您现在的位置是:首页 >技术交流 >image adaptive 3dlut based on deep learning网站首页技术交流
image adaptive 3dlut based on deep learning
文章目录
- image adaptive 3dlut based on deep learning
- 1. Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
- 2. CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement
- 3. 4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
- 4. RSFNet A White-Box Image Retouching Approach using Region-Specific Color Filters
- 5. Flexible Piecewise Curves Estimation for Photo Enhancement
- 6. Neural Color Operators for Sequential Image Retouching
- 7. AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
- 8. SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
image adaptive 3dlut based on deep learning
1. Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
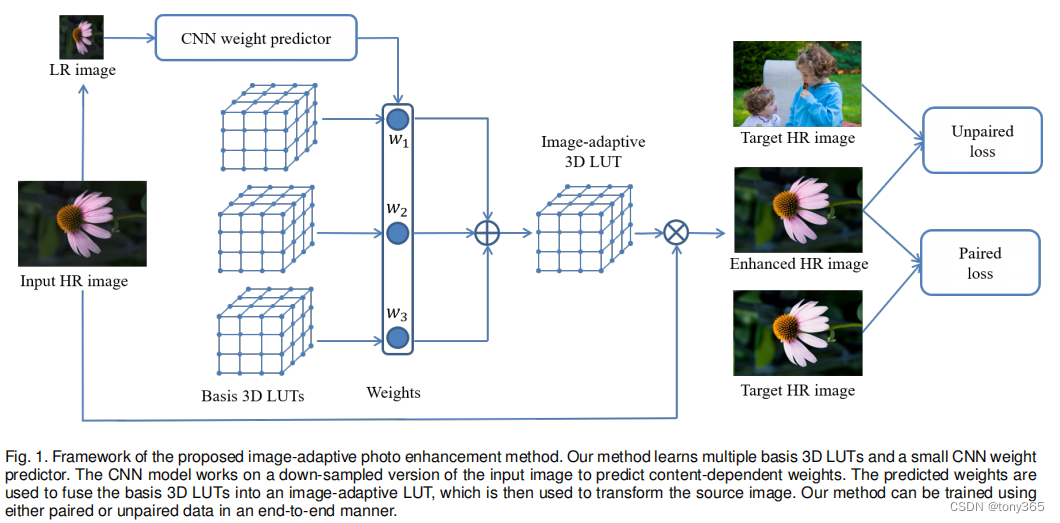
图像输入一个卷积网络输出3个weight,
初始化3个3dlut
weight 和 3dlut 合成为一个,然后三线性插值得到 pred, 与target建立损失。
2. CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement
2.1 3dlut分析
Given a specific color channel ? where ? ∈ {?, ?, ?} and the other two channels denoted by ?
and ?, we find that the output value 3Dlut(?) is strongly correlated to the input value of channel ? while weakly correlated to the input values ???, ??? of channel ? and ?, respectively.
意思是R 通道的3Dlut 与R相关性更大, 与GB通道相关性小
G 通道的3Dlut 与R相关性更大, 与RB通道相关性小
B 通道的3Dlut 与R相关性更大, 与RG通道相关性小
因此,对于R通道的3Dlut, 原本是 17 * 17 * 17 个节点, 作者替换为 S * W
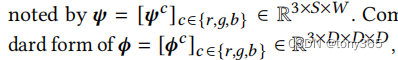
2.2 具体方法
主要是 矩阵分解的思想, 然后再重建
重建:

由两个矩阵 Ms, Mw, 压缩后的Clut 重建为原始 3dlut
2.3 主要原理
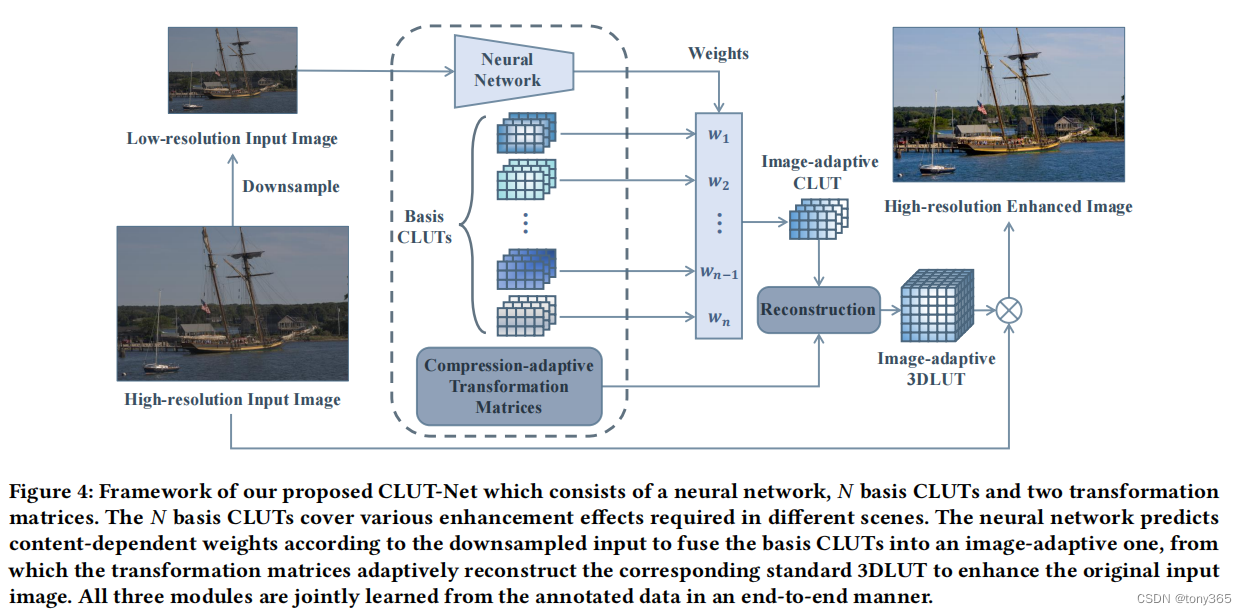
主要是对3dlut进行压缩处理,降低参数量,提高效率。
首先同样是 学习得到 weight 和 basis Cluts。
然后还有两个矩阵需要学习得到。一共这三个模块
其中bisis Cluts和两个矩阵 Ms, Mw在推理阶段是不变化的。
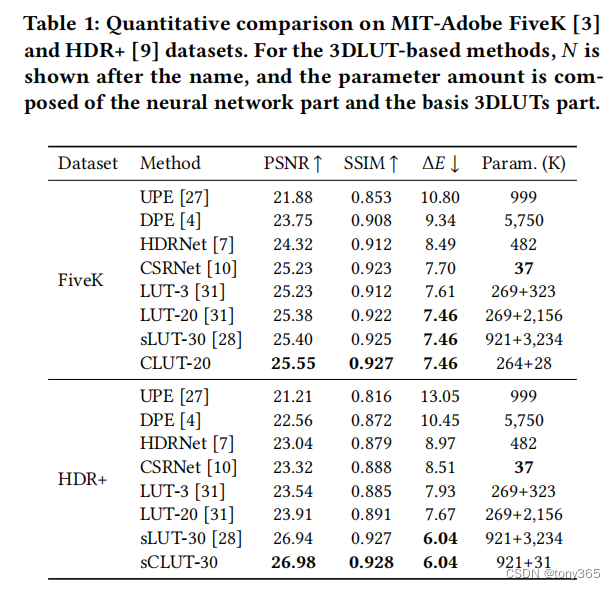
2.4 实验结果
FiveK: PSNR, SSIM, deltaE 三种评价标准
3. 4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
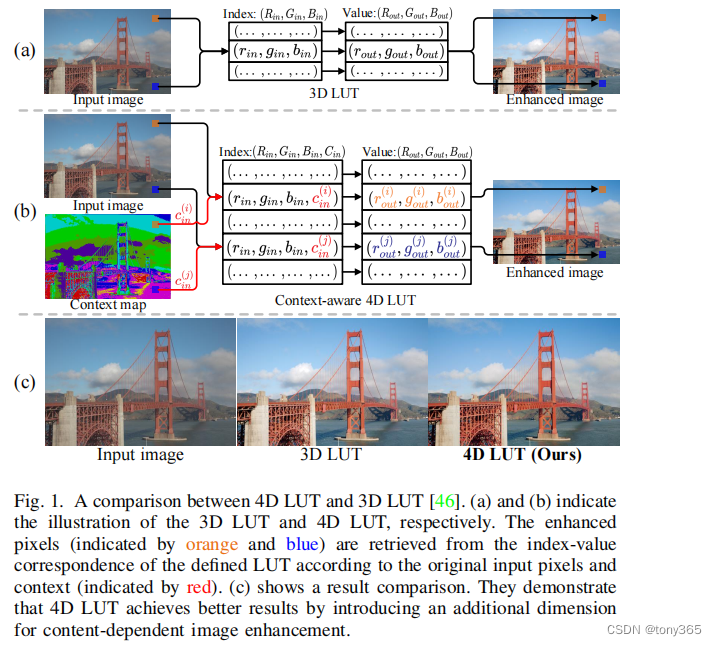
4D lut: 输入r,g,b,context 输出r,g,b
增加一个图像内容context map : achieve content-dependent image enhancement
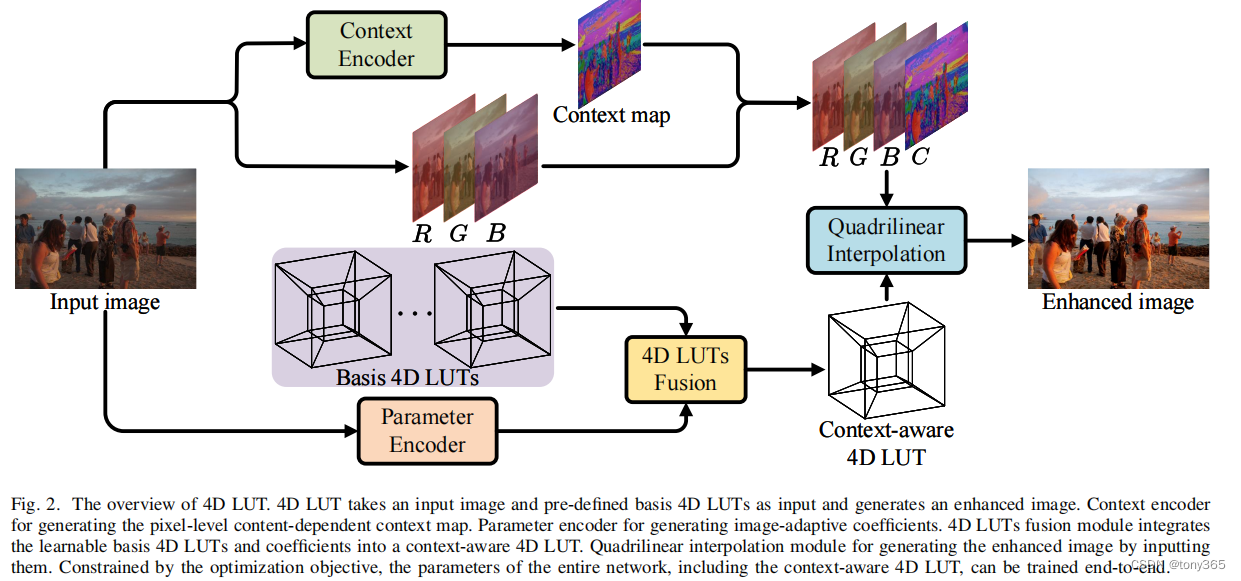
原理和3dlut类似, 框架如下很容易明白:
学习 weight, bisis 4dluts, context map
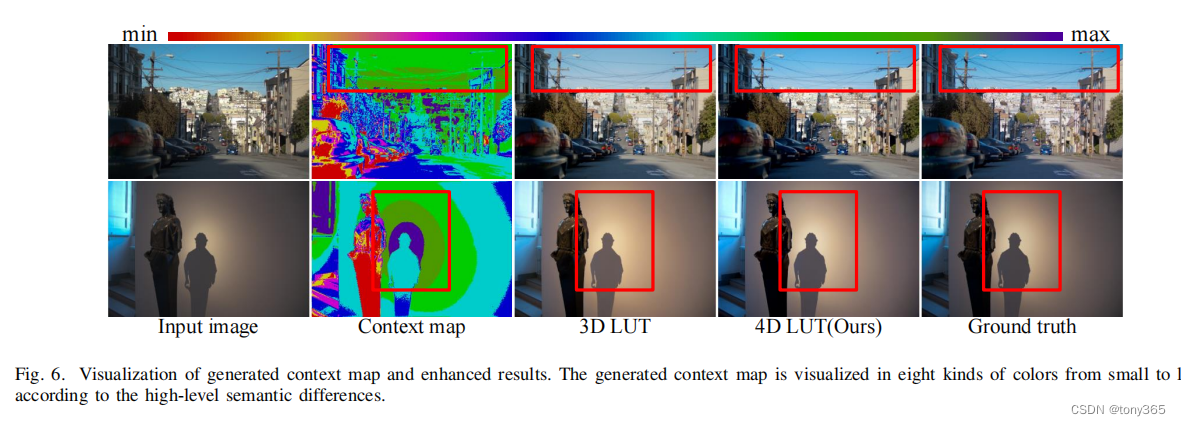
本来生成的3dlut就是image-adaptive,因为weight是每个图像都不同的。 这篇论文又多一个维度说是content map, 这样效果就有提升?
作者实验确实有提升,而且context map越大的地方相比3dlut提升越好:
4. RSFNet A White-Box Image Retouching Approach using Region-Specific Color Filters
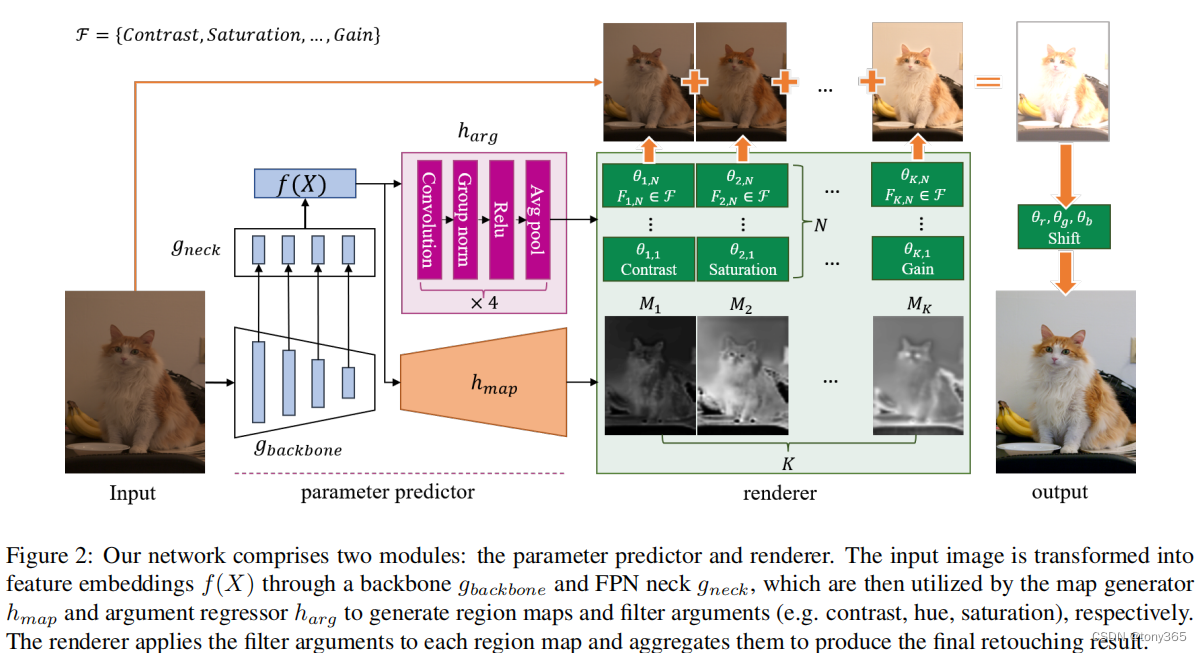
4.1 选择10个图像处理方法(或者叫做filter)
We select 10 commonly used retouching filters from traditional tools(e.g., Davinci Resolve)
to represent adjustment manipulations, including contrast,
saturation, hue, temperature, shadows, midtones, highlights
and shift.
4.2 预测每个filter的参数
比如 亮度 ±, 饱和度±

h-map 预测 K 个 map
h-arg 为每个map 预测 N 个filter的参数
然后每个map,N个filter 调整后,得到 K 个 image
K个image 加权融合,再shift得到最终的output
5. Flexible Piecewise Curves Estimation for Photo Enhancement
5.1 什么是PNG curve
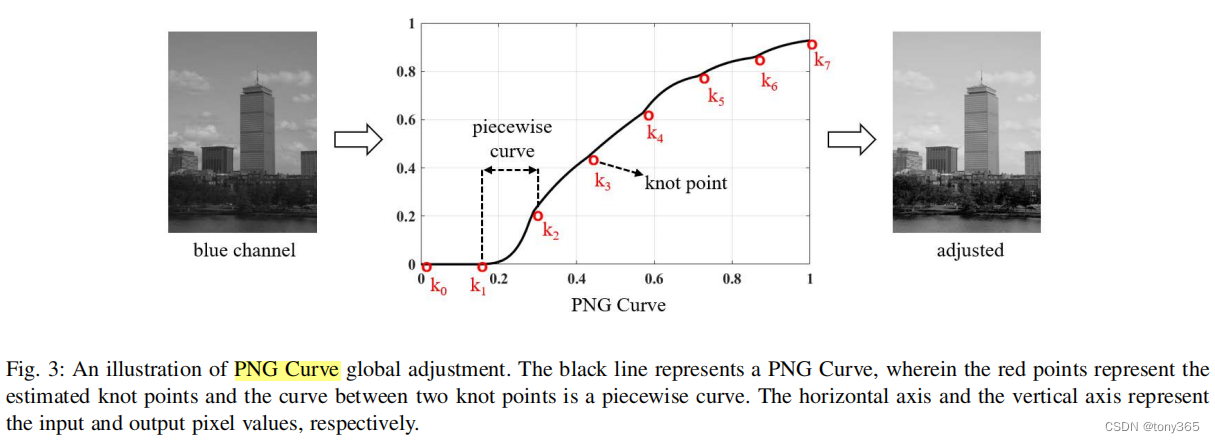
就是一个分段函数,每一段都是非线性的。
一个PNG curve可以有 knot节点,和非线性的参数 得到。
然后就得到了一个1D lut曲线。
其实有点麻烦,直接预测1D lut就可以呀。
5.2 网络结构
主要原理如下:

其中MT net: 预测 knot , parameter, 这两个构成 global look up table
然后还有 confidence map, 用于local adjust
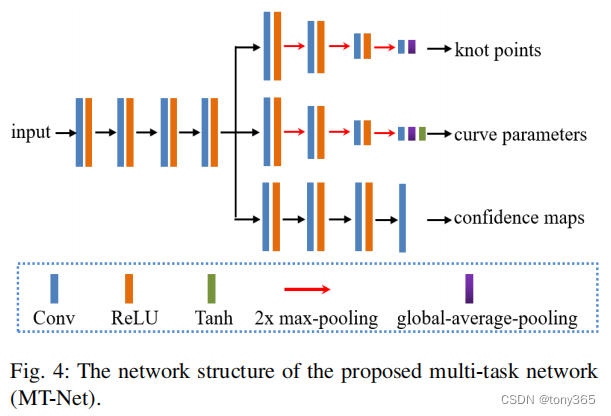
5.3 Spatial-Adaptive Confidence Map Fusion
3个global 调整后的图像,与 3个confidence map 加权就是 final output

6. Neural Color Operators for Sequential Image Retouching
和 RSFNet A White-Box Image Retouching Approach using Region-Specific Color Filters
思想类似,方法不同。
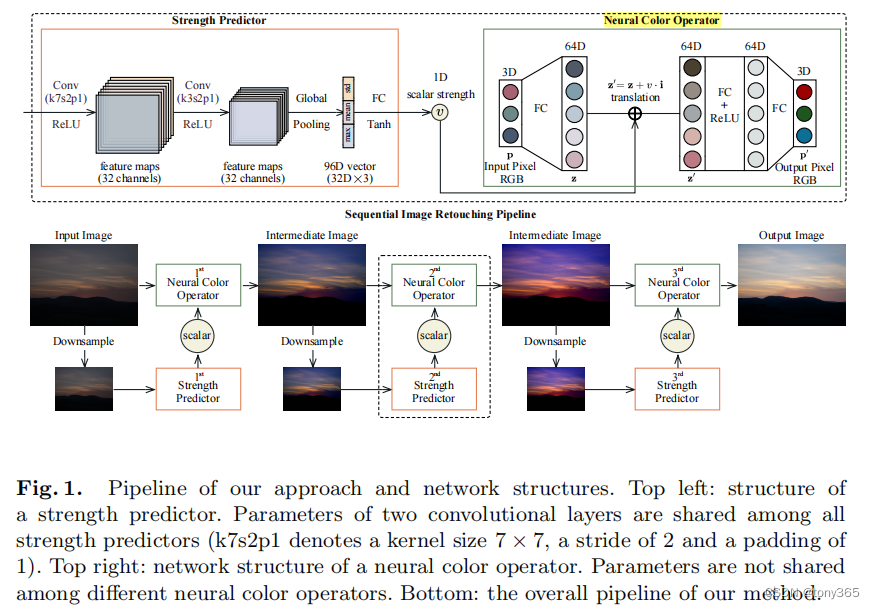
6.1 NOP (neural color operators)
这里是 利用NOP模仿 传统图像操作方法,文中模仿的是 black clipping, exposure, and vibrance in Lightroom.
通过优化的方法模仿:首先制作 三种方法的图像,然后训练:

模仿后NOP就有了,其实是初始化,后面训练的时候仍然会被更新。
6.2 strength predictor就是一个小网络预测 三个 NOP 的强度。
最终训练和网络架构如下:
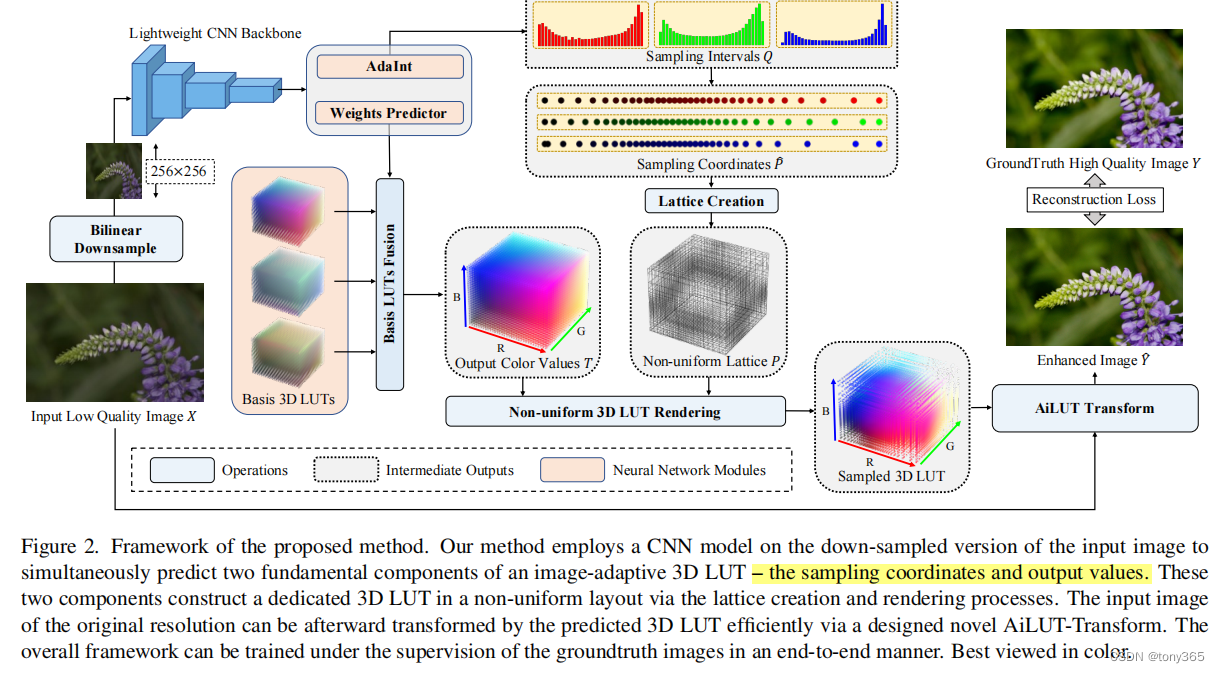
7. AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
用一张图说一下它的原理:
相比与之前的3dlut, 多了一个 position 预测, 就是以前的3dlut都是均匀的坐标分布,这里分别为RGB三个通道预测 采样的坐标位置。
原因是啥呢? 因为一个图像可能只覆盖一小部分3dlut, 浪费了很多信息。 而通过non-uniform 3dlut可以更精细的处理图像。
8. SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
这个相比与3dlut 多了 r,g,b 的1D lut.
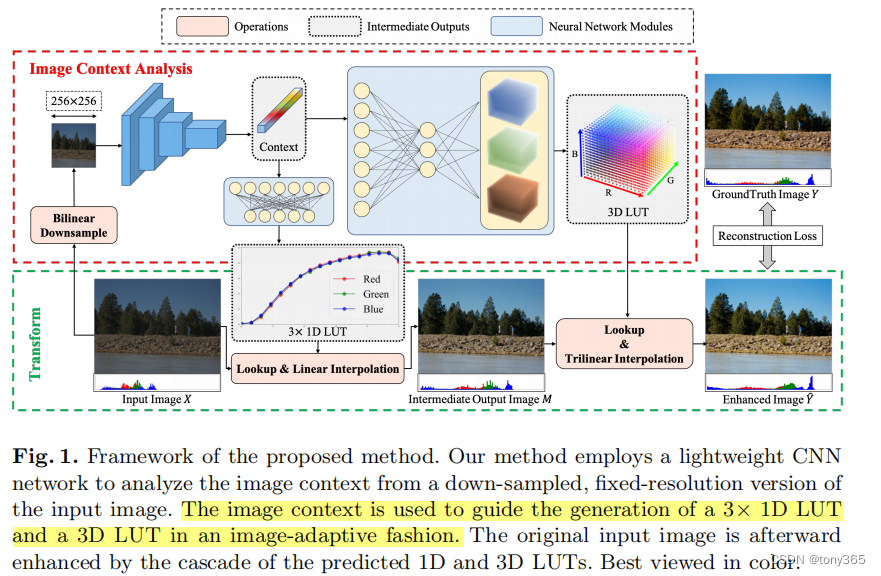
代码中 1dlut和 3dlut的表示相比于Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time 更简单优秀, 3dlut直接利用fc的weight来表示。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结