您现在的位置是:首页 >技术交流 >【Redis系列】Redis布隆过滤之8亿大数据集实战网站首页技术交流
【Redis系列】Redis布隆过滤之8亿大数据集实战

序言
即便平凡的日子仿佛毫无波澜,但在某个特定的时刻,执着的努力便会显现出它的价值和意义。
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级重要
- 蓝色:用来标记二级重要
希望这篇文章能让你不仅有一定的收获,而且可以愉快的学习,如果有什么建议,都可以留言和我交流
1 问题描述
接到一个优化场景:
小程序用户的openid作为最主要的业务查询字段,在做了缓存设计之后仍有非常高频的查询,通过埋点简单统计约在每日1000w次。
其中:由于有新增用户,新增矩阵小程序等原因
导致请求的openid根本不存在MySQL数据库中,这部分统计约占30%左右,也就是约300w次查询是浪费的。
2 解决思路
优化的思路也非常简单:布隆过滤(bloom filter)
它作为非常成熟的方案很适合类似场景,所以使用bloom在查MySQL之前优先判断openid是否存在就可以解决这个问题。
虽然平时对bloom的原理有所了解,但是本次主要的挑战是需要过滤的openid数据集有8亿,具体实施的过程中遇到了很多没有考虑过的细节,因此整理分享一下。
3 方案介绍
1. 布隆过滤
先简单描述一下bloom filter的原理
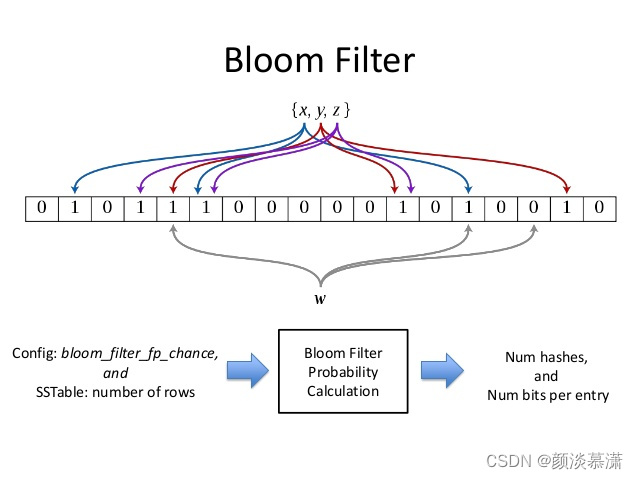
布隆过滤器(Bloom Filter)
- 是一种数据结构,其主要功能是判断某个元素是否出现在集合中。
- 它通过使用多个哈希函数将元素映射到一个位数组中,并将对应位标记为1,来实现对元素的判重。
- 如果一个元素在位数组中对应的位置上有一位为0,那么该元素一定不存在于集合中,
- 如果所有对应位都为1,那么该元素可能存在于集合中。
具体来说:
当要加入一个元素时,使用多个不同的哈希函数对该元素进行哈希,得到多个哈希值,然后将这些哈希值对应的位数组上的位置置为1。
当查找一个元素时,同样使用多个哈希函数进行哈希,然后查看对应位置上的位,
- 如果存在任意一位为0,那么该元素不存在于集合中;
- 如果所有位都为1,那么该元素可能存在于集合中,需要进一步确认。
由于布隆过滤器的判重操作只需对位数组进行一次查找,无需遍历整个集合,因此它的查找效率非常高,并且它所占用的空间相对于集合本身也非常少。
但是,布隆过滤器存在一定的误判率。
对于一个元素,如果多个哈希函数将其映射到的位都已被标记为1,则它可能被误判为存在于集合中,即有一定的假阳性率 。
误判率取决于哈希函数的数量和位向量的长度。
2. 8亿数据集怎么做布隆?
8亿数据集做布隆过滤主要需要规划的问题是
- 内存占用|分配、分片
- Hash函数规划
- 如何论证效果
内存占用
说bloom的内存占用前,要来说明一下bloom在redis中的实现:
- Bitmap
Bitmap:是一种Bit数组数据结构,它的主要作用是储存0和1两个状态。
在Redis中,Bitmap通过字符串来实现,一个字符串可以存储超过2^32个元素,所以一个bloom能存储的最大上限就是2^32个,约42.9亿。
那么在redis底层bitmap 和string 其实是同一个结构,只是提供了不同的命令来进行操作,想要看一个redis 对象占用多少内存可以使用 MEMORY USAGE Key,返回的是字节数:
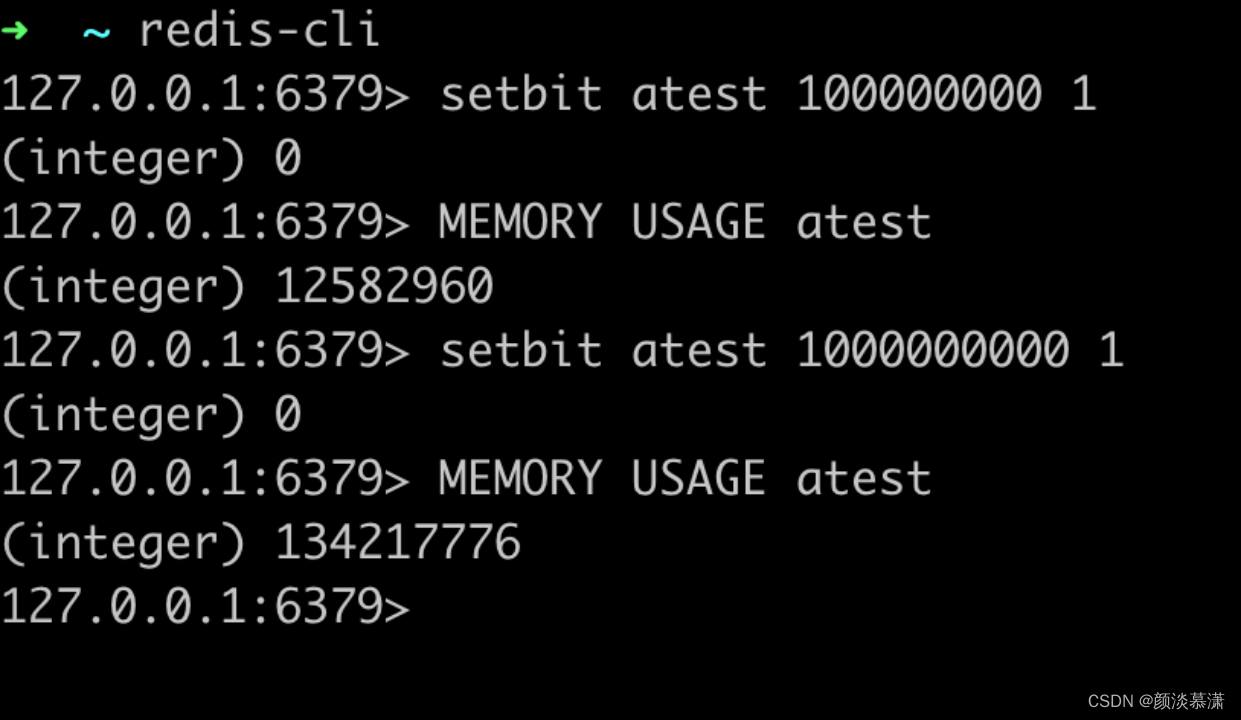
Bitmap内存分配
如上图bitmap操作命令:
setbit key index 1这里有个需要注意的问题是,如果index比较大,比如在10亿位上写1,那么redis在内存分配时其实是分配了一个完整的10亿长度的数组(10亿位是1,前面的全部补0)。
可以理解为是一个非常长的字符串,而不是下意识我们想象很简单的1个bit那么小,它瞬间分配的内存大概在128M
Bitmap读取
既然一个10亿位的bitmap需要128M内存,那么很直接的想法就是,这么大的内存,bitmap读起来会慢吗?
结论当然是不会的。
因为bitmap是一个位数组,它在内存中是连续的,CPU并不需要去读取完整的128M内存,它只要获取到这个数组起始位置,+ index 就可以计算出对应的位置然后进行读取,也就是说,它的时间复杂度是 O(1)
虽然读操作是O(1)的,但是很显然创建一个大的bitmap时是非常重量级的一个操作,布隆过滤的Hash函数计算基本都是32位,64位长度的Hash值
我们无法控制bitmap的增长是一个顺序过程,所以最直接的办法就是控制最大长度
分片 -- Roaring Bitmap
目前openid数据总量已经有8亿+,肯定不能都放入一个Bitmap中,这样就会有个非常大的key,最简单的优化方向就是分片。
Roaring Bitmap (RBM)就是类似的算法:
RBM 的主要思想并不复杂,简单来讲,有如下三条:
- 范围划分:将 32-bit 的范围 ([0, n)) 划分为 2^16 个桶,每一个桶有一个 Container 来存放一个数值的低16位;
- 存储:在存储和查询数值的时候,将一个数值 k 划分为高 16 位(k % 2^16)和低 16 位(k mod 2^16),取高 16 位找到对应的桶,然后在低 16 位存放在相应的 Container 中;
- 查询判断:当查询一个数值 k 是否存在时,我们只需要判断 k mod 2^16 是否存在于对应的 Container 中即可。
这个例子可以用计算器按一下,就很直观的理解了
举例:821697800 对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA, 低16位为 1D08。
找到数值为 30FA 的容器(如果该容器不存在,则新建一个)这里用 Bitmap 做存储,找到了相应的容器后,看一下低 16 位的数值 1D08,它相当于是 7432,因此在 Bitmap 中找到相应的位置,将其置为 1 即可。
实现取高位和低位代码:
取高位作桶,就是通过位运算向右移16位
将一个数的二进制位向左或向右移动特定的位数。向左移动相当于在该数的二进制表示中加上多个0,向右移动相当于去掉多余的二进制位$container = $hash >> 16;取低位作数据字段,就是通过&位运算取低16位
它对两个数的每一个二进制位进行比较,只有当两个数的对应二进制位都为1时,结果才会将该位置设置为1,否则设置为0
0xFFFF是16位全1的二进制数的16进制表示方式
可以简单理解为就是截取了一个数的低16位
$index = $hash & 0xFFFF;
做一个git演示,可以看到821697800转换为二进制后,通过位移取值,可以一次一次移,也可以一次移16位
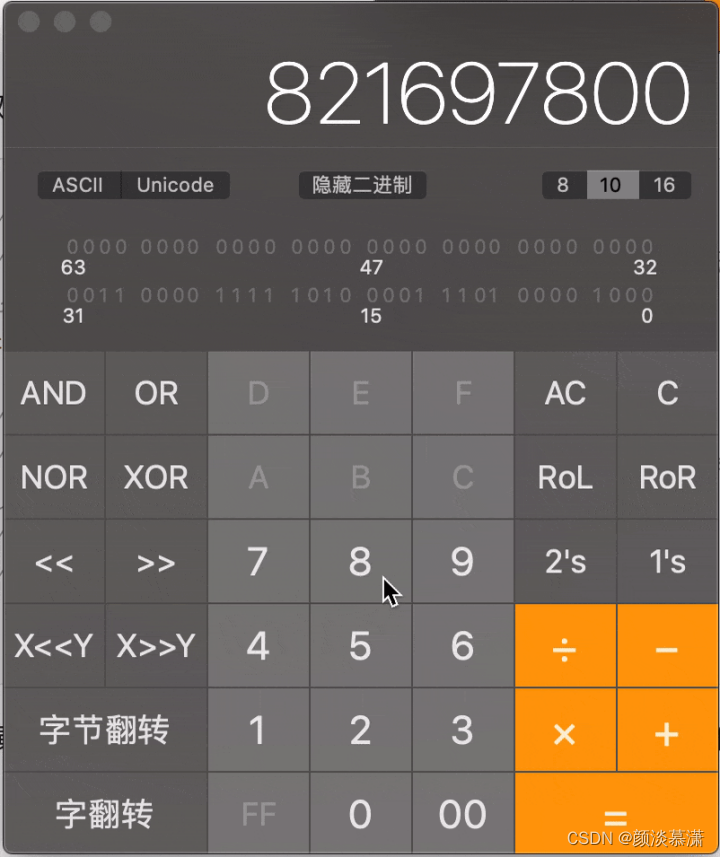
总结一下,Roaring Bitmap 先取高16位做桶,是为了做分片,取低16位做index,主要是为了压缩Bitmap长度,达到节省内存的作用
Hash函数规划
已知openid 8亿,按照预留一倍空间规划,这个布隆过滤器总量为20亿,通过RBM分片分散到2^16 = 65525 个container中,也就是每个container承担3w个元素,这样取低16位长度就不太够了
我们可以取低17位,这样一个container可以存储13w个,我们期望的误差率为千分之一,
那么可以通过布隆计算公式得出需要的Hash函数个数,这里我们直接利用ChatGPT计算就好了:

得出需要15个哈希函数,其实按照公式算出来这个值还是有待论证,
我对它的存疑是这样的:
15个哈希函数,3w个元素,如果不考虑哈希冲突,也就是有15*3w = 45w,而一个container的总长度才13w,真的能满足千分之一的误差率吗?
我去验证了,答案是不能。
45w次hash结果存入一个container中,大多数的位都存满了1,导致误差率高达50%以上,
那么问题出在哪里?没有深究这个公式是如何推导出来的,就用最朴素的方法去尝试了多种条件下的测试。
得出的结论是: 元素n ✖️ 哈希个数k ,不能超过位图长度m(或者超过太多), 在这个基础上,公式推导的结论是可靠的
继续思考
既然65535个container不能满足需要,那可选的方案就只有继续扩大bitmap长度或者是扩大container数量,
最终用的方案是扩大一倍container数量,也就是取高17位作为container,公式推导需要10个hash,最终也验证了这个结果是对的。

得出了hash个数之后,就需要找一些具体的hash函数,这里贴一些搜集到的hash算法和具体实现的代码:
Redis key数量对性能是否有影响
既然选择了扩大container数量,紧接着需要思考的问题是:
- 选择增大key数量会对redis性能有影响吗?
Redis把所有的key都放在了一个字典当中,它的查询时间复杂度是O(1),
所以基本上key的数量对于读写操作是不影响的,可以看下Redis 键空间示意图:
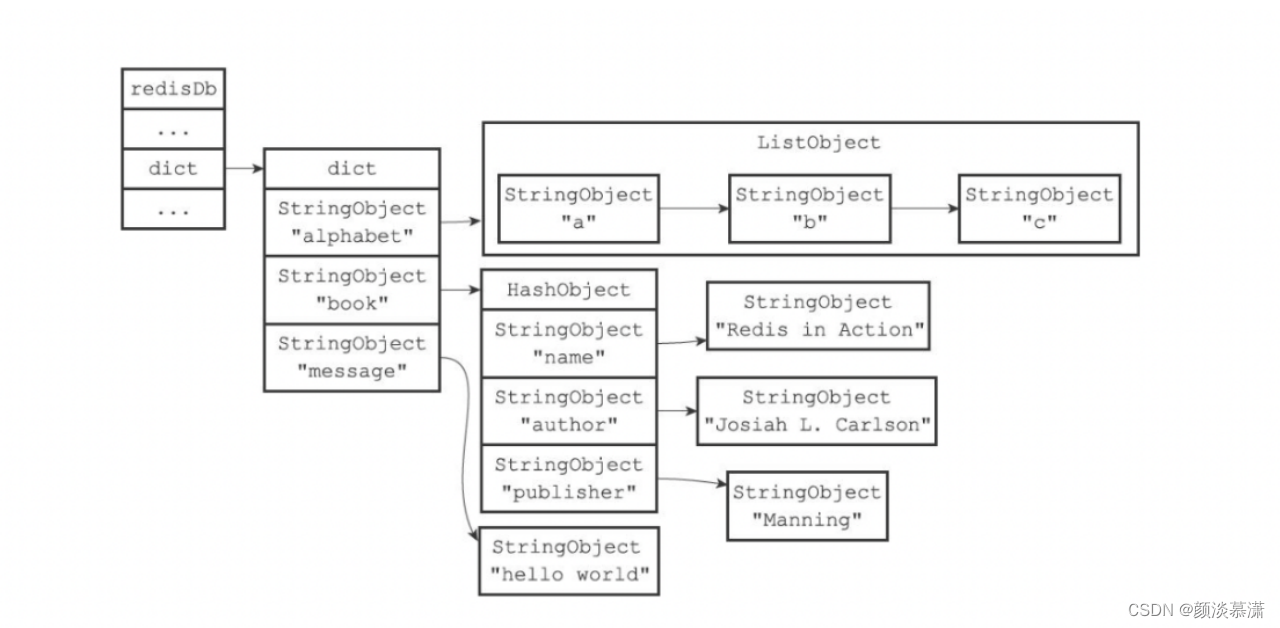
但是也不是说Redis 中key过多完全没有影响,它更主要的会影响到备份的效率,特别是启动一个RDB 备份 Process时,key的数量过多会影响RDB的执行效率,而负责数据读取和备份是两个线程,并不影响。
总结
结论就是,只是多了6w的key而已,对Redis来说还是很小case的,相对于可能形成的大key造成的影响,还是简单的多加点key吧。
3 如何论证
在整个实战的过程中,非常大的一个难点是数据集很大,想要验证一遍非常耗时,那么提升redis写入性能就非常重要,所以一开始就想到了使用批处理的方式
$redis->multi()
->set('key1', 'val1')
->get('key1')
->set('key2', 'val2')
->get('key2')
->exec();
但是这里有一个细节, $redis->multi() 支持两种模式,
Redis::MULTI
Redis::PIPELINE
默认是使用Redis::MULTI,但它们的作用和使用方式略有不同:
- Pipeline:将多个命令打包发送给 Redis 服务器,减少了客户端与服务器之间的网络往返次数,从而提高了性能。但是,pipeline 并没有原子化地执行这些命令,因此如果出现错误会导致部分命令执行失败。
- Multi:通过开启一个事务(transaction),将多个命令打包成一个事务,确保这些命令被原子化地执行。由于事务需要等待 EXEC 命令的触发才会真正执行,因此 multi 的性能可能会受到影响。但是,multi 提供了回滚(rollback)和乐观锁控制机制,可以避免在多个客户端同时修改同一资源时出现数据竞争问题。
总结
虽然Multi 功能更强,但是相对的执行效率也慢(当然还是要比单个命令执行要快的,节省了很多网络io时间)
而pipeline模式的性能要比Multi快50倍 ( 这个基准测试是以100w次 setbit操作测试的)
按照pipeline模式下8亿openid * 10 hash = 20个小时来算,
如果用multi,我可能要跑一个月 ?
选对批处理模式,对于大批量数据导入相当重要
投票






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结