您现在的位置是:首页 >其他 >基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类网站首页其他
基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类
简介基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类
基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类
任务概述
微博情绪分类任务旨在识别微博中蕴含的情绪,输入是一条微博,输出是该微博所蕴含的情绪类别。在本次任务中,我们将微博按照其蕴含的情绪分为以下六个类别之一:积极、愤怒、悲伤、恐惧、惊奇和无情绪。
- 数据集来源
本数据集(疫情微博数据集)内的微博内容是在疫情期间使用相关关键字筛选获得的疫情微博,其内容与新冠疫情相关 - 数据集标签
每条微博被标注为以下六个类别之一: neural (无情绪)、angry (愤怒)、sad (悲伤)、surprise (惊奇)。 - 数据集规模
疫情微博训练数据集包括6,606条微博,测试数据集包含5,000条微博。 - 数据集形式
数据集为json格式,包含三个字段:数据编号(id),文本(content),情绪标签(label)。
示例: {“id”: 11, “content”: “武汉加油!中国加油!安徽加油!”, “label”: “happy”} - 下载
链接:https://pan.baidu.com/s/13_czouycHR8mK0pHzuH7gw
提取码:t81p
实验设计
文件框架
简单易懂,不多逼逼
main函数
import torch
import torch.nn as nn
import torch.optim as optim
import pickle as pkl
from src.models.textCNN import TextCNN
from src.models.textRNN import TextRNN
from src.models.Transformer import Transformer
from src.Config import Config
from src.get_data import get_data
from src.train import train
if __name__ == '__main__':
config = Config()
batch_size = config.batch_size
learning_rate = config.learning_rate
train_dataloader, test_dataloader, n_vocab = get_data(batch_size)
config.n_vocab = n_vocab
# model = TextCNN(config).to(Config.device)
model = TextRNN(config).to(Config.device)
# model = Transformer(config).to(Config.device)
# 导入word2vec训练出来的预训练词向量
id_vec = open(Config.id_vec_path, 'rb')
id_vec = pkl.load(id_vec)
id_vec = torch.tensor(list(id_vec.values())).to(Config.device)
if config.embedding_pretrained:
model.embedding = nn.Embedding.from_pretrained(id_vec)
loss = nn.CrossEntropyLoss().to(Config.device)
optimizer = optim.Adam(params=model.parameters(), lr=learning_rate)
train(model, loss, optimizer, train_dataloader, test_dataloader, Config.epoches, Config.device)
配置信息
import torch
class Config():
train_data_path = '../data/virus_train.txt'
test_data_path = '../data/virus_eval_labeled.txt'
vocab_path = '../data/vocab.pkl'
split_word_all_path = '../data/split_word_all.txt'
model_file_name_path = '../data/vec_model.txt'
id_vec_path = '../data/id_vec.pkl'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
word_level = True # 按照字级别进行分词
embedding_pretrained = False # 是否使用预训练的词向量
label_fields = {'neural': 0, 'happy': 1, 'angry': 2, 'sad': 3, 'fear': 4, 'surprise': 5}
all_seq_len = 64 # 句子长度,长剪短补
batch_size = 128
learning_rate = 0.0001
epoches = 50
dropout = 0.5
num_classes = 6
embed_dim = 300
n_vocab = 0
数据准备
import re
import os
import json
import jieba
import pickle as pkl
import numpy as np
import gensim.models.word2vec as w2v
import torch
from src.Config import Config
import torch.utils.data as Data
train_data_path = Config.train_data_path
test_data_path = Config.test_data_path
vocab_path = Config.vocab_path
label_fields = Config.label_fields
all_seq_len = Config.all_seq_len
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
# 构造字典
def build_vocab(content_list, tokenizer):
file_split_word = open(Config.split_word_all_path, 'w', encoding='utf-8')
vocab_dic = {}
for content in content_list:
word_lines = []
for word in tokenizer(content):
vocab_dic[word] = vocab_dic.get(word, 0) + 1
word_lines.append(word)
str = " ".join(word_lines) + "
"
file_split_word.write(str)
file_split_word.close()
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
vocab_dic = {word_count: idx for idx, word_count in enumerate(vocab_dic)}
return vocab_dic
def build_id_vec(vocab_dic, model):
model.wv.add_vector(UNK, np.zeros(300))
model.wv.add_vector(PAD, np.ones(300))
id2vec = {}
for word in vocab_dic.keys():
id = vocab_dic.get(word, vocab_dic.get(UNK))
vec = model.wv.get_vector(word)
id2vec.update({id: vec})
return id2vec
# 预训练词向量
def train_vec():
model_file_name = Config.model_file_name_path
sentences = w2v.LineSentence(Config.split_word_all_path)
model = w2v.Word2Vec(sentences, vector_size=300, window=20, min_count=0)
model.save(model_file_name)
# 读入数据与数据清洗
def load_data(root):
content_list = []
content_token_list = []
label_list = []
# 不同分词器
if Config.word_level:
tokenizer = lambda x: [y for y in x]
else:
tokenizer = lambda x: jieba.cut(x, cut_all=False)
file = open(root, 'r', encoding='utf-8')
datas = json.load(file)
# 多种数据清洗方式
# pattern = re.compile(r'[^u4e00-u9fa5|,|。|!|?|[|]]')
pattern = re.compile(r'[^u4e00-u9fa5|,|。|!|?]')
# pattern = re.compile(r'[^u4e00-u9fa5|,|。]') # seq_len=32 CNN:67%-68% RNN:61%-62% Transformer:63-64%
# pattern = re.compile(r'[^u4e00-u9fa5|,|。|!]') # CNN:65%-66%
for data in datas:
content_after_clean = re.sub(pattern, '', data['content'])
content_list.append(content_after_clean)
label_list.append(label_fields[data['label']])
if os.path.exists(vocab_path):
vocab = pkl.load(open(vocab_path, 'rb'))
else:
vocab = build_vocab(content_list, tokenizer)
pkl.dump(vocab, open(vocab_path, 'wb'))
if Config.embedding_pretrained:
train_vec()
model = w2v.Word2Vec.load(Config.model_file_name_path)
id_vec = build_id_vec(vocab, model)
pkl.dump(id_vec, open(Config.id_vec_path, 'wb'))
for content in content_list:
word_line = []
token = list(tokenizer(content))
seq_len = len(token)
if seq_len < all_seq_len:
token.extend([PAD] * (all_seq_len - seq_len))
else:
token = token[:all_seq_len]
for word in token:
word_line.append(vocab.get(word, vocab.get(UNK)))
content_token_list.append(word_line)
n_vocab = len(vocab)
return content_token_list, label_list, n_vocab
# 将数据映射为Dataset
class WeiBboDataset(Data.Dataset):
def __init__(self, content_token_list, label_list):
super(WeiBboDataset, self).__init__()
self.content_token_list = content_token_list
self.label_list = label_list
def __getitem__(self, index):
label = float(self.label_list[index])
return torch.tensor(self.content_token_list[index]), torch.tensor(label)
def __len__(self):
return len(self.label_list)
# 核心函数
def get_data(batch_size):
train_content_token_list, train_label_list, n_vocab = load_data(train_data_path)
test_content_token_list, test_label_list, _ = load_data(test_data_path)
train_dataset = WeiBboDataset(train_content_token_list, train_label_list)
test_dataset = WeiBboDataset(test_content_token_list, test_label_list)
train_dataloader = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = Data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
return train_dataloader, test_dataloader, n_vocab
if __name__ == '__main__':
get_data(32)
模型搭建
TextCNN
import torch.nn as nn
import torch
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, Config):
super(TextCNN, self).__init__()
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 64 # 卷积核数量(channels数)
self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)
self.convs = nn.ModuleList(
[nn.Conv2d(1, self.num_filters, (k, Config.embed_dim)) for k in self.filter_sizes])
self.dropout = nn.Dropout(Config.dropout)
self.fc = nn.Linear(self.num_filters * len(self.filter_sizes), Config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x))
x = x.squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x)
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
LSTM
import os
import torch
import torch.nn as nn
import numpy as np
class TextRNN(nn.Module):
def __init__(self, Config):
super(TextRNN, self).__init__()
self.hidden_size = 128 # lstm隐藏层
self.num_layers = 2 # lstm层数
self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)
self.lstm = nn.LSTM(Config.embed_dim, self.hidden_size, self.num_layers,
bidirectional=True, batch_first=True, dropout=Config.dropout)
self.fc = nn.Linear(self.hidden_size * 2, Config.num_classes)
def forward(self, x):
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
Transformer
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import copy
class Transformer(nn.Module):
def __init__(self, Config):
super(Transformer, self).__init__()
self.hidden = 1024
self.last_hidden = 512
self.num_head = 5
self.num_encoder = 2
self.dim_model = 300
self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)
self.postion_embedding = Positional_Encoding(Config.embed_dim, Config.all_seq_len, Config.dropout, Config.device)
self.encoder = Encoder(self.dim_model, self.num_head, self.hidden, Config.dropout)
self.encoders = nn.ModuleList([
copy.deepcopy(self.encoder)
# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
for _ in range(self.num_encoder)])
self.fc1 = nn.Linear(Config.all_seq_len * self.dim_model, Config.num_classes)
# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)
# self.fc1 = nn.Linear(config.dim_model, config.num_classes)
def forward(self, x):
out = self.embedding(x)
out = self.postion_embedding(out)
for encoder in self.encoders:
out = encoder(out)
out = out.view(out.size(0), -1)
# out = torch.mean(out, 1)
out = self.fc1(out)
return out
class Encoder(nn.Module):
def __init__(self, dim_model, num_head, hidden, dropout):
super(Encoder, self).__init__()
self.attention = Multi_Head_Attention(dim_model, num_head, dropout)
self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)
def forward(self, x):
out = self.attention(x)
out = self.feed_forward(out)
return out
class Positional_Encoding(nn.Module):
def __init__(self, embed, pad_size, dropout, device):
super(Positional_Encoding, self).__init__()
self.device = device
self.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])
self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])
self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)
out = self.dropout(out)
return out
class Scaled_Dot_Product_Attention(nn.Module):
'''Scaled Dot-Product Attention '''
def __init__(self):
super(Scaled_Dot_Product_Attention, self).__init__()
def forward(self, Q, K, V, scale=None):
'''
Args:
Q: [batch_size, len_Q, dim_Q]
K: [batch_size, len_K, dim_K]
V: [batch_size, len_V, dim_V]
scale: 缩放因子 论文为根号dim_K
Return:
self-attention后的张量,以及attention张量
'''
attention = torch.matmul(Q, K.permute(0, 2, 1))
if scale:
attention = attention * scale
# if mask: # TODO change this
# attention = attention.masked_fill_(mask == 0, -1e9)
attention = F.softmax(attention, dim=-1)
context = torch.matmul(attention, V)
return context
class Multi_Head_Attention(nn.Module):
def __init__(self, dim_model, num_head, dropout=0.0):
super(Multi_Head_Attention, self).__init__()
self.num_head = num_head
assert dim_model % num_head == 0
self.dim_head = dim_model // self.num_head
self.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)
self.attention = Scaled_Dot_Product_Attention()
self.fc = nn.Linear(num_head * self.dim_head, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
batch_size = x.size(0)
Q = self.fc_Q(x)
K = self.fc_K(x)
V = self.fc_V(x)
Q = Q.view(batch_size * self.num_head, -1, self.dim_head)
K = K.view(batch_size * self.num_head, -1, self.dim_head)
V = V.view(batch_size * self.num_head, -1, self.dim_head)
# if mask: # TODO
# mask = mask.repeat(self.num_head, 1, 1) # TODO change this
scale = K.size(-1) ** -0.5 # 缩放因子
context = self.attention(Q, K, V, scale)
context = context.view(batch_size, -1, self.dim_head * self.num_head)
out = self.fc(context)
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out
class Position_wise_Feed_Forward(nn.Module):
def __init__(self, dim_model, hidden, dropout=0.0):
super(Position_wise_Feed_Forward, self).__init__()
self.fc1 = nn.Linear(dim_model, hidden)
self.fc2 = nn.Linear(hidden, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out
训练和测试
import os
import torch
import torch.nn as nn
from torch.autograd import Variable
from utils.draw_loss_pic import draw_loss_pic
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def train(net, loss, optimizer, train_loader, test_loader, epoches, device):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epoches):
net.train()
total_loss = 0.0
correct = 0
sample_num = 0
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device).long()
target = target.to(device).long()
optimizer.zero_grad()
output = net(data)
ls = loss(output, target)
ls.backward()
optimizer.step()
total_loss += ls.item()
sample_num += len(target)
max_output = output.data.max(1, keepdim=True)[1].view_as(target)
correct += (max_output == target).sum()
print('epoch %d, train_loss %f, train_acc: %f' % (epoch + 1, total_loss/sample_num, float(correct.data.item()) / sample_num))
train_loss.append(total_loss/sample_num)
train_acc.append(float(correct.data.item()) / sample_num)
test_ls, test_accury = test(net, test_loader, device, loss)
test_loss.append(test_ls)
test_acc.append(test_accury)
draw_loss_pic(train_loss, test_loss, "loss")
draw_loss_pic(train_acc, test_acc, "acc")
def test(net, test_loader, device, loss):
net.eval()
total_loss = 0.0
correct = 0
sample_num = 0
for batch_idx, (data, target) in enumerate(test_loader):
data = data.to(device)
target = target.to(device).long()
output = net(data)
ls = loss(output, target)
total_loss += ls.item()
sample_num += len(target)
max_output = output.data.max(1, keepdim=True)[1].view_as(target)
correct += (max_output == target).sum()
print('test_loss %f, test_acc: %f' % (
total_loss / sample_num, float(correct.data.item()) / sample_num))
return total_loss / sample_num, float(correct.data.item()) / sample_num
运行结果
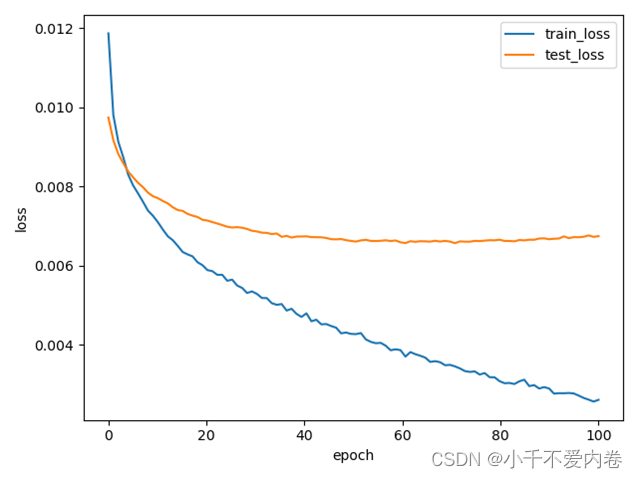
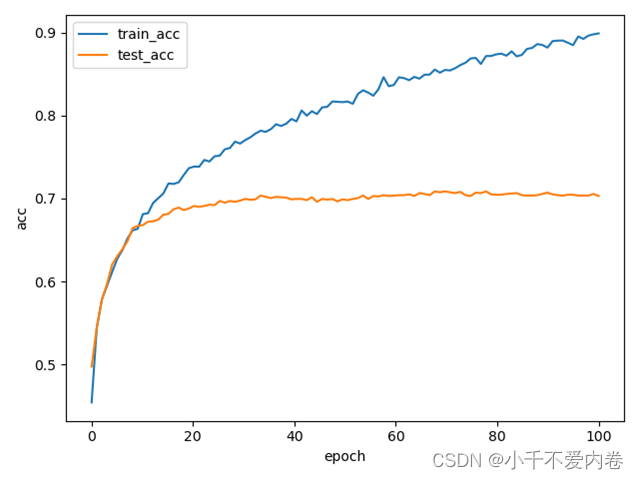
在分词器为按字进行分词、句子长度为64、batch_size为128、learning_rate为0.0001、数据清洗方式为“保留中文、逗号、句号、感叹号、问号、emoji(带中括号)”,训练模型为CNN的情况下,损失曲线和准确率曲线如下图所示:
参考
https://blog.csdn.net/cui_yonghua/article/details/121094116
https://ask.csdn.net/questions/672138?ops_request_misc&request_id&biz_id=106&utm_term=re%E5%BA%93%E5%8C%B9%E9%85%8D%E4%B8%AD%E6%8B%AC%E5%8F%B7&utm_medium=distribute.pc_search_result.none-task-ask-2~ask~sobaiduweb~default-2-672138.pc_ask&spm=1018.2226.3001.4187
https://blog.csdn.net/Littewood/article/details/123393736?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167258426316800180660412%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167258426316800180660412&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-123393736-null-null.142^v68^control,201^v4^add_ask,213^v2^t3_control2&utm_term=lambda%E7%94%A8%E6%B3%95&spm=1018.2226.3001.4449
https://blog.csdn.net/benzhujie1245com/article/details/117173090
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结