您现在的位置是:首页 >技术教程 >Hive on Spark调优(大数据技术7)网站首页技术教程
Hive on Spark调优(大数据技术7)
简介Hive on Spark调优(大数据技术7)
第7章 数据倾斜优化
7.1 数据倾斜说明
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
7.2 分组聚合导致的数据倾斜
示例SQL语句如下:
select
province_id,
count(*)
from dwd_trade_order_detail_inc
where dt='2020-06-16'
group by province_id;7.2.1 优化前执行计划
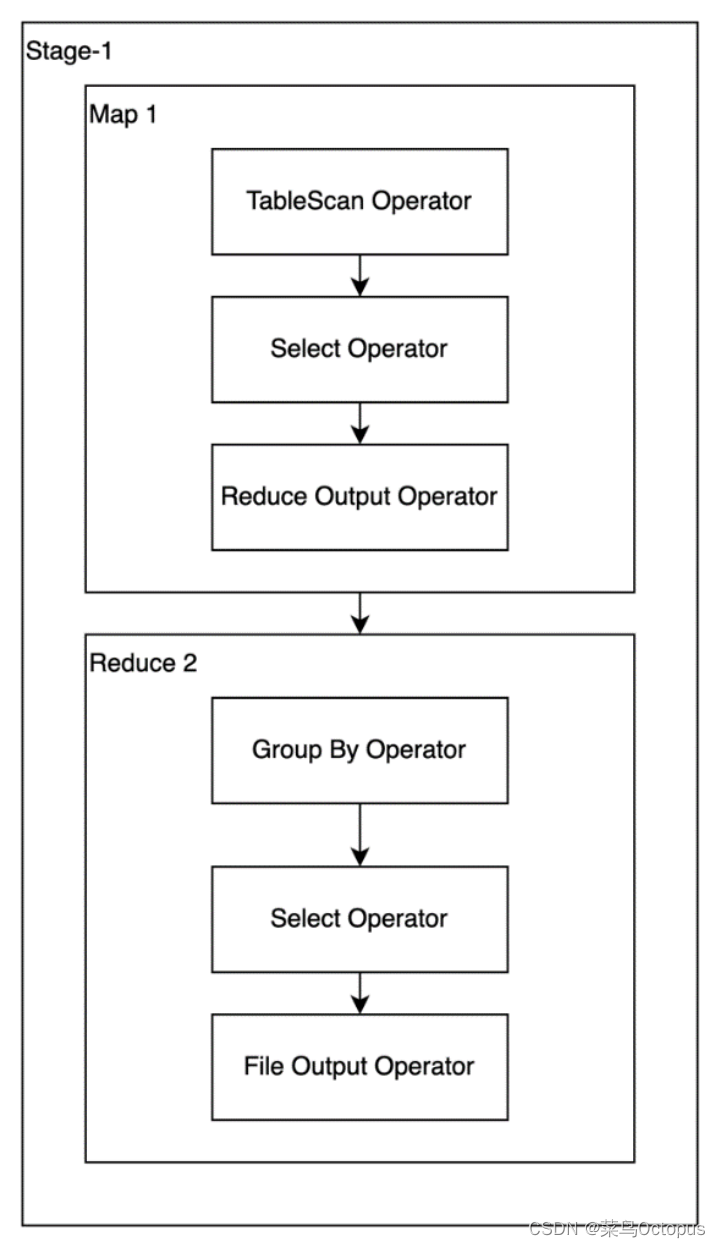
7.2.2 优化思路
由分组聚合导致的数据倾斜问题主要有以下两种优化思路:
1)启用map-side聚合
相关参数如下:
--启用map-side聚合
set hive.map.aggr=true;
--hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;启用map-side聚合后的执行计划如下图所示:
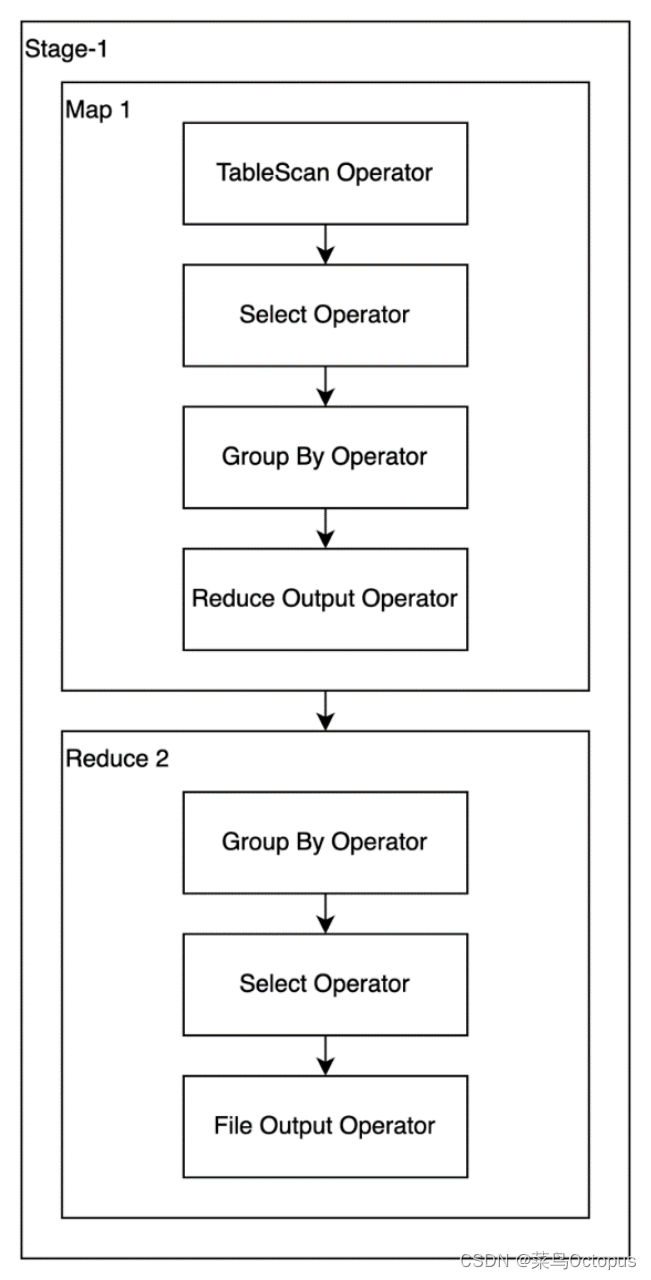
2)启用skew groupby优化
其原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;启用skew groupby优化后的执行计划如下图所示:
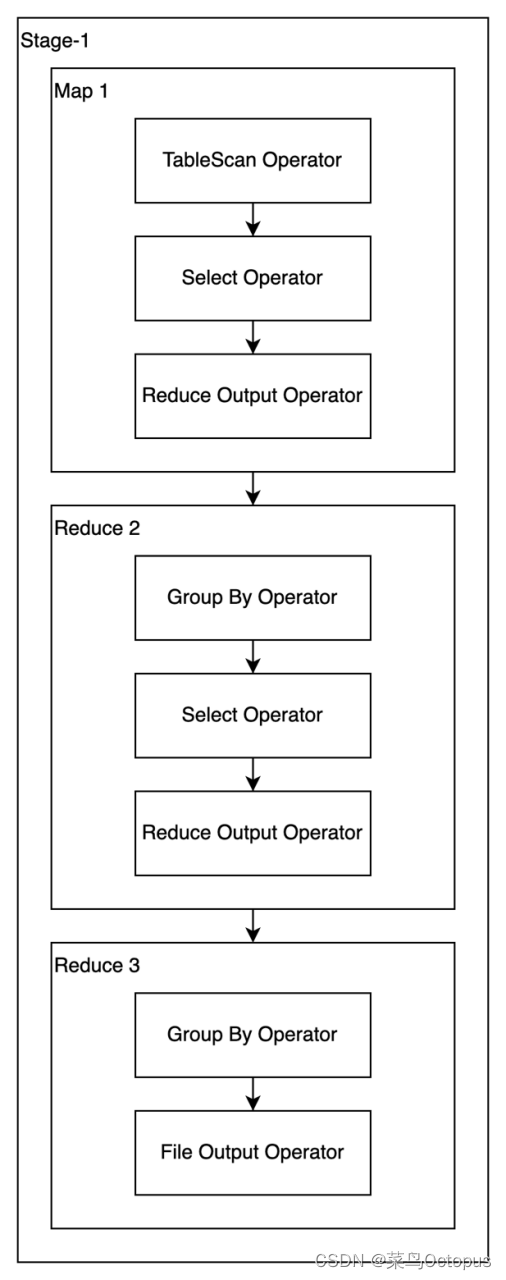
7.3 join导致的数据倾斜
示例SQL语句如下。
select
*
from
(
select
*
from dwd_trade_order_detail_inc
where dt='2020-06-16'
)fact
join
(
select
*
from dim_province_full
where dt='2020-06-16'
)dim
on fact.province_id=dim.id;7.3.1 优化前的执行计划
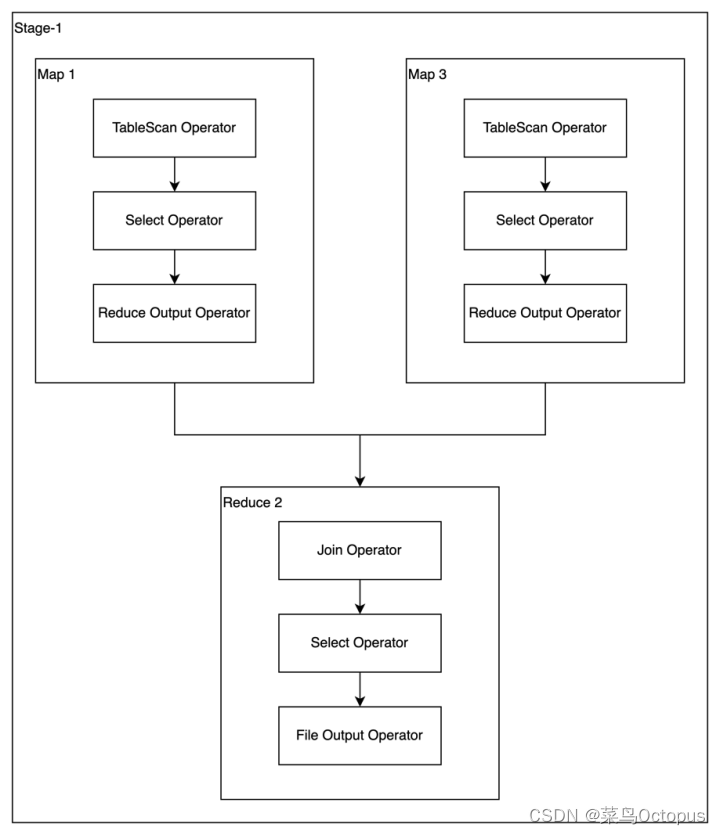
7.3.2 优化思路
由join导致的数据倾斜问题主要有以下两种优化思路:
1)使用map join
相关参数如下:
--启用map join自动转换
set hive.auto.convert.join=true;
--common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size使用map join优化后执行计划如下图。
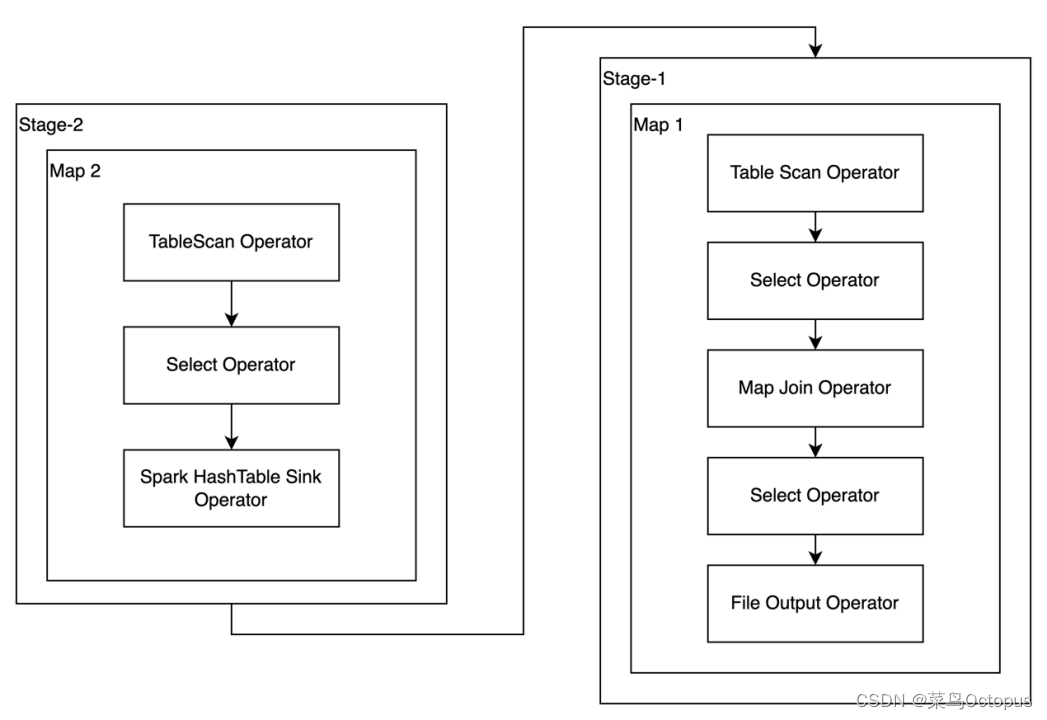
2)启用skew join优化
其原理如下图:
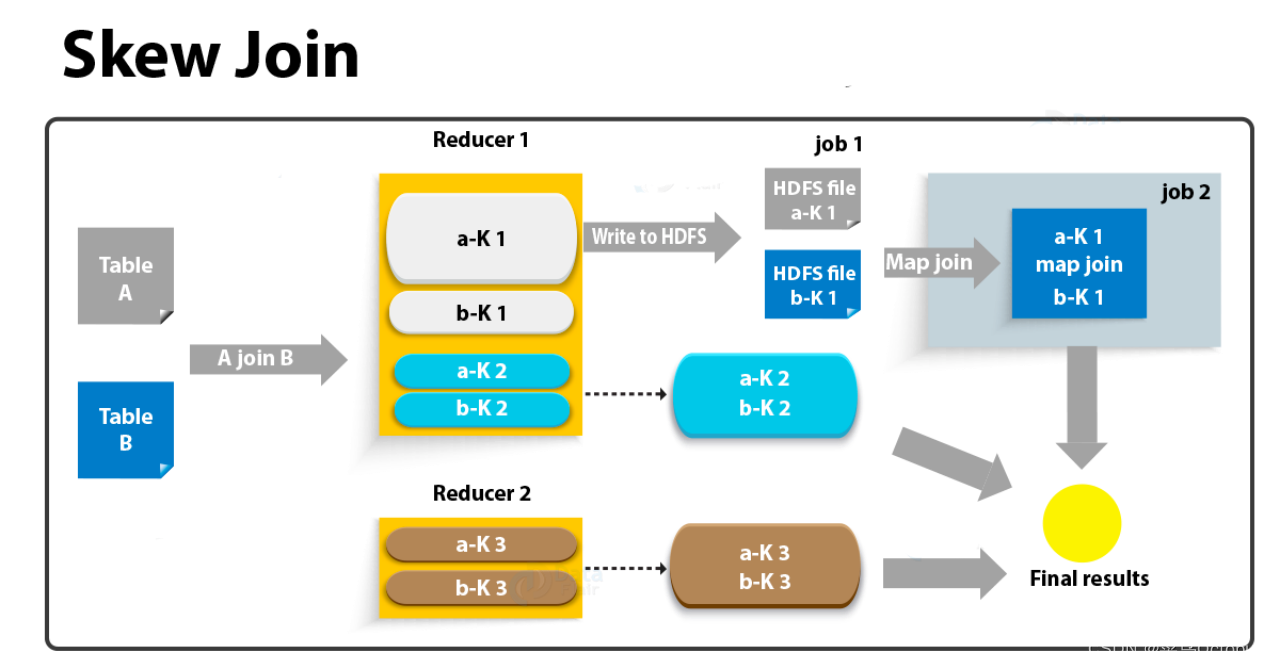
相关参数如下:
--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
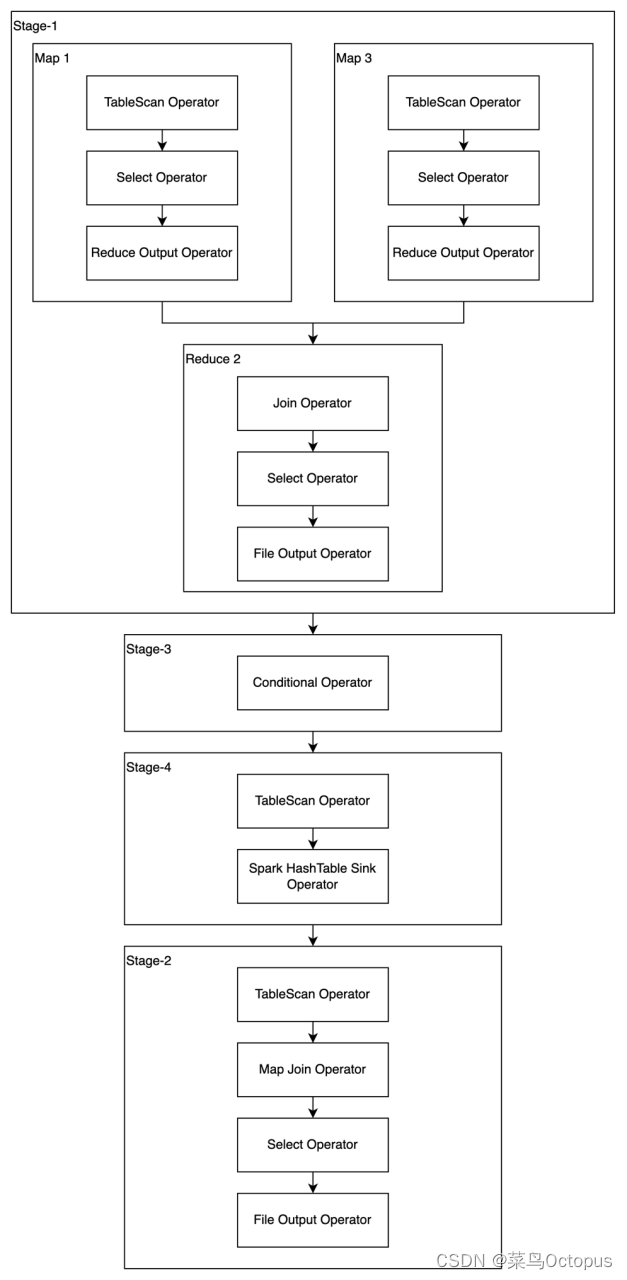
set hive.skewjoin.key=100000;需要注意的是,skew join只支持Inner Join。
启动skew join优化后的执行计划如下图所:
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结