您现在的位置是:首页 >技术杂谈 >【K8s】Pod一文详解网站首页技术杂谈
【K8s】Pod一文详解
文章目录
一、Pod介绍
1、Pod结构
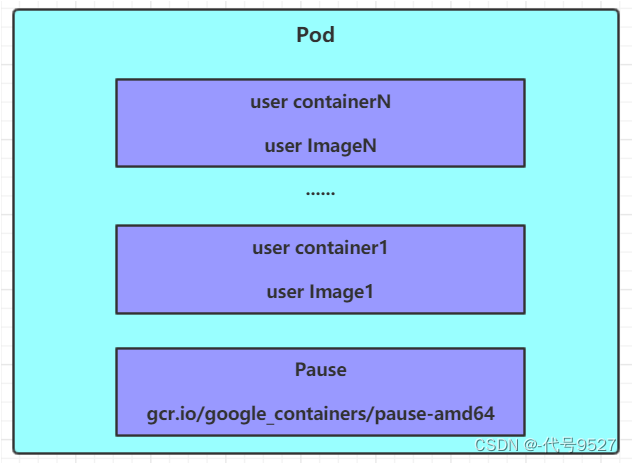
每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类:
1)用户容器:用户程序所在的容器,数量可多可少
2)根容器:Pause容器,由Kubernetes创建,这是每个Pod都会有的一个根容器,它的作用有两个:
- 可以以它为依据,评估整个Pod的健康状态
- 可以在根容器上设置Ip地址,其它容器都共享此Ip(Pod IP),以实现Pod内部的网络通信
注意上面说的是Pod内部的通讯,Pod的之间的通讯采用虚拟二层网络技术来实现,我们当前环境用的是Flannel
2、Pod的定义
下面是Pod的资源清单:(常用的)
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,资源类型,例如 Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认为"default"
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
配置项很多,可以通过指令来查看每种资源的可配置项:
# 查看某种资源可以配置的一级属性
kubectl explain 资源类型
# 查看属性的子属性
kubectl explain 资源类型.属性
# explain:解释
[root@k8s-master01 ~] kubectl explain pod
KIND: Pod
VERSION: v1
FIELDS:
apiVersion <string>
kind <string>
metadata <Object>
spec <Object>
status <Object>
[root@k8s-master01 ~] kubectl explain pod.metadata
KIND: Pod
VERSION: v1
RESOURCE: metadata <Object>
FIELDS:
annotations <map[string]string>
clusterName <string>
creationTimestamp <string>
deletionGracePeriodSeconds <integer>
deletionTimestamp <string>
finalizers <[]string>
generateName <string>
generation <integer>
labels <map[string]string>
managedFields <[]Object>
name <string>
namespace <string>
ownerReferences <[]Object>
resourceVersion <string>
selfLink <string>
uid <string>
Kubernetes中,基本所有资源的一级属性都是一样的,有五部分:
- apiVersion:版本,由kubernetes内部定义,版本号必须可以用 kubectl api-versions 查询到所有,explain查看当前
- kind:类型,由kubernetes内部定义,版本号必须可以用 kubectl api-resources 查询到所有,explain查看当前
- metadata:元数据,主要是资源
标识和说明,常用的有name、namespace、labels等- spec:描述,这是配置中最重要的一部分,里面是对各种
资源配置的详细描述- status:状态信息,里面的内容不需要定义,由kubernetes
自动生成
先重点看spec的常用子属性:
- containers <Object[ ]> : 容器列表,用于定义容器的详细信息
- nodeName: 根据nodeName的值将pod调度到指定的Node节点上,不指定则由schedule调度分配
- nodeSelector <map[]>: 根据NodeSelector中定义的信息选择将该Pod调度到包含这些label的Node 上
- hostNetwork: 是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络,多个副本pod就端口冲突了,不建议
- volumes <Object[]> :存储卷,用于定义Pod上面挂载的存储信息
- restartPolicy :重启策略,表示Pod在遇到故障的时候的处理策略
二、Pod配置:spec.containers
[root@k8s-master01 ~] kubectl explain pod.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object> # 数组,代表可以有多个容器
FIELDS:
name <string> # 容器名称
image <string> # 容器需要的镜像地址
imagePullPolicy <string> # 镜像拉取策略
command <[]string> # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args <[]string> # 容器的启动命令需要的参数列表
env <[]Object> # 容器环境变量的配置
ports <[]Object> # 容器需要暴露的端口号列表
resources <Object> # 资源限制和资源请求的设置
1、基本配置 name和image
创建个yaml文件pod-base.yaml 测试name和image:
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labels:
user: 9527
spec:
containers:
# - 即数组
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
以上即定义一个pod,包含两个容器:
- nginx:用1.17.1版本的nginx镜像创建,(nginx是一个轻量级web容器)
- busybox:用1.30版本的busybox镜像创建,(busybox是一个小巧的linux命令集合)
[root@k8s-master01 pod] kubectl apply -f pod-base.yaml
pod/pod-base created
# READY 1/2 : 表示当前Pod中有2个容器,其中1个准备就绪,1个未就绪
# RESTARTS : 重启次数,因为有1个容器故障了,Pod一直在重启试图恢复它
[root@k8s-master01 pod] kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pod-base 1/2 Running 4 95s
2、镜像拉取策略 imagePullpolicy
镜像拉取策略有三种:
- Always:总是从远程仓库拉取镜像(一直远程下载)
- IfNotPresent:本地有则使用本地镜像,本地没有则从远程仓库拉取镜像(本地有就本地 本地没远程下载)
- Never:只使用本地镜像,从不去远程仓库拉取,本地没有就报错 (一直使用本地)
关于策略默认值:
- 若镜像tag为具体版本号,则默认策略是:IfNotPresent
- 若镜像tag为latest(最终版本),则默认always
创建pod-imagepullpolicy.yaml文件做测试:
apiVersion: v1
kind: Pod
metadata:
name: pod-imagepullpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent # 用于设置镜像拉取策略
- name: busybox
image: busybox:1.30
创建pod:
[root@k8s-master01 pod] kubectl create -f pod-imagepullpolicy.yaml
pod/pod-imagepullpolicy created
# 查看Pod详情
# 此时明显可以看到nginx镜像有一步Pulling image "nginx:1.17.1"的过程
[root@k8s-master01 pod] kubectl describe pod pod-imagepullpolicy -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1
Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1"
Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1"
Normal Created 26s kubelet, node1 Created container nginx
Normal Started 25s kubelet, node1 Started container nginx
Normal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 7s (x3 over 25s) kubelet, node1 Created container busybox
Normal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
3、启动命令 command
上面busybox容器一直没有成功运行,因为busybox并不是一个程序,而是类似于一个工具类的集合,kubernetes集群启动管理后,容器中就没有进程了,它会自动关闭。解决方法就是让其一直在运行 ⇒ command
command,用于在pod中的容器
初始化完毕之后运行一个命令
创建pod-command.yaml文件做测试:
apiVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]
命令解释:
"/bin/sh","-c", 使用sh执行命令
touch /tmp/hello.txt; 创建一个/tmp/hello.txt 文件
while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done; 每隔3秒向文件中写入当前时间
[root@k8s-master01 pod] kubectl create -f pod-command.yaml
pod/pod-command created
# 此时发现两个pod都正常运行了
[root@k8s-master01 pod] kubectl get pods pod-command -n dev
NAME READY STATUS RESTARTS AGE
pod-command 2/2 Runing 0 2s
补充一个命令:进入容器,在容器内部执行命令
kubectl exec pod名称 -n 命名空间 -it -c 容器名称 /bin/sh
# 进入pod中的busybox容器,查看文件内容
[root@k8s-master01 pod] kubectl exec pod-command -n dev -it -c busybox /bin/sh
/: tail -f /tmp/hello.txt
14:44:19
14:44:22
14:44:25
最后:kubernetes中的command、args两项其实是实现覆盖Dockerfile中ENTRYPOINT的功能:
- 如果command和args均没有写,那么用Dockerfile的配置。
- 如果command写了,但args没有写,那么Dockerfile默认的配置会被忽略,执行输入的command
- 如果command没写,但args写了,那么Dockerfile中配置的ENTRYPOINT的命令会被执行,使用当前args的参数
- 如果command和args都写了,那么Dockerfile的配置被忽略,执行command并追加上args参数
4、环境变量 env
env,环境变量,通过name-value的键值对,用于在pod中的容器设置环境变量。创建pod-env.yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: pod-env
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do /bin/echo $(date +%T);sleep 60; done;"]
env: # 设置环境变量列表
- name: "username"
value: "admin"
- name: "password"
value: "123456"
创建pod:
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-env.yaml
pod/pod-env created
# 进入容器,输出环境变量
[root@k8s-master01 ~] kubectl exec pod-env -n dev -c busybox -it /bin/sh
/ echo $username
admin
/ echo $password
123456
5、端口设置 ports
容器的端口设置,先看ports下的子属性:
[root@k8s-master01 ~] kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:
name <string> # 端口名称,如果指定,必须保证name在pod中是唯一的
containerPort<integer> # 容器要监听的端口(0<x<65536)
hostPort <integer> # 容器要在主机上公开的端口,如果设置,主机上只能运行容器的一个副本(一般省略)
hostIP <string> # 要将外部端口绑定到的主机IP(一般省略)
protocol <string> # 端口协议。必须是UDP、TCP或SCTP。默认为“TCP”。
关于hostPort:创建一个二副本的deploy,两个pod的IP分别为1.1和1.2,此时使用podIP + 容器Port正常。但容器端口都是80,此时都想映射到主机端口,比如映射到主机80,就会冲突。
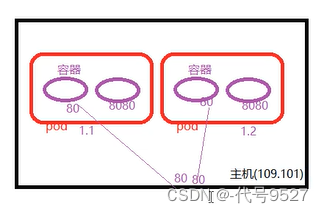
编写一个测试案例,创建pod-ports.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports: # 设置容器暴露的端口列表
- name: nginx-port
containerPort: 80
protocol: TCP
创建pod:
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-ports.yaml
pod/pod-ports created
# 查看pod
# 在下面可以明显看到配置信息
[root@k8s-master01 ~] kubectl get pod pod-ports -n dev -o yaml
......
spec:
containers:
- image: nginx:1.17.1
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: nginx-port
protocol: TCP
......
访问容器中的程序需要使用的是PodIp:containerPort
6、资源配额 resources
容器中的程序要运行,要占用一定资源,比如cpu和内存等,如果不对某个容器的资源做限制,那么它就可能吃掉大量资源,导致其它容器无法运行。因此kubernetes提供了对内存和cpu的资源进行配额的机制 ⇒ resources:
resources.limits:上限。用于限制运行时容器的最大占用资源,当容器占用资源超过limits时会被终止,并进行重启resources.requests:下限。用于设置容器需要的最小资源,如果环境资源不够,容器将无法启动
写个测试配置文件pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # 资源配额
limits: # 限制资源(上限)
cpu: "2" # CPU限制,单位是core数
memory: "10Gi" # 内存限制
requests: # 请求资源(下限)
cpu: "1" # CPU限制,单位是core数
memory: "10Mi" # 内存限制
关于单位:
- cpu:core数,可以为整数或小数
- memory: 内存大小,可以使用Gi、Mi、G、M等形式
# 运行Pod
[root@k8s-master01 ~] kubectl create -f pod-resources.yaml
pod/pod-resources created
# 查看发现pod运行正常
[root@k8s-master01 ~] kubectl get pod pod-resources -n dev
NAME READY STATUS RESTARTS AGE
pod-resources 1/1 Running 0 39s
# 接下来,停止Pod
[root@k8s-master01 ~] kubectl delete -f pod-resources.yaml
pod "pod-resources" deleted
停止pod后,更改内存最低配额为10Gi(虚拟机配置不够了)
# 编辑pod,修改resources.requests.memory的值为10Gi
[root@k8s-master01 ~] vim pod-resources.yaml
# 再次启动pod
[root@k8s-master01 ~] kubectl create -f pod-resources.yaml
pod/pod-resources created
# 查看Pod状态,发现Pod启动失败
[root@k8s-master01 ~] kubectl get pod pod-resources -n dev -o wide
NAME READY STATUS RESTARTS AGE
pod-resources 0/1 Pending 0 20s
pod状态为pending(待定、挂起):
# 查看pod详情会发现,如下提示
[root@k8s-master01 ~] kubectl describe pod pod-resources -n dev
......
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.(内存不足)
调度失败(没有节点满足这个最低配置),Insufficient memory.(内存不足)
三、Pod的生命周期
pod从创建至终止,有这几个阶段:
1)pod创建过程
2)运行初始化容器(init container)过程
3)运行主容器(main container)
- 容器启动后钩子(post start)、容器终止前钩子(pre stop)
- 容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
4)pod终止过程
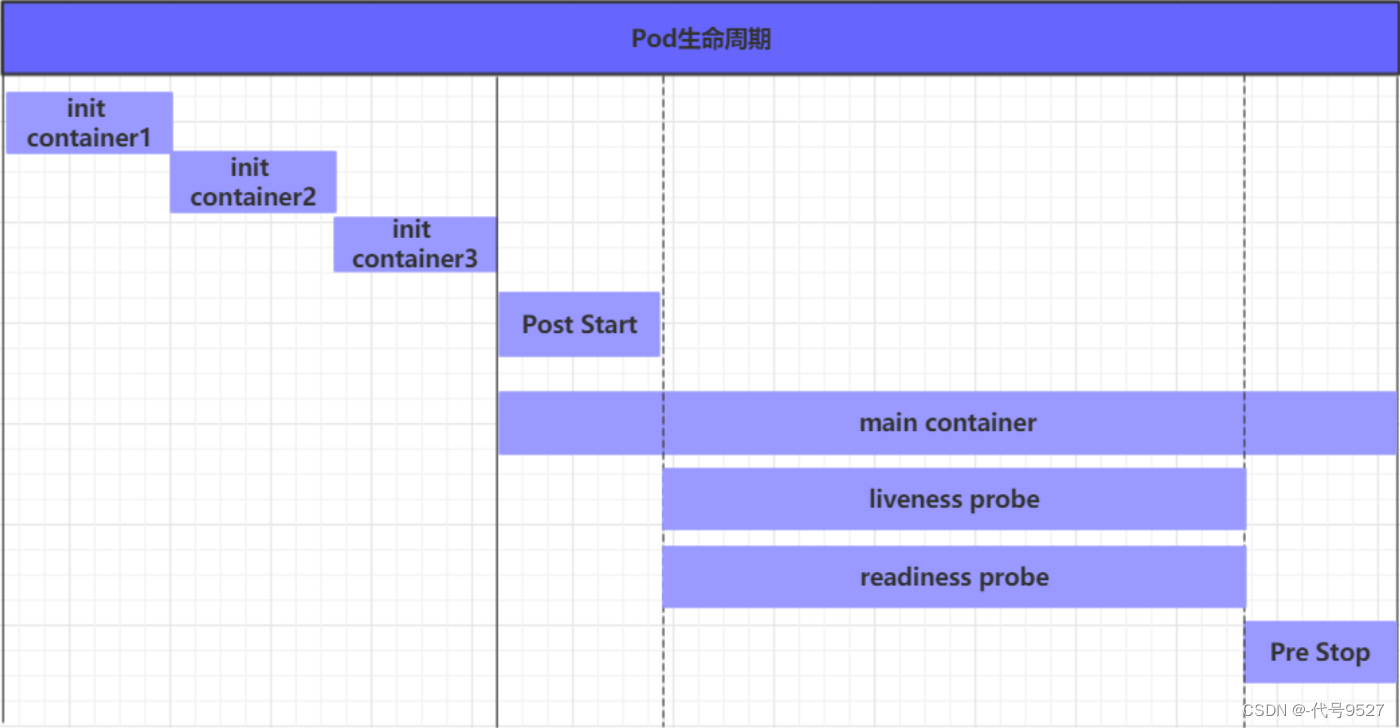
在整个生命周期中,Pod会出现5种状态(相位):
- 挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
- 运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
- 成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启
- 失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态
- 未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致
1、创建和终止
Pod创建的过程
- 用户执行kubectl指令提交pod信息给apiServer
- apiServer生成pod信息,存入etcd,并返回确认信息给客户端
- apiServer开始反馈pod的变化信息,其它组件使用watch机制来跟踪检查apiServer上的变动
- scheduler发现有新的pod要创建,开始为Pod分配主机并将结果信息更新至apiServer
- node节点上的kubelet发现有pod调度过来,尝试调用docker启动容器,并将结果回送至apiServer
- apiServer将接收到的pod状态信息存入etcd中
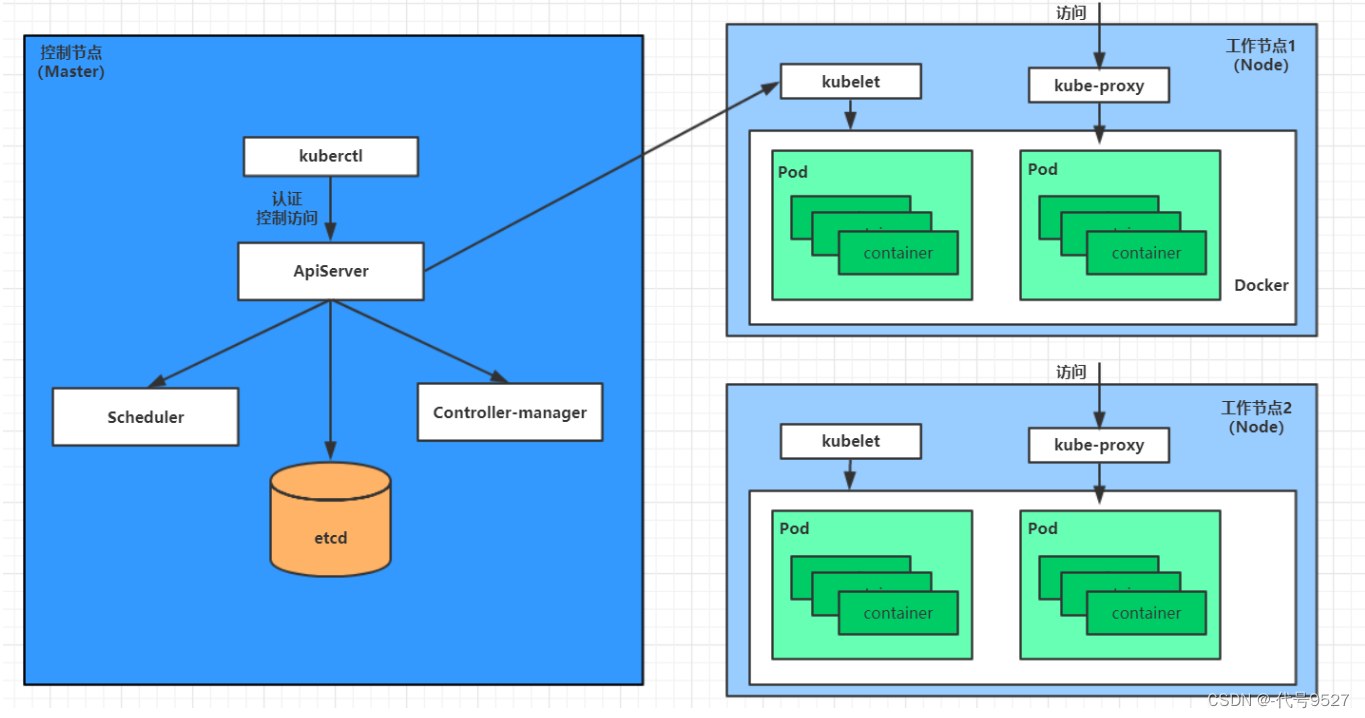
Pod终止过程
- 用户向apiServer发送删除pod命令
- apiServcer中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead
- 将pod标记为terminating状态
- kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
- 端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除
- 如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行
- pod对象中的容器进程收到停止信号
- 宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立即终止的信号
- kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见
2、初始化容器
初始化容器是在pod的主容器启动之前要运行的容器,主要做著容器启动前的前置工作。特点是:
- 初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成
- 初始化容器必须
按照定义的顺序执行,当且仅当前一个成功之后,后面的一个才能运行
初始化容器的应用场景有两个:
- 提供主容器镜像中不具备的工具程序或自定义代码
- 初始化容器要先于应用容器串行启动并运行完成,因此可用于
延后应用容器的启动直至其依赖的条件得到满足
案例:
假设要以主容器来运行nginx,但是要求在运行nginx之前先要能够连接上mysql和redis所在服务器:
# 服务器的地址假设如下:
mysql: 192.168.90.14
redis: 192.168.90.15
创建pod-initcontainer.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers: # 注意初始化容器和主容器平级
- name: test-mysql
image: busybox:1.30 # 初始化容器的镜像用busybox这个工具包
# !!!!!!
command: ['sh', '-c', 'until ping 192.168.90.14 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.90.15 -c 1 ; do echo waiting for reids...; sleep 2; done;']
上面定义了两个初始化容器,一个启动后ping MySQL,另一个ping Redis:
# 创建pod
[root@k8s-master01 ~] kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created
# 查看pod状态
# 发现pod卡在初始化容器test-mysql创建后,后面的容器不会运行
root@k8s-master01 ~] kubectl describe pod pod-initcontainer -n dev
........
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1
Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 48s kubelet, node1 Created container test-mysql
Normal Started 48s kubelet, node1 Started container test-mysql
-w动态查看pod,和watch一个意思。
# 动态查看pod
# init:0/2 即两个初始化容器都卡住了
[root@k8s-master01 ~] kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
为当前服务器新增两个ip,使得能ping通那两个IP,同时观察pod的变化:
[root@k8s-master01 ~] ifconfig ens33:1 192.168.90.14 netmask 255.255.255.0 up
[root@k8s-master01 ~] ifconfig ens33:2 192.168.90.15 netmask 255.255.255.0 up
pod状态的变化:
# 动态查看pod
[root@k8s-master01 ~] kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
pod-initcontainer 0/1 Init:1/2 0 52s
pod-initcontainer 0/1 Init:1/2 0 53s
pod-initcontainer 0/1 PodInitializing 0 89s
pod-initcontainer 1/1 Running 0 90s
# 最后runing1/1即pod启动成功,副本一个,也成功一个
3、钩子函数
直白讲就是一些特殊时机,想Java静态代码块一样,是一种时机。在这里可以执行用户自己的行为代码。钩子函数有两种:
post start:即容器创建之后执行,如果失败了会重启容器pre stop:即容器终止之前执行,执行完成之后容器将成功终止,在其执行完之前会阻塞删除容器的操作
钩子处理器支持使用下面三种方式定义动作:
- Exec命令:在容器内执行一次命令
……
lifecycle:
postStart:
exec:
command:
- cat
- /tmp/healthy
……
- TCPSocket:在当前容器尝试访问指定的socket
……
lifecycle:
postStart:
tcpSocket:
port: 8080
……
- HTTPGet:在当前容器中向某url发起http请求
……
lifecycle:
postStart:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 192.168.5.3 #主机地址
scheme: HTTP #支持的协议,http或者https
……
以exec方式为例,创建pod-hook-exec.yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # 在容器启动的时候执行一个命令,修改掉nginx的默认首页内容
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # 在容器停止之前停止nginx服务
command: ["/usr/sbin/nginx","-s","quit"]
启动pod
# 创建pod
[root@k8s-master01 ~] kubectl create -f pod-hook-exec.yaml
pod/pod-hook-exec created
# 查看pod,取podIP
[root@k8s-master01 ~] kubectl get pods pod-hook-exec -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2
# 访问pod
[root@k8s-master01 ~] curl 10.244.2.48
postStart...
4、容器探测
直白讲就是测测这个实例健康不,实例的状态不符合预期,那么kubernetes就会把该问题实例" 摘除 ",不承担业务流量。
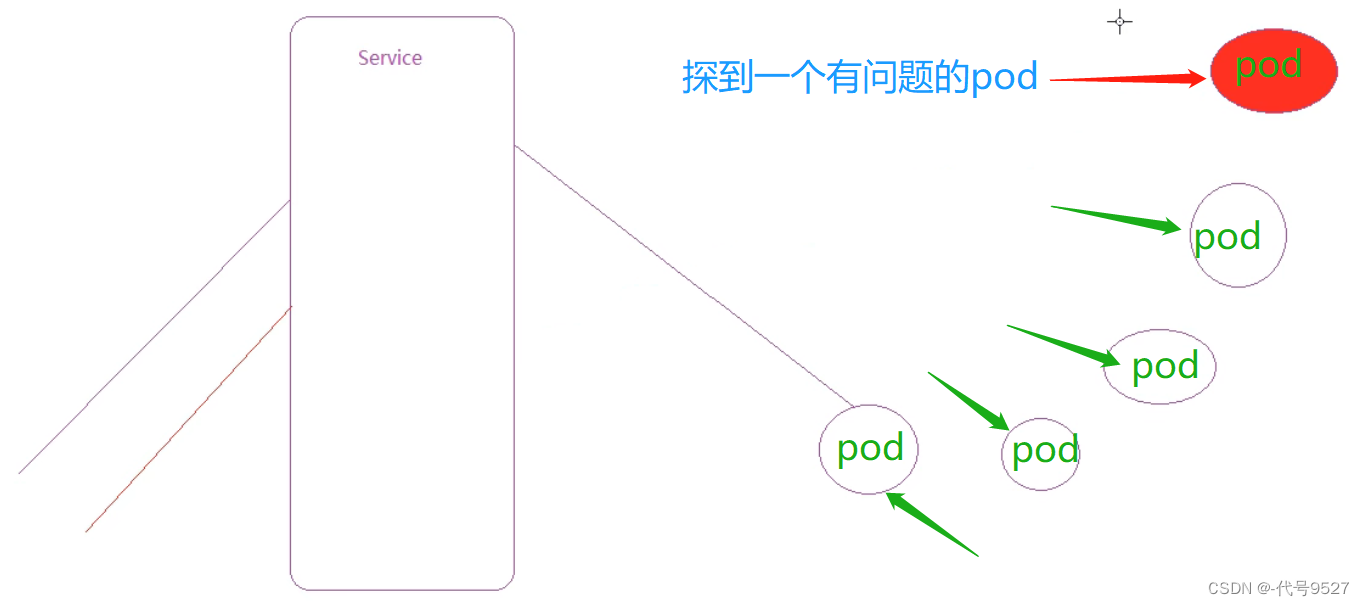
探针有两种:
liveness probes:存活性探针,用于检测应用实例当前是否处于正常运行状态,不是则k8s会重启容器readiness probes:就绪性探针,用于检测应用实例当前是否可以接收请求,不能则k8s不会转发流量
livenessProbe 决定是否重启容器,readinessProbe 决定是否将请求转发给容器
举个形象例子:
公司来了一个高级后端开发,刚来公司第一天,要熟悉代码,装环境等等。这个时候,他"存活",但不"就绪"!暂时不能给他分配工作任务。
这两种探针都有三种实现方式:
- Exec命令:在容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则不正常
……
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
……
- TCPSocket:将会尝试访问一个
用户容器的端口,如果能够建立这条连接,则认为程序正常,否则不正常
……
livenessProbe:
tcpSocket:
port: 8080
……
- HTTPGet:调用
容器内Web应用的URL,如果返回的状态码在200和399之间,则认为程序正常,否则不正常
……
livenessProbe:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 127.0.0.1 #主机地址
scheme: HTTP #支持的协议,http或者https
……
探针效果演示:
方式一:liveness+Exec
创建pod-liveness-exec.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # 执行一个查看文件的命令
创建pod,发现它一直在重启,状态CrashLoopBackOff
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created
# 查看Pod详情
[root@k8s-master01 ~] kubectl describe pods pod-liveness-exec -n dev
......
Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx
Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx
Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted
Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory
# 观察上面的信息就会发现nginx容器启动之后就进行了健康检查
# 检查失败之后,容器被kill掉,然后尝试进行重启(这是重启策略的作用,后面讲解)
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~] kubectl get pods pod-liveness-exec -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个存在的文件,cat指令执行成功,则健康检查通过,pod开始running
方式二:TCPSocket + liveness
创建pod-liveness-tcpsocket.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # 尝试访问用户容器中的8080端口,而用户容器我只开启了80端口
创建pod,查看效果:
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created
# 查看Pod详情
[root@k8s-master01 ~] kubectl describe pods pod-liveness-tcpsocket -n dev
......
Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2
Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machine
Normal Created <invalid> kubelet, node2 Created container nginx
Normal Started <invalid> kubelet, node2 Started container nginx
Warning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused
# 观察上面的信息,发现尝试访问8080端口,但是失败了
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~] kubectl get pods pod-liveness-tcpsocket -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个可以访问的端口,比如80,再试,结果就正常了......
注意TCPSocket是尝试访问一个用户容器的端口:

方式三:HTTPGet + liveness
创建pod-liveness-httpget.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet: # 其实就是访问http://127.0.0.1:80/hello
scheme: HTTP #支持的协议,http或者https
port: 80 #端口号
path: /hello #URI地址
创建pod查看效果:
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created
# 查看Pod详情
[root@k8s-master01 ~] kubectl describe pod pod-liveness-httpget -n dev
.......
Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine
Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx
Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx
Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted
# 观察上面信息,尝试访问路径,但是未找到,出现404错误
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~] kubectl get pod pod-liveness-httpget -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 1/1 Running 5 3m17s
# 当然接下来,可以修改成一个可以访问的路径path,比如/,再试,结果就正常了......
最后,关于容器探针的其他子属性,如:容器启动后多久执行一次探测
[root@k8s-master01 ~] kubectl explain pod.spec.containers.livenessProbe
FIELDS:
exec <Object>
tcpSocket <Object>
httpGet <Object>
initialDelaySeconds <integer> # 容器启动后等待多少秒执行第一次探测
timeoutSeconds <integer> # 探测超时时间。默认1秒,最小1秒
periodSeconds <integer> # 执行探测的频率。默认是10秒,最小1秒
failureThreshold <integer> # 连续探测失败多少次才被认定为失败。默认是3。最小值是1
successThreshold <integer> # 连续探测成功多少次才被认定为成功。默认是1
举例:
[root@k8s-master01 ~]# more pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /9527
initialDelaySeconds: 30 # 容器启动后30s开始探测
timeoutSeconds: 5 # 探测超时时间为5s
35秒后:

5、重启策略
一旦容器探测出现了问题,kubernetes就会对容器所在的Pod进行重启,怎么重启由重启策略决定:
- Always :容器失效时,自动重启该容器,这也是默认值
- OnFailure : 容器终止运行且退出码不为0时重启
- Never : 不论状态为何,都不重启该容器
注意:
重启策略适用于pod对象中的所有容器,首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长以此为10s、20s、40s、80s、160s和300s,300s是最大延迟时长,到300以后不再加时长。阶梯增加重启的前摇,不然本来就跑不起来,你频繁重启只会浪费系统资源。
做验证:
apiVersion: v1
kind: Pod
metadata:
name: pod-restartpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # 设置重启策略为Never
运行pod:
# 创建Pod
[root@k8s-master01 ~] kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created
# 查看Pod详情,发现nginx容器失败
[root@k8s-master01 ~] kubectl describe pods pod-restartpolicy -n dev
......
Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 15s kubelet, node1 Container nginx failed liveness probe
# 多等一会,再观察pod的重启次数,发现一直是0,并未重启
[root@k8s-master01 ~] kubectl get pods pod-restartpolicy -n dev
NAME READY STATUS RESTARTS AGE
pod-restartpolicy 0/1 Running 0 5min42s
四、Pod调度
在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,当然也可进行人为干预,这和调度方式有关:
- 自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出
- 定向调度:NodeName、NodeSelector
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
- 污点(容忍)调度:Taints、Toleration
1、定向调度
就是直接在pod的yaml文件中声明一下去哪个节点(nodeName),或者去有哪个标签的节点(nodeSelector)。
这里直接跳过Scheduler的调度逻辑,强制调度,即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
# 创建一个pod-nodename.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 指定调度到node1节点上
# 集群中节点名称可以kubectl get nodes
创建pod,查看效果:
#创建Pod
[root@k8s-master01 ~] kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@k8s-master01 ~] kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 1/1 Running 0 56s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeName的值为node3(并没有node3节点)
[root@k8s-master01 ~] kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@k8s-master01 ~] vim pod-nodename.yaml
[root@k8s-master01 ~] kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在node3节点,所以pod无法正常运行
[root@k8s-master01 ~] kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 0/1 Pending 0 6s <none> node3 ......
接下来测试NodeSelector,即将pod调度到添加了指定标签的node节点上。它是通过kubernetes的label-selector机制实现的,也就是说,在pod创建之前,会由scheduler使用MatchNodeSelector调度策略进行label匹配,找出目标node,然后将pod调度到目标节点,该匹配规则是强制约束。
先为node节点添加标签
[root@k8s-master01 ~] kubectl label nodes node1 nodeenv=pro
node/node2 labeled
[root@k8s-master01 ~] kubectl label nodes node2 nodeenv=test
node/node2 labeled
创建一个pod-nodeselector.yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # 指定调度到具有nodeenv=pro标签的节点上
创建pod,查看效果:
#创建Pod
[root@k8s-master01 ~] kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@k8s-master01 ~] kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeselector 1/1 Running 0 47s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeSelector的值为nodeenv: xxxx(不存在打有此标签的节点)
[root@k8s-master01 ~] kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@k8s-master01 ~] vim pod-nodeselector.yaml
[root@k8s-master01 ~] kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#再次查看,发现pod无法正常运行,Node的值为none
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none>
# 查看详情,发现node selector匹配失败的提示
[root@k8s-master01 ~] kubectl describe pods pod-nodeselector -n dev
.......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
2、亲和性调度
形象的说,就是想去哪些节点、想去有哪个pod的节点,不想去有哪个pod的节点。
就像分座位,想去哪几个班、想去有某位同学的班级、不去有哪位同学的班级。
和定向调度的强制性相比,亲和性调度更温柔,使得调度更灵活了。亲和性Affinity主要分三类:
- nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题 ==>
想去哪几个班 - podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题 ==>
想去有某位同学的班级 - podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题 ==>
不去有哪位同学的班级
关于亲和性和反亲和性的使用场景:
亲和性:
如果两个pod需要频繁交互,如mysql和tomcat,那就有必要利用亲和性让两个应用的尽可能的靠近(同一节点),这样可以减少因网络通信而带来的性能损耗。
反亲和性:
当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,这样可以提高服务的高可用性。(别一个节点挂了,某个服务的副本pod被一锅端了。)
2.1 node亲和性调度
查看NodeAffinity的配置项:
[root@k8s-master01 ~]kubectl explain pod.spec.affinity.nodeAffinity
---------
requiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可以调度成功,相当于硬限制
nodeSelectorTerms 节点选择列表
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operat or 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
---------
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当于软限制 (倾向)
preference 一个节点选择器项,与相应的权重相关联
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
关于关系符的使用:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"
创建一个pod-nodeaffinity-required.yaml文件来举例看看:
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
nodeAffinity: #设置node亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
nodeSelectorTerms:
- matchExpressions: # 匹配key为nodeenv,值在["xxx","yyy"]中的标签的节点
- key: nodeenv
operator: In
values: ["xxx","yyy"]
启动pod,查看效果:
# 创建pod
[root@k8s-master01 ~] kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 查看pod状态 (运行失败)
[root@k8s-master01 ~] kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ......
# 查看Pod的详情,pending
# 发现调度失败,提示node选择失败
[root@k8s-master01 ~] kubectl describe pod pod-nodeaffinity-required -n dev
......
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
由于我只设置了硬限制,所以调度失败,修改一下配置文件:
#停止pod
[root@k8s-master01 ~] kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted
# 修改文件,将values: ["xxx","yyy"]------> ["pro","yyy"]
[root@k8s-master01 ~] vim pod-nodeaffinity-required.yaml
# 再次启动
[root@k8s-master01 ~] kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 此时查看,发现调度成功,已经将pod调度到了node1上
[root@k8s-master01 ~] kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 11s 10.244.1.89 node1 ......
接下来测试使用节点亲和性的软限制,创建pod-nodeaffinity-preferred.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-preferred
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
nodeAffinity: #设置node亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软限制
- weight: 1
preference:
matchExpressions: # 优先匹配env的值在["xxx","yyy"]中的标签(当前集群没有),匹配不到可考虑其他
- key: nodeenv
operator: In
values: ["xxx","yyy"]
创建pod查看:
# 创建pod
[root@k8s-master01 ~] kubectl create -f pod-nodeaffinity-preferred.yaml
pod/pod-nodeaffinity-preferred created
# 查看pod状态 (运行成功)
[root@k8s-master01 ~] kubectl get pod pod-nodeaffinity-preferred -n dev
NAME READY STATUS RESTARTS AGE
pod-nodeaffinity-preferred 1/1 Running 0 40s
几个注意点:
NodeAffinity规则设置的注意事项:
1 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能运行在指定的Node上
2 如果nodeAffinity指定了多个nodeSelectorTerms,那么只需要其中一个能够匹配成功即可
3 如果一个nodeSelectorTerms中有多个matchExpressions ,则一个节点必须满足所有的才能匹配成功
4 如果一个pod所在的Node在Pod运行期间其标签发生了改变,不再符合该Pod的节点亲和性需求,则系统将忽略此变化,不会二次调度
2.2 pod亲和性调度
让新创建的Pod跟参照pod在一个区域的功能,去有某同学的那个班级。
kubectl explain pod.spec.affinity.podAffinity
----------
requiredDuringSchedulingIgnoredDuringExecution 硬限制
namespaces 指定参照pod的namespace
topologyKey 指定调度作用域
labelSelector 标签选择器
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist.
matchLabels 指多个matchExpressions映射的内容
----------
preferredDuringSchedulingIgnoredDuringExecution 软限制
podAffinityTerm 选项
namespaces
topologyKey
labelSelector
matchExpressions
key 键
values 值
operator
matchLabels
weight 倾向权重,在范围1-100
topologyKey指定调度作用域,作用域即范围,调度到和参照pod同一节点、同一网段还是同样的操作系统里。(和你同学同一个班级?同一张课桌?同一个学校?)
topologyKey取值:
kubernetes.io/hostname,那就是以Node节点为区分范围
beta.kubernetes.io/os,则以Node节点的操作系统类型来区分
举个例子说明pod亲和性,先创建一个参照pod,并定向调度到node1
# pod-podaffinity-target.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: dev
labels:
podenv: pro #设置标签
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 将目标pod名确指定到node1上
# 启动目标pod
[root@k8s-master01 ~] kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# 查看pod状况
[root@k8s-master01 ~] kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s
创建待调度的pod,配置文件pod-podaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: podenv
operator: In
values: ["xxx","yyy"]
# 如果找到这种pod了,那就把这个pod调度到和匹配成功的pod的同一几点上
topologyKey: kubernetes.io/hostname
上面配置表达的意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上,硬限制。
# 启动pod
[root@k8s-master01 ~] kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 查看pod状态,发现未运行
[root@k8s-master01 ~] kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s
# 查看详细信息
[root@k8s-master01 ~] kubectl describe pods pod-podaffinity-required -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.
调度失败了,稍微修改一下匹配的label:
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"]
# 意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@k8s-master01 ~] vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果
[root@k8s-master01 ~] kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" de leted
[root@k8s-master01 ~] kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 发现此时Pod运行正常
[root@k8s-master01 ~] kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>
2.3 pod反亲和性调度
PodAntiAffinity主要实现以运行的Pod为参照,让新创建的Pod跟参照pod不在一个区域中的功能。(不和谁一个班)
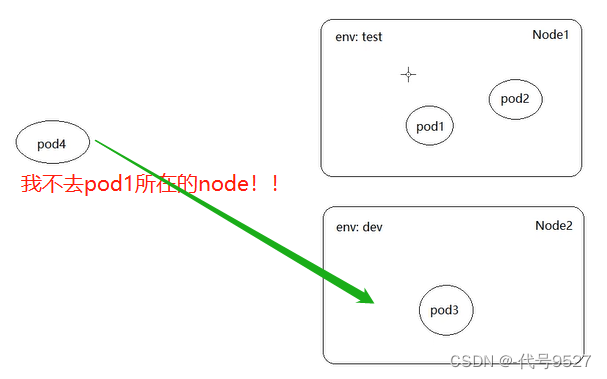
举个例子说明,继续使用pod亲和性中建的pod:
[root@k8s-master01 ~] kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE LABELS
pod-podaffinity-required 1/1 Running 0 3m29s 10.244.1.38 node1 <none>
pod-podaffinity-target 1/1 Running 0 9m25s 10.244.1.37 node1 podenv=pro
创建pod-podantiaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podantiaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAntiAffinity: #设置pod反亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配podenv的值在["pro"]中的标签
- key: podenv
operator: In
values: ["pro"]
topologyKey: kubernetes.io/hostname
上面配置表达的意思是:新Pod必须要与拥有标签nodeenv=pro的pod不在同一Node上:
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created
# 查看pod
# 发现调度到了node2上
[root@k8s-master01 ~] kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96 node2 ..
3、污点和容忍调度
前面的两种调度都是在pod的角度,来说pod要去哪儿,不要去哪儿。接下来站在node的角度,来说允许哪些pod过来,不允许哪些pod过来。(前面是学生要转校到哪个学校,现在是校长贴出告示说明不要哪些学生)
3.1 污点(Taints)
Node被设置上污点之后就和Pod之间存在了一种相斥的关系,进而拒绝Pod调度进来,甚至可以将已经存在的Pod驱逐出去。
污点的格式为:key=value:effect, key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
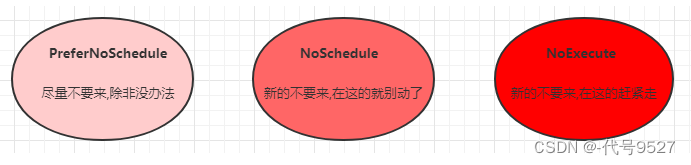
- PreferNoSchedule:kubernetes将尽量避免把Pod调度到具有该污点的Node上,除非没有其他节点可调度
- NoSchedule:kubernetes将不会把Pod调度到具有该污点的Node上,但不会影响当前Node上已存在的Pod
- NoExecute:kubernetes将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱离
设置和去除污点:
# 设置污点
kubectl taint nodes node1 key=value:effect
# 去除污点
kubectl taint nodes node1 key:effect-
# 去除所有污点
kubectl taint nodes node1 key-
接下来举例子演示效果,先停掉node2节点(关机),只留master和node1,先看PreferNoSchedule:
# 为node1设置污点(PreferNoSchedule)
[root@k8s-master01 ~] kubectl taint nodes node1 tag=code9527:PreferNoSchedule
# 创建pod1
[root@k8s-master01 ~] kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
仅有一个工作节点,且该节点设置了污点PreferNoSchedule,但仍调度成功。
再看NoSchedule:
# 为node1设置污点(取消PreferNoSchedule,设置NoSchedule)
[root@k8s-master01 ~] kubectl taint nodes node1 tag:PreferNoSchedule-
[root@k8s-master01 ~] kubectl taint nodes node1 tag=code9527:NoSchedule
创建pod,发现pending,且调度失败:
# 创建pod2
[root@k8s-master01 ~] kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
taint2-544694789-6zmlf 0/1 Pending 0 21s <none> <none>
再看NoExecute:
# 为node1设置污点(取消NoSchedule,设置NoExecute)
[root@k8s-master01 ~] kubectl taint nodes node1 tag:NoSchedule-
[root@k8s-master01 ~] kubectl taint nodes node1 tag=code9527:NoExecute
可以看到已有的pod也被驱逐了:
# 创建pod3
[root@k8s-master01 ~] kubectl run taint3 --image=nginx:1.17.1 -n dev
# IP全为<none>
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
taint1-7665f7fd85-htkmp 0/1 Pending 0 35s <none> <none> <none>
taint2-544694789-bn7wb 0/1 Pending 0 35s <none> <none> <none>
taint3-6d78dbd749-tktkq 0/1 Pending 0 6s <none> <none> <none>
小提示:
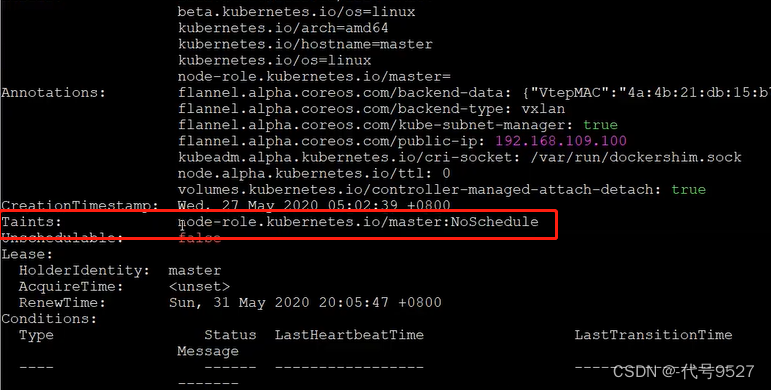
使用kubeadm搭建的集群,默认就会给master节点添加一个污点标记,所以pod就不会调度到master节点上.
kubectl describe node master
# 查看一下
3.2 容忍(Toleration)
在node上添加污点用于拒绝pod调度上来,但是如果就是想将一个pod调度到一个有污点的node上去,这时就要使用到容忍。
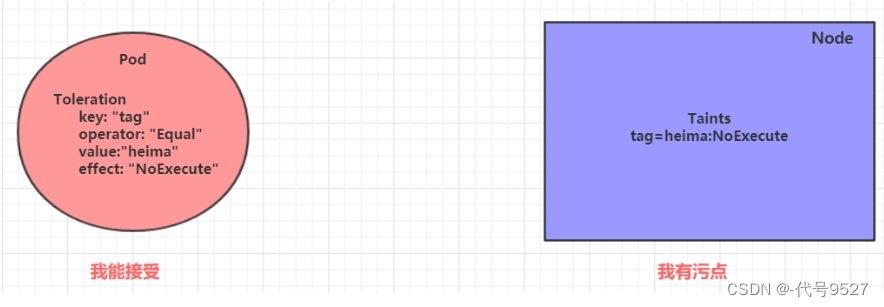
污点就是拒绝,容忍就是忽略,Node通过污点拒绝pod调度上去,Pod通过容忍忽略拒绝
形象的说,污点就是,相亲时,你告诉相亲对象,你这人脾气大,对方说:没事,我能接收。于是你们在一起了。
创建pod-toleration.yaml做演示:
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
tolerations: # 添加容忍
- key: "tag" # 要容忍的污点的key
operator: "Equal" # 操作符
value: "code9527" # 容忍的污点的value
effect: "NoExecute" # 添加容忍的规则,这里必须和标记的污点规则相同
上一小节,已经在node1节点上打上了NoExecute的污点,此时pod是调度不上去的。启动pod看一下加了容忍以后的效果:
# 添加容忍之前的pod
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 0/1 Pending 0 3s <none> <none> <none>
# 添加容忍之后的pod
[root@k8s-master01 ~] kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 1/1 Running 0 3s 10.244.1.62 node1 <none>
最后看一下容忍的所有子属性:
[root@k8s-master01 ~] kubectl explain pod.spec.tolerations
......
FIELDS:
key # 对应着要容忍的污点的键,空意味着匹配所有的键
value # 对应着要容忍的污点的值
operator # key-value的运算符,支持Equal和Exists(默认),Exists是对键进行操作
effect # 对应污点的effect,空意味着匹配所有影响
tolerationSeconds # 容忍时间,
# 当effect为NoExecute时生效
# 表示pod在Node上的停留时间
注意最后这个tolerationSeconds容忍时间,NoExecute时生效,NoExcute本来就禁止往上调度。tolerationSeconds就是忍多久以后跑路。
到此,Pod篇结束,下来是各种Pod控制器!!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结