您现在的位置是:首页 >技术杂谈 >MiniGPT-4:用高级大型语言模型增强视觉-语言理解网站首页技术杂谈
MiniGPT-4:用高级大型语言模型增强视觉-语言理解
摘要
论文链接:https://arxiv.org/pdf/2304.10592v1.pdf
最近的GPT-4展示了非凡的多模态能力,例如从手写文本直接生成网站和识别图像中的幽默元素。这些特征在以前的视觉语言模型中很少观察到。我们认为,GPT-4具有先进的多模态生成能力的主要原因在于使用了更先进的大型语言模型(LLM)。为研究这一现象,本文提出MiniGPT-4,用一个投影层将冻结的视觉编码器与冻结的LLM Vicuna对齐。MiniGPT-4具有许多类似于GPT-4所展示的功能,如从手写草稿中生成详细的图像描述和创建网站。此外,还观察到MiniGPT-4中其他新兴的功能,包括从给定的图像中创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片做饭等。在实验中,我们发现仅对原始图像-文本对进行预训练,可能会产生缺乏连贯性的不自然语言输出,包括重复和碎片化的句子。为解决这个问题,在第二阶段策划一个高质量、对齐良好的数据集,使用对话模板对模型进行微调。事实证明,这一步对于增强模型的生成可靠性和整体可用性至关重要。值得注意的是,该模型的计算效率很高,因为只利用大约500万对齐的图像-文本对训练一个投影层。我们的代码、预训练模型和收集的数据集可以在https://minigpt-4.github.io/上找到。
1、简介
近年来,大型语言模型(llm)经历了快速的发展[21,18,4,24,32,9,14]。凭借卓越的语言理解能力,这些模型可以以零样本的方式执行各种复杂的语言任务。值得注意的是,大规模多模态模型GPT-4[19]最近被引入,并展示了许多令人印象深刻的功能。例如,GPT-4可以产生非常详细和准确的图像描述,解释不寻常的视觉现象,甚至基于手写文本指令构建网站。
尽管GPT-4表现出了卓越的能力,但其卓越能力背后的方法仍然是一个谜[19]。我们认为,这些高级技能可能源于对更高级的大型语言模型(LLM)的利用。llm展示了各种涌现能力,这在GPT-3的少样本提示设置[4]和Wei等人(2022)[34]的发现中得到证明。在更小的模型中很难找到这样的涌现特性。据推测,这些突现能力也适用于多模态模型,这可能是GPT-4令人印象深刻的视觉描述能力的基础。
为证实该假设,提出一种名为MiniGPT-4的新模型。它使用了一个先进的大型语言模型(LLM) Vicuna[8]作为语言解码器,该模型建立在LLaMA[32]之上,据报告,根据GPT-4的评估,它的质量达到了ChatGPT的90%。在视觉感知方面,采用了与BLIP-2[16]相同的预训练视觉组件,该组件由EVA-CLIP[13]的ViT-G/14和Q-Former组成。MiniGPT-4添加了一个投影层,以将编码的视觉特征与Vicuna语言模型对齐,并冻结所有其他视觉和语言组件。MiniGPT-4最初在4个A100 gpu上使用256个批次大小进行20k步训练,利用组合数据集,其中包括来自LAION[26]、Conceptual Captions[5,27]和SBU[20]的图像,以使视觉特征与Vicuna语言模型对齐。然而,简单地将视觉特征与LLM对齐不足以训练具有像聊天机器人那样的视觉对话能力的高性能模型,原始图像-文本对背后的噪声可能会导致不连贯的语言输出。收集了另外3500对高质量对齐的图像-文本对,用设计好的对话模板进一步微调模型,以提高生成语言的自然度和可用性。
在实验中,我们发现MiniGPT-4具有许多类似于GPT-4所展示的功能。例如,MiniGPT-4可以生成复杂的图像描述,基于手写文本指令创建网站,并解释不寻常的视觉现象。此外,我们的发现表明,MiniGPT-4还具有GPT-4演示中没有展示的各种其他有趣的能力。例如,MiniGPT-4可以通过观察令人胃口大开的食物照片、受图像启发的工艺故事或说唱歌曲直接生成详细的食谱,在图像中为产品写广告,区分照片中显示的问题并提供相应的解决方案,以及直接从图像中检索有关人、电影或艺术的丰富事实等功能。这些能力在之前的视觉-语言模型(如Kosmos-1[15]和BLIP-2[16])中是不存在的,它们不适用更强的语言模型(如Vicuna)。这种对比验证了将视觉特征与高级语言模型集成可以产生涌现的视觉-语言能力。
我们总结了我们的主要发现:
- 我们的研究表明,通过将视觉特征与先进的大型语言模型Vicuna相结合,我们可以实现涌现视觉语言能力。我们演示了MiniGPT-4可以处理类似于GPT-4演示中展示的功能。
- 通过使用预训练视觉编码器和大型语言模型,MiniGPT-4实现了更高的计算效率。我们的研究结果表明,仅仅训练一个投影层就可以有效地将视觉特征与大语言模型对齐。我们的minipt -4只需要在4个A100 gpu上训练大约10个小时。
- 我们发现,使用来自公共数据集的原始图像-文本对,简单地将视觉特征与大型语言模型对齐,不足以开发性能良好的MiniGPT-4模型。它可能会产生不自然的语言输出,缺乏连贯性,包括重复和破碎的句子。解决这一限制需要使用高质量、对齐良好的数据集进行训练,这将显著提高其可用性。
2、相关工作
近年来,由于训练数据的扩大和参数数量的增加,大型语言模型取得了巨大的成功。早期的模型,如BERT[11]、GPT-2[22]和T5[23],为这一进展奠定了基础。随后,推出了具有1750亿个参数的大规模GPT-3[4],在众多语言基准上取得了重大突破。这一开发启发了其他各种大型语言模型的创建,包括Megatron-Turing NLG[28]、Chinchilla[14]、PaLM[9]、OPT[38]、BLOOM[25]和LLaMA[32]等。Wei等人进一步发现了一些只在大型模型中出现的涌现能力。这些能力的出现强调了在大型语言模型的开发中扩展的重要性。此外,通过将预训练的大型语言模型GPT-3与人类意图、指令和人类反馈相结合,InstructGPT[21]和ChatGPT[18]可以与人类进行对话交互,并可以回答各种各样的复杂问题。最近,几个开源模型,如Alpaca[30]和Vicuna[8],都是基于LLaMA[32]开发的,也表现出类似的性能。
在视觉语言任务中利用预训练的LLMs。近年来,在视觉语言任务中使用自回归语言模型作为解码器的趋势得到了极大的关注[6,15,36,31,2,16,17,12]。这种方法利用了跨模态迁移的优势,允许知识在语言和多模态域之间共享。像VisualGPT[6]和Frozen[33]这样的开创性研究已经证明了使用预训练的语言模型作为视觉语言模型解码器的好处。然后开发了Flamingo[2],使用门控交叉注意来对齐预训练的视觉编码器和语言模型,并在数十亿图像-文本对上进行了训练,展示了令人印象深刻的上下文少镜头学习能力。随后,引入了BLIP-2[16],采用带有Q-Former的Flan-T5[10],有效地将视觉特征与语言模型对齐。最近,具有5620亿个参数的PaLM-E[12]已被开发用于将现实世界的连续传感器模式集成到LLM中,从而建立了现实世界感知与人类语言之间的联系。GPT-4[19]最近也发布了,在对大量对齐的图像-文本数据进行预训练后,展示了更强大的视觉理解和推理能力。
LLMs,如ChatGPT,已被证明是通过与其他专业模型协作来提高视觉语言任务性能的强大工具。例如,Visual ChatGPT[35]和MM-REACT[37]展示了ChatGPT如何充当协调者,集成不同的视觉基础模型并促进他们的协作以应对更复杂的挑战。[39]将ChatGPT视为提问者,促使blip2回答各种问题。ChatGPT通过多轮对话,从BLIP-2中提取视觉信息,有效地总结图像内容。Video ChatCaptioner[7]扩展了这种方法,将其应用于视频时空理解。ViperGPT[29]展示了将LLM与不同视觉模型相结合以编程方式处理复杂视觉查询的潜力。相比之下,MiniGPT4直接将视觉信息与语言模型对齐,以完成各种视觉-语言任务,而不使用外部视觉模型。
3、方法
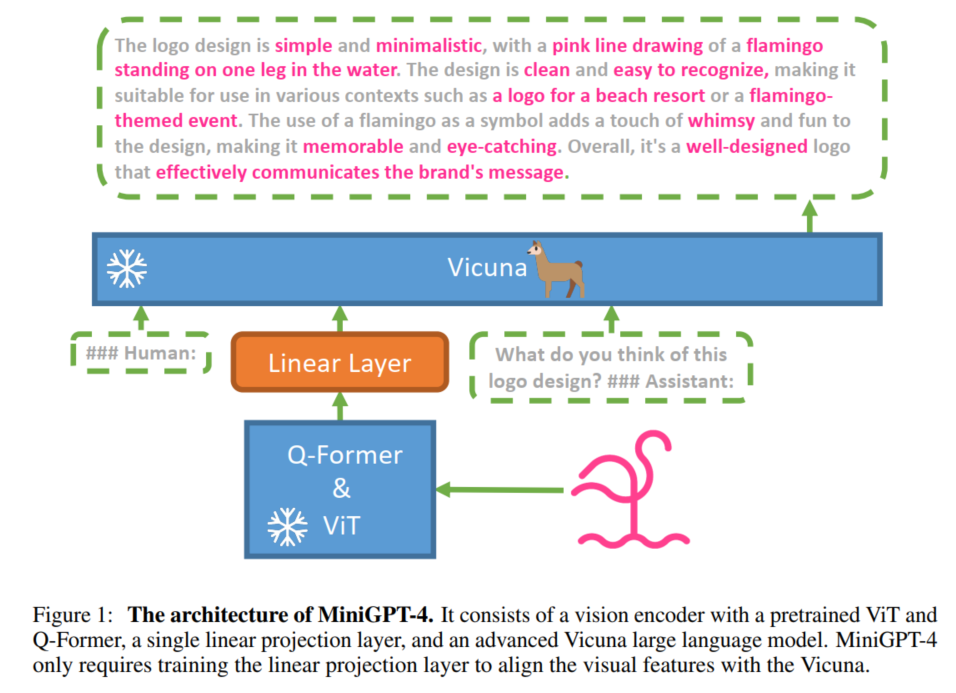
MiniGPT-4旨在将预训练视觉编码器的视觉信息与高级大型语言模型(LLM)对齐。利用Vicuna[8]作为语言解码器,以Vicuna[32]为基础构建,可以执行广泛的复杂语言任务。对于视觉感知,采用了与BLIP-2[16]中使用的相同的视觉编码器,这是一个ViT骨干[13]与其预训练的Q-Former相结合。语言和视觉模型都是开源的。本文的目标是使用线性投影层弥合视觉编码器和LLM之间的差距,所提出模型的概述如图1所示。
为了实现有效的MiniGPT-4,提出了一种两阶段的训练方法。初始阶段涉及在大量对齐的图像-文本对集合上预训练模型,以获得视觉-语言知识。在第二阶段,用一个较小但高质量的图像-文本数据集和设计的对话模板对预训练模型进行微调,以增强模型生成的可靠性和可用性。
3.1、第一个预训练阶段
在初始预训练阶段,该模型旨在从大量对齐的图像-文本对集合中获取视觉-语言知识。将注入的投影层的输出视为LLM的软提示,促使其生成相应的地面真实文本。
在整个预训练过程中,预训练的视觉编码器和LLM都保持冻结,只有线性投影层被预训练。我们使用概念描述[5,27]、SBU[20]和LAION[26]的组合数据集来训练我们的模型。该模型经历了20,000个训练步骤,批次大小为256,覆盖了大约500万张图像-文本对。整个过程大约需要10个小时,使用4块A100 (80GB) gpu。
第一个预训练阶段的问题。在第一个预训练阶段之后,MiniGPT-4展示了拥有丰富知识的能力,并对人类的询问提供合理的回应。然而,我们观察到它很难产生连贯的语言输出的实例,例如生成重复的单词或句子,碎片化的句子或无关内容。这些问题阻碍了MiniGPT-4与人类进行流畅的视觉对话的能力。
我们还注意到,在GPT-3中也面临着类似的问题。尽管在广泛的语言数据集上进行了预训练,但GPT-3不能直接生成符合用户意图的语言输出。通过从人类反馈中进行指令微调和强化学习的过程,GPT-3进化为GPT-3.5[21,18],并能够产生对人类更友好的输出。这种现象与MiniGPT-4在初始预训练阶段后的当前状态相似。因此,我们的模型在现阶段可能难以生成流利和自然的人类语言输出也就不足为奇了。
3.2、策划高质量的视觉语言域对齐数据集。
为了在生成的语言中实现更大的自然性并增强模型的可用性,第二阶段的对齐过程是必不可少的。虽然在NLP领域,指令微调数据集[30]和会话[1]很容易访问,但在视觉语言领域没有相应的数据集。为了解决这个不足,我们精心策划了一个高质量的图像-文本数据集,专门为对齐目的量身定制。该数据集随后用于在第二阶段对准过程中微调我们的MiniGPT-4。
初始对齐图像-文本生成。在初始阶段,我们使用从第一个预训练阶段导出的模型来生成给定图像的全面描述。为了使我们的模型能够产生更详细的图像描述,我们设计了一个遵循Vicuna[8]语言模型会话格式的提示符,如下所示:
###Human: Describe this image in detail. Give as many details as
possible. Say everything you see. ###Assistant:
在这个提示中,<ImageFeature>表示线性投影层产生的视觉特征。
为了识别不完整的句子,我们检查生成的句子是否超过80个标记。如果没有,我们将加入一个额外的提示符,###Human: Continue ###Assistant:,提示我们的MiniGPT-4扩展生成。通过连接这两个步骤的输出,我们可以创建一个更全面的图像描述。这种方法使我们能够生成更多具有详细和信息丰富的图像描述的图像-文本对。我们从Conceptual Caption数据集中随机选择5000张图像[5,27],并使用这种方法为每张图像生成相应的语言描述。
数据后处理。生成的图像描述仍然存在很大的噪声和错误,如单词或句子的重复,以及不连贯陈述的存在。为了缓解这些问题,我们使用ChatGPT通过使用下面的提示来改进描述:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not
English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences.
Return directly the results without explanation. Return directly the input paragraph if it is already
correct without explanation.
在完成后处理阶段后,我们手动验证每张图像描述的正确性,以保证其高质量。具体来说,我们检查每个生成的图像描述是否遵循我们期望的格式,并通过消除ChatGPT无法检测到的冗余单词或句子来手动改进生成的标题。最后,5000对图像-文本对中只有大约3500对满足我们的要求,这些对随后被用于第二阶段的对齐过程。
3.3、第二阶段微调
在第二阶段,我们用精心策划的高质量图像-文本对我们的预训练模型进行微调。在调优期间,我们在以下模板中使用预定义的提示符:
###Human: ###Assistant:
在这个提示中,<Instruction>表示从我们预定义的指令集中随机抽样的指令,其中包含各种形式的指令,例如“详细描述这张图像”或“您可以为我描述这张图像的内容吗?”需要注意的是,我们没有计算这个特定文本-图像提示的回归损失。
因此,MiniGPT-4现在能够产生更自然、更可靠的反应。此外,我们观察到模型的微调过程非常高效,只需要400个训练步骤,批量大小为12,使用单个A100 GPU只需7分钟即可完成。
4、演示:
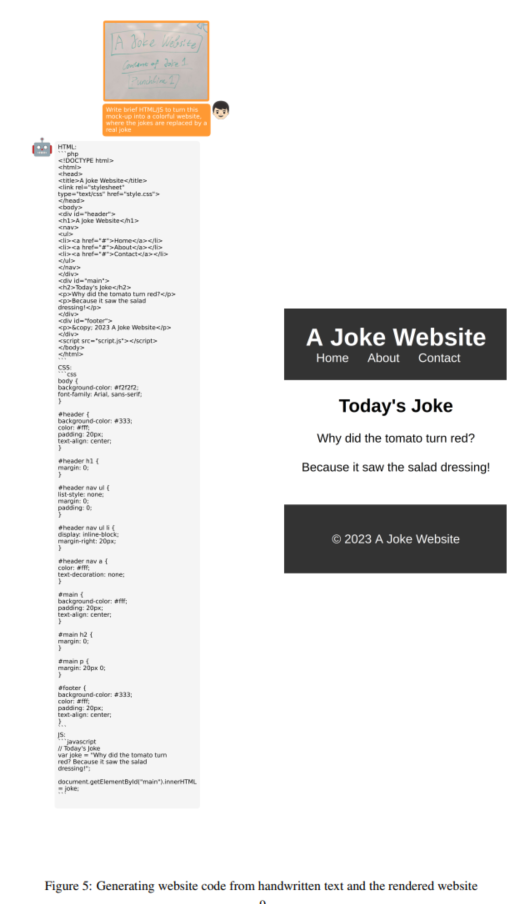
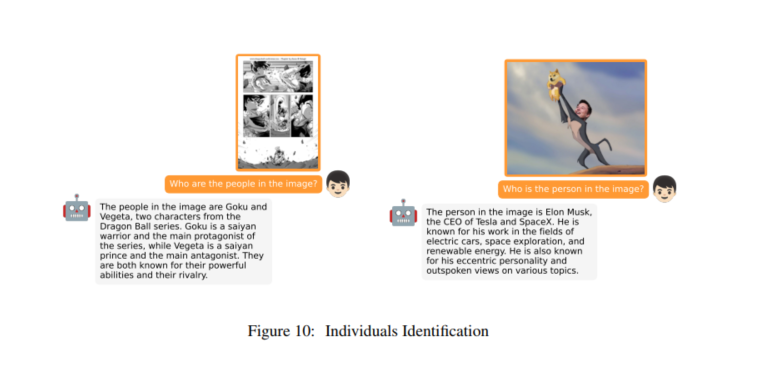
我们的MiniGPT-4展示了许多与GPT-4类似的功能。这些包括生成详细的图像描述(图2),识别图像中的有趣方面(图3),以及发现不寻常的内容(图4)。此外,该模型可以从手写文本生成网站(图5)。我们还发现,我们的MiniGPT-4还具有其他能力,例如识别图像中的问题并提供解决方案(图6),受图像启发创作诗歌或说唱歌曲(图7),为图像写故事(图8),在图像中为产品做广告(图9),识别个体(图10),提供有见地的图像评论(图11),检索与图像相关的事实(图12),教用户使用给定的照片烹饪食物(图13)。这些不同的示例展示了我们的MiniGPT-4的强大功能。
5、局限性
尽管MiniGPT-4处理了许多先进的视觉语言功能,正如我们在演示中所展示的,但它目前仍然面临一些限制。
语言的错觉。由于minipt -4是建立在LLM的基础上的,它继承了LLM的局限性,如不可靠的推理能力和幻想不存在的知识。这个问题可以通过使用更多高质量、对齐的图像-文本对来训练模型,或者在将来与更高级的llm对齐来缓解。

感知能力不足。MiniGPT-4的视觉感知仍然有限。它可能很难从图像中识别详细的文本信息,并区分空间定位。这种限制可能源于以下几个因素:1)缺乏足够的对齐图像-文本数据,其中包含足够的信息,如空间定位和光学字符注释。这个问题可以通过在更一致和更丰富的数据上进行训练来缓解。2)视觉编码器中使用的冻结Q-former可能会失去一些基本特征,如视觉空间接地。用一个更强的视觉感知模型来取代它,这可能会得到改善。3)只训练一个投影层可能无法提供足够的能力来学习广泛的视觉-文本对齐。















站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结