您现在的位置是:首页 >技术杂谈 >FlinkTableAPI与SQL编程实战网站首页技术杂谈
FlinkTableAPI与SQL编程实战
FlinkTableAPI与SQL编程实战
接下来我们一起来进入到FlinkSQL的编码实战当中,通过代码来实现FlinkSQL的编码开发
1、Flink TableAPI实践
1.1、创建Maven工程 并添加以jar包坐标依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.14.3</flink.version>
<hadoop.version>3.1.4</hadoop.version>
<hbase.version>2.2.7</hbase.version>
<hive.version>3.1.2</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.15</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.15</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>commons-math3</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>hadoop-hdfs</artifactId>
<groupId>org.apache.hadoop</groupId>
</exclusion>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
-->
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr-runtime</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<!-- put your configurations here -->
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.10</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、FlinkTable API操作
FlinkTable API提供了很多的connector用于对接各种数据源,例如CSV、json、HDFS数据、HBase数据、Kafka数据、JDBC数据、Hive数据等,可以将各个系统当中的数据,直接接入到Flink当中来进行处理,然后处理完成的数据,也可以写入到各个地方去
我们接下来就一起来看一下关于各种输入数据源的使用
2.1、读取集合数据,并注册表实现数据查询
读取集合当中的数据,然后注册表,并实现数据的查询操作
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.row;
public class FlinkTableStandardStructure {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2、创建source table: 1)读取外部表;2)从Table API或者SQL查询结果创建表
Table projTable = tEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.DECIMAL(10, 2)),
DataTypes.FIELD("name", DataTypes.STRING())
),
row(1, "zhangsan"),
row(2L, "lisi")
).select($("id"), $("name"));
//注册表到catalog(可选的)
tEnv.createTemporaryView("sourceTable", projTable);
//3、创建sink table
final Schema schema = Schema.newBuilder()
.column("id", DataTypes.DECIMAL(10, 2))
.column("name", DataTypes.STRING())
.build();
//https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/print/
tEnv.createTemporaryTable("sinkTable", TableDescriptor.forConnector("print")
.schema(schema)
.build());
//4、Table API执行查询(可以执行多次查询,中间表可以注册到catalog也可以不注册)
Table resultTable = tEnv.from("sourceTable").select($("id"), $("name"));
//如果不注册sourceTable,可以这么写
//Table resultTable = projTable.select($("id"), $("name"));
//5、输出(包括执行,不需要单独在调用tEnv.execute("job"))
resultTable.executeInsert("sinkTable");
}
}
2.2、Flink Table内置的Connector
Flink 的 Table API & SQL通过Connectors连接外部系统,并执⾏批/流⽅式的读写操作。Connectors提供了丰富的外部系统连接器,根据source和sink的类型,它们⽀持不同的格式,例如 CSV、Avro、Parquet 或 ORC。注意:如果作为sink⼤家还要注意⽀持的输出模式(Append/Retract/Upsert)
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/overview/
| 名称 | 支持版本 | source | sink |
|---|---|---|---|
| Filesystem | 有界和⽆界scan、 lookup均⽀持 | Streaming Sink, Batch Sink | |
| Kafka | 0.10+ | ⽆界scan | Streaming Sink, Batch Sink |
| JDBC | 有界scan和lookup | Streaming Sink, Batch Sink | |
| HBase | 1.4.x、2.2.x | 有界scan和lookup | Streaming Sink, Batch Sink |
| Hive | 1.0、1.1、1.2、2.0、2.1、 2.2、2.3、3.1 | ⽆界scan、有界scan 和lookup | Streaming Sink, Batch Sink |
| Elasticsearch | 6.x & 7.x | 不支持 | Streaming sink,Batch Sink |
表Format
数据以各种格式存储在不同的存储中(CSV、Avro、Parquet 或 ORC等),Flink定义了Format来⽀持读取不同格式的数据
| Formats | Support Connectors |
|---|---|
| CSV | Apache Kafka, Upsert Kafka, Filesystem |
| JSON | Apache Kafka, Upsert Kafka, Filesystem,Elasticsearch |
| Apache Avro | Apache Kafka, Upsert Kafka, Filesystem, |
| Apache Parquet | Filesystem |
| Apache ORC | Filesystem |
| Debezium | Apache Kafka, |
| Canal | Apache Kafka, |
| Maxwell | Apache Kafka, |
| Raw | Apache Kafka, |
2.3、通过内置的connector实现JSON数据读取,并将数据写入到HDFS上成为CSV数据格式
通过Flink的内置Connector实现读取JSON数据
通过TableAPI实现读取CSV文件内容,然后将数据写入到HDFS上面去
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class FlinkJson2HDFSCsv {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE json_table (
" +
" id Integer,
" +
" name STRING,
" +
" email STRING,
" +
" date_time STRING" +
") WITH (
" +
" 'connector'='filesystem',
" +
" 'path'='input/userbase.json',
" +
" 'format'='json'
" +
")";
String sink_sql = "CREATE TABLE sink_hdfs (
" +
" id Integer,
" +
" name STRING,
" +
" email STRING,
" +
" date_time STRING" +
") WITH (
" +
" 'connector' = 'filesystem',
" +
" 'path' = 'hdfs://bigdata01:8020/output_csv/userbase.csv' ,
" +
" 'format' = 'csv'
" +
")";
String insert_SQL = "insert into sink_hdfs select id,name ,date_time,email from json_table ";
//注册表
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(insert_SQL);
}
}
2.4、通过内置的Connector实现读取HDFS上的csv格式的数据写入HBase
通过Flink的内置Connector实现读取json数据,然后将读取的数据写入到HBase里面去
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/filesystem/
进入HBase的shell客户端,然后创建表
[hadoop@bigdata01 ~]$ cd /opt/install/hbase-2.2.7/
[hadoop@bigdata01 hbase-2.2.7]$ bin/hbase shell
hbase(main):009:0> create 'hTable','f1'
通过TableAPI实现读取CSV文件内容,然后将数据写入到HBase当中去
import org.apache.flink.table.api.*;
public class FlinkWithHDFSCSV2HBase {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE source_hdfs (
" +
" id Integer,
" +
" name STRING,
" +
" date_time STRING,
" +
" email STRING" +
") WITH (
" +
" 'connector' = 'filesystem',
" +
" 'path' = 'hdfs://bigdata01:8020//output_csv/userbase.csv/' ,
" +
" 'format' = 'csv'
" +
")";
String sink_sql = "CREATE TABLE sink_table (
" +
" rowkey Integer,
" +
" f1 ROW<name STRING,email STRING,date_time STRING > ,
" +
" PRIMARY KEY (rowkey) NOT ENFORCED
" +
") WITH (
" +
" 'connector' = 'hbase-2.2',
" +
" 'table-name' = 'hTable',
" +
" 'zookeeper.quorum' = 'bigdata01:2181,bigdata02:2181,bigdata03:2181'
" +
") ";
String execute_sql = "insert into sink_table select id as rowkey,ROW(name,email,date_time) from source_hdfs ";
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(execute_sql);
}
}
2.6、通过内置的connector实现读取HBase上的数据,写入到Kafka当中去
通过Flink的内置Connector实现读取HBase数据,然后将数据写入到Kafka当中去
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/hbase/
创建HBase表,并添加以下数据内容
准备HBase数据集
hbase(main):003:0> create 'opt_log','f1'
#插入数据集
put 'opt_log','1','f1:username','郑剃'
put 'opt_log','1','f1:email','kyzqcd0686@vjikq.tng'
put 'opt_log','1','f1:date_time','2022-10-04 08:01:48'
put 'opt_log','2','f1:username','王曙介'
put 'opt_log','2','f1:email','axvcbj7vbo@ecyi1.4gw'
put 'opt_log','2','f1:date_time','2022-10-04 08:04:39'
put 'opt_log','3','f1:username','赖溯姆'
put 'opt_log','3','f1:email','ew1qu5sunz@caxtg.vtn'
put 'opt_log','3','f1:date_time','2022-10-04 08:00:19'
创建Kafak的topic,并打开消费者进行消费
#查看topic列表
cd /opt/install/kafka_2.12-2.6.3/
bin/kafka-topics.sh --zookeeper bigdata01:9092,bigdata02:9092,bigdata03:9092 --list
#创建topic
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_output --replication-factor 3 --partitions 3
#打开消费者
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_output
通过TableAPI实现读取HBase文件内容,然后将数据写入到Kafka
import org.apache.flink.table.api.*;
public class FlinkTableWithHBase2Kafka {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_table = "CREATE TABLE hTable (
" +
" rowkey STRING,
" +
" f1 ROW<username STRING,email STRING,date_time String> ,
" +
" PRIMARY KEY (rowkey) NOT ENFORCED
" +
") WITH (
" +
" 'connector' = 'hbase-2.2',
" +
" 'table-name' = 'opt_log',
" +
" 'zookeeper.quorum' = 'bigdata01:2181,bigdata02:2181,bigdata03:2181'
" +
") ";
String sink_table = "CREATE TABLE KafkaTable (
" +
" `username` STRING,
" +
" `email` STRING,
" +
" `date_time` STRING
" +
") WITH (
" +
" 'connector' = 'kafka',
" +
" 'topic' = 'user_output',
" +
" 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
" +
" 'format' = 'json'
" +
")";
String insert_sql = "insert into KafkaTable select username,email,date_time from hTable";
tableEnvironment.executeSql(source_table);
tableEnvironment.executeSql(sink_table);
tableEnvironment.executeSql(insert_sql);
}
}
2.7、通过内置的connector实现读取Kafka上的数据,然后将数据写入到mysql
通过Flink的内置Connector实现读取Kafka数据
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
创建Kafka的topic,并添加以下数据内容
#创建topic
bin/kafka-topics.sh --zookeeper bigdata01:2181,bigdata02:2181,bigdata03:2181 --create --topic usr_opt --replication-factor 3 --partitions 3
#打开生产者
bin/kafka-console-producer.sh --broker-list bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic usr_opt
测试数据
{"date_time":"2022-10-04 08:01:48","email":"kyzqcd0686@vjikq.tng","id":0,"name":"郑剃"}
{"date_time":"2022-10-04 08:06:31","email":"bvkqwbmgwi@lh80q.4ln","id":1,"name":"闾丘喜造"}
{"date_time":"2022-10-04 08:04:39","email":"axvcbj7vbo@ecyi1.4gw","id":2,"name":"王曙介"}
{"date_time":"2022-10-04 08:00:19","email":"ew1qu5sunz@caxtg.vtn","id":3,"name":"赖溯姆"}
Kafka数据生产与消费
#查看topic列表
cd /opt/install/kafka_2.12-2.6.3/
bin/kafka-topics.sh --zookeeper bigdata01:9092,bigdata02:9092,bigdata03:9092 --list
#创建topic
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_input --replication-factor 3 --partitions 3
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_output --replication-factor 3 --partitions 3
#打开消费者
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_output
#打开生产者
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_input
#输入数据内容如下
{"user":"Cidy","visit_url":"./home","op_time":"2022-02-03 12:00:00"}
{"user":"Lili","visit_url":"./index","op_time":"2022-02-03 13:30:50"}
{"user":"Tom","visit_url":"./detail","op_time":"2022-02-04 13:35:30"}
定义mysql表
CREATE DATABASE /*!32312 IF NOT EXISTS*/`user_log` /*!40100 DEFAULT CHARACTER SET latin1 */;
USE `user_log`;
/*Table structure for table `clickcount` */
DROP TABLE IF EXISTS `clickcount`;
CREATE TABLE `clickcount` (
`username` varchar(64) DEFAULT NULL,
`result` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `clickcount` */
/*Table structure for table `clicklog` */
DROP TABLE IF EXISTS `clicklog`;
CREATE TABLE `clicklog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL,
`date_time` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
/*Data for the table `clicklog` */
insert into `clicklog`(`id`,`username`,`email`,`date_time`) values (1,'zhangsan','kyzqcd0686@vjikq.tng','2022-10-04 08:01:48'),(2,'lisi','bvkqwbmgwi@lh80q.4ln','2022-10-04 08:06:31');
通过TableAPI实现读取Kafka数据内容,然后将数据写入到mysql里面去
import org.apache.flink.table.api.*;
public class FlinkTableWithKafka2MySQL {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE KafkaTable (
" +
" id Integer,
" +
" name STRING,
" +
" email STRING,
" +
" date_time STRING" +
") WITH (
" +
" 'connector' = 'kafka',
" +
" 'topic' = 'usr_opt',
" +
" 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',
" +
" 'properties.group.id' = 'user_opt_group',
" +
" 'scan.startup.mode' = 'earliest-offset',
" +
" 'format' = 'json',
" +
" 'json.fail-on-missing-field' = 'false',
" +
" 'json.ignore-parse-errors' = 'true'
" +
")";
String sink_sql = "CREATE TABLE mysql_sink (
" +
" id Integer,
" +
" name STRING,
" +
" email STRING,
" +
" date_time STRING" +
") WITH (
" +
" 'connector' = 'jdbc',
" +
" 'url' = 'jdbc:mysql://localhost:3306/user_log?characterEncoding=utf-8&serverTimezone=GMT%2B8',
" +
" 'driver' = 'com.mysql.jdbc.Driver',
" +
" 'table-name' = 'clicklog',
" +
" 'username' = 'root',
" +
" 'password' = '123456'
" +
")";
String execute_sql = "insert into mysql_sink select id,name,email,date_time from KafkaTable";
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(execute_sql);
}
}
2.8、通过内置的connector实现读取Hive数据以及写入Hive数据
通过Flink的内置Connector实现读取hive数据
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/hive/overview/
修改hive-site.xml的配置属性,添加以下配置
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.52.120:9083</value>
</property>
将hive-site.xml存放到项目路径当中
启动hive的metastore服务,并创建hive数据库以及hive数据库表
#启动hive的metastore服务以及hiveserver2服务
[hadoop@bigdata03 apache-hive-3.1.2]$ cd /opt/install/apache-hive-3.1.2/
[hadoop@bigdata03 apache-hive-3.1.2]$ bin/hive --service metastore
[hadoop@bigdata03 apache-hive-3.1.2]$ bin/hive --service hiveserver2
#创建本地文件
[hadoop@bigdata03 install]$ cd /opt/install/
[hadoop@bigdata03 install]$ vim userbase.csv
#文件内容如下
0,郑剃,"2022-10-04 08:01:48",kyzqcd0686@vjikq.tng
1,闾丘喜造,"2022-10-04 08:06:31",bvkqwbmgwi@lh80q.4ln
2,王曙介,"2022-10-04 08:04:39",axvcbj7vbo@ecyi1.4gw
3,赖溯姆,"2022-10-04 08:00:19",ew1qu5sunz@caxtg.vtn
4,钱泼奎,"2022-10-04 08:04:51",50xdhnfppw@vwreu.kxk
5,尉迟亏,"2022-10-04 08:02:25",h8ist2s54k@lorkp.79s
6,贾盏,"2022-10-04 08:05:22",hnzfdmnjgo@rsiq9.syx
7,蔡辟,"2022-10-04 08:03:53",apjlg5pyuo@lhs6l.oj4
8,蔡矛,"2022-10-04 08:05:35",cpqofnn5xd@7iknh.qc5
9,赖妖炬,"2022-10-04 08:05:03",0wg3nfjdv9@fomvu.2kb
10,毛溜孝,"2022-10-04 08:06:37",1kkaib5i4e@ecvb8.6cs
准备Hive数据
#创建test数据库
create database if not exists test location "/user/hive/warehouse/test";
use test;
#创建Hive表
drop table userbase;
create table if not exists userbase
(id int,
name string,
date_time string,
email string
)
row format delimited fields terminated by ","
stored as textfile;
#加载click.txt至Hive表
load data local inpath '/opt/install/userbase.csv' into table userbase;
#查询Hive
select * from userbase;
#创建hive表数据保存目的地表
create table user_count (username string,count_result int) row format delimited fields terminated by ' ';
通过TableAPI实现读取Hive数据内容
import org.apache.flink.table.api.*;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
public class FlinkTableWithHive {
public static void main(String[] args) {
//1.创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2.创建HiveCatalog
String name = "myCataLog";
String defaultDatabase = "test";
String hiveConfDir = "input/hiveconf/";
tEnv.loadModule(name,new HiveModule("3.1.2"));
tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
HiveCatalog hive = new HiveCatalog(name,defaultDatabase,hiveConfDir);
//3.注册catalog
tEnv.registerCatalog(name,hive);
//4.设置当前会话使用的catalog和database
tEnv.useCatalog(name);
tEnv.useDatabase(defaultDatabase);
tEnv.executeSql("insert into user_count select username,count(1) as count_result from clicklog group by username");
}
}
3、Flink的Time类型
-
对于流式数据处理,最大的特点是数据上具有时间的属性特征。
-
Flink根据时间产生的位置不同,可以将时间区分为三种时间类型:
-
Event Time(事件发生时间)
- 事件产生的时间,它通常由事件中的时间戳描述
-
Ingestion time(事件接入时间)
- 事件进入Flink程序的时间
-
Processing Time(事件处理时间)
- 事件被处理时当前系统的时间
-
-
Flink在流处理程序中支持不同的时间类型。
3.1 EventTime
- 1、事件生成时的时间,在进入Flink之前就已经存在,可以从event的字段中抽取
- 2、必须指定
watermarks(水位线)的生成方式 - 3、优势:确定性,乱序、延时、或者数据重放等情况,都能给出正确的结果
- 4、弱点:处理无序事件时性能和延迟受到影响
3.2 IngestionTime
- 1、事件进入flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间。
- 2、不需要指定watermarks的生成方式(自动生成)
- 3、弱点:不能处理无序事件和延迟数据
3.3 ProcessingTime
-
1、执行操作的机器的当前系统时间(每个算子都不一样)
-
2、不需要流和机器之间的协调
-
3、优势:最佳的性能和最低的延迟
-
4、弱点:不确定性 ,容易受到各种因素影响(event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
3.4 三种时间的综合比较
-
性能
- ProcessingTime > IngestionTime> EventTime
-
延迟
- ProcessingTime < IngestionTime< EventTime
-
确定性
- EventTime > IngestionTime> ProcessingTime
3.5、消息乱序问题
实时系统中,由于各种原因造成的延时,造成某些消息发到flink的时间延时于事件产生的时间。如果基于event time构建window,但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。

4、Flink 的WaterMark机制
Watermarks(水位线)机制
是event time处理进度的标志
表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据 )
基于watermark来进行窗口触发计算的判断
1 什么是乱序
-
当数据是一条一条规规矩矩的按照流程发送,经过MQ传输,Flink接受后处理,这个时候,就是有序的处理。

-
当出现异常,有些数据延迟了,排在后面的数据出现在前面了,这就出现了乱序。

-
思考:我们应该以哪个时间类型来判定乱序呢?
2 WaterMark的概念
- WaterMark(水位线)主要用来处理乱序事件,而正确地处理乱序事件,通常用WaterMark机制结合窗口来实现。
- 从流处理原始设备产生事件,到Flink程序读取数据,再到Flink多个算子处理数据,在这个过程中由于网络或者系统等外部因素影响下,导致数据是乱序的,为了保证计算结果的正确性,需要等待数据,这就带来了计算的延迟。
- 对于延迟太久的数据,不能无限期的等下去,所以必须有一个机制,来保证特定的时间后一定会触发窗口进行计算,这个触发机制就是WaterMark。
3 Watermark的原理
-
在 Flink 的窗口处理过程中,如果确定全部数据到达,就可以对 Window 的所有数据做窗口计算操作(如汇总、分组等),如果数据没有全部到达,则继续等待该窗口中的数据全部到达才开始处理。

- 乱序会导致各种统计结果有问题。比如一个Time Window本应该计算1、2、3,结果3迟到了,那么这个窗口统计就丢失数据了,结果就不准确了。
-
这种情况下就需要用到水位线(WaterMark)机制,它能够衡量数据处理进度(表达数据到达的完整性),保证事件数据(全部)到达Flink系统,或者在乱序及延迟到达时,也能够像预期一样计算出正确并且连续的结果。
-
当任何 Event 进入到 Flink 系统时,会根据当前最大事件时间产生 Watermarks 时间戳。
-
那么 Flink 是怎么计算 WaterMark 的值呢?
- Watermark = 进入 Flink 的最大的事件产生时间(maxEventTime)— 指定的乱序时间(t)
-
那么有 Watermark 的 Window 是怎么触发窗口函数的呢?
(1) watermark >= window的结束时间
(2) 该窗口必须有数据 注意:[window_start_time,window_end_time) 中有数据存在,前闭后开区间
4 生活场景理解WaterMark
-
经常户外徒步的同学应该知道徒步小队通常会有一个正两副领队,队首队尾各一名副队,队伍前面的由一名副领队开路,队伍后面由一名副领队收队,正队长在队伍中穿插协调。

-
队尾的领队叫后队领队,它的职责是要保证所有队员都在前面,也就是说后领队是整个队伍的队尾。当收队的时候,看见队尾的领队,那就说明整个队伍都已经完全到达了。
-
这个
WaterMark就相当于给整个数据流设置一个后领队。但是窗口不知道具体要来多少数据,所有只能设置一个时间上的限制,以此来推测当前窗口最后一条数据是否已经到达。假设窗口大小为10秒,watermark为进入 Flink 的最大的事件产生时间(maxEventTime)— 指定的乱序时间(t) -
接下来它会进行以下处理
- 每来一条数据,取当前窗口内所有数据最大的事件发生时间
- 用最大的事件发生时间扣减指定乱序时间
- 看看是否符合触发窗口关闭计算的条件
- 如果不符合,则继续进数据
- 如果符合,则关闭窗口开始计算
-
你看,多像户外徒步
-
每来一个人,就问问他出发的时是多少号,然后确认所有已到队员的最大号码
-
用最大的号码对比一下后领队的号码
-
如果比后领队的号码小,就不收队,如果号码大于等于后领队的号码,就收队!!!
5 Watermark 使用的三种情况
-
(1)顺序数据流中的watermark
-
在某些情况下,基于Event Time的数据流是有序的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。
如果数据元素的事件时间是有序的,Watermark 时间戳会随着数据元素的事件时间按顺序生成,此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置乱序时间了,那么 t 就是 0。 所以 watermark= maxEventtime-0 = maxEventtime),也就是理想状态下的水位线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推, 下一个 Window 也是一样。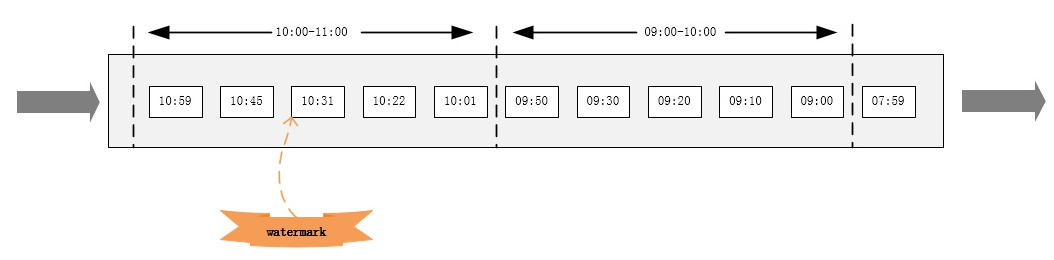
-
-
(2)乱序数据流中的watermark
-
现实情况下数据元素往往并不是按照其产生顺序接入到 Flink 系统中进行处理,而频繁出现乱序或迟到的情况,这种情况就需要使用 Watermarks 来应对。
比如下图,假设窗口大小为1小时,延迟时间设为10分钟。明显,数据09:38已经迟到,但它依然会被正确计算,只有当有数据时间大于10:10的数据到达之后(即对应的watermark大于等于10:10-10min) 09:00~10:00的窗口才会执行计算。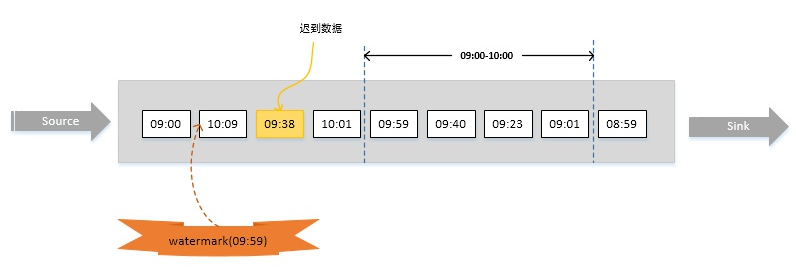
-
-
(3)并行数据流中的 Watermark
-
对应并行度大于1的source task,它每个独立的subtask都会生成各自的watermark。这些watermark会随着流数据一起分发到下游算子,并覆盖掉之前的watermark。当有多个watermark同时到达下游算子的时候,flink会选择较小的watermark进行更新。当一个task的watermark大于窗口结束时间时,就会立马触发窗口操作。
在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel 中最小的 Watermark。
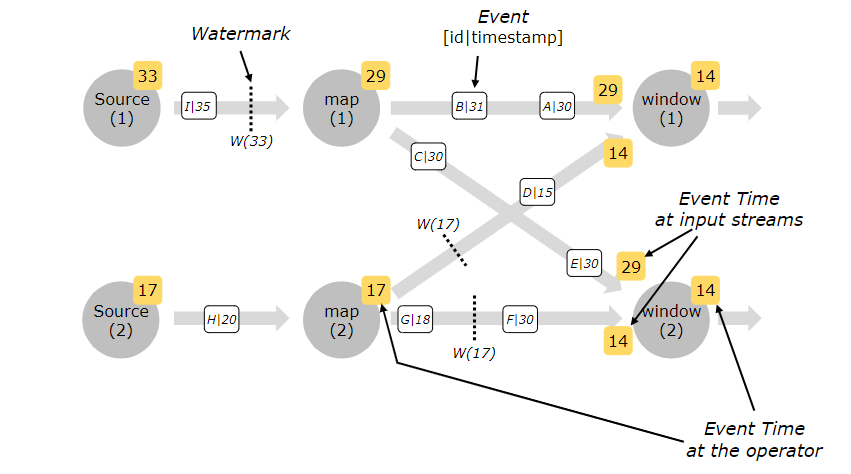
-
6、使用EventTime来作为基准时间处理本地json数据
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
public class FlinkSQLEvent {
public static void main(String[] args) {
//1.创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2.创建source table,这种方式会自动注册表
tEnv.executeSql("CREATE TABLE userbase ("+
" id Integer,"+
" name STRING,"+
" email STRING,"+
" date_time TIMESTAMP(3),"+
" WATERMARK FOR date_time AS date_time - INTERVAL '10' SECOND"+
") WITH ("+
" 'connector' = 'filesystem',"+
" 'path' = 'input/userbase.json',"+
" 'format' = 'json'"+
")");
//3.Flink SQL 查询
Table resultTable = tEnv.sqlQuery("select * from userbase");
resultTable.printSchema();
//4.执行Flink SQL
resultTable.execute().print();
}
}
5、Flink当中的窗口操作
有了时间属性,我们就可以配合窗⼝来完成各种业务的计算,Flink Table API/SQL提供了丰富的窗⼝操作。
Flink DataStream已经支持Group Windows
Flink Table API/SQL还支持Over Windows
5.1 window概念
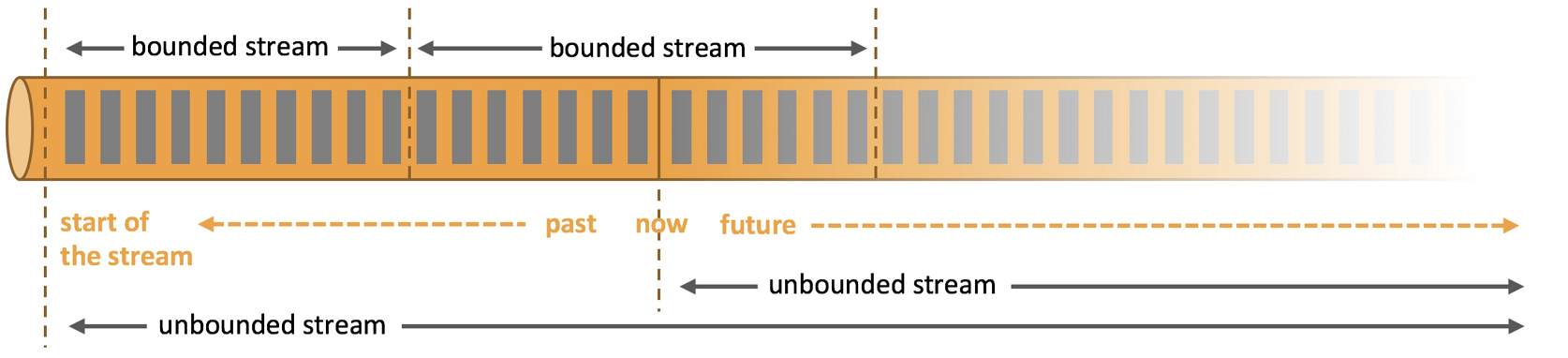
- streaming 流式计算是一种被设计用于处理无限数据集的处理引擎,无限数据集是指一种随时间不断增长的数据,而 window 是一种切割无限数据为有限块进行处理的手段。
- window 就是将无界流切割成有界流的一种方式,它会将流分发到有限大小的桶(bucket)中进行分析。
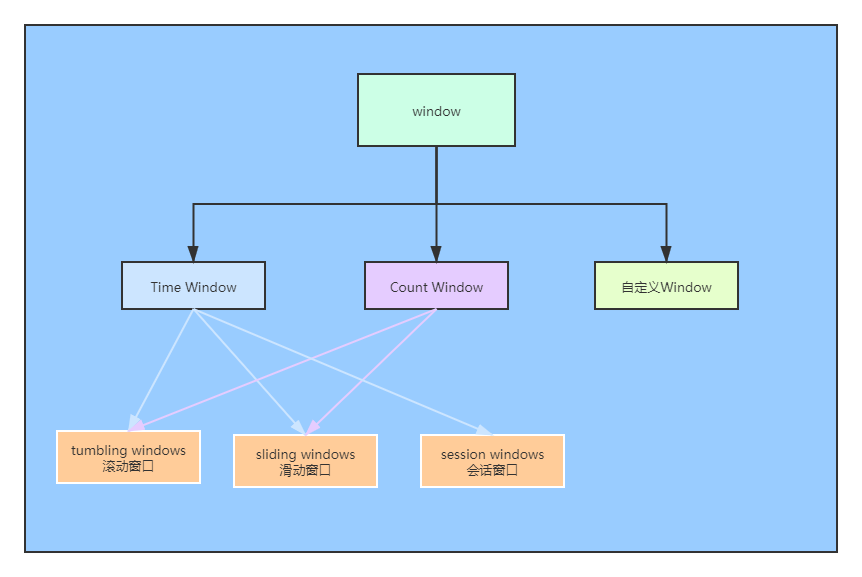
5.2 window的类型
- Window 可以分成两类:
- TimeWindow
- 计时窗口: 按照一定时间生成 Window(比如:每10秒)
- CountWindow
- 计数窗口:按照指定的数据量生成一个 Window,与时间无关(比如:每100个元素)
- TimeWindow

- 窗口类型汇总:
5.3 TimeWindow 分类
- 对于 TimeWindow,可以根据窗口实现原理的不同分成三类:
- 滚动窗口(TumblingWindow)
- 滑动窗口(Sliding Window)
- 会话窗口(Session Window)
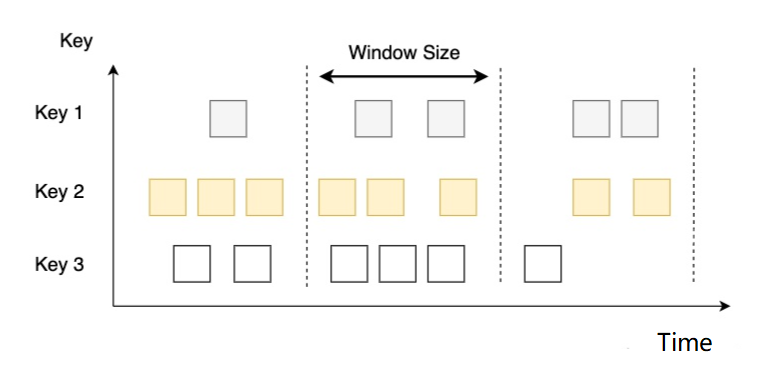
5.3.1 滚动窗口(Tumbling Windows)
-
概念
- 将数据依据固定的窗口长度对数据进行切片
-
特点
- 时间对齐,窗口长度固定,没有重叠
-
例如
- 如果你指定了一个 5 分钟大小的滚动窗口,窗口的创建如下图所示

-
适用场景
- 适合做 BI 统计等(做每个时间段的聚合计算)
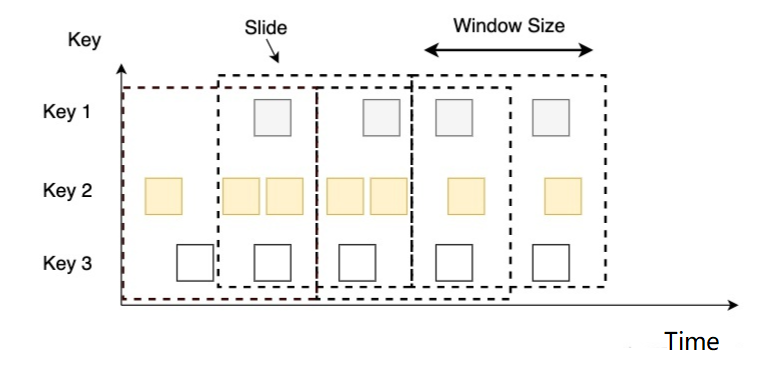
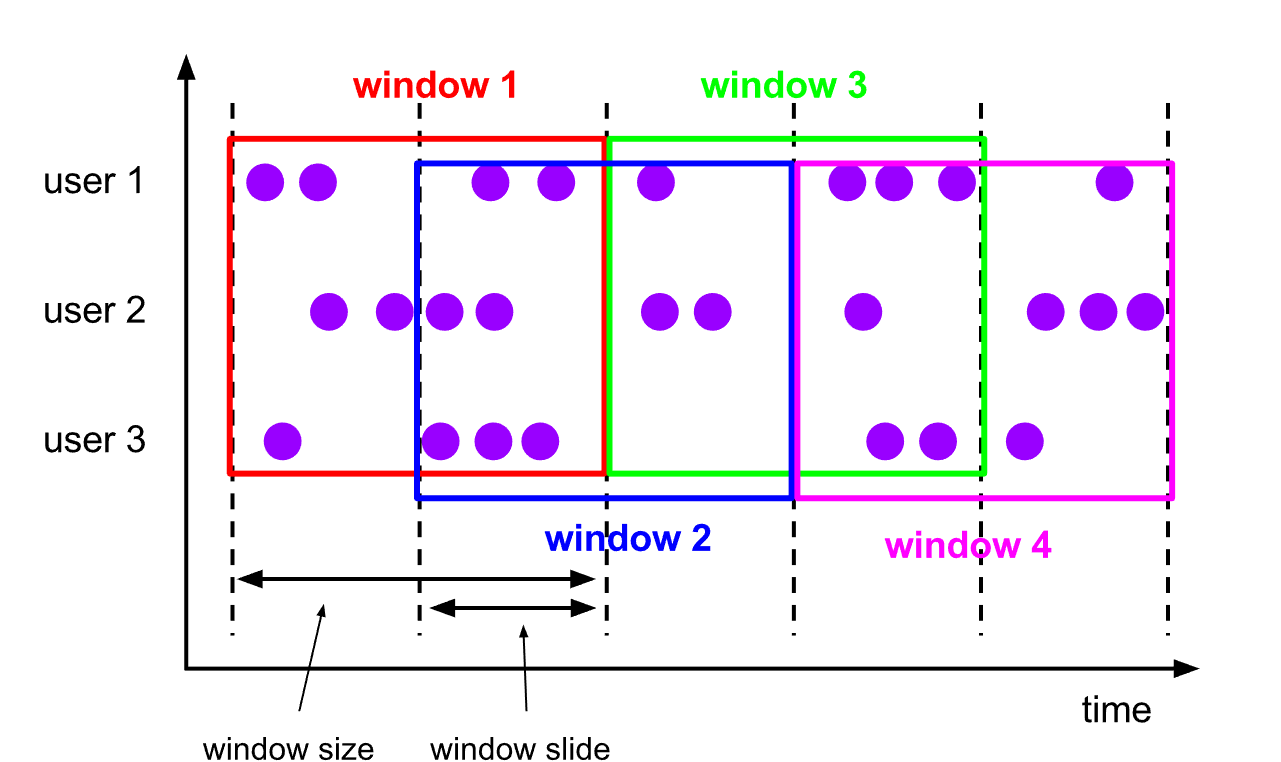
5.3.2 滑动窗口(Sliding Windows)
-
概念
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
-
特点
- 时间对齐,窗口长度固定,可以有重叠
-
例如
-
你有 10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上个 10 分钟产生的数据,如下图所示
-
-
适用场景
- 对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是否要报警)
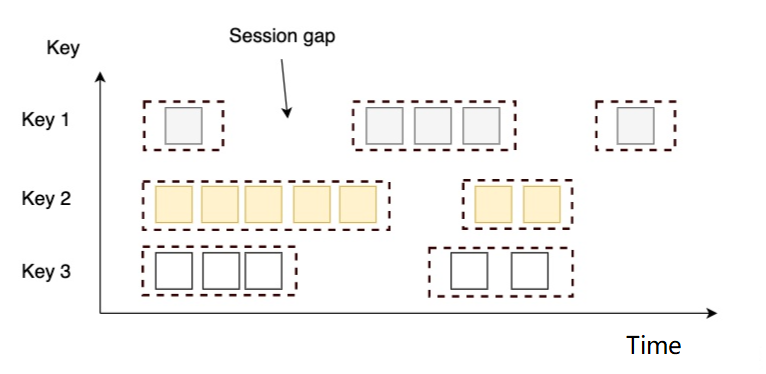
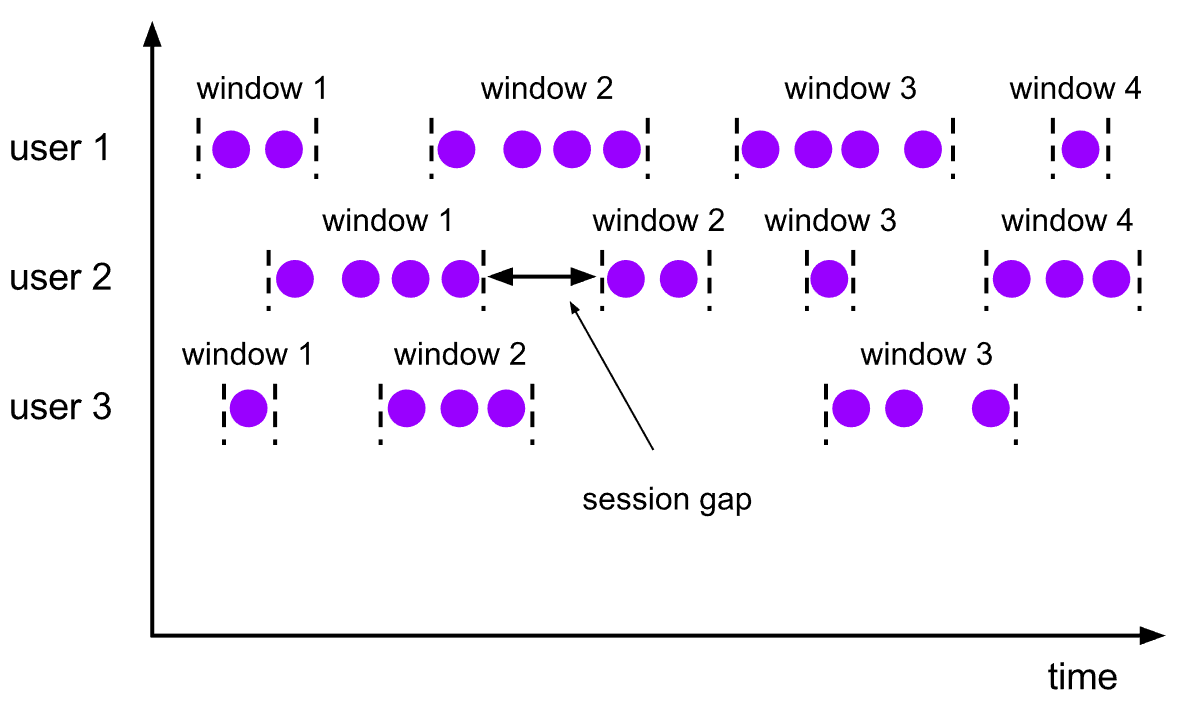
5.3.3 会话窗口(Session Windows)
-
概念
- 由一系列事件组合一个指定时间长度的
timeout间隙组成,类似于 web 应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
- 由一系列事件组合一个指定时间长度的
-
特点
- 窗口大小是由数据本身决定,它没有固定的开始和结束时间。
- 会话窗口根据Session gap间隙切分不同的窗口,当一个窗口在大于Session gap间隙的时间内没有接收到新数据时,窗口将关闭
-
例如
-
设置的时间gap是6秒,那么,当相邻的记录相差>=6秒时,则触发窗口
-
-
适用场景
- 每个用户在一个独立的session中平均页面访问时长, session 和 session 的间隔时间是15分钟 。
5.3.4、group windows
所谓Group Windows (分组窗口),就是把event按照时间或者计数 分成若干个组,然后在对每个组执行窗口函数,Group Window 从键控来说,分为键控window 和 非键控window,按照窗口事件分配逻辑又分为若干类型。
键控分window和非键控window
按照是否先根据指定的键(字段/属性)分组再基于时间/计数构建的Window,可以把Group Window分为【键控 Window】【⾮键控Window】
有时把键控窗⼝跟翻滚窗⼝/滑动窗⼝搞混淆,其实是事物的不同层⾯:
| 概念 | 定义 | |
|---|---|---|
| 键控window | 先根据指定的键(字段/属性)分组,再基于时间/计数构建的Window(双重分组) | |
| ⾮键控Window | 不根据指定的键(字段/属性)分组,直接基于时间/计数构建的Window |
注意:窗⼝也是⼀种分组
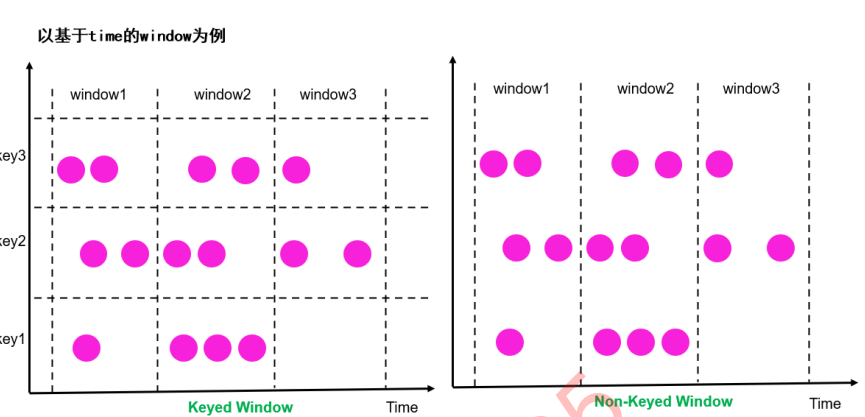
5.3.5、按照event分配逻辑分类
时间窗⼝:根据时间对数据流进⾏行行分组切⽚片
翻滚时间窗⼝:Tumbling Time Window
滑动时间窗⼝:Sliding Time Window
会话窗⼝:Session Window
计数窗⼝口:根据元素个数对数据流进⾏行行分组切⽚片
翻滚计数窗:Tumbling CountWindow
滑动计数窗:Sliding CountWindow
注意:时间窗⼝口[start,end),左闭右开
5.4、flinkSQL当中窗口的使用
Flink SQL中通过Group Windows函数来定义分组窗⼝

特别注意:FlinkSQL只⽀持基于时间的分组窗⼝,对于批处理time_attr必须是TIMESTAMP类型的
另外还有⼀些辅助函数,可以在select⼦句中⽤来查询 Group Window 的开始和结束时间戳,以及时间属性 (start,end,rowtime,proctime)。
| 辅助函数 | 说明 |
|---|---|
| TUMBLE_START(time_attr, interval) HOP_START(time_attr, interval, interval) SESSION_START(time_attr, interval) | 返回窗⼝的开始时间戳(start),即窗⼝的下边界时间戳 |
| TUMBLE_END(time_attr, interval) HOP_END(time_attr, interval, interval) SESSION_END(time_attr, interval) | 返回窗⼝的结束时间戳(end),即窗⼝的上边界之外紧挨着的不包含在 本窗⼝的时间戳注意:结束时间戳【不能】⽤作【后续】基于时间的操作中的⾏时间属 性,例如group window或者over window的聚合操作 |
| TUMBLE_ROWTIME(time_attr, interval) HOP_ROWTIME(time_attr, interval, interval) SESSION_ROWTIME(time_attr, interval) | 返回窗⼝的上边界时间戳,以rowtime形式返回 注意:结果是rowtime时间属性,【可以】⽤做后续基于时间的操作,例 如group window 或者 over window的聚合操作等 |
| TUMBLE_PROCTIME(time_attr, interval) HOP_PROCTIME(time_attr, interval, interval) SESSION_PROCTIME(time_attr, interval) |
注意:必须使⽤与 GROUP BY ⼦句中的窗⼝函数完全相同的参数来调⽤辅助函数。
基本语法如下
CREATE TABLE Orders (
user BIGINT,
product STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '1' MINUTE
) WITH (...);
SELECT
user,
TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,//参数必须跟下⾯GROUP BY⼦句中的窗⼝
函数参数⼀致
SUM(amount) FROM Orders
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
user
5.4.1、基于Event-time的滚动窗口实现
现有数据内容如下:表示不同用户购买的商品记录,以下数据都是product_id为1的商品,被不同的用户在不同的时间下单,所花费的金额如下,使用flinkSQL当中的滚动窗口来计算每隔2秒钟的金额的最大值,或者平均值,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
定义javaBean对象如下
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UserProduct {
private Integer product_id;
private String buyer_name;
private Long date_time;
private Double price;
}
启动socket服务,然后将以上数据写入到socket里面去,通过FlinkSQL程序实现数据的处理
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLTumbEvtWindowTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
//4.流转换为动态表
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),$("buyer_name"),$("price"),$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price),"+
"TUMBLE_START(date_time,INTERVAL '5' second) as winstart "+
"from "+table+" GROUP BY product_id,TUMBLE(date_time,INTERVAL '5' second) ");
//6.执行Flink
resultTable.execute().print();
}
}
5.4.2、基于Event-time的滑动窗口实现
现有数据内容如下:表示不同用户购买的商品记录,以下数据都是product_id为1的商品,被不同的用户在不同的时间下单,所花费的金额如下,使用flinkSQL当中的滑动窗口来计算每隔2秒钟的金额的最大值,或者平均值,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
启动socket服务,然后将以上数据写入到socket里面去,通过FlinkSQL程序实现数据的处理
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLSlideWindowEvtTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Schema schema = Schema.newBuilder()
.column("product_id", "bigint")
.column("buyer_name", "String")
.column("date_time", "Long")
.column("price", "double")
.build();
Table table = tEnv.fromDataStream(userProductDataStream, $("product_id"),$("buyer_name"),$("price"),$("date_time").rowtime());
Table resulTable = tEnv.sqlQuery("select product_id,max(price), HOP_START(date_time ,INTERVAL '2' second,INTERVAL '4' second ) " +
"as winstart from " + table +
" group by product_id, HOP(date_time, INTERVAL '2' second, INTERVAL '4' second) ");
resulTable.execute().print();
}
}
5.4.3、基于Event_time的会话窗口实现
现有数据内容如下:表示不同用户购买的商品记录,以下数据都是product_id为1的商品,被不同的用户在不同的时间下单,所花费的金额如下,使用flinkSQL当中的会话窗口来计算每隔2秒钟的金额的最大值,或者平均值,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
启动socket服务,然后将以上数据写入到socket里面去,通过FlinkSQL程序实现数据的处理
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLSessionWindowEvtTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
Table resulTable = tEnv.sqlQuery("select product_id,max(price),SESSION_START( date_time,INTERVAL '5' second ) as winstart from " + table + " group by product_id, SESSION(date_time , INTERVAL '5' second )");
resulTable.execute().print();
}
}
5.4.4、Over窗口使用基于时间前置指定值
Over window 聚合是标准 SQL 中已有的(Over 子句),可以在查询的 SELECT 子句中定义。Over window 聚合,会针对每个输入行,计算相邻行范围内的聚合。Over windows使用.window(w:overwindows*)子句定义,并在 select()方法中通过别名来引用。例子:
val table = input.window([w: OverWindow] as 'w).select('a, 'b.sum over 'w, 'c.min over 'w)
Table API 提供了 Over 类,来配置 Over 窗口的属性。可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义 Over windows。
无界的 over window 是使用常量指定的。也就是说,时间间隔要指定 UNBOUNDED_RANGE,或者行计数间隔要指定 UNBOUNDED_ROW。而有界的 over window 是用间隔的大小指定的。
// 无界的事件时间
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)//无界的处理时间
over window (时间字段"proctime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)// 无界的事件时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)//无界的处理时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
使用Over窗口按event-time排序有界向==前5s开窗==,求取最大金额以及平均金额值
数据格式如下
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLOverWinEvTimeRange {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price) OVER w AS max_price,"+
"avg(price) OVER w AS avg_price "+
"from "+table+" WINDOW w AS (
" +
" PARTITION BY product_id
" +
" ORDER BY date_time
" +
" RANGE BETWEEN INTERVAL '5' second PRECEDING AND CURRENT ROW)
");
//6.执行Flink
resultTable.execute().print();
}
}
5.4.4、Over窗口使用基于数据条数前置
Over window 聚合是标准 SQL 中已有的(Over 子句),可以在查询的 SELECT 子句中定义。Over window 聚合,会针对每个输入行,计算相邻行范围内的聚合。Over windows使用.window(w:overwindows*)子句定义,并在 select()方法中通过别名来引用。例子:
val table = input.window([w: OverWindow] as 'w).select('a, 'b.sum over 'w, 'c.min over 'w)
Table API 提供了 Over 类,来配置 Over 窗口的属性。可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义 Over windows。
无界的 over window 是使用常量指定的。也就是说,时间间隔要指定 UNBOUNDED_RANGE,或者行计数间隔要指定 UNBOUNDED_ROW。而有界的 over window 是用间隔的大小指定的。
// 无界的事件时间
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)//无界的处理时间
over window (时间字段"proctime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)// 无界的事件时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)//无界的处理时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
使用Over窗口按event-time排序有界向==前3条数据==,求取最大金额以及平均金额值
数据格式如下
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLOverWinEvRowRange {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price) OVER w AS max_price,"+
"avg(price) OVER w AS avg_price "+
"from "+table+" WINDOW w AS (
" +
" PARTITION BY product_id
" +
" ORDER BY date_time
" +
" ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
");
//6.执行Flink
resultTable.execute().print();
}
}
6、FlinkSQL当中的函数
FlinkSQL当中也内置了大量的函数,我们使用SQL主要就是在使用各种函数,这里我们来统一给大家介绍一下关于内置函数以及自定义函数
6.1、内置函数概览
Flink Table API/SQL提供了⼤量的内置函数,⼤家⾃⼰⽤到了当字典查即可:
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/functions/systemfunctions/

6.2、FlinkSQL自定义函数
除了以上各种内置的函数之外,flinkSQL当中还有自定义函数,接下来我们就来看一下FlinkSQL的自定义函数如何实现
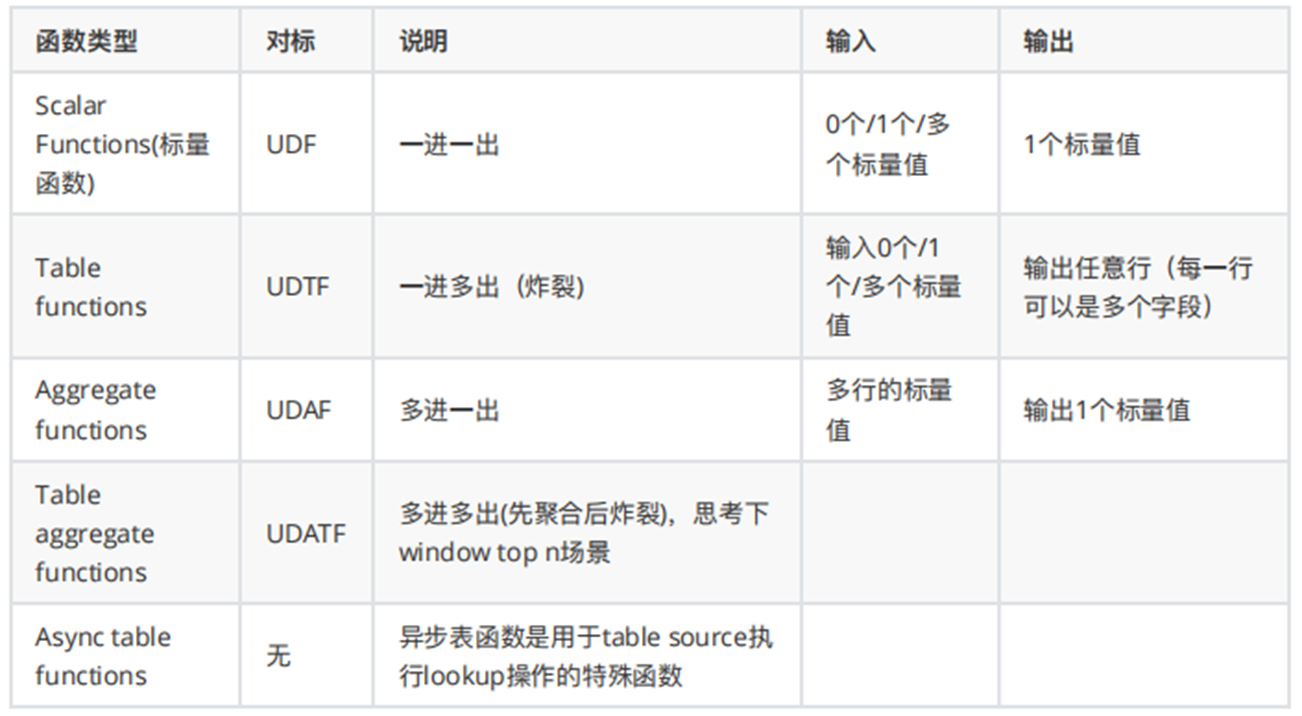
自定义函数分类
在hive当中,有UDF,UDAF以及UDTF这几种自定义函数,但是在FlinkSQL当中简化了这几个概念,使用的是标量函数,Tabel Function以及Aggregate Function等多种方式来表示,下表标识了flinkSQL当中的各种函数
6.2.1、自定义函数调用方式
FlinkSQL自定义函数使用方式:
可以通过Call函数内联方式来调用

6.2.2、FlinkSQL自定义函数实现方式
如果需要自定义函数,首先需要继承对应的基类,例如ScalarFunction,且该类必须声明为公共、⾮抽象、全局可访问的。 因此,不允许使⽤⾮静态内部类或匿名类。必须有默认构造⽅法(因为Flink需要实例化并注册到catalog中)
必须提供公共的、有明确定义的参数的eval⽅法(可以重载,可变参数,继承)

6.2.3、初始化open以及结束时close方法
UDF基类的open、close⽅法可以被覆盖,分别⽤于⾃定义UDF初始化和清理逻辑。在open⽅法中,提供FunctionContext参数,通过它可以获取Runtime环境的各种信息:

6.3、FlinkSQL自定义函数一进一出实战UDF
通过FlinkSQL当中的自定义函数ScalarFunction来实现json解析,通过传入json的key,获取到json对应的value字段值
json数据格式内容如下
{"date_time":"2022-10-04 08:01:48","email":"kyzqcd0686@vjikq.tng","id":0,"name":"郑剃"}
{"date_time":"2022-10-04 08:06:31","email":"bvkqwbmgwi@lh80q.4ln","id":1,"name":"闾丘喜造"}
{"date_time":"2022-10-04 08:04:39","email":"axvcbj7vbo@ecyi1.4gw","id":2,"name":"王曙介"}
{"date_time":"2022-10-04 08:00:19","email":"ew1qu5sunz@caxtg.vtn","id":3,"name":"赖溯姆"}
定义json解析函数
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public class JsonParseFunction extends ScalarFunction {
@Override
public void open(FunctionContext context) throws Exception {
}
public String eval(String jsonLine,String key){
JSONObject jsonObject = JSONObject.parseObject(jsonLine);
if(jsonObject.containsKey(key)){
return jsonObject.getString(key);
}else{
return "";
}
}
@Override
public void close() throws Exception {
}
}
代码实现如下:
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class FlinkSQLScalarFunction {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
tableEnvironment.createTemporarySystemFunction("JsonParse",JsonParseFunction.class);
String source_sql = "CREATE TABLE json_table (
" +
" line STRING
" +
") WITH (
" +
" 'connector'='filesystem',
" +
" 'path'='input/userbase.json',
" +
" 'format'='raw'
" +
")";
tableEnvironment.executeSql(source_sql);
tableEnvironment.sqlQuery("select * from json_table").execute().print();
tableEnvironment.sqlQuery("select JsonParse(line,'date_time'),JsonParse(line,'email'),JsonParse(line,'id'),JsonParse(line,'name') from json_table")
.execute().print();
}
}
6.4、FlinkSQL自定义函数一进多出实战UDTF
我们也可以自定义函数,实现一条数据进入之后,产出多条数据,类似于爆炸函数一样的作用
Table functions(表函数)⼀进多出(炸裂),继承TableFunction,提供⽆返回值的eval⽅法,使⽤collect来输出。
Table functions的返回值是⼀个表,需要跟原来的表join才能得到最终结果,因此要⽤到侧写表(不明⽩的可
以研究下LATERAL TABLE)
现有json数据内容如下:其中userBaseList是一个array数组,里面存放了多个用户信息,使用UDTF自定义函数,将每个用户信息给解析出来
{"date_time":1665145907806,"price":258.7,"productId":920956185,"userBaseList":[{"begin_time":"2022-10-07 08:38:31","email":"njvjeuchpe@mk1t0.d4e","id":"0","name":"尹修彻"},{"begin_time":"2022-10-07 08:33:59","email":"qurkb119uo@fvyg5.kqj","id":"1","name":"萧幅括"},{"begin_time":"2022-10-07 08:37:40","email":"i4w8ecponz@bpoay.3yv","id":"2","name":"胡乘"},{"begin_time":"2022-10-07 08:38:05","email":"uwl7fpfwbb@b7riu.fh3","id":"3","name":"黄煎"},{"begin_time":"2022-10-07 08:37:12","email":"bjjqrvajih@c75ur.lhs","id":"4","name":"袁肇"}]}
{"date_time":1665145918652,"price":258.7,"productId":-786075263,"userBaseList":[{"begin_time":"2022-10-07 08:39:47","email":"yfynwlektk@sz0me.hys","id":"0","name":"程痢"},{"begin_time":"2022-10-07 08:32:03","email":"jwpwuiwdnc@esxbd.hta","id":"1","name":"程盐殃"},{"begin_time":"2022-10-07 08:40:17","email":"fbfnidktqg@zaxxw.g1w","id":"2","name":"蔡锻"},{"begin_time":"2022-10-07 08:35:24","email":"twrm30opcb@5rgzj.sow","id":"3","name":"李猎甩"},{"begin_time":"2022-10-07 08:33:05","email":"rnkabnvaz9@bt319.xlk","id":"4","name":"夏焙匈"}]}
{"date_time":1665145927285,"price":258.7,"productId":-988723330,"userBaseList":[{"begin_time":"2022-10-07 08:37:04","email":"pcs8ejgibk@kxf95.djq","id":"0","name":"郝疯框"},{"begin_time":"2022-10-07 08:40:20","email":"n63k5twind@eddbg.aui","id":"1","name":"万侨"},{"begin_time":"2022-10-07 08:33:52","email":"1xmk0vh3bb@1htg2.tw2","id":"2","name":"侯临迸"},{"begin_time":"2022-10-07 08:33:05","email":"cnrqk4crpy@svhkq.wwf","id":"3","name":"闾丘耘"},{"begin_time":"2022-10-07 08:34:26","email":"ubozcxmrxc@c6qpp.8ug","id":"4","name":"皇甫坡"}]}
代码实现如下
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.json.JSONArray;
import org.json.JSONObject;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public class FlinkSQLTableFunction {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
tableEnvironment.createTemporarySystemFunction("JsonFunc",JsonFunction.class);
tableEnvironment.createTemporarySystemFunction("explodeFunc",ExplodeFunc.class);
String source_sql = "CREATE TABLE json_table (
" +
" line STRING
" +
") WITH (
" +
" 'connector'='filesystem',
" +
" 'path'='input/product_user.json',
" +
" 'format'='raw'
" +
")";
tableEnvironment.executeSql(source_sql);
//方式一:使用TableAPI通过内连接来实现
tableEnvironment.from("json_table")
.joinLateral(call(ExplodeFunc.class,$("line"),"userBaseList")
.as("id","name","begin_time","email"))
.select(call(JsonFunction.class,$("line"),"date_time"),
call(JsonFunction.class,$("line"),"price"),
call(JsonFunction.class,$("line"),"productId"),
$("id"),
$("name"),
$("begin_time"),
$("email")
).execute().print();
//方式二:使用TableAPI通过左外连接来实现
tableEnvironment.from("json_table")
.leftOuterJoinLateral(call(ExplodeFunc.class,$("line"),"userBaseList")
.as("id","name","begin_time","email"))
.select(call(JsonFunction.class,$("line"),"date_time"),
call(JsonFunction.class,$("line"),"price"),
call(JsonFunction.class,$("line"),"productId"),
$("id"),
$("name"),
$("begin_time"),
$("email")
).execute().print();
//方式三:使用FlinkSQL内连接来实现
tableEnvironment.sqlQuery("select " +
"JsonFunc(line,'date_time')," +
"JsonFunc(line,'price')," +
"JsonFunc(line,'productId')," +
"id," +
"name," +
"begin_time " +
"email " +
" from json_table " +
",lateral table(explodeFunc(line,'userBaseList')) "
).execute().print();
//方式四:使用FlinkSQL左外连接来实现
tableEnvironment.sqlQuery("select " +
"JsonFunc(line,'date_time') as date_time," +
"JsonFunc(line,'price') as price ," +
"JsonFunc(line,'productId') as productId," +
"id," +
"name," +
"begin_time " +
"email " +
" from json_table left join lateral table (explodeFunc(line,'userBaseList')) as sc(id,name,begin_time,email) on true"
).execute().print();
}
/**
* 自定义udf
*/
public static class JsonFunction extends ScalarFunction {
public String eval(String line,String key){
//转换为JSON
JSONObject baseJson = new JSONObject(line);
String value = "";
if(baseJson.has(key)){
//根据key获取value
return baseJson.getString(key);
}
return value;
}
}
/**
* 自定义UDTF
*/
@FunctionHint(output = @DataTypeHint("ROW<id String,name String,begin_time String,email String>"))
public static class ExplodeFunc extends TableFunction {
public void eval(String line,String key){
JSONObject jsonObject = new JSONObject(line);
JSONArray jsonArray = new JSONArray(jsonObject.getString(key));
for(int i = 0;i< jsonArray.length();i++){
String date_time = jsonArray.getJSONObject(i).getString("begin_time");
String email = jsonArray.getJSONObject(i).getString("email");
String id = jsonArray.getJSONObject(i).getString("id");
String name = jsonArray.getJSONObject(i).getString("name");
collect(Row.of(id,name,date_time,email));
}
}
}
}
6.5、FlinkSQL自定义函数实现多进一出UDAF
Aggregate functions(聚合函数)将多⾏的标量值映射到新的标量值(多进⼀出),聚合函数⽤到了累加器,下图是聚合过程:
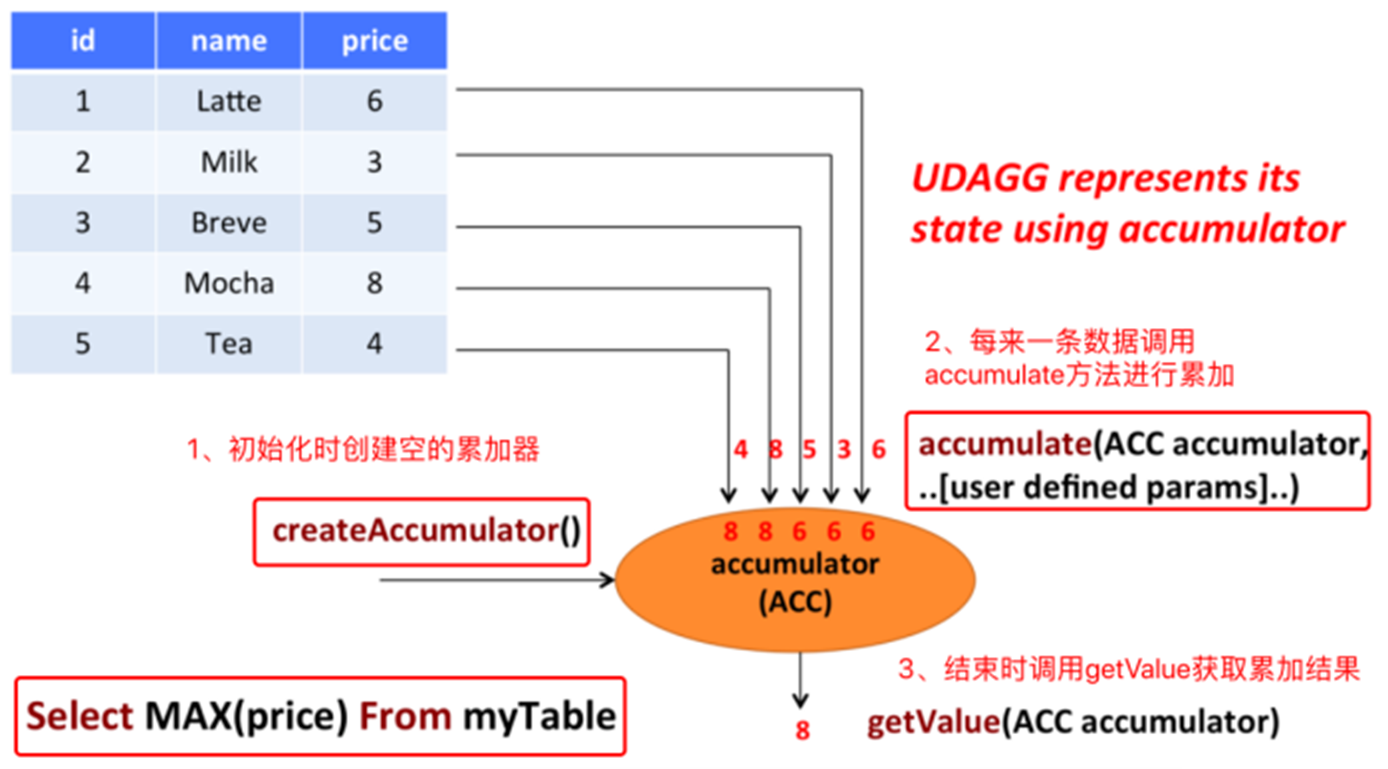
Aggregate functions(聚合函数)将多⾏的标量值映射到新的标量值(多进⼀出),聚合函数⽤到了累加器,下图是聚合过程:
继承AggregateFunction
必须覆盖createAccumulator和getValue
提供accumulate⽅法
retract⽅法在OVER windows上才是必须的
merge有界聚合以及会话窗⼝和滑动窗⼝聚合都需要(对性能优化也有好处)
需求:使用自定义UDAF函数来求每门课程的平均分数
现有CSV数据内容如下
1,zhangsan,Chinese,80
1,zhangsan,Math,76
1,zhangsan,Science,84
1,zhangsan,Art,90
2,lisi,Chinese,60
2,lisi,Math,78
2,lisi,Science,86
2,lisi,Art,88
代码实现如下
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public class FlinkUdafAggregrate {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
//注册函数
tableEnvironment.createTemporarySystemFunction("AvgFunc",AvgFunc.class);
String source_sql = "CREATE TABLE source_score (
" +
" id int,
" +
" name STRING,
" +
" course STRING,
" +
" score Double" +
") WITH (
" +
" 'connector' = 'filesystem',
" +
" 'path' = 'input/score.csv' ,
" +
" 'format' = 'csv'
" +
")";
//创建表
tableEnvironment.executeSql(source_sql);
tableEnvironment.from("source_score")
.groupBy($("course"))
.select($("course"),call("AvgFunc",$("score").as("avg_score")))
.execute().print();
tableEnvironment.executeSql("select course,AvgFunc(score) as avg_score from source_score group by course")
.print();
}
public static class AvgFunc extends AggregateFunction<Double,AvgAccumulator> {
@Override
public Double getValue(AvgAccumulator avgAccumulator) {
if(avgAccumulator.count==0){
return null;
}else {
return avgAccumulator.sum/avgAccumulator.count;
}
}
//初始化累加器
@Override
public AvgAccumulator createAccumulator() {
return new AvgAccumulator();
}
//迭代累加
public void accumulate(AvgAccumulator acc,Double score){
acc.setSum(acc.sum+score);
acc.setCount(acc.count+1);
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class AvgAccumulator {
public double sum = 0.0;
public int count = 0;
}
}






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结