您现在的位置是:首页 >学无止境 >搭建go web 框架网站首页学无止境
搭建go web 框架
思想
web框架服务主要围绕着请求与响应来展开的
搭建一个web框架的核心思想
1 便捷添加响应路径与响应函数(base)
2 能够接收多种数据类型传入(上下文context)
3 构建多种数据类型的响应(上下文context)
4 使用前缀树储存搜索路径,实现动态路由的功能(前缀树)
5 能够进行分组与中间件的插入(分组,中间件)
-
优化
1 替换原生的json数据解析函数
使用JSON-iterator对json数据进行解析(编码与解码)
2 构建线程池限制同时用户访问的数量
3 搭建统一数据返回的函数,使用
{
code:状态码
msg:提示信息
data:返回数据
}
的格式进行返回,便于前端使用
4 搭建传入json数据的解析,解析任意形式的json的数据,便于数据的读入 (个人比较喜欢使用json格式的数据,将请求与响应的数据统一为json类型,前端后端都比较分别使用)
base部分
了解原生的http.ListenAndServe函数
打开一个端口,用户根据端口访问到服务器
定义ServeHTTP函数处理请求进行响应
通过对路经的判断,实现路径的控制,访问特定的路径实现特定的响应
首先了解原生的ListenAndServe与ServeHTTP进行响应
-
添加路由: 使用http.HandleFunc来添加路由:
第一给参数为添加的路由,第二个参数是hander函数,就是当路由匹配时执行方法
hander函数必须是这两个形参w http.ResponseWriter, req *http.Request,一个是输出的端口,一个是用户传入的数据
-
响应请求 使用http.ListenAndServe方法,一个监听的端口,一个http.Handler 接口,只包含一个方法 ServeHTTP,就是传入的参数可以调serveHTTP方法处理用户的请求.
func indexhander(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "URL=%q
", req.URL.Path) //输出路径
}
func hellohander(w http.ResponseWriter, req *http.Request) {
for k, v := range req.Header {
fmt.Fprintf(w, "header[%q]=%q
", k, v) //输出头部信息
}
}
func main() {
http.HandleFunc("/", indexhander)//第一给参数为添加的路由,第二个参数是hander函数,就是当路由匹配时执行的
http.HandleFunc("/hello", hellohander)
log.Fatal(http.ListenAndServe(":8888", nil)) //开启监听端口8888 ,并打印日志
}
访问hello路径
head的内容
header["Accept"]=["text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"]
header["Sec-Fetch-Site"]=["none"]
header["Sec-Fetch-Dest"]=["document"]
header["Connection"]=["keep-alive"]
header["Sec-Ch-Ua-Platform"]=[""Windows""]
header["Sec-Fetch-User"]=["?1"]
header["X-Forwarded-For"]=["4.2.2.2"]
header["Accept-Language"]=["zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"]
header["User-Agent"]=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.42"]
header["Sec-Fetch-Mode"]=["navigate"]
header["Accept-Encoding"]=["gzip, deflate, br"]
header["Sec-Ch-Ua"]=[""Not?A_Brand";v="8", "Chromium";v="108", "Microsoft Edge";v="108""]
header["Sec-Ch-Ua-Mobile"]=["?0"]
header["Upgrade-Insecure-Requests"]=["1"]
包含了访问的头部信息
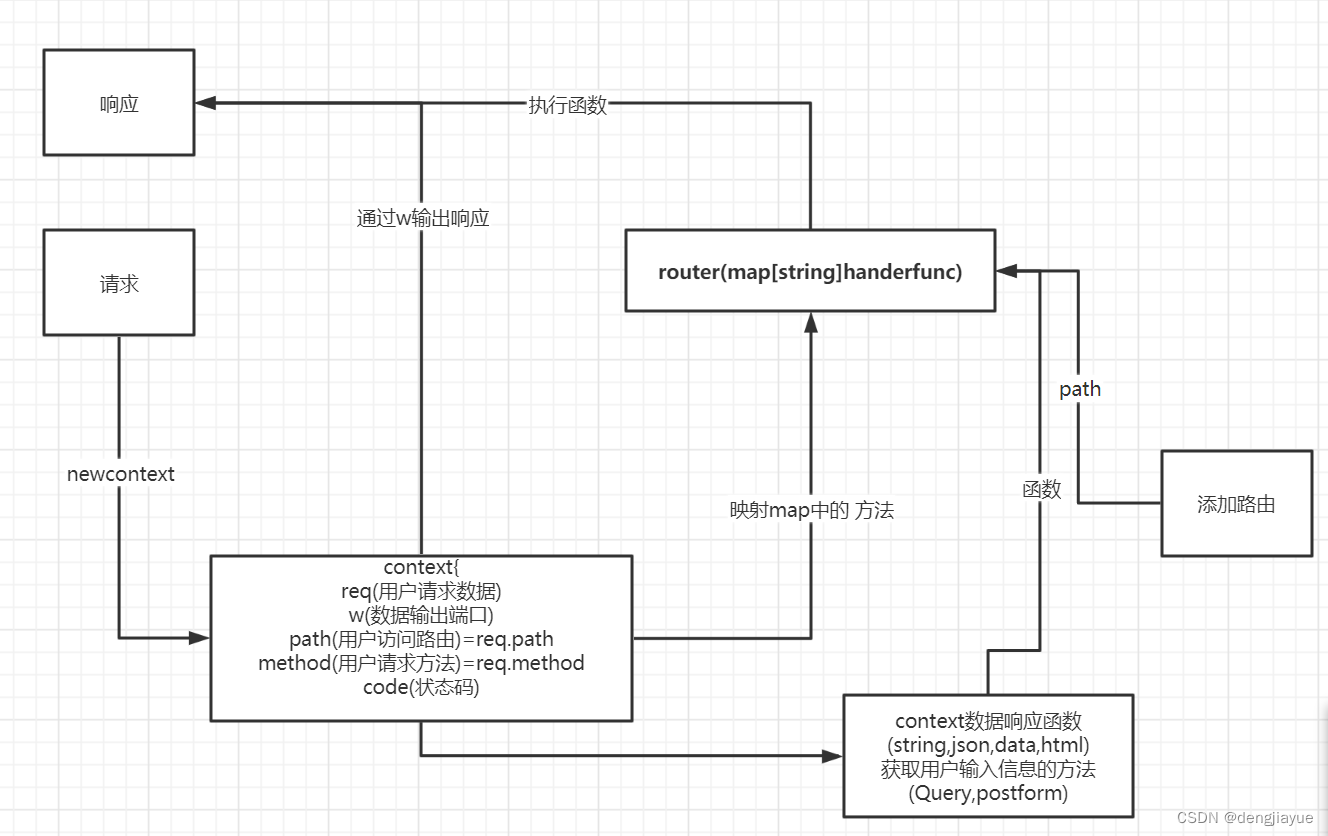
day1:封装gee
实现功能:便捷添加响应路径与响应函数
-
核心:定义 map[string]Handlerfunc用于储存路径与响应函数
-
当用户访问路径就去map中映射响应函数
-
因为web的基础就是添加路由,然后支持用户的访问,对用户的访问做出正确的的响应,就是根据用户提交的路径执行相应的函数
我们就用一个map来添加和映射出对应的返回
map的string储存路径, Handlerfunc储存执行的方法
type Engin struct {
router map[string]Handlerfunc
}
-
然后是添加路由的方法:向map中添加元素key为方法(get/post)路由value为hander函数(用户请求该路径的响应函数)
// 添加路由映射
func (engin *Engin) addroute(method string, pettern string, hander Handlerfunc) {
key := method + "-" + pettern
//
engin.router[key] = hander
}
key为用户请求的方法(get,post)+路径;
-
get与post方法,添加两种不同的method的添加路由映射的方法
// 定义get方法
func (engin *Engin) GET(pattern string, handler Handlerfunc) {
engin.addroute("GET", pattern, handler)
}
// 定义post方法;参数:一个是 路径字段,一个是响应函数
func (engin *Engin) POSE(pattern string, handler Handlerfunc) {
// 调用add函数添加路由映射
engin.addroute("POST", pattern, handler)
}
没什么可说的,就是method不同而已,其他都是一样的
-
实现ServeHTTP接口,处理用户的 访问
用户请求的执行函数,只要用户请求端口,无论什么路径都执行函数 执行两步:
-
根据用户访问的method和url,映射出对应的处理函数(addrouter的时候添加好的) -
执行处理函数,如果没有对应的就输出404错误
// 定义serve函数
func (engin *Engin) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 查找映射字段
key := req.Method + "-" + req.URL.Path
if handler, ok := engin.router[key]; ok { //查找成功成功就执行hander函数
handler(w, req)
} else { //失败就返回404
fmt.Fprintf(w, "404 NOT FOUND: %s
", req.URL)
}
}
-
封装run函数
// 启动http服务;监听addr端口,并执行engin接口,当用户访问,执行servehttp函数
func (engin *Engin) Run(addr string) (err error) {
return http.ListenAndServe(addr, engin)
}
-
开启addr端口, -
启动服务:当用户访问的时候执行engine.ServeHTTP函数 -
然后就是从map中映射响应函数,如果没有当前路径,就响应404not found
这样实现了最基本的静态路由的添加与访问的响应.(最基本功能)
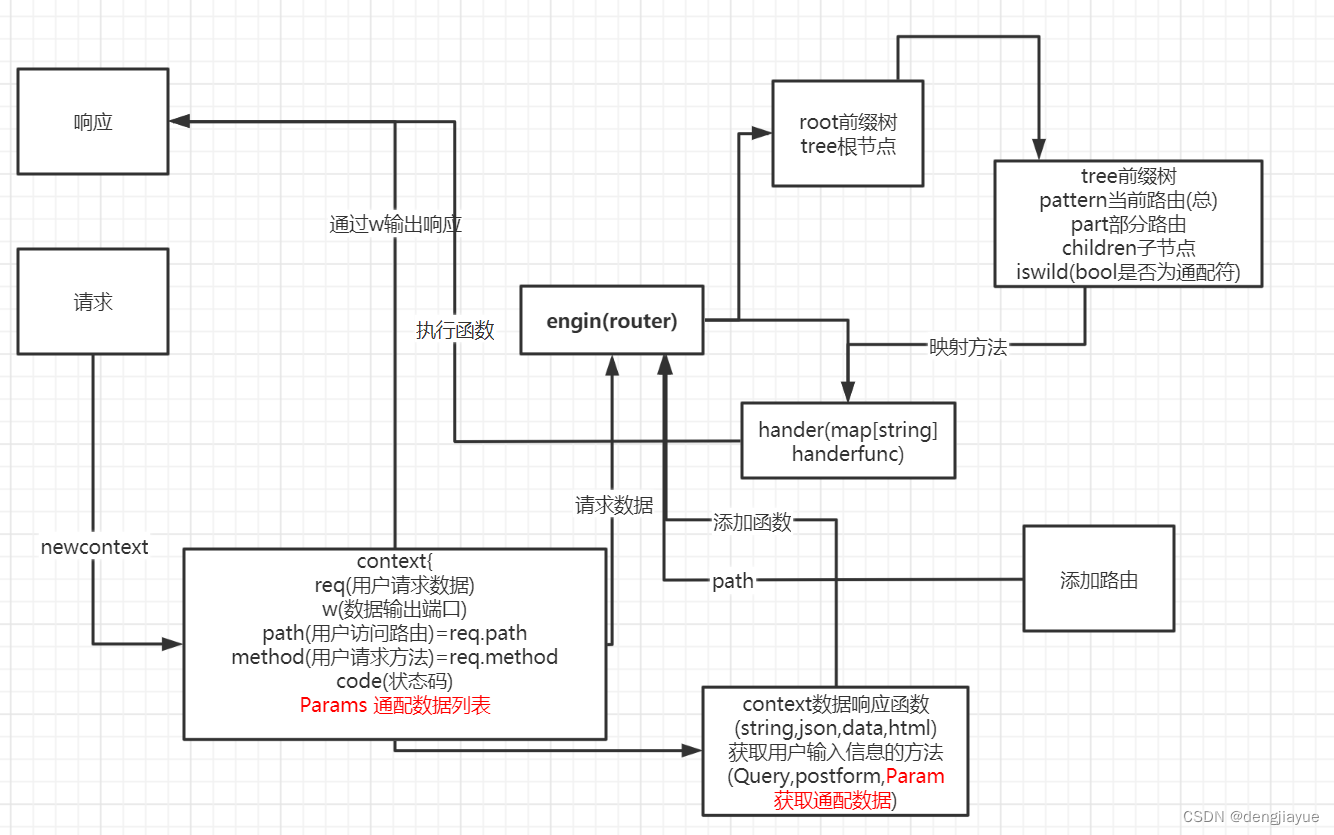
封装context上下文
context功能:封装处理请求与响应数据
1 解析传入的数据
2 多种类型的响应数据的的定义
封装context节点,储存需要用到的节点与数据
type Context struct {
// 数据响应端口,用于返回数据
Writer http.ResponseWriter
// 用户请求的数据
Req *http.Request
// 路径字符串
Path string
//方法(get/post....)
Method string
//状态码404/200...
StatusCode int
}
// 初始化context,请求时创建节点
func NewContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
Writer: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
}
}
context.go:
type Context struct {
// 数据响应端口,用于返回数据
Writer http.ResponseWriter
// 用户请求的数据
Req *http.Request
// 路径字符串
Path string
//方法
Method string
//状态码404/200...
StatusCode int
}
// 初始化context,请求时创建节点
func NewContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
Writer: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
}
}
//请求执行函数
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := contexts.NewContext(w, req)
engine.router.handle(c)
}
-
获取请求参数
我们可以获取用户请求携带的数据,储存再req中,在动态路由时可以获取储存与使用
//动态路由,tree加的动态路由
//获取路由参数 .例:/users/123
func (c *Context) Param(key string) string {
value, _ := c.Params[key]
return value
}
//获取表单数据
func (c *Context) PostForm(key string) string {
return c.Req.FormValue(key)
}
//获取query数据.例/login/?id=123
func (c *Context) Query(key string) string {
return c.Req.URL.Query().Get(key)
}
-
构建响应
通过writer接口输出相应,
根据需要设置header信息与输各种类型的相应信息
//输出响应信息
//设置header
func (c *Context) SetHeader(key string, value string) {
c.Writer.Header().Set(key, value)
}
func (c *Context) String(code int, format string, values ...interface{}) {
c.SetHeader("Content-Type", "text/plain")
c.Status(code)
c.Writer.Write([]byte(fmt.Sprintf(format, values...)))
}
func (c *Context) JSON(code int, obj interface{}) {
c.SetHeader("Content-Type", "application/json")
c.Status(code)
encoder := json.NewEncoder(c.Writer)
if err := encoder.Encode(obj); err != nil {
http.Error(c.Writer, err.Error(), 500)
}
}
func (c *Context) Data(code int, data []byte) {
c.Status(code)
c.Writer.Write(data)
}
//name为文件名
func (c *Context) HTML(code int, name string, data interface{}) {
c.SetHeader("Content-Type", "text/html")
c.Status(code)
if err := c.engine.htmlTemplates.ExecuteTemplate(c.Writer, name, data); err != nil {
c.Fail(500, err.Error())
fmt.Fprintf(c.Writer, "404 NOT FOUND: %s
", c.Req.URL)
}
}
func (c *Context) Fail(StatusCode int, err string) {
http.Error(c.Writer, err, StatusCode)
}
封装前缀tree路由树
-
了解前缀树路由机制: 我们之前的代码只能实现静态路由的添加,如果我们需要就需要使用到前缀树路由,当访问到树节点的值为通配符时可以继续向下索引路径
目的实现动态路由解析
我们使用前缀树来对路由进行储存,实现动态路由的解析.
定义通配符规则:我们这里使用:和*作为通配符
比如:我们添加的路由是user/:id/*name
用户访问的是user/123/小明 或者 user/456/小红 都是是可以正常访问的,就是如果该节点是通配符就可以继续查找子节点直到找到最终的节点或者找不到节点,讲节点的pattern拿去hander map中映射函数,再用函数输出响应
前缀树路由机制:
前缀树(Prefix Tree),也被称为字典树(Trie),是一种经常用于实现路由机制的数据结构。前缀树的主要目的是高效地存储和检索字符串键(例如IP地址或URL),并且在路由表中查找最长前缀匹配。
在前缀树中,每个节点代表一个字符或一个字符的片段。从根节点到叶节点的路径构成了一个完整的字符串。树的根节点不包含字符,每个子节点都代表一个字符,通过连接从根到子节点的路径可以得到完整的字符串。这种结构使得前缀树非常适合用于匹配和查找具有共同前缀的字符串。
在路由机制中,前缀树被用于快速匹配输入数据包的目的地址与路由表中的最长前缀匹配。路由表中的每个条目包含一个目标地址前缀和相应的下一跳信息(下一个路由器或目的地)。当数据包到达路由器时,它的目的地址与前缀树中的条目进行匹配。
前缀树的匹配过程是从根节点开始,根据数据包的每个位依次向下遍历树的路径。如果在某个节点上无法匹配下一个位,则根据匹配到的最长前缀对应的下一跳信息进行转发。这样可以确保数据包被正确路由到最接近目标地址的下一个跳。
使用前缀树路由机制的优点包括:
高效的查找和匹配:前缀树可以在时间复杂度为O(k)的情况下(k为键的长度)找到匹配的前缀,因此具有快速查找和匹配的能力。 空间效率:前缀树在内存中存储键和值的关联,可以在较小的空间内存储大量的键。 支持最长前缀匹配:前缀树可以进行最长前缀匹配,确保数据包按照最准确的路由进行转发。
节点定义
type Node struct {
Pattern string // 准确的 路径
Part string // 路径的尾(当前的)
Children []*Node // 子节点
IsWild bool // 是否为通配符
}
type Rrouter struct {
Roots map[string]*tree.Node
Handlers map[string]HandlerFunc
}
func (n *Node) MatchChild(part string) *Node {
for _, child := range n.Children {
if child.Part == part || child.IsWild {
return child
}
}
return nil
}
// 查找返回与所有节点;查找n中part字段,返回节点数组(与MatchChild的区别:本函数返回所有匹配的节点而MatchChild返回第一个匹配的节点)
func (n *Node) MatchChildren(part string) []*Node {
nodes := make([]*Node, 0) //建立一个新节点
for _, child := range n.Children { //遍历n中是否有panrt的相对或者绝对路径
if child.Part == part || child.IsWild { //如果存在或者精确匹配
nodes = append(nodes, child) //节点赋值
}
}
return nodes //返回节点数组,没有就是空节点
}
// 如果当前处理的 URL 路径部分已经到了最后一部分(即 len(parts) == height),那么说明已经找到了该路由规则对应的叶子节点,将该叶子节点的模式设置为该规则对应的处理器函数 pattern,然后直接返回。
// 如果当前节点的子节点中有一个子节点的 part 值和当前处理的 URL 路径部分相等,或者是一个通配符(即 child.part == part || child.isWild),那么说明这个子节点可以用于匹配当前 URL 路径部分,就把 height 加一,递归调用 Insert 方法,将处理的 URL 路径部分的索引值向后移动一个位置。
// 如果找不到符合条件的子节点,说明当前节点的子节点中没有一个子节点能够匹配当前处理的 URL 路径部分,就创建一个新的子节点,将该子节点插入到当前节点的子节点列表中,然后递归调用 Insert 方法。
// 插入节点:pattern 为路由,路由的parts为字符串切片,,hight为树的深度.
func (n *Node) Insert(pattern string, parts []string, height int) {
if len(parts) == height {
n.Pattern = pattern
return
}
part := parts[height]
child := n.MatchChild(part)
if child == nil {
child = &Node{Part: part, IsWild: part[0] == ':' || part[0] == '*'}
n.Children = append(n.Children, child)
}
child.Insert(pattern, parts, height+1)
}
// 如果当前处理的 URL 路径部分已经到了最后一部分(即 len(parts) == height),或者当前节点是一个以 * 开头的通配符节点,那么说明已经找到了匹配的叶子节点,如果该叶子节点的模式不为空,就返回该叶子节点,否则返回 nil。
// 如果当前节点的子节点中有一个子节点的 part 值和当前处理的 URL 路径部分相等,或者是一个通配符(即 child.part == part || child.isWild),那么说明这个子节点可以用于匹配当前 URL 路径部分,就把 height 加一,递归调用 Search 方法,将处理的 URL 路径部分的索引值向后移动一个位置。
// 如果找不到符合条件的子节点,说明当前节点的子节点中没有一个子节点能够匹配当前处理的 URL 路径部分,就返回 nil。
func (n *Node) Search(parts []string, height int) *Node {
if len(parts) == height || strings.HasPrefix(n.Part, "*") {
if n.Pattern == "" {
return nil
}
return n
}
part := parts[height]
children := n.MatchChildren(part)
for _, child := range children {
result := child.Search(parts, height+1)
if result != nil {
return result
}
}
return nil
}
//parts 是一个字符串切片,表示一个 URL 路径经过分割后的每一个部分。比如,对于一个 URL 路径 /users/:id/books/*title,经过分割后的 parts 内容应该是 []string{"users", ":id", "books", "*title"}。
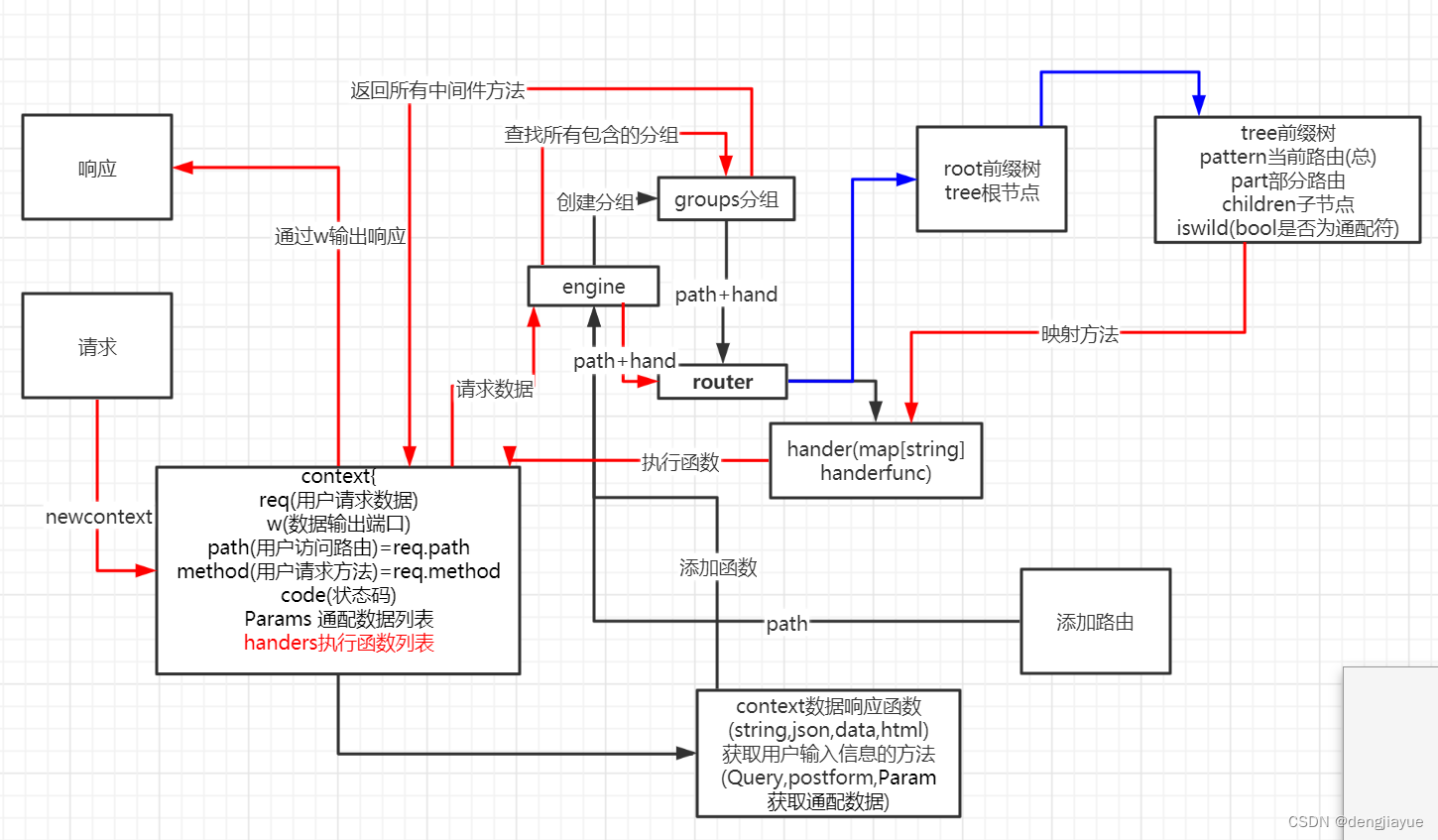
分组封装group与中间件封装
分组的主要目的就是便于中间件的添加与代码提高简洁性
比如index为母路径,其子路径有100个,每个都要执行一个相同的功能,我们就先定义为输出一个hello world
那么按照之前的代码,/index/xxx就要写一百遍,并且输出一个hello world的函数也要写100遍,如果不是输出一个hello world,而是一个关键的功能,还不能漏了,如果后面还要增加功能,也需要继续添加输出一个hello world的功能
就不是很方便,如果不是100个而是1000个或者10000个呢,就算你每次都一丝不苟的加好了,万一增加一个需求,需要增加一个输出一个hello master呢,你就要改10000行代码,就算是复制粘贴也不是很合理,或者是老板说取名不好,叫你将所有的/index/xxx全部改成/user/xxx
我们可以使用分组将相同的根路径的进行分组,并且定义一个中间件函数的储存列表,分组列表的函数将可以在继承父路径中间件函数的基础上增加增加自己的中间件函数,相应函数也变成了一个相应函数列表,当用户访问的时候需要执行中间件与路径的响应函数的总和,还可以根据需要使用next方法来控制函数执行的顺序
比如说我们要添加两个路由分别是user/id与user/name
两条路径都要输出一个hello world
除此之外访问user/id还要输出this is id
访问user/name还要输出this is name
这时我们可定义一个分组/user,然后给user分组添加中间件函数输出hello world,然后还分组执行定义/id与/name的响应函数
type RouterGroup struct {
Prefix string //父元素的字符串(分组名:例如/user)
Middlewares []HandlerFunc //中间件函数
Parent *RouterGroup //父元素的节点
Engine *Engine //所有的分组公用一个engine以实现所有的函数的接口
}
Prefix储存分组名,就是路径相同的部分 Middlewares储存中间件函数,就是访问路径就要执行的函数,比如刚刚的访问包括/user就会执行hello world,就可以将hello world函数添加到中间件函数列表中.
而context也会增加一个属性就是handers,它是一个handerfunc的函数列表,
type Context struct {
// origin objects
Writer http.ResponseWriter //Writer: 一个 http.ResponseWriter 类型的对象,用于将响应内容写入 HTTP 响应体。
Req *http.Request //Req: 一个 *http.Request 类型的指针,表示客户端发起的 HTTP 请求。
// request info
Path string //一个字符串,表示请求的 URL 路径。
Method string //一个字符串,表示请求的 HTTP 方法。get/post...
Params map[string]string //一个字符串到字符串的映射,表示 URL 查询参数或表单数据。
// response info
StatusCode int //一个整数,表示 HTTP 响应状态码。
// middleware
Handlers []HandlerFunc //handlers: 一个 HandlerFunc 类型的切片,表示当前请求需要经过的中间件函数列表。
Index int //index: 一个整数,表示当前执行到的中间件函数在 handlers 中的下标。可以理解为handers的下标
engine *Engine
}
用于储存执行函数,就是当用户访问路径正确后handers=group.Middlewares(中间件函数)+route.hander(路径的执行函数) 比如刚刚的例子:handers=group.Middlewares("/user"输出hello world)+route.hander("/user/id"映射出的输出this is id) 最后依次执行handers中所有的函数
原理如图 黑色表示添加路由路径,红色表示请求响应路径,蓝色表示添加路由与响应都走的路径 只是一个是插入,一个是查找.
type RouterGroup struct {
Prefix string //父元素的字符串(分组名;例如/user)
Middlewares []HandlerFunc //中间件函数
Parent *RouterGroup //父元素的节点
Engine *Engine //所有的分组公用一个engine以实现所有的函数的接口
}
type Engine struct {
*RouterGroup
Router *Rrouter //
Groups []*RouterGroup //
htmlTemplates *template.Template //
funcMap template.FuncMap //
}
// 初始化一个engine节点用于实现整个框架的功能
func New() *Engine {
engine := &Engine{Router: NewRouter()}
engine.RouterGroup = &RouterGroup{Engine: engine}
engine.Groups = []*RouterGroup{engine.RouterGroup}
return engine
}
// 在当前路由分组下创建一个子分组,可以通过传入前缀字符串来指定子分组的前缀,该函数会返回一个新的 RouterGroup 对象,表示创建的子分组。在创建子分组时,需要指定父分组和引擎节点。
func (group *RouterGroup) Group(prefix string) *RouterGroup {
engine := group.Engine
newGroup := &RouterGroup{
Prefix: group.Prefix + prefix,
Parent: group,
Engine: engine,
}
engine.Groups = append(engine.Groups, newGroup)
return newGroup
}
中间件创建于响应的执行
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
var middlewares []HandlerFunc
// 这行代码使用了Go语言标准库中的strings包的HasPrefix函数来判断req.URL.Path是否以group.Prefix为前缀。
for _, group := range engine.Groups {
if strings.HasPrefix(req.URL.Path, group.Prefix) {
middlewares = append(middlewares, group.Middlewares...)
}
}
c := NewContext(w, req)
c.Handlers = middlewares
c.engine = engine
engine.Router.Handle(c)
}
// 在当前路由分组下创建一个子分组,可以通过传入前缀字符串来指定子分组的前缀,该函数会返回一个新的 RouterGroup 对象,表示创建的子分组。在创建子分组时,需要指定父分组和引擎节点。
func (group *RouterGroup) Group(prefix string) *RouterGroup {
engine := group.Engine
newGroup := &RouterGroup{
Prefix: group.Prefix + prefix,
Parent: group,
Engine: engine,
}
engine.Groups = append(engine.Groups, newGroup)
return newGroup
}
文件解析封装
在服务器上面的文件都是受访问保护的,不能直接访问的,
我们可以通过打开文件的方式再添加一个文件路径相同的路由使其指向被打开的文件,就可以实现通过访问文件路径的方法访问服务器的文件了
// createStaticHandler() 函数创建了一个处理静态文件请求的 HandlerFunc。
// 它接收两个参数:相对路径 relativePath 和文件系统 fs。该函数返回另一个 HandlerFunc,该函数负责检查请求的文件是否存在并且是否可以访问
// ,如果可以访问,就使用 http.FileServer 将文件传输给客户端。
func (group *RouterGroup) createStaticHandler(relativePath string, fs http.FileSystem) HandlerFunc {
absolutePath := path.Join(group.Prefix, relativePath)
fileServer := http.StripPrefix(absolutePath, http.FileServer(fs))
return func(c *Context) {
file := c.Param("filepath")
// Check if file exists and/or if we have permission to access it
if _, err := fs.Open(file); err != nil {
c.Status(http.StatusNotFound)
return
}
fileServer.ServeHTTP(c.Writer, c.Req)
}
}
// Static() 函数是将静态文件服务器注册到路由中的函数。
// 它接收两个参数:相对路径 relativePath 和静态文件的根目录 root。它调用 createStaticHandler() 函数创建一个 HandlerFunc,并将其注册到路由器中,以便在请求 URL 匹配特定模式时调用。
func (group *RouterGroup) Static(relativePath string, root string) {
handler := group.createStaticHandler(relativePath, http.Dir(root))
urlPattern := path.Join(relativePath, "/*filepath")
// Register GET handlers
group.GET(urlPattern, handler)
}
// 设置 HTML 模板中使用的函数,接收一个 template.FuncMap 类型的参数,将其存储到 engine.funcMap 中。
func (engine *Engine) SetFuncMap(funcMap template.FuncMap) {
engine.funcMap = funcMap
}
// 用于加载 HTML 模板文件,接收一个字符串类型的参数 pattern,表示要加载的模板文件的路径。
// 该方法首先通过 template.New("") 创建了一个空的模板,然后通过 engine.funcMap 将模板中使用的函数添加到模板中,
// 最后调用 template.ParseGlob(pattern) 加载指定路径下的所有模板文件,并通过 template.Must() 将加载的模板文件包装成一个不可变的 template.Template 类型,
// 并将其存储到 engine.htmlTemplates 中。这样,在程序运行过程中,就可以通过 engine.htmlTemplates 调用 HTML 模板了。
func (engine *Engine) LoadHTMLGlob(pattern string) {
engine.htmlTemplates = template.Must(template.New("").Funcs(engine.funcMap).ParseGlob(pattern))
}
封装错误处理
错误处理就是一个中间件函数,使其在出错的时候可以继续工作,并打印错误日志.
-
Recovery中间件函数,用于捕获panic并打印详细的错误日志和堆栈信息。 -
trace函数用于打印错误信息和堆栈跟踪
// print stack trace for debug
func trace(message string) string {
//runtime.Callers函数来获取当前goroutine的调用堆栈,并将其存储在一个长度为32的uintptr数组中,最多存储32个调用者的地址。
var pcs [32]uintptr
n := runtime.Callers(3, pcs[:]) //该函数的返回值n表示实际存储在数组中的调用者数目。
//runtime.Callers函数的第一个参数指定从哪个调用者开始跟踪,
//通常传入3,以跳过当前函数trace、调用trace的函数log.Printf和Recovery函数。
var str strings.Builder
//错误信息、堆栈跟踪等信息写入该字符串中。
str.WriteString(message + "
Traceback:")
for _, pc := range pcs[:n] {//for循环遍历pcs[:n]数组,获取每个函数调用者的信息,并将其写入str中
fn := runtime.FuncForPC(pc)
file, line := fn.FileLine(pc)
str.WriteString(fmt.Sprintf("
%s:%d", file, line))
}
return str.String()
}
func Recovery() HandlerFunc {
return func(c *Context) {
defer func() {
//该代码中的recover函数用于恢复panic,并将其转换为字符串类型的message。然后,使用log.Printf函数打印错误信息和堆栈跟踪信息,并使用c.Fail函数向客户端发送一个HTTP错误响应。
if err := recover(); err != nil {
message := fmt.Sprintf("%s", err)
log.Printf("%s
", trace(message))
c.Fail(http.StatusInternalServerError, "Internal Server Error")
fmt.Fprintf(c.Writer, "404 NOT FOUND: %s
", c.Req.URL)
}
}()
c.Next()
}
}
http://localhost:9999/http://localhost:9999/static/index.html
测试
-
单元测试
-
集成测试
测试代码
func main() {
r := gee6.New()
r.Use(gee6.Logger())
r.SetFuncMap(template.FuncMap{
"FormatAsDate": FormatAsDate,
})
r.LoadHTMLGlob("templates/*")
r.Static("/assets", "./static")
stu1 := &student{Name: "Geektutu", Age: 20}
stu2 := &student{Name: "Jack", Age: 22}
//测试string函数
r.GET("/", func(c *gee6.Context) {
c.String(200, "hello world")
})
r.GET("/students", func(c *gee6.Context) {
c.HTML(http.StatusOK, "arr.tmpl", gee6.H{
"title": "gee",
"stuArr": [2]*student{stu1, stu2},
})
})
// 测试html数据响应
r.GET("/date", func(c *gee6.Context) {
c.HTML(http.StatusOK, "custom_func.tmpl", gee6.H{
"title": "gee6",
"now": time.Date(2023, 3, 29, 0, 0, 0, 0, time.UTC),
})
})
//测试PostForm函数
r.POST("/login/name", func(ctx *gee6.Context) {
ctx.String(200, "hello:"+ctx.PostForm("name"))
})
//测试Query函数
r.GET("/login", func(ctx *gee6.Context) {
ctx.String(200, "id=%s, name=%s", ctx.Query("id"), ctx.Query("name"))
})
r.GET("/users/:id", func(c *gee6.Context) {
id := c.Param("id")
c.String(200, "id=%s", id)
})
r.Run(":8888")
}
get请求可以由服务器路由发送
post请求,由apifox发送  加载html文件并渲染
加载html文件并渲染
响应数据
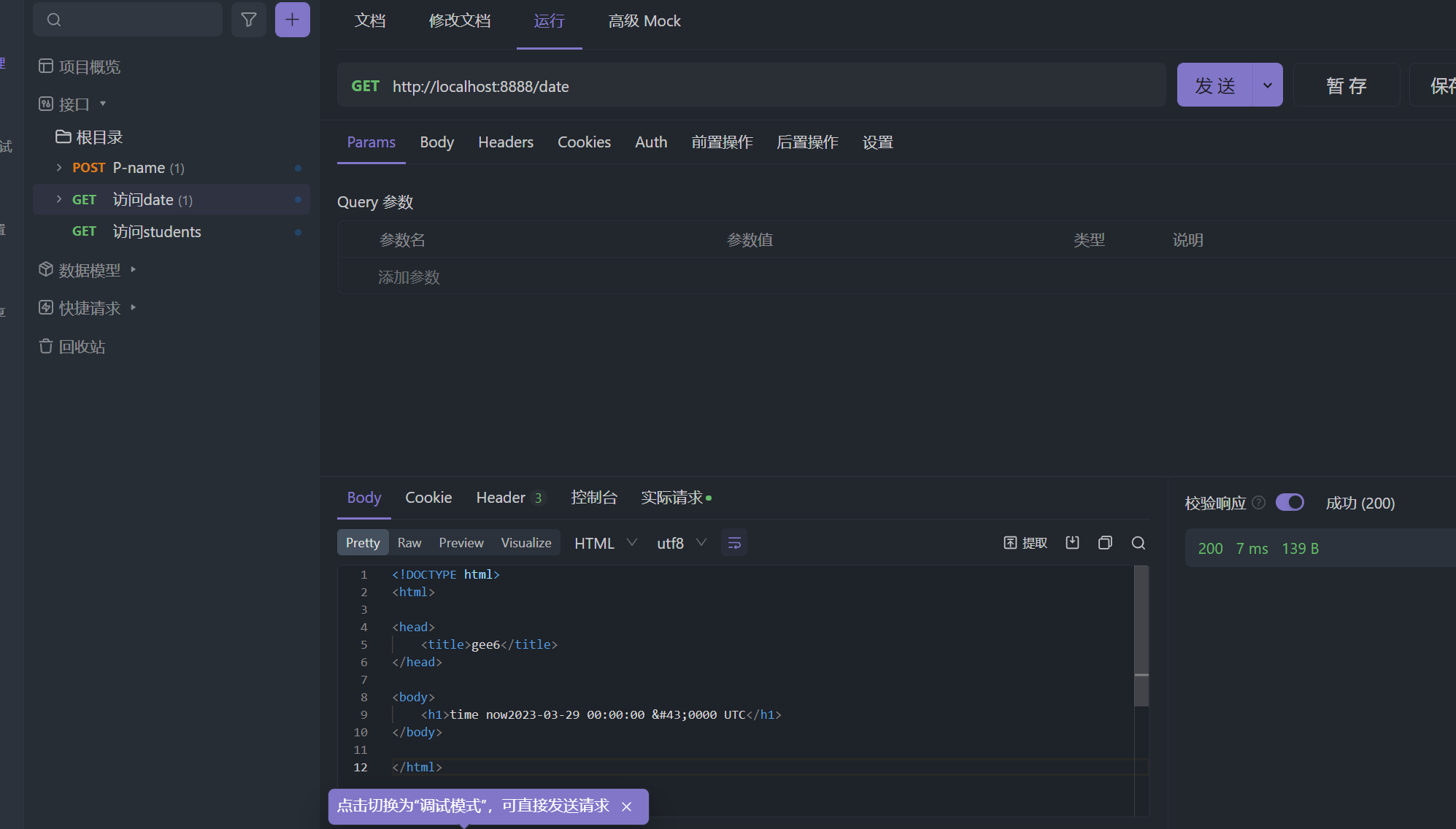 响应结果
响应结果 
-
压力测试(并发测试,测试性能)//完成 我的gee6请求"/"1000*100次压力测试结果
Document Path: /
Document Length: 11 bytes
Concurrency Level: 100
Time taken for tests: 0.118 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 113000 bytes
HTML transferred: 11000 bytes
Requests per second: 8502.39 [#/sec] (mean)
Time per request: 11.761 [ms] (mean)
Time per request: 0.118 [ms] (mean, across all concurrent requests)
Transfer rate: 938.25 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 0.9 2 10
Processing: 1 9 16.9 3 62
Waiting: 0 8 16.3 2 59
Total: 2 11 16.7 5 63
Percentage of the requests served within a certain time (ms)
50% 5
66% 6
75% 6
80% 7
90% 58
95% 61
98% 62
99% 62
100% 63 (longest request)
gin的请求"/"1000*100次压力测试结果
Document Length: 13 bytes
Concurrency Level: 100
Time taken for tests: 0.127 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 130000 bytes
HTML transferred: 13000 bytes
Requests per second: 7893.53 [#/sec] (mean)
Time per request: 12.669 [ms] (mean)
Time per request: 0.127 [ms] (mean, across all concurrent requests)
Transfer rate: 1002.11 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 1.3 1 13
Processing: 1 10 18.9 3 69
Waiting: 0 9 18.7 2 68
Total: 2 11 19.1 4 72
Percentage of the requests served within a certain time (ms)
50% 4
66% 6
75% 7
80% 9
90% 66
95% 69
98% 69
99% 69
100% 72 (longest request)
稍微快一点点,总体差不多的
优化
1.使用JSON-iterator对json数据进行解析
JSON-iterator 是一个用于高性能 JSON 解析的库,它提供了一种快速解析 JSON 数据的方式(快10倍)。以下是使用 JSON-iterator 库的基本步骤:
下载并安装 JSON-iterator 库
你可以在 https://github.com/json-iterator/go 上找到 JSON-iterator 库的代码, 可以使用 go get 命令安装库:
go get github.com/json-iterator/go
导入 JSON-iterator 库 在 Go 代码中导入 JSON-iterator 库,可以使用以下命令:
import "github.com/json-iterator/go"
2.构建线程池限制同时用户访问的数量
-
在 Web 服务中,你可以使用 ants 包来限制同时访问你的服务的用户数量。这样可以避免服务过载和资源浪费。
要安装 ants,你需要使用 Go 的包管理工具 go get 命令。
首先,在终端中打开命令行,然后输入以下命令:
go get github.com/panjf2000/ants/v2
这个命令会从 GitHub 上下载 ants 的源代码,并将其安装到你的 $GOPATH 目录中。
如果你已经在代码中导入了 ants 包,并且想要升级到最新版本,可以使用以下命令:
go get -u github.com/panjf2000/ants/v2
这个命令会更新 ants 到最新版本。
在代码中导入 ants 包后,你就可以开始使用 ants 来控制协程数量了。
下面定义一个线程池的中间件来限制同时用户访问的数量
定义OnPool中间件
// 开启线程池
func OnPool(n int) HandlerFunc {
// 创建一个具有 n 个协程的池
pool, err := ants.NewPool(n)
if err != nil {
log.Fatalf("Failed to create ants pool: %v", err)
}
defer pool.Release()
// 创建一个等待组
var wg sync.WaitGroup
// 创建一个计数器,用于记录当前正在访问服务的用户数量
var counter int
return func(ctx *Context) {
// 如果正在访问服务的用户数量已经达到了限制值,直接返回错误
if counter >= n {
ctx.Fail(http.StatusTooManyRequests, "error : 服务器繁忙,请稍后再试!")
return
}
// 将计数器加 1
counter++
// 通过 ants 执行请求处理函数
wg.Add(1)
pool.Submit(func() {
defer func() {
// 将计数器减 1
counter--
wg.Done()
}()
// 处理请求
ctx.Next()
})
}
}
我们只需要在web服务中Use这个中间件就可以了
搜索走前缀树,
-
我们可以将用户访问的path先通过前缀树获取到对应的子节点*Node -
再通过node.pattern去映射hander map中的执行函数与groups中的中间件函数,这样也可以实现中间件的通配访问
比如group("/:id")定义get("/:name",....)
那么存再tree中相应的node的pattern就为/:user/:id当用户访问/123/xm的时候是可以正常访问的
统一数据返回
对json数据返回进行包装
context.go
// 定义统一返回函数
func (c *Context) Returnfunc(code int, msg string, data interface{}) {
c.JSON(code, H{
"code": code,
"msg": msg,
"data": data,
})
}
前端根据code判断错误的类型,根据msg判断错误的信息,data为相应的数据体,为interface接口,可以使用所有的结构
json数据读取
获取传入的任意结构的json数据
我们需要根据需求定义结构,再将结构放入函数,就可以实现数据的解析
// 解析用户的json数据
func (c *Context) Getjson(v any) error {
body, err := ioutil.ReadAll(c.Req.Body)
if err != nil {
return err
}
if err = jsoniter.Unmarshal(body, v); err != nil {
return err
}
return nil
}
先读取body的内容,再解析到v(value 为任意类型),这样v就是传入的结构
本文由 mdnice 多平台发布






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结