您现在的位置是:首页 >其他 >Yolov5训练日记~如何用Yolov5训练识别自己想要的模型~网站首页其他
Yolov5训练日记~如何用Yolov5训练识别自己想要的模型~
目录
最近尝试了Yolov5训练识别人体,用的是自己尝试做的训练集。见识到Yolo的强大后,决定分享给大家。
一.数据集准备
数据集是从百度图片上下载的,我当然不可能一个一个下载,会累死的。。。
既然会python,就做最好的爬虫~
from fake_useragent import UserAgent
import requests
import re
import uuid
#参考:
#https://blog.csdn.net/weixin_56198196/article/details/120470874
#https://blog.csdn.net/weixin_52971139/article/details/125065788
headers={ #遇到Forbid spider access就在请求头多加一些东西,试了一下'Accept-Encoding'是关键
# 'Accept': 'text/plain, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'Connection': 'keep-alive',
'Cookie': 'BDqhfp=%E5%8F%B2%E5%8A%AA%E6%AF%94%26%260-10-1undefined%26%263746%26%264; BIDUPSID=5A04241009FD166564DACF4050551F2D; PSTM=1611376447; __yjs_duid=1_2de46e288096c13a7edea3d05a5204421620544039468; BAIDUID=F163DBC1DF098AF604AE753E72659BAA:FG=1; BDUSS=Tczc3RnamRhaUhicm5rfm83V3pkMTBySUd1Z0V4Q25mbXhYdElRemJHdVktVnRoRVFBQUFBJCQAAAAAAQAAAAEAAACR090iR3JpZmZleTUxMQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJhsNGGYbDRhN; BDUSS_BFESS=Tczc3RnamRhaUhicm5rfm83V3pkMTBySUd1Z0V4Q25mbXhYdElRemJHdVktVnRoRVFBQUFBJCQAAAAAAQAAAAEAAACR090iR3JpZmZleTUxMQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJhsNGGYbDRhN; BAIDUID_BFESS=F163DBC1DF098AF604AE753E72659BAA:FG=1; BDORZ=AE84CDB3A529C0F8A2B9DCDD1D18B695; userFrom=cn.bing.com; IMG_WH=573_756; H_WISE_SIDS=110085_178384_179349_181588_182531_183327_183611_183750_184578_185029_185517_185653_185750_186317_186411_187020_187195_187206_187292_187450_187663_187670_187928_8000097_8000100_8000126_8000140_8000150_8000169_8000177_8000185; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; cleanHistoryStatus=0; indexPageSugList=%5B%22%E5%8F%B2%E5%8A%AA%E6%AF%94%22%2C%22%E6%B5%B7%E8%B4%BC%E7%8E%8B%22%2C%22%E8%8A%B1%E6%9C%B5%22%2C%22undertale%22%2C%22python%22%2C%22%E8%8A%B1%E7%AE%80%E7%AC%94%E7%94%BB%22%2C%22%E5%90%8C%E5%9E%8B%E4%B8%96%E4%BB%A3%E4%BA%A4%E6%9B%BF%22%2C%22%E6%A8%9F%E7%A7%91%E8%8A%B1%22%2C%22%E6%A8%9F%E7%A7%91%E8%8A%B1%E7%9A%84%E8%A7%A3%E5%89%96%22%5D; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; ab_sr=1.0.1_MTY1OTI2YjEyMzViNzQyYWVhZjdhZWQxNzc0YjE1NzA2NGEyZmMwZGEwNzRmMWVjZGM3N2IzMDlkYjViZWVlOGYyNTllZDMzZjgwZGMxZWZhOWFiMmEyYjg0NjgyYzgwYjk0Y2QxYWVmM2E1ZTFiZjkyYTNlOGYzMDg1MWVjNjUyODViYzMyZjc2Mjk2OGFmZmZjZTkwNjg3OWI4NjhjZjdiNzJmNTY3NTIyZjg2ODVjMzUzNTExYjhiMjkxZjEx; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E5%8F%B2%E5%8A%AA%E6%AF%94&oq=%E5%8F%B2%E5%8A%AA%E6%AF%94&rsp=-1',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Mobile Safari/537.36 Edg/93.0.961.52'
}
img_re = re.compile('"thumbURL":"(.*?)"')
img_format = re.compile("f=(.*).*?w")
def file_op(img):
uuid_str = uuid.uuid4().hex
tmp_file_name = './arsenal/%s.jpg' % uuid_str
with open(file=tmp_file_name, mode="wb") as file:
file.write(img)
def xhr_url(url_xhr, start_num=0, page=5):
end_num = page*30
for page_num in range(start_num, end_num, 30):
resp = requests.get(url=url_xhr+str(page_num), headers=headers)
if resp.status_code == 200:
print(resp.text)
img_url_list = img_re.findall(resp.text) # 这是个列表形式
for img_url in img_url_list:
img_rsp = requests.get(url=img_url, headers=headers)
file_op(img=img_rsp.content)
else:
break
print("爬取了"+str(page_num)+"张")
print("内容已经全部爬取")
if __name__ == "__main__":
org_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&word={text}&pn=".format(text=input("输入你想检索内容:"))
xhr_url(url_xhr=org_url, start_num=int(input("开始页:")), page=int(input("所需爬取页数:")))
用这样的代码就可以把指定关键词的照片爬取下来,如下图所示是爬取下来的照片。爬取代码位于newdata目录下。

(图源网络侵删)
在上图中,爬取的数据关键词为“路人照片”。
二.标签设置
标签有很多可以打的工具,我采用的是vott,图片和安装包链接如下。

链接:https://pan.baidu.com/s/1CtAiR6ub072WvgfoFkm6Ig?pwd=0kqu
提取码:0kqu
--来自百度网盘超级会员V5的分享
具体使用方法参考:标注工具 VoTT 详细教程_vott使用_清欢守护者的博客-CSDN博客
如果要识别人,就把人的区域都框起来~
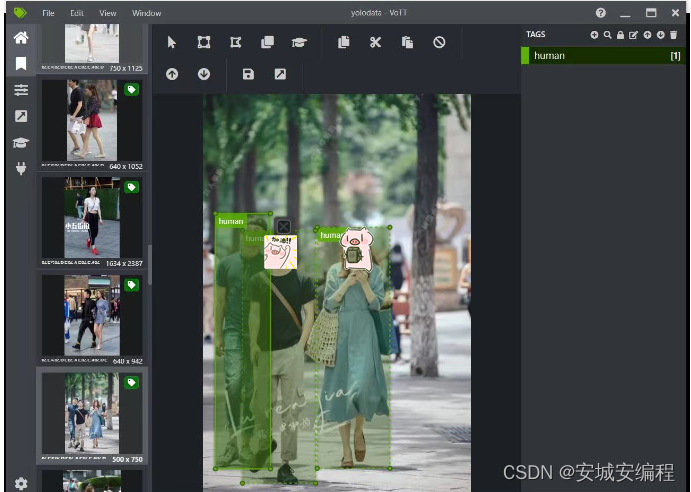 最后输出的标签如下:
最后输出的标签如下:
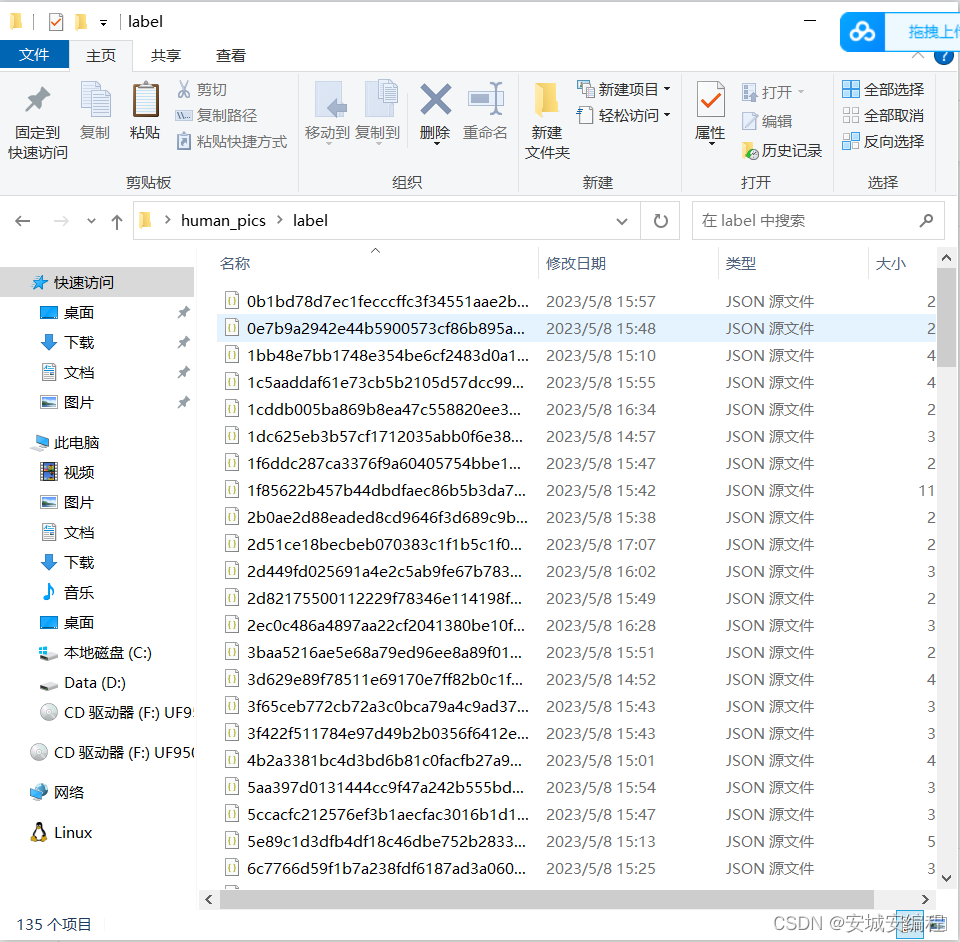
json内的标签数据
标签数据需要经过如下代码处理成yolov5的可识别数据
import os
import json
import shutil
img_folder_path = "img/"
# 使用os.listdir()函数获取文件夹下的所有文件名
img_file_names = os.listdir(img_folder_path)
lab_folder_path = "label/"
# 使用os.listdir()函数获取文件夹下的所有文件名
lab_file_names = os.listdir(lab_folder_path)
# 打印所有文件名
'''for file_name in img_file_names:
print(file_name)'''
# 打印所有文件名
data_num=0
outdir_img="outdata/images/"
outdir_lab="outdata/labels/"
for file_name in lab_file_names:
with open(lab_folder_path+file_name,'r',encoding = 'utf-8') as fp:
# read()方法将fp(一个支持.read()的文件类对象,包含一个JSON文档)转换成字符串
data = json.loads(fp.read())
#print(fp.read())
for img_file_name in img_file_names:
if img_file_name[-4:]==".jpg":
if img_file_name[-18:]==data['asset']['name'][-18:]:
name="im"+str(data_num)
data_num+=1
shutil.copy(img_folder_path+img_file_name,outdir_img+name+".jpg")
for item in data['regions']:
data1=str((item['points'][0]['x']+item['points'][1]['x'])/(2*data['asset']['size']['width']))
data2=str((item['points'][0]['y']+item['points'][2]['y'])/(2*data['asset']['size']['height']))
data3=str(item['boundingBox']['width']/data['asset']['size']['width'])
data4=str(item['boundingBox']['height']/data['asset']['size']['height'])
Note=open(outdir_lab+name+".txt",mode='a')
Note.write("0 "+data1+" "+data2+" "+data3+" "+data4+"
")
Note.close()
(代码仅供参考,具体以实际情况为准)
上述代码的目录架构:
img
-xx.jpg
-xx.jpg
...
label
-xx.json
-xx.json
...
outdata
-images
-labels运行后在outdata文件夹会生成转换格式成功的图像和标签
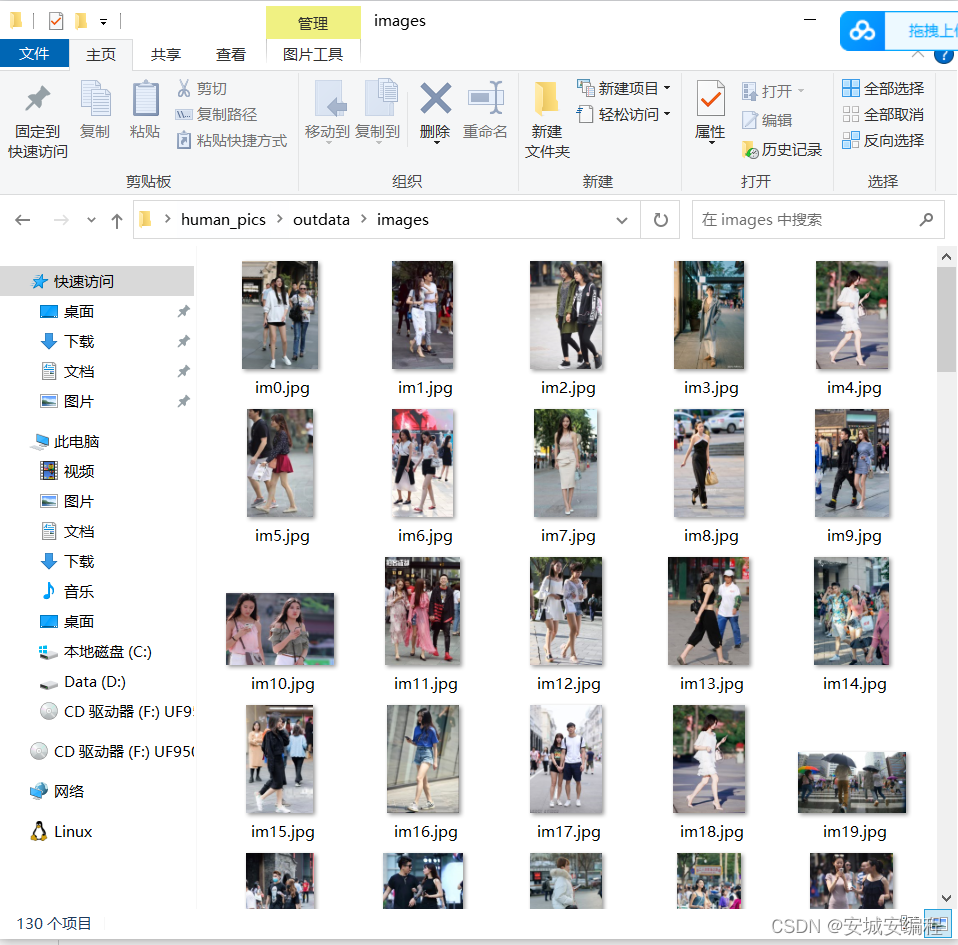

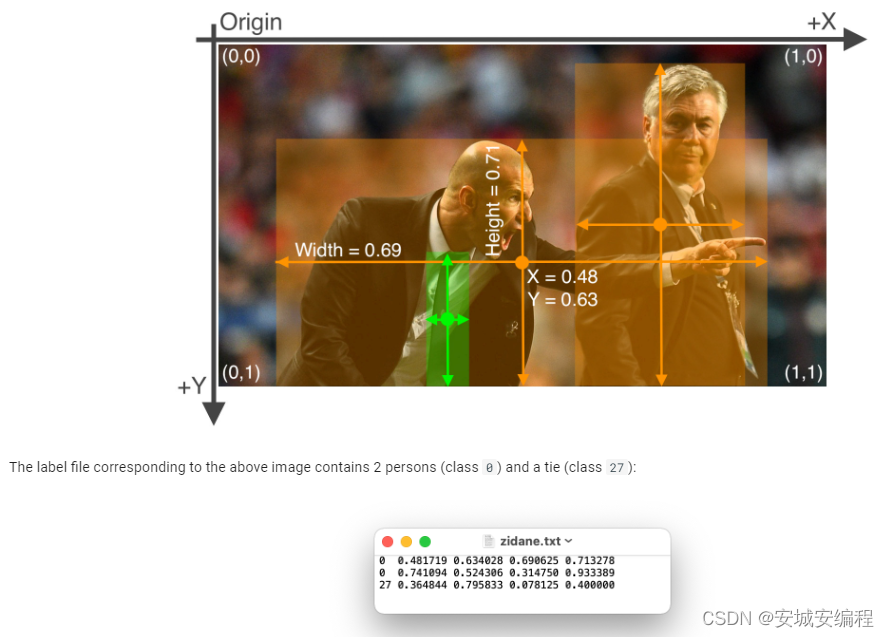
其中,标签的格式如下:

参考yolov5的数据格式:
Train Custom Data - Ultralytics YOLOv8 Docs

三.模型训练
准备好数据集,就可以训练啦~
GitHub - ultralytics/yolov5: YOLOv5 ? in PyTorch > ONNX > CoreML > TFLite
下载好YOLOv5后按要求配置环境:

下载COCO128数据集coco128 | Kaggle
将下载好的dataset文件与yolov5文件夹按如下放置:
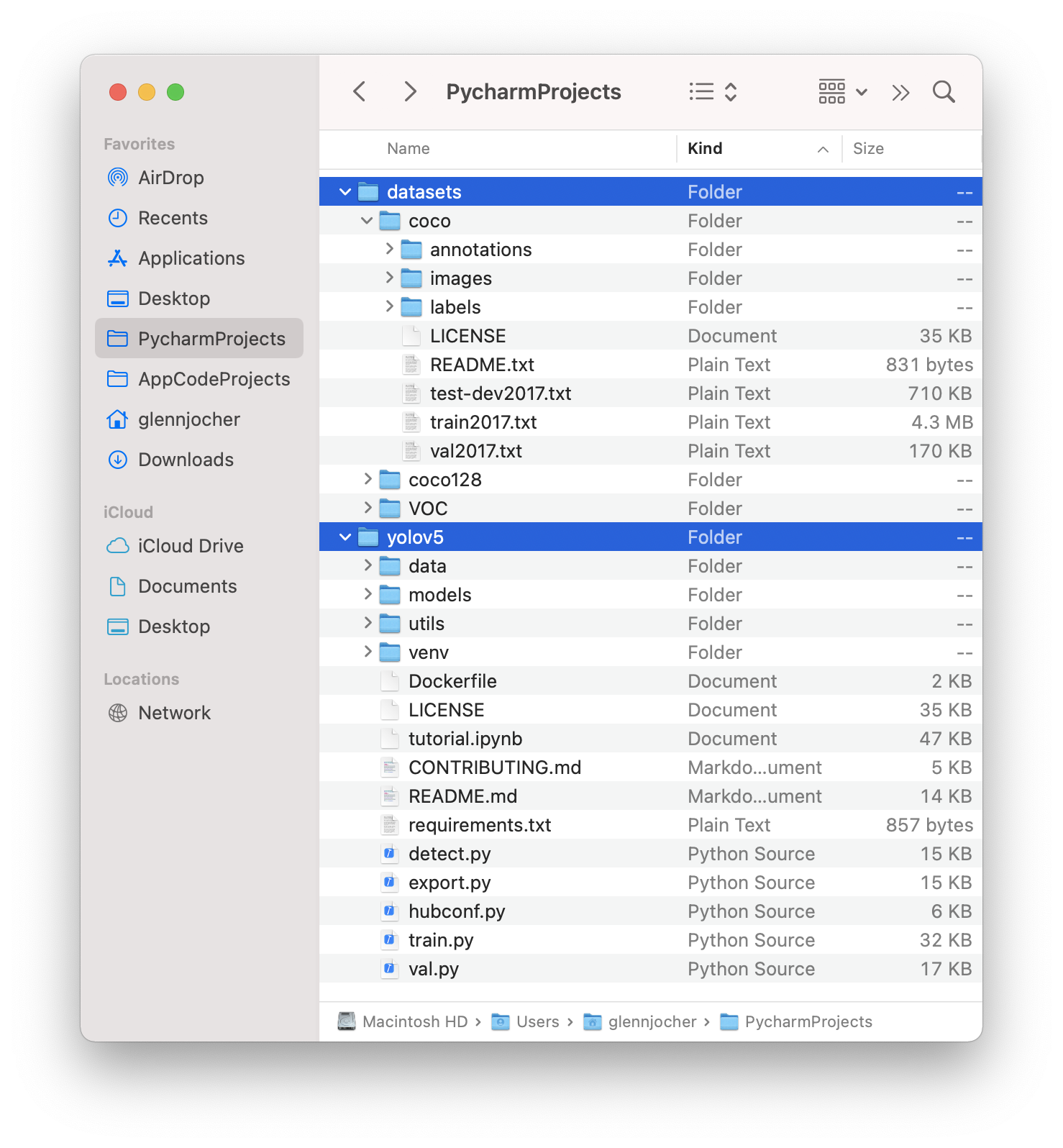
将coco128.yaml的内容修改:
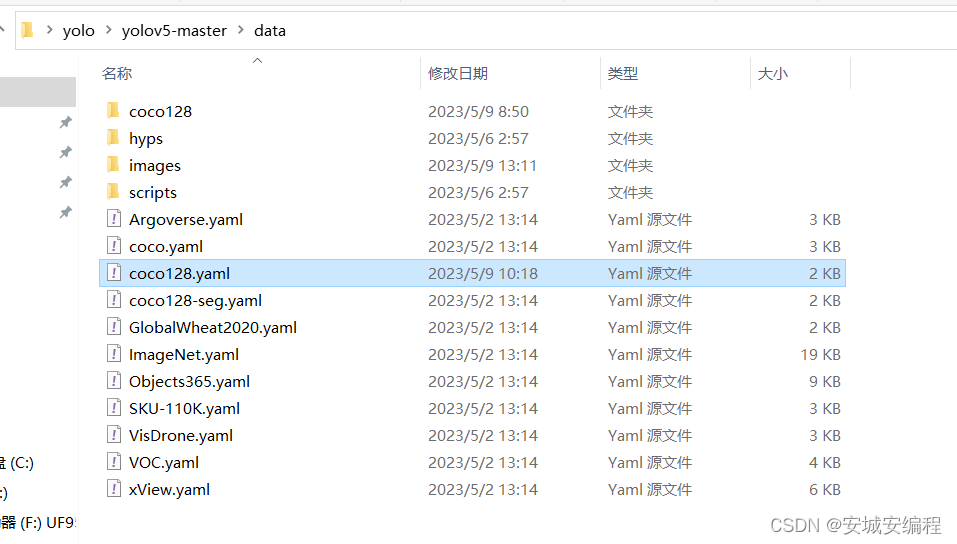
改成如下:
# YOLOv5 ? by Ultralytics, AGPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: 0
# 1: bicycle
# 2: car
# 3: motorcycle
# 4: airplane
# 5: bus
# 6: train
# 7: truck
# 8: boat
# 9: traffic light
# 10: fire hydrant
# 11: stop sign
# 12: parking meter
# 13: bench
# 14: bird
# 15: cat
# 16: dog
# 17: horse
# 18: sheep
# 19: cow
# 20: elephant
# 21: bear
# 22: zebra
# 23: giraffe
# 24: backpack
# 25: umbrella
# 26: handbag
# 27: tie
# 28: suitcase
# 29: frisbee
# 30: skis
# 31: snowboard
# 32: sports ball
# 33: kite
# 34: baseball bat
# 35: baseball glove
# 36: skateboard
# 37: surfboard
# 38: tennis racket
# 39: bottle
# 40: wine glass
# 41: cup
# 42: fork
# 43: knife
# 44: spoon
# 45: bowl
# 46: banana
# 47: apple
# 48: sandwich
# 49: orange
# 50: broccoli
# 51: carrot
# 52: hot dog
# 53: pizza
# 54: donut
# 55: cake
# 56: chair
# 57: couch
# 58: potted plant
# 59: bed
# 60: dining table
# 61: toilet
# 62: tv
# 63: laptop
# 64: mouse
# 65: remote
# 66: keyboard
# 67: cell phone
# 68: microwave
# 69: oven
# 70: toaster
# 71: sink
# 72: refrigerator
# 73: book
# 74: clock
# 75: vase
# 76: scissors
# 77: teddy bear
# 78: hair drier
# 79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
即将没有用到的种类注释掉。
之后训练:
python train.py --img 640 --epochs 30 --data coco128.yaml --weights yolov5s.pt其中yolov5s.pt会自动下载,如果进度条没跑完就停止了,则把命令行中的下载网址复制到浏览器下载,并删除原本下载一半的数据。
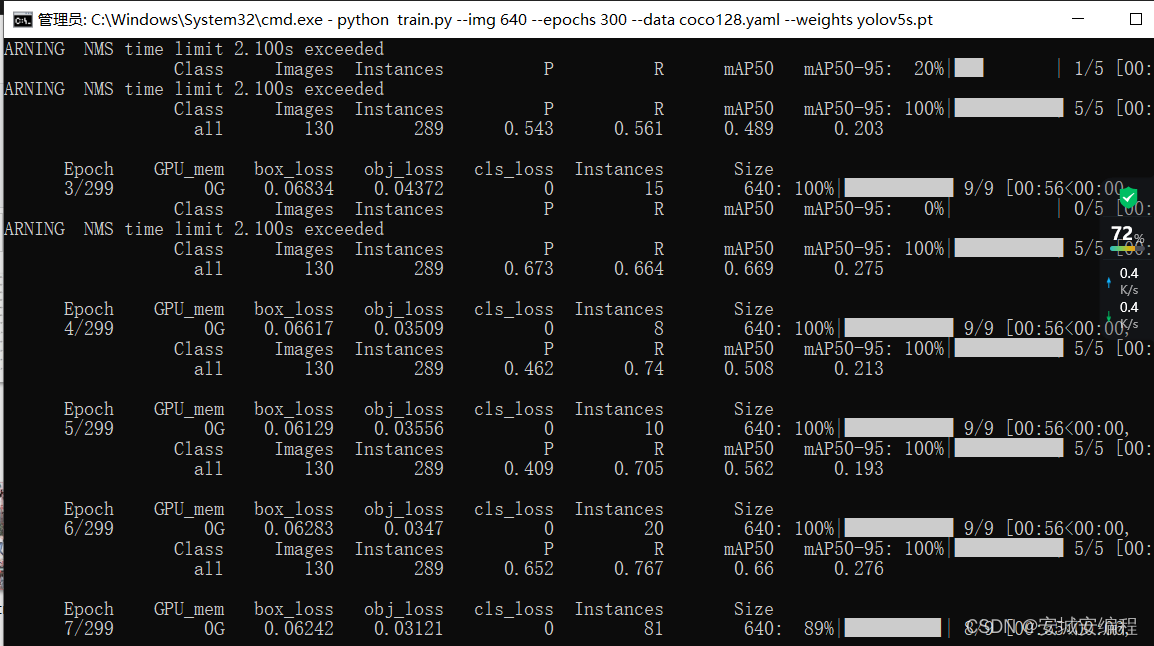
训练后在runs/train文件夹下寻找训练好的模型best.pt并替换yolov5s.pt

四.模型测试
测试模型的命令行:
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream测试效果:

(图源网络侵删)
注意:如果遇到什么问题,请在留言区留言并附上你的代码,认为有用的文件内容截图~






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结