您现在的位置是:首页 >其他 >图像分割之SAM(Segment Anything Model)网站首页其他
图像分割之SAM(Segment Anything Model)
Github:https://github.com/facebookresearch/segment-anything
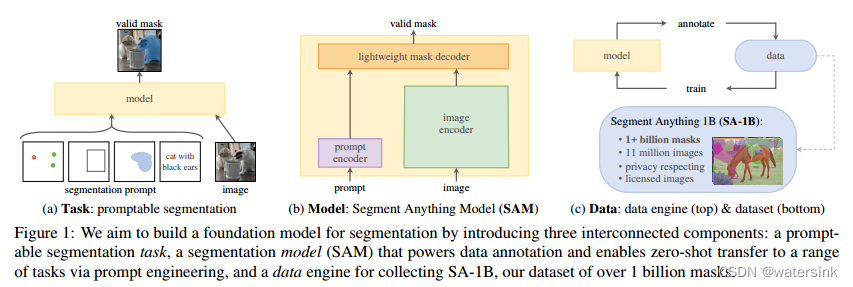
论文从zero-shot主干网络的基础出发,提出了SAM(Segment Anything Model)模型。该模型有别于传统的分割模型。传统分割模型只能输入原图输出固定的分割结果,SAM在设计上可以同时输入原图和特定提示(点、框、阴影、文本),然后根据不同的提示输出不同的分割结果图,并且SAM支持不同提示的交互式分割。SAM可以适用于多种分割场景,包括交互式分割、边界检测、超分、物体生成、前景分割、语义分割、实例分割、全景分割等众多场景。另外为了训练SAM这种多模态的模型,论文在数据上也下足了功夫,论文贡献了大规模分割数据集SA-1B,包括10亿个mask和110w图片。
要使模型具备0样本迁移能力,需要从模型容量、数据集大小、整体训练这3方面下功夫。
因此论文就从task, model, data 3个方面进行了改进。
Task:

在论文的交互式分割任务中,有的提示信息,比如点的提示,存在模棱两可的情况。为了解决这样的问题,SAM模型会同时输出3个分割结果,分别为全部(whole),部分(part), 局部(subpart)。
model:

论文设计了包含多模态信息的SAM分割模型,模型在相关提示下预测分割mask大概耗时50ms。
SAM模型由图片编码器模块(image encoder)、提示信息编码器模块(prompt encoder)、分割mask解码器模块(mask decoder)3部分组成。
图片编码器模块基于Vision Transformer (ViT)主干网络实现。
提示信息编码器模块支持稀疏特征点、框、文本 (points, boxes, text) 和稠密特征阴影 (masks)。
对于点和框在提取embedding的时候加入了位置编码信息的embedding,然后将两者相加得到最终的embedding。对于文本信息的编码采用了clip模型。
对于阴影信息的编码通过conv实现,并最终和图片的编码特征相加。
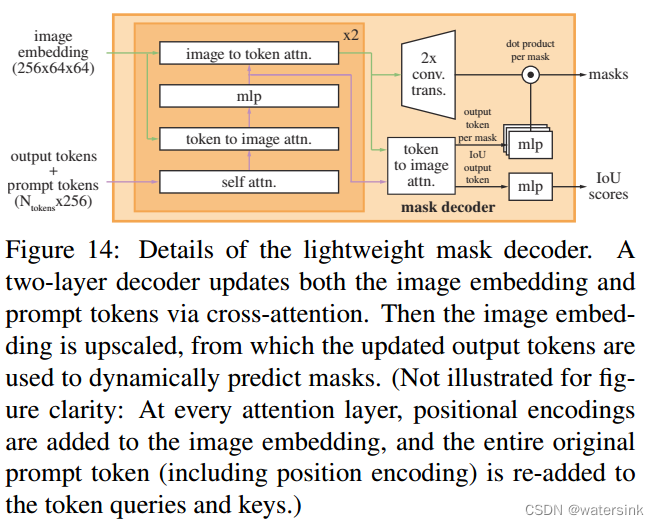
分割mask解码器模块采用Transformer的解码器部分实现,并在后面接入动态的头部预测模块。同时在训练过程中,从图片到提示和从提示到图片都引入了自监督(self-attention)和跨监督(cross-attention)操作。 最后上采样图片的embedding,通过一个MLP模块,经线性分类器,得到最终的概率图。
Data engine:
为了建立一个大规模的分割数据集,论文建立了一套数据制作的引擎。整个过程包含3个阶段,人工手动阶段(assisted-manual),半自动阶段(semi-automatic), 全自动阶段(fully automatic)。
人工手动阶段(assisted-manual):
该阶段标注过程和训练过程是同步进行的。需要人工在标注引擎上对mask进行标注,如果一个mask的标注时间超过30s就会放弃选择标注下一个图片。随着标注图片的增加和训练过程的进行,图片编码器的主干网络从ViT-B进化为ViT-H。这样的标注-训练迭代过程持续了6轮。最终每张图片的标注时间从34s降低为14s。每个图片中的mask数量从20个提升到44个。最终在该阶段收集到了4.3M mask和 120k image。
半自动阶段(semi-automatic):
该阶段主要目的是提高mask的多样性,从而提高模型的分割能力。由于标注过程更注重mask多样性的标注,所以该阶段的平均标注时间提升到了34s/图。每个图片中的mask数量从44提升到了72。在该阶段收集了5.9M mask和180k image。
全自动阶段(fully automatic):
该阶段使用模型进行全自动标注。每个图片会被设置32*32的网格点来覆盖图片中的所有物体。并且会通过iou来选择靠谱的mask,然后再进行NMS操作,从而得到最终的mask。
该阶段共收集到1.1B mask和 11M image。
Losses and training:
训练过程采用focal loss 和 dice loss的线性组合作为最终loss。
训练过程中会根据mask随机采样不同的提示进行训练。
Dataset:
大规模分割数据集SA-1B,包括10亿个mask和110w图片。相比同类分割数据集,多了400倍的mask。
Images:
原始图片的分辨率为3300× 4950,考虑到存储和展示的必要,将图片都缩放到短边为1500像素。即使是这样,也比coco数据集的图片分辨率480× 640大很多。
Masks:
通过数据引擎标注的图片具有很高的标注质量。
Mask quality:
从所有数据中随机选取了500张图片以及对应的大概50000mask。让专家进行精细标注,然后和数据引擎标注的结果进行iou对比。结果是94%的图片iou超过90%,97%的图片iou超过75%。iou一致性基本在85-91%。
Mask properties:
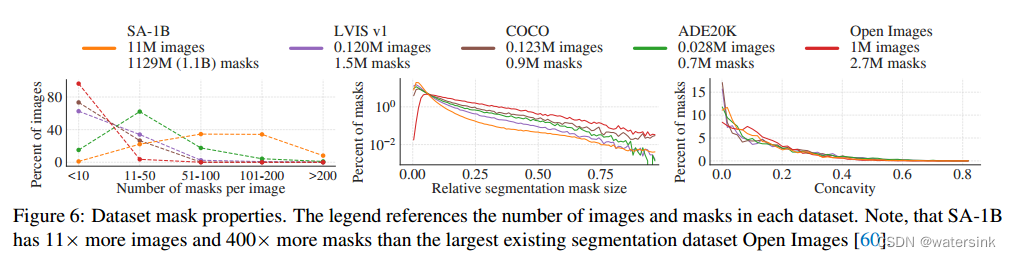
SA-1B覆盖了更广泛的图片区间,比第二大分割数据集多了11倍的图片400倍的mask。同时SA-1B包含了更多的小和中等的mask。通过mask轮廓的凹陷程度来分析mask的多样性,发现SA-1B和其他分割数据集拥有同样的mask多样性。
RAI Analysis:

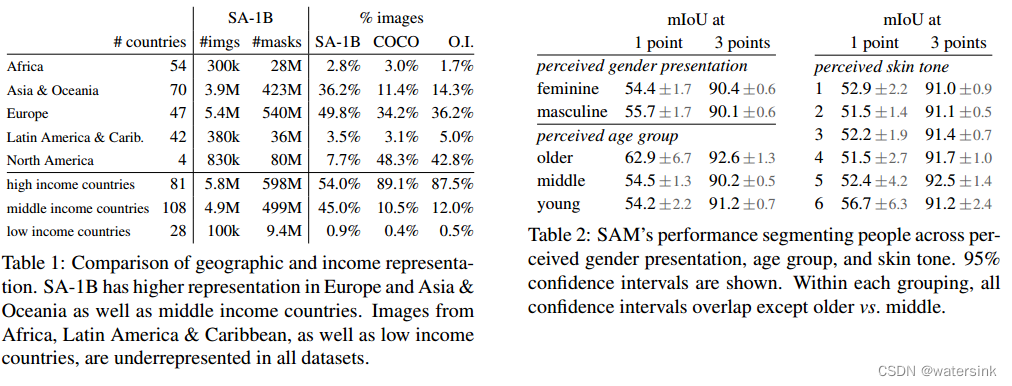
通过Responsible AI (RAI)分析,SA-1B覆盖了全世界各个角落的数据图片。同时在年龄、性别、肤色等维度也都没有各种歧视。表现出了更多的包容性More Inclusive Annotations for People (MIAP)。
实验结果:
 在众多数据集上,SAM方法都优于RITM方法。
在众多数据集上,SAM方法都优于RITM方法。
随着提示点的数量的增加,SAM的分割效果越来越高,随着提示点从1到9的增加,SAM方法和其他分割方法之间的gap越来越小。当提示点达到9个是,SAM的分割效果会略低于其他方法,这是因为SAM方法的设计初衷就不是一个高IOU的分割方法。
SAM方法在中型物体、大型物体、罕见物体、正常物体上的分割效果是优于其他分割方法的。

SAM可以实现基于文本的分割。同时在文本分割不准确的情况下,可以通过增加点的提示信息,来提升分割效果。
Limitations:
SAM在细粒度的分割、非连续部件的分割上表现都较差。同时分割的边界也不够干净利落。
对于文本到mask的分割任务还在尝试探索阶段,尚不够鲁棒,具有很大的提升空间。
结论:
SAM首个提出在图像分割领域0样本迁移的基础模型(foundation models)的概念。也就是不需要任何实际使用场景的训练,该模型就可以直接进行分割推理。论文贡献了SAM分割模型和SA-1B分割数据集。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结