您现在的位置是:首页 >学无止境 >基于sklearn的K近邻算法的鸢尾花种类预测代码整理网站首页学无止境
基于sklearn的K近邻算法的鸢尾花种类预测代码整理
简介基于sklearn的K近邻算法的鸢尾花种类预测代码整理
一、简介
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
二、步骤
获取数据集—数据预处理—特征工程—机器学习—模型评估
三、代码
1、导入模块
# 获取鸢尾花数据集
from sklearn.datasets import load_iris
# 分割训练集和测试集
from sklearn.model_selection import train_test_split
# 特征工程:标准化
from sklearn.preprocessing import StandardScaler
# 机器学习:KNN算法
from sklearn.neighbors import KNeighborsClassifier
2、先从sklearn当中获取数据集 然后进行数据集的分割
##其中改变random_state的数值将改变训练集和测试集数据,使最终准确率不同
#1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris,target, test_size=0.2,random_state=22)
3、数据标准化

通过fit_transform对标准差和均值进行处理
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)4、模型的调优、训练、预测
(1)这里的KNeighborsClassifier其实还可以添加一个参数指定算法如:algorithm='auto'/'ball_tree'/'kd_tree'/'brute'
(2)在训练前进行网格搜索和交叉验证
# 4、机器学习(模型训练)
estimator = KNeighborsClassifier() # 实例化估计器
# 交叉验证、网格搜索
param_grid={"n_neighbors":[1,3,5,7]}
GridSearchCV(estimator,param_gird=param_grid,cv=5) # 5折交叉验证
estimator.fit(x_train, y_train) # 模型训练
# 5、模型评估
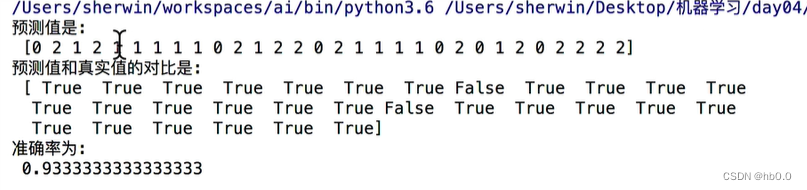
# 比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:
",y_predict)
print("比对真实值和预测值:
",y_predict == y_test)
# 计算准确率
score = estimator.score(x_test,y_test)
print("准确率为:
",score)
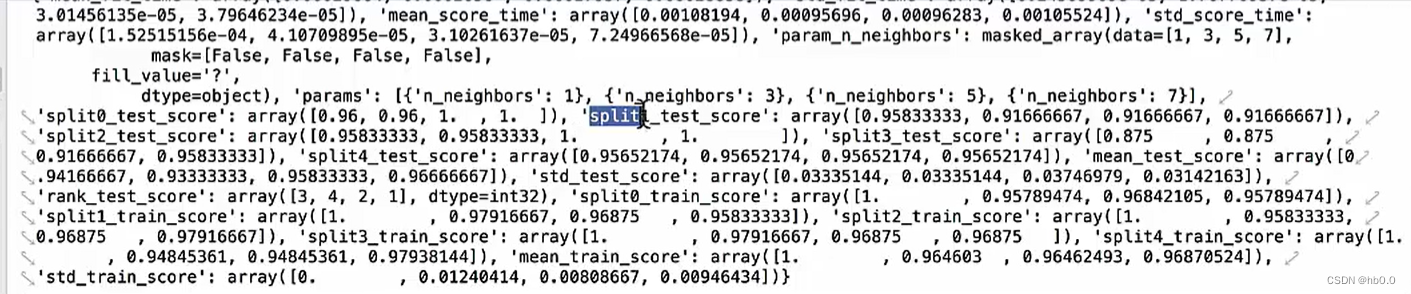
# 交叉验证网格搜索的一些api
print("在交叉验证中,得到的最好结果是:
",estimator.best_score_)
print("在交叉验证中,得到的模型结果是:
",estimator.best_estimator_)
print("在交叉验证中,得到的最好的模型是:
",estimator.cv_results_)
四、输出

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结