您现在的位置是:首页 >技术教程 >【集群模式】执行MapReduce程序-wordcount网站首页技术教程
【集群模式】执行MapReduce程序-wordcount
简介【集群模式】执行MapReduce程序-wordcount
因为是在hadoop集群下通过jar包的方式运行我们自己写的wordcount案例,所以需要传递的是 HDFS中的文件路径,所以我们需要修改上一节【本地模式】中 WordCountRunner类 的代码:
//5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//6.设置结果数据存放路径,将命令行的第二个参数作为数据的输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));打包项目
因为hadoop集群中本身就是hadoop环境,所以不需要打包hadoop-client依赖,而self4j和junit对于这个案例也意义不大,也可省略。
在pom.xml中添加依赖
其中,被注释掉的部分的作用是将maven项目中所有的依赖一同打包为jar文件,这里可以省略。
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- 需要依赖的话可以使用该插件将所有依赖一同打包 -->
<!-- <plugin>-->
<!-- <artifactId>maven-assembly-plugin </artifactId>-->
<!-- <configuration>-->
<!-- <descriptorRefs>-->
<!-- <descriptorRef>jar-with-dependencies</descriptorRef>-->
<!-- </descriptorRefs>-->
<!-- </configuration>-->
<!-- <executions>-->
<!-- <execution>-->
<!-- <id>make-assembly</id>-->
<!-- <phase>package</phase>-->
<!-- <goals>-->
<!-- <goal>single</goal>-->
<!-- </goals>-->
<!-- </execution>-->
<!-- </executions>-->
<!-- </plugin>-->
</plugins>
</build>打包完成后,建议将文件名修改的简洁一点(放便我们在linux下的输入),直接通过sz工具将jar包通过xshell拖拽到我们的hadoop目录下(将当前目录切换到hadoop目录下,然后直接将文件进行拖拽到xshell界面即可)。
sz工具说明
一、安装 lrzsz
# RedHat 系列:CentOS/Fedora
yum install lrzsz
# Debian 系列:Debian/Ubuntu
apt install lrzsz
二、执行命令 sz
sz 文件名作用:将linux环境下的文件直接下载到windows中(下载位置自己选择)
三、将文件发送到终端
这里就是从windows发送文件到linux 的hadoop目录下

执行命令
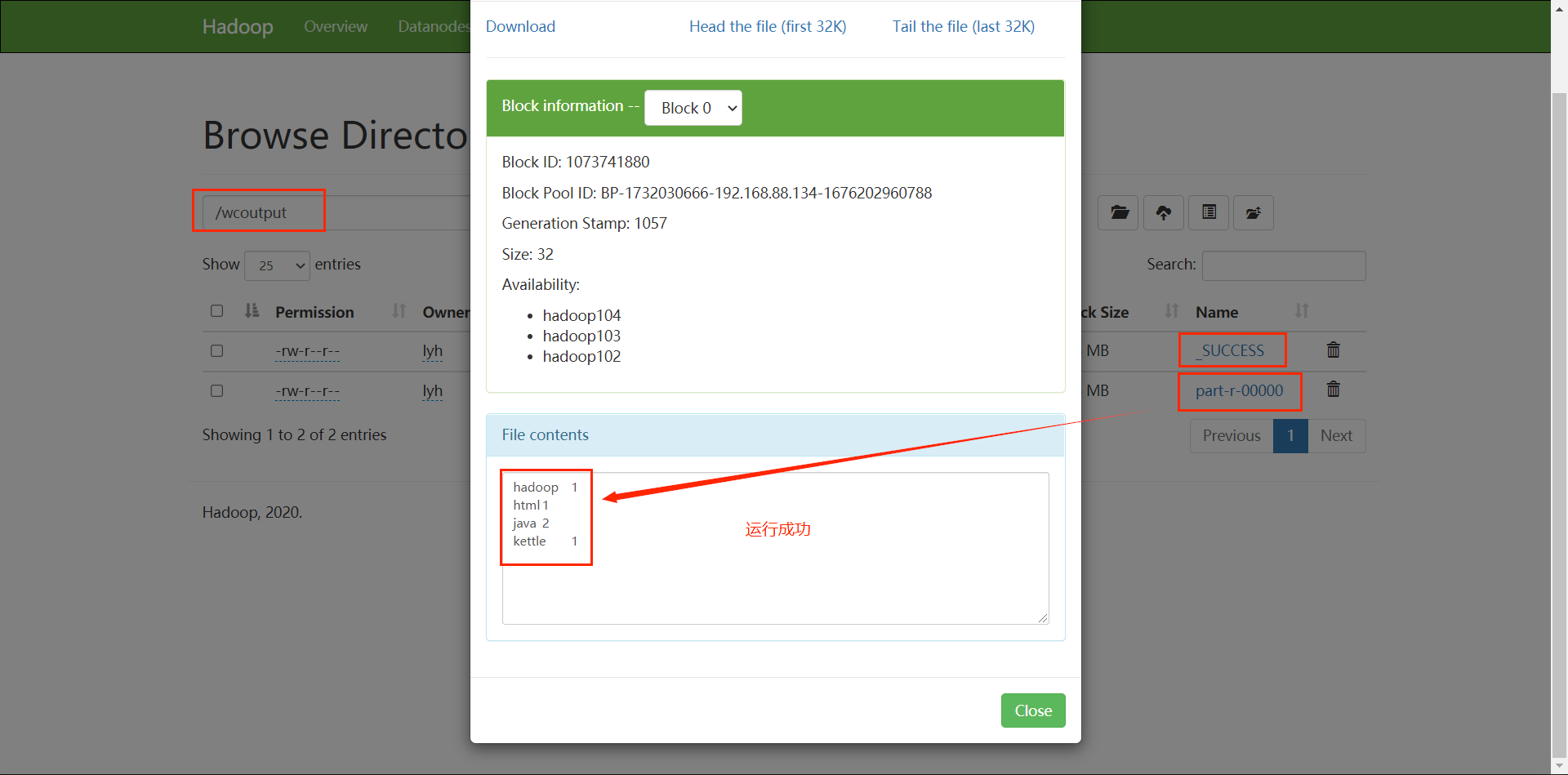
hadoop jar wc.jar com.lyh.mapreduce.wordcount2.WordCountRunner /wcinput/ /wcoutput
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结