2, 4, 512])
tensor([[[-0.6481, 0.6222, -0.2731, ..., 0.2868, 1.0175, 0.6720],
[-0.3056, 0.6657, 0.1862, ..., 0.3972, 0.9435, 0.5340],
[-0.1928, 1.0572, 0.3111, ..., -0.0410, 0.5555, 0.5671],
[-0.4334, -0.2361, -0.1477, ..., 0.0923, 2.0700, 0.7032]],
[[ 1.0477, -0.7183, 0.0449, ..., 1.6828, 0.3927, 0.5616],
[ 1.5125, -1.1870, 0.5266, ..., 1.4665, 1.8670, 0.2973],
[ 0.8196, -2.3064, -0.2661, ..., 1.0591, 1.1476, -0.2259],
[ 0.3523, -0.5912, 0.5318, ..., 1.0312, 0.6859, -0.6222]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.6 子层连接结构SublayerConnection
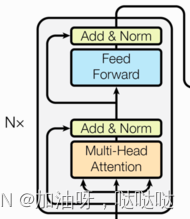
如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.
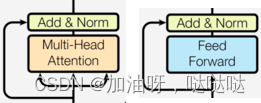
(1)代码实现
- 类的初始化函数输入参数是
size,dropout, 分别代表词嵌入大小和置零比率. - 它的实例化对象输入参数是
x,sublayer, 分别代表上一层输出以及子层的函数表示. - 它的输出就是通过子层连接结构处理的输出.
class SublayerConnection(nn.Module):
""" 子层连接结构的类
"""
def __init__(self, size, dropout=0.1):
""" 初始化
- size: 词嵌入维度的大小,
- dropout: 是对模型结构中的节点数进行随机抑制的比率,
"""
super(SublayerConnection, self).__init__()
# 实例化了规范化对象self.norm
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
""" 前向逻辑函数中, 接收上一个层或者子层的输入作为第一个参数,
将该子层连接中的子层函数作为第二个参数
"""
# 我们首先对输出进行规范化,然后将结果传给子层处理,之后再对子层进行dropout操作,
# 随机停止一些网络中神经元的作用,来防止过拟合. 最后还有一个add操作,
# 因为存在跳跃连接,所以是将输入x与dropout后的子层输出结果相加作为最终的子层连接输出.
return x + self.dropout(sublayer(self.norm(x)))
(2)测试
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadAttention(head, embedding_dim, dropout)
sublayer = lambda x : mha(x, x, x, mask)
size = 512
sc = SublayerConnection(size, dropout)
print(x.shape)
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
torch.Size([2, 4, 512])
tensor([[[ -8.1109, 0.2217, 1.0194, ..., 22.8768, 40.2057, 14.8928],
[ 31.5267, 33.8321, 29.1483, ..., 17.2134, -16.1430, -4.6771],
[ 7.9553, -20.3707, -41.5156, ..., -10.6798, -23.8106, 4.3206],
[-59.5128, 31.6802, 1.1462, ..., -15.4225, -2.6904, 45.0427]],
[[ 6.9450, -18.4468, -42.5561, ..., -10.3473, -23.6293, 4.3888],
[-38.2155, 46.7522, -22.8546, ..., 28.8744, -0.0767, 13.4702],
[ 31.4326, 33.3512, 29.2566, ..., 17.6481, -16.0407, -4.4314],
[-16.7070, -15.7774, 16.0646, ..., -65.1326, 0.0000, 0.1910]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.7 编码器层EncoderLayer
作为编码器的组成单元,** 每个编码器层完成一次对输入的特征提取过程**, 即编码过程.
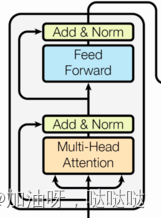
(1)代码实现
- 类的初始化函数共有4个, 第一个是
size,其实就是我们词嵌入维度的大小. 第二个self_attn,之后我们将传入多头自注意力子层实例化对象, 并且是自注意力机制. 第三个是feed_froward, 之后我们将传入前馈全连接层实例化对象. 最后一个是置0比率dropout. - 实例化对象的输入参数有2个,x代表来自上一层的输出, mask代表掩码张量.
- 它的输出代表经过整个编码层的特征表示.
class EncoderLayer(nn.Module):
""" 编码器层
"""
def __init__(self, size, self_attn, feed_forward, dropout):
""" 初始化
- size: 词嵌入维度的大小,它也将作为我们编码器层的大小,
- self_attn: 传入多头自注意力子层实例化对象, 并且是自注意力机制,
- eed_froward: 传入前馈全连接层实例化对象,
- dropout: 置0比率
"""
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
# 如图所示, 编码器层中有两个子层连接结构, 所以使用clones函数进行克隆
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
""" x和mask,分别代表上一层的输出,和掩码张量mask
"""
# 首先通过第一个子层连接结构,其中包含多头自注意力子层,
# 然后通过第二个子层连接结构,其中包含前馈全连接子层. 最后返回结果.
x = self.sublayer[0](x, lambda x : self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
(2)测试
size = d_model = 512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
print(x.shape)
el_result = el(x, mask)
print(el_result)
print(el_result.shape)
torch.Size([2, 4, 512])
tensor([[[-29.5621, -2.0977, 2.6601, ..., 33.7814, -41.1742, -10.7692],
[ 36.1439, -27.8296, -23.2643, ..., 21.5115, -4.6657, 14.0641],
[ -8.1926, -29.1385, -2.2535, ..., -5.4215, 2.7747, -0.4909],
[-25.4288, -14.2624, -22.5432, ..., -5.3338, 9.2610, 4.8978]],
[[ -9.4071, -27.6196, -2.8486, ..., -5.1319, 2.3754, 14.1391],
[-15.6512, -1.9466, -36.3869, ..., 19.8941, 24.4394, 40.9649],
[ 36.5416, -28.4673, -22.8311, ..., 21.5283, -4.6554, 14.3312],
[-30.7237, 38.2961, -8.4991, ..., 57.8437, 11.2464, -5.4290]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.8 编码器Encoder
编码器用于对输入进行指定的特征提取过程, 也称为编码, 由N个编码器层堆叠而成.
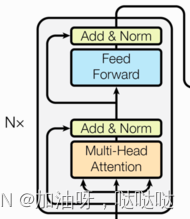
(1)实现
- 类的初始化函数参数有两个,分别是
layer和N,代表编码器层和编码器层的个数. - forward函数的输入参数也有两个, 和编码器层的forward相同, x代表上一层的输出, mask代码掩码张量.
- 编码器类的输出就是Transformer中编码器的特征提取表示, 它将成为解码器的输入的一部分.
class Encoder(nn.Module):
""" 实现编码器
"""
def __init__(self, layer, N):
""" 初始化
- layer: 编码器层
- N: 编码器层的个数
"""
super(Encoder, self).__init__()
# 使用clones函数克隆N个编码器层放在self.layers中
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"""forward函数的输入和编码器层相同,
- x: 上一层的输出,
- mask: 掩码张量
"""
# 首先就是对我们克隆的编码器层进行循环,每次都会得到一个新的x,
# 这个循环的过程,就相当于输出的x经过了N个编码器层的处理.
# 最后再通过规范化层的对象self.norm进行处理,最后返回结果.
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
(2)测试
size = d_model = 512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
N = 8
self_attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
layer = EncoderLayer(size, copy.deepcopy(self_attn), copy.deepcopy(ff), dropout)
encoder = Encoder(layer, N)
print(x.shape)
en_result = encoder(x, mask)
print(en_result)
print(en_result.shape)
torch.Size([2, 4, 512])
tensor([[[-0.7567, -1.2521, -0.2055, ..., 0.8205, -1.2941, -2.0247],
[-0.0359, 0.9469, 0.0691, ..., -0.6150, 0.4005, -0.1147],
[-1.3874, 0.9941, 0.1449, ..., -0.3395, 1.3993, -2.0148],
[-0.5812, -0.6430, 2.1250, ..., 1.8703, -0.1342, 0.6250]],
[[-1.4746, 1.0971, -0.0154, ..., -0.3533, 1.4110, -1.8592],
[-0.5287, -1.6246, 0.7500, ..., 0.4196, 0.8892, 0.2809],
[-0.1306, 0.8462, 0.0411, ..., -0.5721, 0.4040, -0.1732],
[-0.8179, -1.3323, -0.7204, ..., -0.4005, 0.5500, -0.0986]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
4.解码器
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
4.1 解码器层DecoderLayer
作为解码器的组成单元, 每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程。
(1)实现
- 类的初始化函数的参数有5个, 分别是
size,代表词嵌入的维度大小, 同时也代表解码器层的尺寸,第二个是self_attn,多头自注意力对象,也就是说这个注意力机制需要Q=K=V,第三个是src_attn,多头注意力对象,这里Q!=K=V, 第四个是前馈全连接层对象,最后就是droupout置0比率. - forward函数的参数有4个,分别是来自上一层的输入x,来自编码器层的语义存储变量mermory, 以及源数据掩码张量和目标数据掩码张量.
- 最终输出了由编码器输入和目标数据一同作用的特征提取结果.
class DecoderLayer(nn.Module):
""" 解码器层
"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
""" 初始化
- size:代表词嵌入的维度大小, 同时也代表解码器层的尺寸,
- self_attn: 多头自注意力对象,也就是说这个注意力机制需要Q=K=V,
- src_attn:多头注意力对象,这里Q!=K=V,
- feed_forward: 前馈全连接层对象,
- droupout:置0比率.
"""
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.dropout = dropout
# 按照结构图使用clones函数克隆三个子层连接对象.
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"""forward函数中的参数有4个,
- x: 来自上一层的输入x,
- mermory: 来自编码器层的语义存储变量
- src_mask: 源数据掩码张量
- tgt_mask: 目标数据掩码张量.
"""
# 将memory表示成m方便之后使用
m = memory
# 将x传入第一个子层结构,第一个子层结构的输入分别是x和self-attn函数,
# 因为是自注意力机制,所以Q,K,V都是x,最后一个参数是目标数据掩码张量,
# 这时要对目标数据进行遮掩,因为此时模型可能还没有生成任何目标数据,
# 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入了第一个字符以便计算损失,
# 但是我们不希望在生成第一个字符时模型能利用这个信息,因此我们会将其遮掩,
# 同样生成第二个字符或词汇时,
# 模型只能使用第一个字符或词汇信息,第二个字符以及之后的信息都不允许被模型使用.
x = self.sublayer[0](x, lambda x : self.self_attn(x, x, x, tgt_mask))
# 接着进入第二个子层,这个子层中常规的注意力机制,q是输入x; k,v是编码层输出memory,
# 同样也传入source_mask,但是进行源数据遮掩的原因并非是抑制信息泄漏,
# 而是遮蔽掉对结果没有意义的字符而产生的注意力值,
# 以此提升模型效果和训练速度. 这样就完成了第二个子层的处理.
x = self.sublayer[1](x, lambda x : self.src_attn(x, m, m, src_mask))
# 最后一个子层就是前馈全连接子层,经过它的处理后就可以返回结果
return self.sublayer[2](x, self.feed_forward)
(2)测试
size = d_model = 512
head = 8
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
# x是来自目标数据的词嵌入表示, 但形式和源数据的词嵌入表示相同, 这里使用per充当.
x = pe_result
# memory是来自编码器的输出
memory = en_result
# 实际中source_mask和target_mask并不相同, 这里为了方便计算使他们都为mask
mask = Variable(torch.zeros(8, 4, 4))
src_mask = tgt_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
print(x.shape)
dl_result = dl(x, memory, src_mask, tgt_mask)
print(dl_result)
print(dl_result.shape)
torch.Size([2, 4, 512])
tensor([[[ 0.3128, -28.9028, 12.6505, ..., -25.0090, 0.0671, 43.7430],
[-18.6592, -20.2816, -0.2946, ..., 30.0085, -15.1012, -14.5942],
[-19.6110, 0.1298, -0.3384, ..., -14.7287, -22.1352, 12.7321],
[-33.9689, 0.9680, -61.3009, ..., -51.5810, -8.8205, -6.2392]],
[[-21.1268, 10.4200, 3.9523, ..., -15.5449, -0.2314, 12.6887],
[ 6.3277, 27.3815, 43.6648, ..., -21.2202, -48.8453, -20.5100],
[-18.5797, -21.5331, -38.0592, ..., 29.7248, -15.0411, 0.4119],
[ 65.4318, 15.5895, -23.6869, ..., -25.7464, 42.8896, 14.5587]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
4.2 解码器Decoder
根据编码器的结果以及上一次预测的结果, 对下一次可能出现的’值’进行特征表示.
(1)实现
- 类的初始化函数的参数有两个,第一个就是解码器层
layer,第二个是解码器层的个数N. - forward函数中的参数有4个,
x代表目标数据的嵌入表示,memory是编码器层的输出,src_mask,tgt_mask代表源数据和目标数据的掩码张量. - 输出解码过程的最终特征表示.
class Decoder(nn.Module):
""" 实现解码器
"""
def __init__(self, layer, N):
""" 初始化
- layer: 解码器层
- N:解码器层个数
"""
super(Decoder, self).__init__()
# 首先使用clones方法克隆了N个layer,然后实例化了一个规范化层.
# 因为数据走过了所有的解码器层后最后要做规范化处理.
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
- x: 来自上一层的输入x,
- mermory: 来自编码器层的语义存储变量
- src_mask: 源数据掩码张量
- tgt_mask: 目标数据掩码张量.
"""
# 然后就是对每个层进行循环,当然这个循环就是变量x通过每一个层的处理,
# 得出最后的结果,再进行一次规范化返回即可.
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
(2)测试
size = d_model = 512
head = 8
d_ff = 64
dropout = 0.2
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, copy.deepcopy(attn), copy.deepcopy(attn), copy.deepcopy(ff), dropout)
N = 8
# 输入参数与解码器层的输入参数相同
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
src_mask = tgt_mask = mask
de = Decoder(layer, N)
print(x.shape)
de_result = de(x, memory, src_mask, tgt_mask)
print(de_result)
print(de_result.shape)
torch.Size([2, 4, 512])
tensor([[[ 6.2605e-01, -1.6188e+00, -2.0886e+00, ..., 1.0329e-01,
-9.3746e-01, -2.6656e-01],
[ 1.0500e-01, -2.6750e+00, 2.6044e+00, ..., -5.4699e-01,
-7.5199e-02, -2.8667e-01],
[-1.6483e-02, -3.6539e-01, -3.1693e-01, ..., -2.1838e-01,
5.6952e-01, 1.4017e+00],
[-4.9258e-01, -9.2657e-01, -1.3348e-01, ..., -2.1710e-01,
1.3200e+00, 1.3176e+00]],
[[-2.6396e-03, -2.1476e-01, -2.9699e-01, ..., -2.0103e-02,
5.1760e-01, 1.5096e+00],
[-4.1995e-01, -2.5207e+00, -1.1587e-01, ..., -4.2679e-01,
7.7861e-01, 1.7993e-02],
[ 2.2358e-02, -2.7497e+00, 2.5735e+00, ..., -4.2572e-01,
-4.1822e-01, -1.9397e-01],
[ 2.8288e-01, 4.5199e-01, 3.6352e-01, ..., 2.1069e+00,
-8.3942e-01, 3.1137e-02]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
5.输出部分
- 线性层
- softmax层
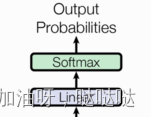
5.1 线性层
通过对上一步的线性变化得到指定维度的输出, 也就是转换维度的作用.
5.2 softmax层
使最后一维的向量中的数字缩放到0-1的概率值域内, 并满足他们的和为1.
5.3 线性层和softmax层的类 Generator
(1)实现
- 初始化函数的输入参数有两个,
d_model代表词嵌入维度,vocab_size代表词表大小. - forward函数接受上一层的输出.
- 最终获得经过线性层和softmax层处理的结果.
class Generator(nn.Module):
""" 生成器类
将线性层和softmax计算层一起实现, 因为二者的共同目标是生成最后的结构
因此把类的名字叫做Generator, 生成器类
"""
def __init__(self, d_model, vocab_size):
"""
- d_model: 词嵌入维度
- vocab_size: 词表的总大小
"""
super(Generator, self).__init__()
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x):
"""
- x: 上一层的输出张量
"""
# 在函数中, 首先使用上一步得到的self.project对x进行线性变化,
# 然后使用F中已经实现的log_softmax进行的softmax处理.
# 在这里之所以使用log_softmax是因为和我们这个pytorch版本的损失函数实现有关, 在其他版本中将修复.
# log_softmax就是对softmax的结果又取了对数, 因为对数函数是单调递增函数,
# 因此对最终我们取最大的概率值没有影响. 最后返回结果即可.
return log_softmax(self.project(x), dim=-1)
(2)测试
d_model = 512
vocab_size = 1000
# 输入x是上一层网络的输出, 我们使用来自解码器层的输出
x = de_result
gen = Generator(d_model, vocab_size)
print(x)
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
torch.Size([2, 4, 512])
tensor([[[-7.6141, -7.1042, -6.0669, ..., -6.8734, -7.0652, -7.3009],
[-7.1238, -6.8357, -7.2459, ..., -7.1225, -8.0530, -6.9380],
[-7.5266, -7.6293, -8.1937, ..., -7.6398, -7.8350, -7.6071],
[-7.4972, -7.2781, -7.3025, ..., -6.6653, -6.4995, -6.9529]],
[[-7.5171, -7.0331, -8.0956, ..., -7.4018, -7.6130, -7.9539],
[-6.4713, -7.4932, -6.8351, ..., -6.6046, -8.0713, -7.4401],
[-7.3482, -6.6409, -7.5268, ..., -7.1031, -8.2056, -7.2852],
[-8.1393, -7.1066, -7.4460, ..., -6.9347, -6.3511, -6.9577]]],
grad_fn=<LogSoftmaxBackward>)
torch.Size([2, 4, 1000])
6.模型构建
6.1 编码器-解码器EncoderDecoder
大部分神经序列转换模型都有一个编码器-解码器结构。编码器把一个输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1,...,xn)映射到一个连续的表示 z = ( z 1 , . . , z n ) z=(z_1, .., z_n) z=(z1,..,zn)中。解码器对z中的每个元素,生成输出序列 ( y 1 , . . . , y m ) (y_1, ..., y_m) (y1,...,ym),一个时间步生成一个元素。在每一步中,模型都是自回归的,在生成下一个结果时,会将先前生成的结构加入输入序列来一起预测。(自回归模型的特点)
(1)实现
- 类的初始化函数传入5个参数, 分别是编码器对象, 解码器对象, 源数据嵌入函数, 目标数据嵌入函数, 以及输出部分的类别生成器对象.
- 类中共实现三个函数,
forward,encode,decode - forward是主要逻辑函数, 有四个参数, source代表源数据, target代表目标数据, source_mask和target_mask代表对应的掩码张量.
- encode是编码函数, 以source和source_mask为参数.
- decode是解码函数, 以memory即编码器的输出, source_mask, target, target_mask为参数
class EncoderDecoder(nn.Module):
""" 实现编码器-解码器结构
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
""" 初始化
- encoder: 编码器对象
- decoder: 解码器对象
- src_embed:源数据嵌入函数
- tgt_embed: 目标数据嵌入函数
- generator:输出部分类别生成器
"""
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"""
- src:源数据
- tgt:目标数据
- src_mask:源数据的掩码张量
- tgt_mask:目标数据的掩码张量
"""
# 在函数中, 将source, source_mask传入编码函数, 得到结果后,
# 与source_mask,target,和target_mask一同传给解码函数.
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
""" 编码函数
- src:源数据
- src_mask:源数据的掩码张量
"""
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
""" 解码函数
- memory:经历编码器编码后的输出张量
- src_mask:源数据的掩码张量
- tgt:目标数据
- tgt_mask:目标数据的掩码张量
"""
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
(2)测试
vocab_size = 1000
d_model = 512
encoder = en
decoder = de
src_embed = nn.Embedding(vocab_size, d_model)
tgt_embed = nn.Embedding(vocab_size, d_model)
generator = Generator(d_model, vocab_size)
src = tgt = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
src_mask = tgt_mask = Variable(torch.zeros(8, 4, 4))
ed = EncoderDecoder(encoder, decoder, src_embed, tgt_embed, generator)
ed_result = ed(src, tgt, src_mask, tgt_mask)
print(ed_result)
print(ed_result.shape)
tensor([[[ 0.3879, 0.1344, -0.5700, ..., -0.2206, -0.7505, -0.3314],
[-0.7957, 0.8759, -0.5033, ..., -1.3409, -1.4451, -0.3243],
[ 0.3513, 0.8083, 0.1246, ..., -0.4443, -1.3551, -1.3547],
[ 0.0050, 0.6573, -1.1390, ..., 0.1529, -1.5487, -0.8990]],
[[-0.1515, 1.9247, -0.0315, ..., -0.5945, -2.7363, -1.2481],
[-0.6422, 1.5250, 0.7561, ..., -1.4778, -1.2162, -2.2946],
[ 0.0163, 1.8034, 0.1408, ..., -0.4170, -1.7017, -1.6474],
[ 0.2880, -0.0269, -0.1636, ..., -0.7687, -1.3453, -0.8909]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
6.2 Transformer模型make_model
(1)实现
- 有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout.
- 该函数最后返回一个构建好的模型对象.
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
""" 构建transformer模型
- src_vocab: 源数据特征(词汇)总数
- tgt_vocab: 目标数据特征(词汇)总数
- N: 编码器和解码器堆叠数
- d_model: 词向量映射维度
- d_ff: 前馈全连接网络中变换矩阵的维度
- h : 多头注意力结构中的多头数
- dropout: 置零比率
"""
# 首先得到一个深度拷贝命令,接下来很多结构都需要进行深度拷贝,
# 来保证他们彼此之间相互独立,不受干扰.
c = copy.deepcopy
# 实例化了多头注意力类,得到对象attn
attn = MultiHeadAttention(h, d_model)
# 然后实例化前馈全连接类,得到对象ff
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
# 实例化位置编码类,得到对象position
position = PositionalEncoding(d_model, dropout)
# 根据结构图, 最外层是EncoderDecoder,在EncoderDecoder中,
# 分别是编码器层,解码器层,源数据Embedding层和位置编码组成的有序结构,
# 目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层.
# 在编码器层中有attention子层以及前馈全连接子层,
# 在解码器层中有两个attention子层以及前馈全连接层.
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab)
)
# 模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵
# 这里一但判断参数的维度大于1,则会将其初始化成一个服从均匀分布的矩阵,
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
(2)测试
src_vocab = 11
tgt_vocab = 11
model= make_model(src_vocab, tgt_vocab)
print(model)
# 太长了。。。
6.3 Inference
在这里,我们用生成模型的预测。 我们尝试使用我们的transformer 来记住输入。 正如您将看到的那样,由于模型尚未训练,输出是随机生成的。
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
def run_tests():
for _ in range(10):
inference_test()
Example Untrained Model Prediction: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Example Untrained Model Prediction: tensor([[0, 3, 4, 4, 4, 4, 4, 4, 4, 4]])
Example Untrained Model Prediction: tensor([[ 0, 10, 10, 10, 3, 2, 5, 7, 9, 6]])
Example Untrained Model Prediction: tensor([[ 0, 4, 3, 6, 10, 10, 2, 6, 2, 2]])
Example Untrained Model Prediction: tensor([[ 0, 9, 0, 1, 5, 10, 1, 5, 10, 6]])
Example Untrained Model Prediction: tensor([[ 0, 1, 5, 1, 10, 1, 10, 10, 10, 10]])
Example Untrained Model Prediction: tensor([[ 0, 1, 10, 9, 9, 9, 9, 9, 1, 5]])
Example Untrained Model Prediction: tensor([[ 0, 3, 1, 5, 10, 10, 10, 10, 10, 10]])
Example Untrained Model Prediction: tensor([[ 0, 3, 5, 10, 5, 10, 4, 2, 4, 2]])
Example Untrained Model Prediction: tensor([[0, 5, 6, 2, 5, 6, 2, 6, 2, 2]])
7.测试运行
7.1 copy任务简介
任务描述:针对数字序列进行学习, 学习的最终目标是使输出与输入的序列相同. 如输入[1, 5, 8, 9, 3], 输出也是[1, 5, 8, 9, 3].
任务意义:copy任务在模型基础测试中具有重要意义,因为copy操作对于模型来讲是一条明显规律, 因此模型能否在短时间内,小数据集中学会它,可以帮助我们断定模型所有过程是否正常,是否已具备基本学习能力。
7.2 模型基本测试
(1)构建数据集生成器
实现
def data_generator(V, batch_size, num_batch):
""" 该函数用于随机生成copy任务的数据
- V: 随机生成数字的最大值+1
- batch: 每次输送给模型更新一次参数的数据量
- num_batch: 一共输送num_batch次完成一轮
"""
for i in range(num_batch):
# 在循环中使用randint方法随机生成[1, V)的整数,
# 分布在(batch, 10)形状的矩阵中,
data = torch.randint(1, V, size=(batch_size, 10))
# 接着使数据矩阵中的第一列数字都为1, 这一列也就成为了起始标志列,
# 当解码器进行第一次解码的时候, 会使用起始标志列作为输入.
data[:, 0] = 1
# 因为是copy任务, 所有source与target是完全相同的, 且数据样本作用变量不需要求梯度
# 因此requires_grad设置为False
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach()
# 使用Batch对source和target进行对应批次的掩码张量生成, 最后使用yield返回
yield Batch(src, tgt, 0)
测试
V = 11
batch_size = 20
num_batch = 30
res = data_generator(V, batch_size, num_batch)
<generator object data_generator at 0x00000245A1AD4BA0>
(2)获得Transformer模型及优化器和损失函数
实现
损失函数计算
class SimpleLossCompute:
"损失函数计算"
def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
) / norm
return sloss.data * norm, sloss
标签平滑
在训练过程中,我们使用的label平滑的值为epsilon_{ls}=0.1 (cite)。这让模型不易理解,因为模型学得更加不确定,但提高了准确性和BLEU得分。
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())
V = 11
batch_size = 20
num_batch = 30
model = make_model(V, V, N=2)
# 获得模型优化器
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
# 使用LabelSmoothing获得标签平滑对象
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获得利用标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator, criterion)
标签平滑示例
# 使用LabelSmoothing实例化一个crit对象.
# 第一个参数size代表目标数据的词汇总数, 也是模型最后一层得到张量的最后一维大小
# 这里是5说明目标词汇总数是5个. 第二个参数padding_idx表示要将那些tensor中的数字
# 替换成0, 一般padding_idx=0表示不进行替换. 第三个参数smoothing, 表示标签的平滑程度
# 如原来标签的表示值为1, 则平滑后它的值域变为[1-smoothing, 1+smoothing].
crit = LabelSmoothing(size=5, padding_idx=0, smoothing=0.5)
# 假定一个任意的模型最后输出预测结果和真实结果
predict = Variable(torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]]))
# 标签的表示值是0,1,2
target = Variable(torch.LongTensor([2, 1, 0]))
# 将predict, target传入到对象中
crit(predict, target)
# 绘制标签平滑图像
plt.imshow(crit.true_dist)
plt.waitforbuttonpress()
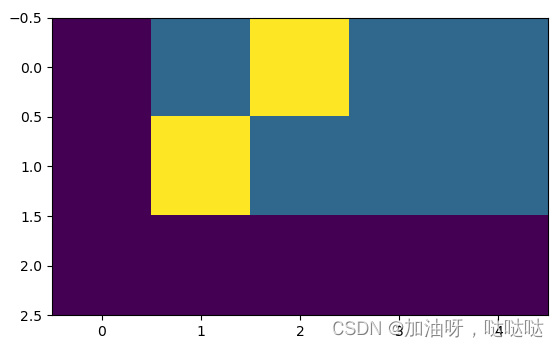
标签平滑图像分析:
- 我们目光集中在黄色小方块上, 它相对于横坐标横跨的值域就是标签平滑后的正向平滑值域, 我们可以看到大致是从0.5到2.5.
- 它相对于纵坐标横跨的值域就是标签平滑后的负向平滑值域, 我们可以看到大致是从-0.5到1.5, 总的值域空间由原来的[0, 2]变成了[-0.5, 2.5].
(3)运行模型进行训练和评估
V = 11
batch_size = 80
model = make_model(V, V, N=2)
# 获得模型优化器
optimizer = torch.optim.Adam(model.parameters(),
lr=0.5, betas=(0.9, 0.98), eps=1e-9)
# 使用LabelSmoothing获得标签平滑对象
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获得利用标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator, criterion)
lr_scheduler = LambdaLR(optimizer=optimizer,
lr_lambda=lambda step: rate(step, model_size=model.src_embed[0].d_model,
factor=1.0, warmup=400))
for epoch in range(epochs):
# 模型使用训练模式, 所有参数将被更新
model.train()
run_epoch(data_generator(V, batch_size, 20), model, loss,
optimizer, lr_scheduler, mode="train")
# 模型使用评估模式, 参数将不会变化
model.eval()
run_epoch(data_generator(V, batch_size, 5), model, loss,
DummyOptimizer(), DummyScheduler(), mode="eval")[0]
(4)使用模型进行贪婪解码
为简单起见,此代码使用贪婪解码预测翻译。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys
V = 11
batch_size = 80
model = make_model(V, V, N=2)
# 获得模型优化器
optimizer = torch.optim.Adam(model.parameters(),
lr=0.5, betas=(0.9, 0.98), eps=1e-9)
# 使用LabelSmoothing获得标签平滑对象
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获得利用标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator, criterion)
lr_scheduler = LambdaLR(optimizer=optimizer,
lr_lambda=lambda step: rate(step, model_size=model.src_embed[0].d_model,
factor=1.0, warmup=400))
for epoch in range(epochs):
# 模型使用训练模式, 所有参数将被更新
model.train()
run_epoch(data_generator(V, batch_size, 20), model, loss,
optimizer, lr_scheduler, mode="train")
# 模型使用评估模式, 参数将不会变化
model.eval()
run_epoch(data_generator(V, batch_size, 5), model, loss,
DummyOptimizer(), DummyScheduler(), mode="eval")[0]
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
result = greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0)
print(result)
tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结