您现在的位置是:首页 >技术教程 >人工智能学习07--pytorch16--MobileNet网络详解网站首页技术教程
人工智能学习07--pytorch16--MobileNet网络详解
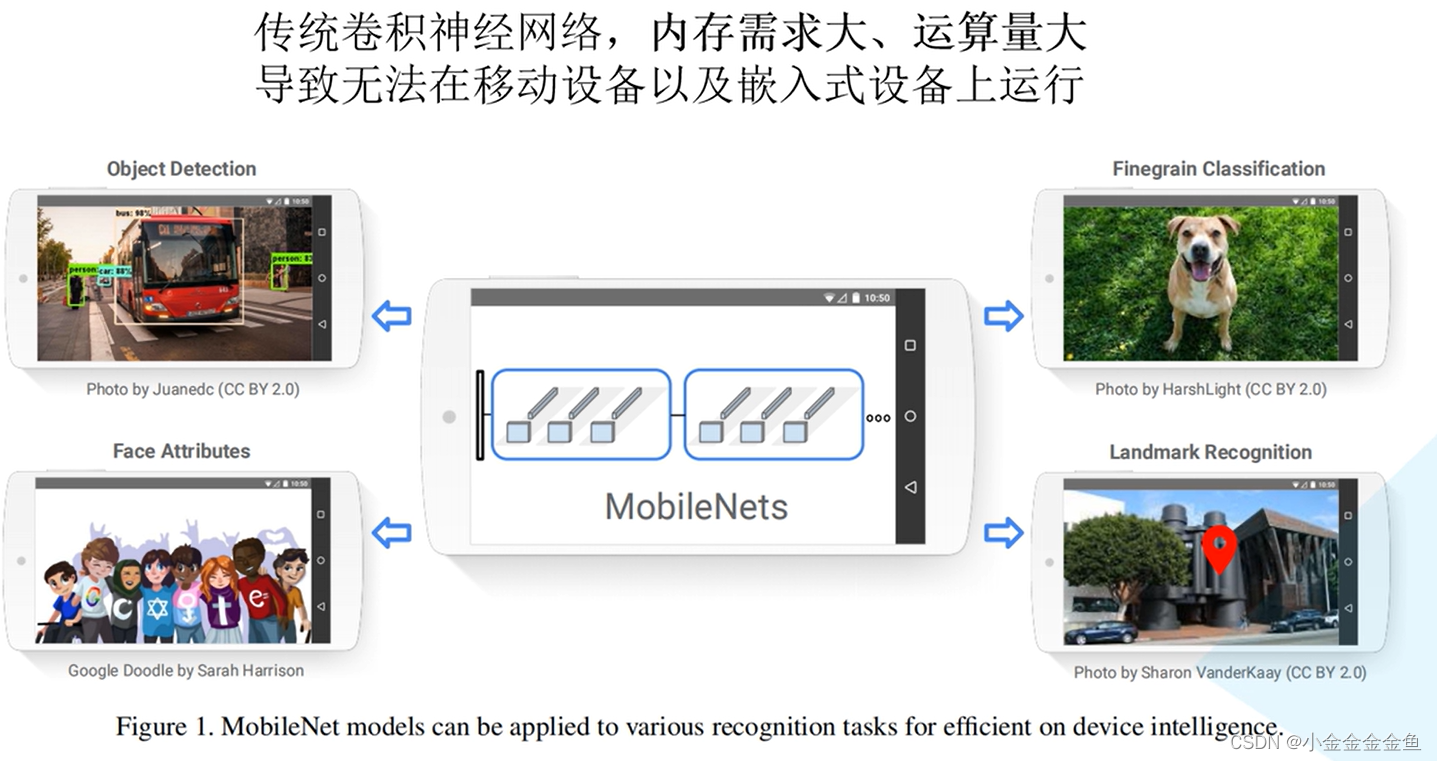
MobileNet详解

DW卷积:
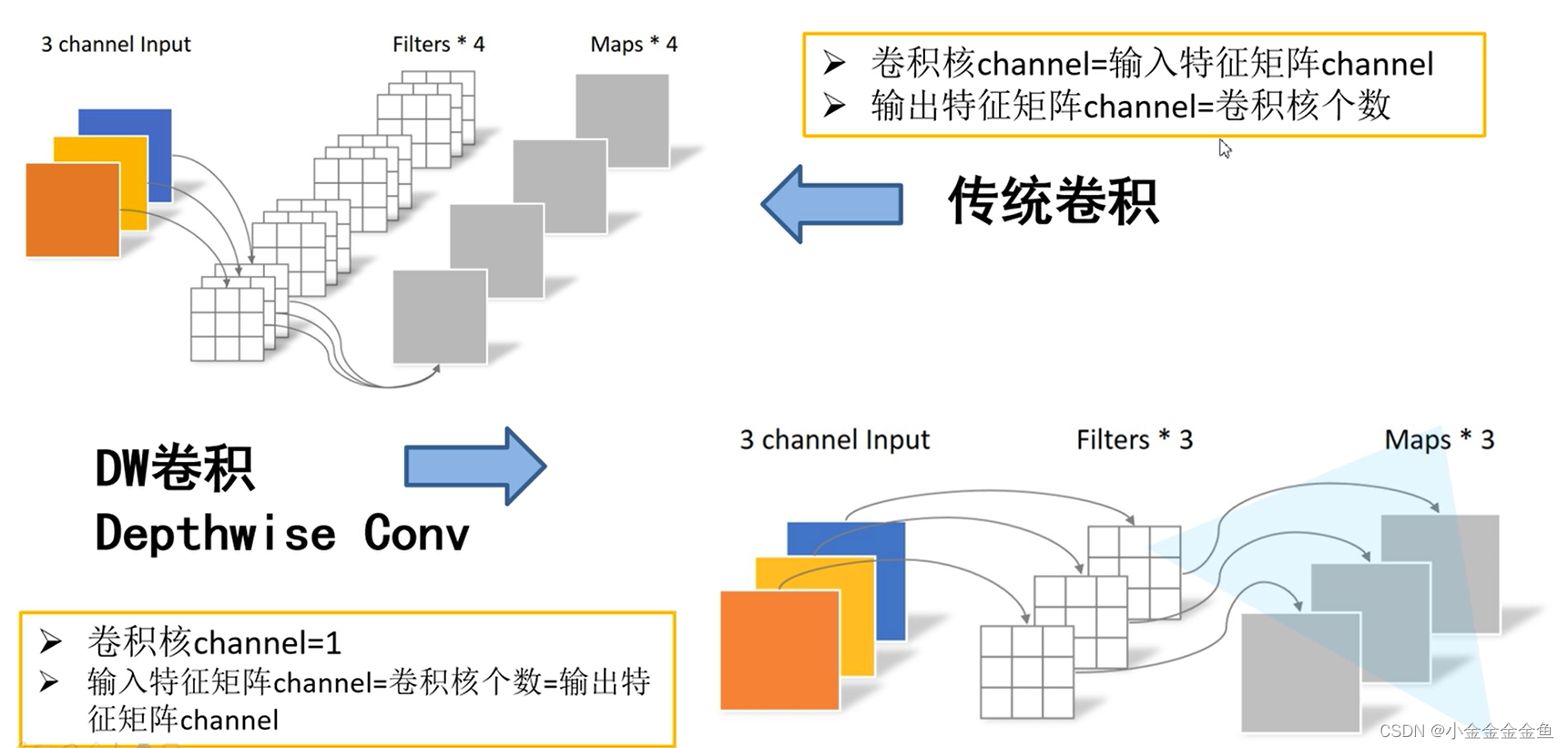
每个卷积核的深度为1,而不是像之前一样等于特征矩阵的深度。
每个卷积核只负责输入特征矩阵的一个channel进行卷积运算,再得到相应的输出矩阵的一个channel。
因为每个卷积核只负责一个channel,则采用的特征矩阵的深度就应该与输入特征矩阵的深度相同,这样即可确保每一个卷积核负责一个channel。
又因为每个卷积核与输入特征矩阵的一个channel进行卷积之后,得到一个输出特征矩阵的channel,则输出特征矩阵的深度与卷积核的个数相同,进一步与输入特征矩阵的深度相同。
深度可分的卷积操作
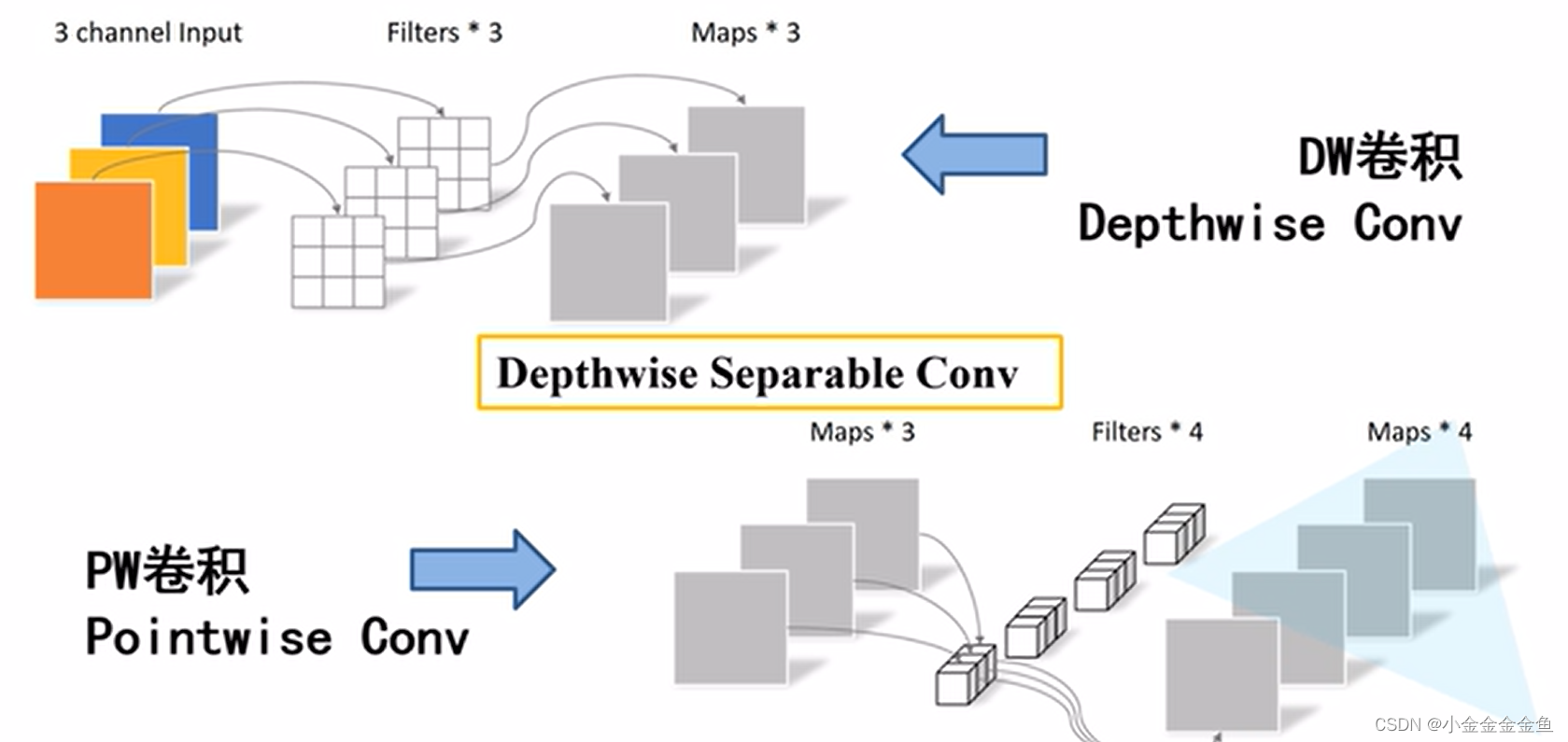
DW卷积+PW卷积
PW卷积:普通卷积,但是卷积核大小等于1。由上图可以看出,每个卷积核的深度与输入特征矩阵的深度相同,输出特征矩阵的深度与卷积核的个数相同。
相比普通卷积而言,参数的变化:
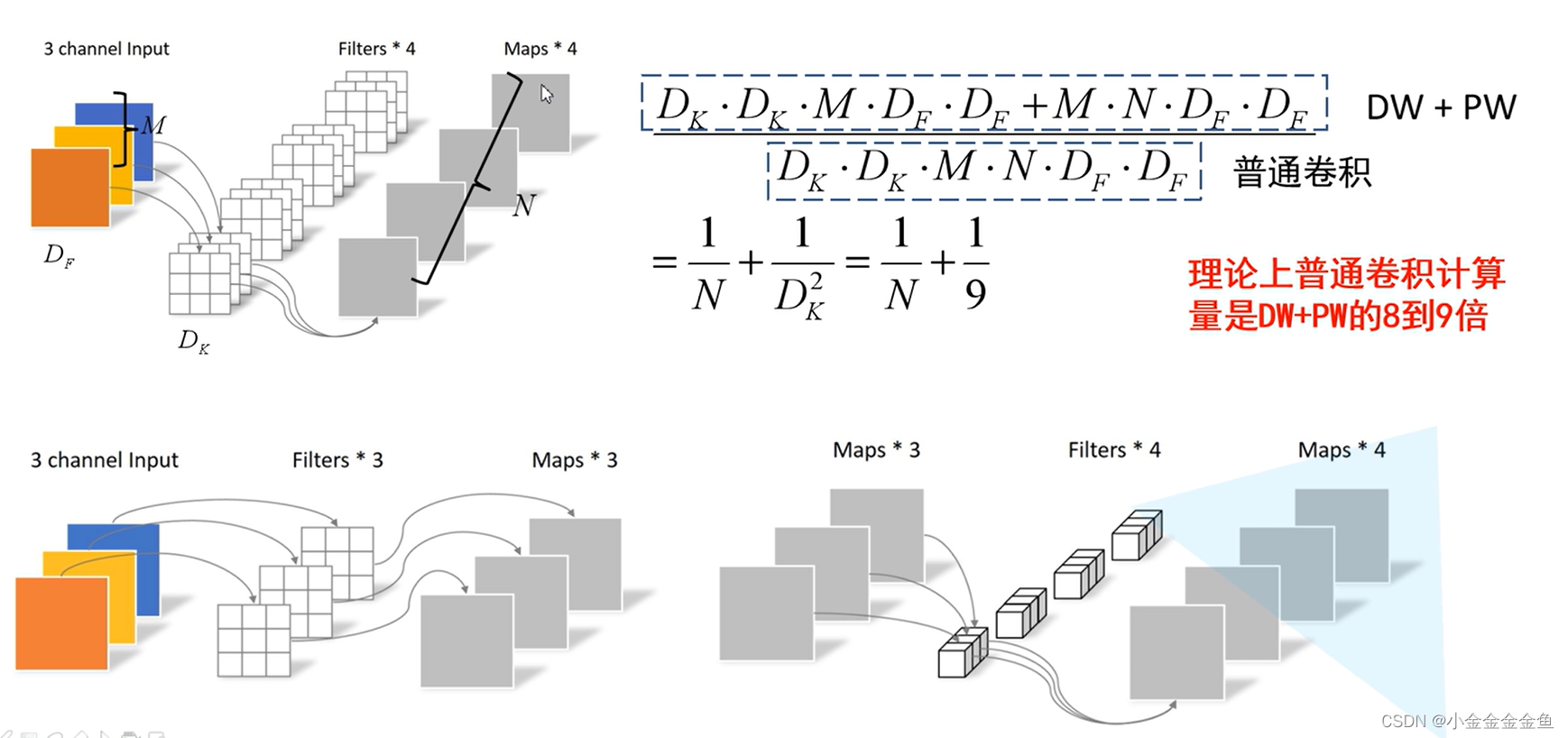
均可得到深度为4的特征矩阵。

彩色图像 32个卷积核
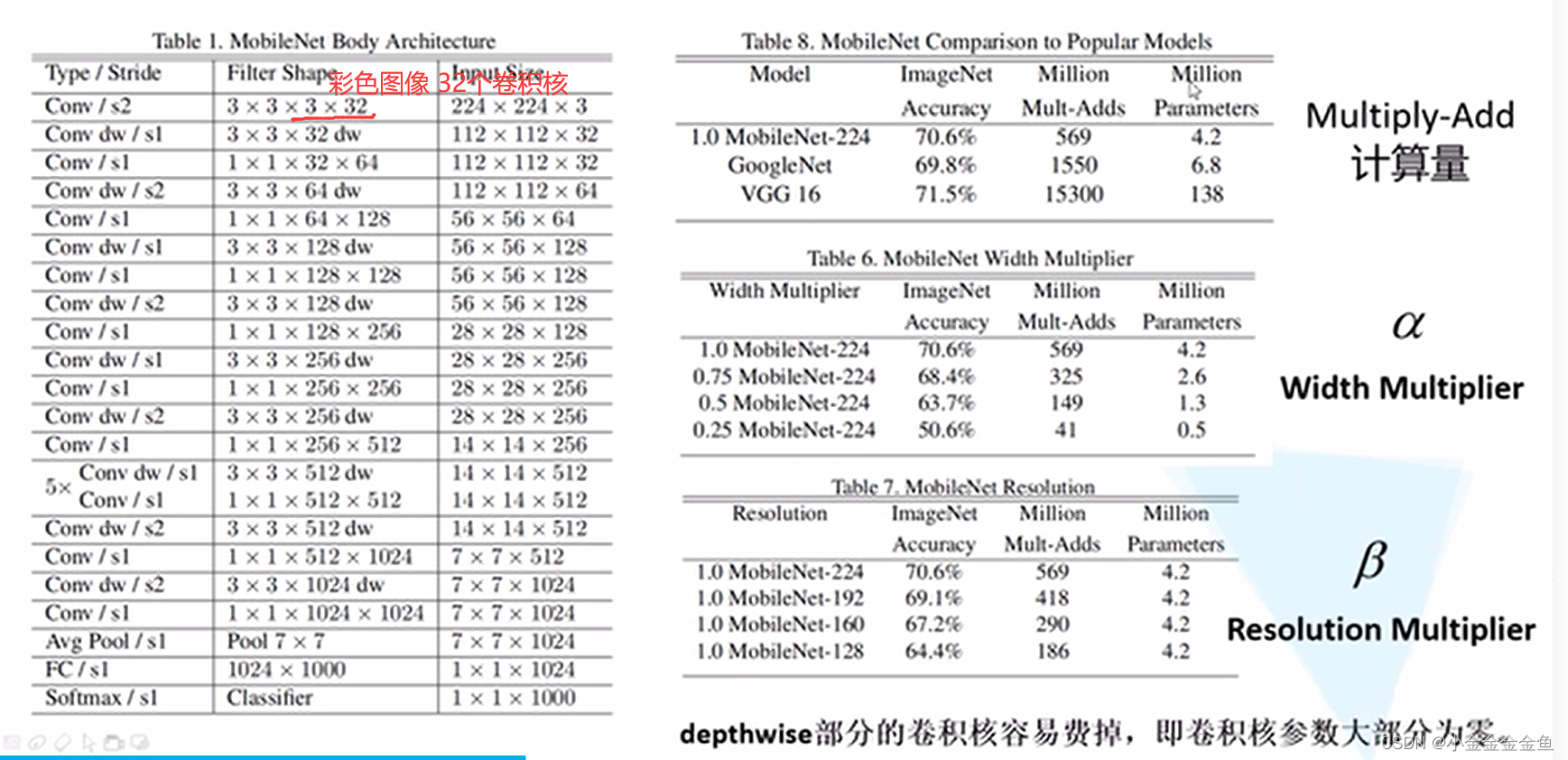
针对MobileNet中部分卷积核废掉的问题,设计了MobileNetV2?
MobileNetV2详解

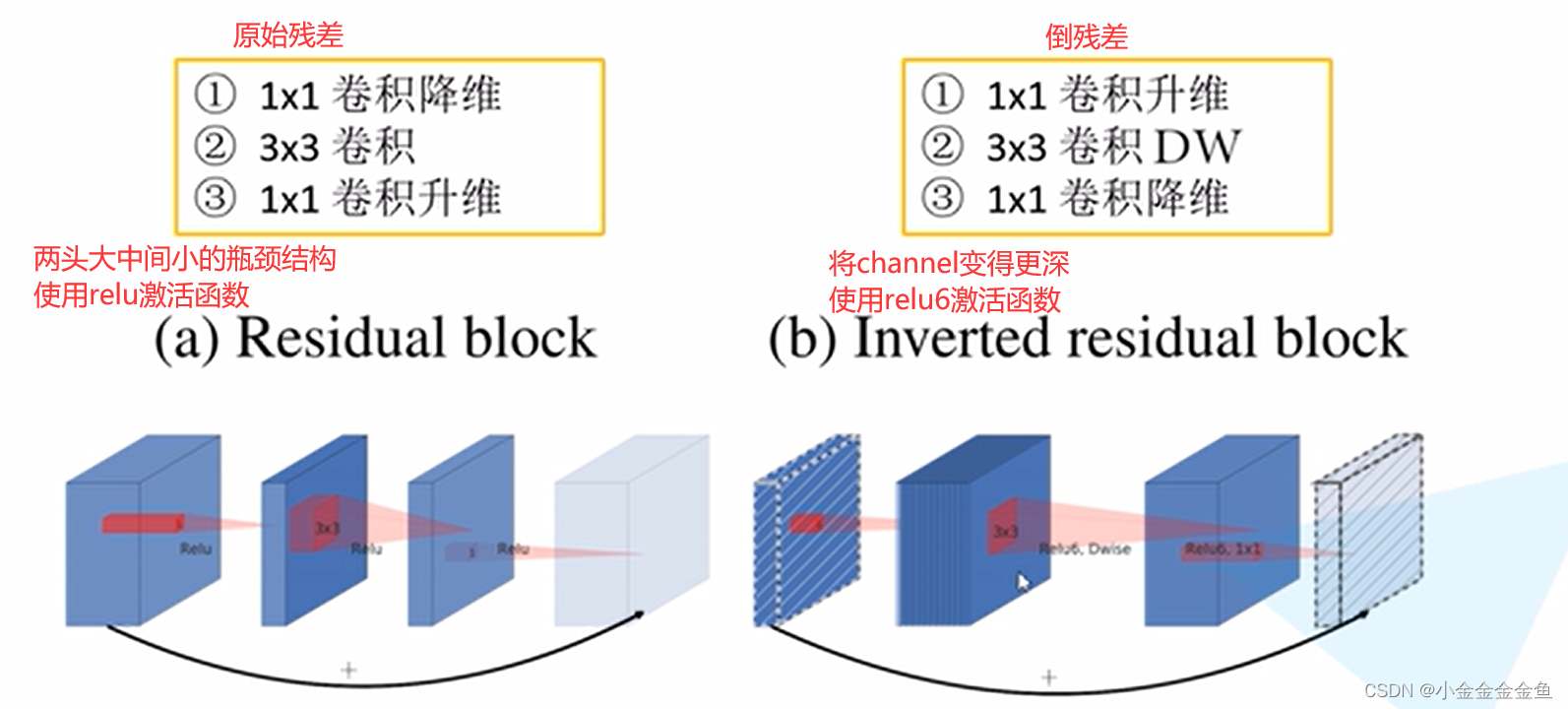
(
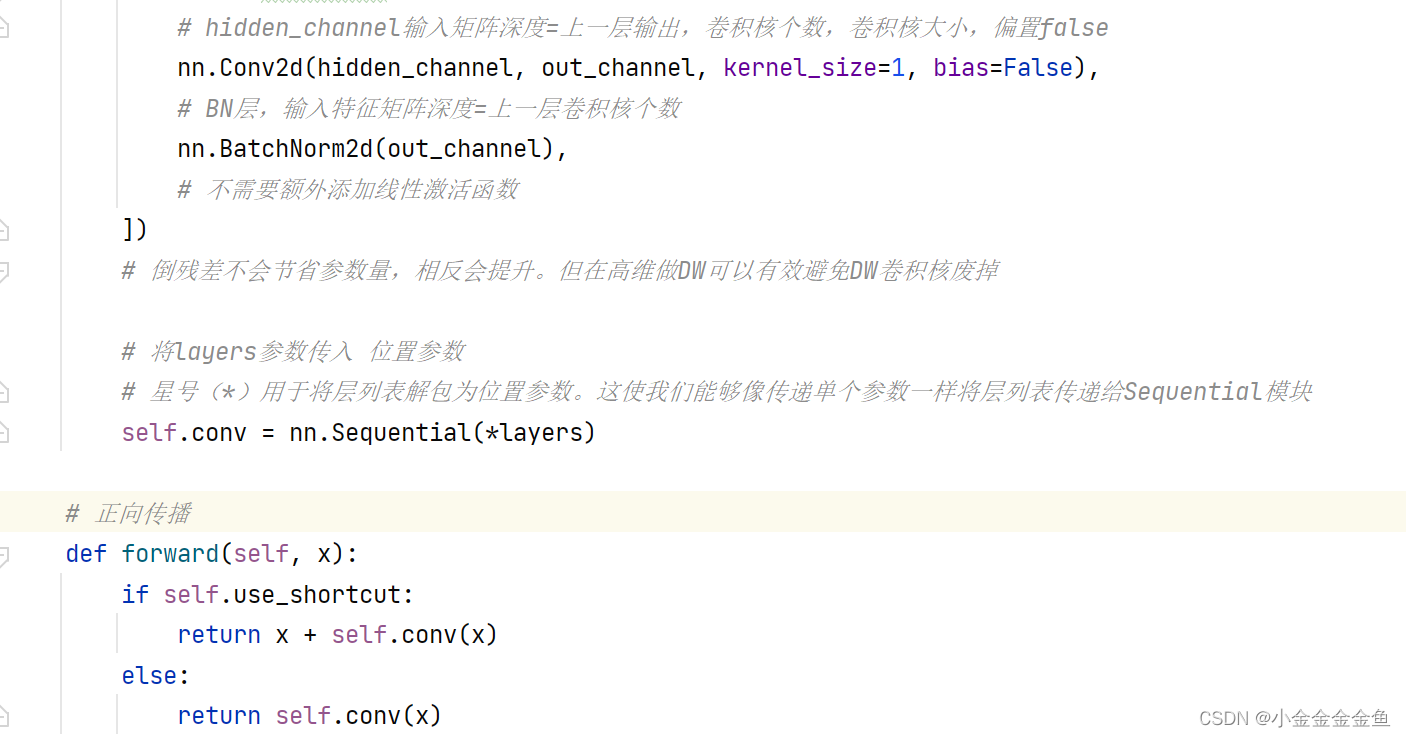
之前瓶颈结构是因为传统卷积运算量大,可以减少运算量,DW本身减少了运算量,使用倒结构,虽然增大一些运算量,但增大了卷积核个数,可以解决v1版本的缺点
)
relu6:relu激活函数的改进版

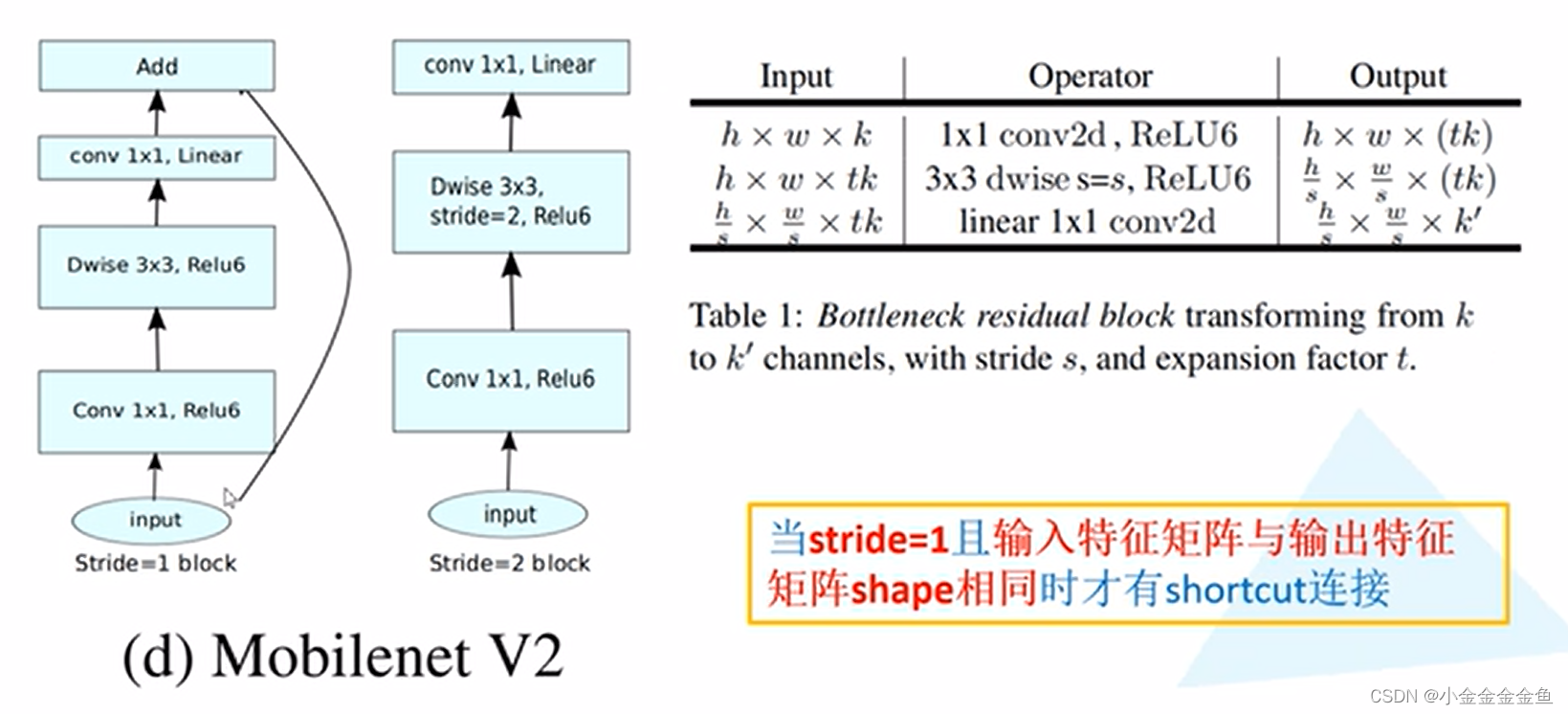
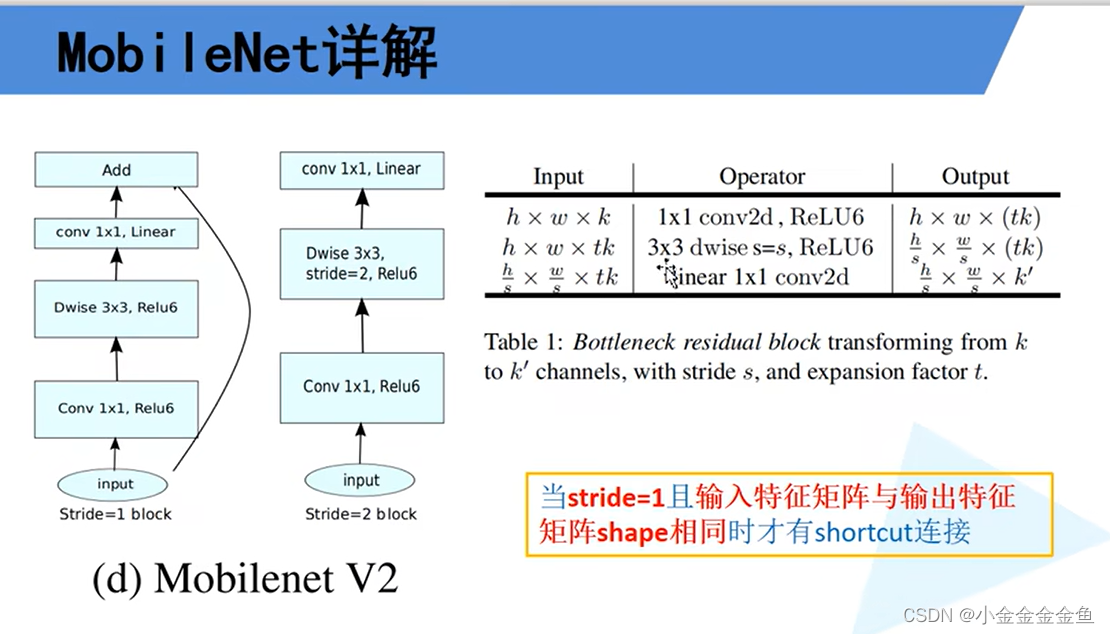
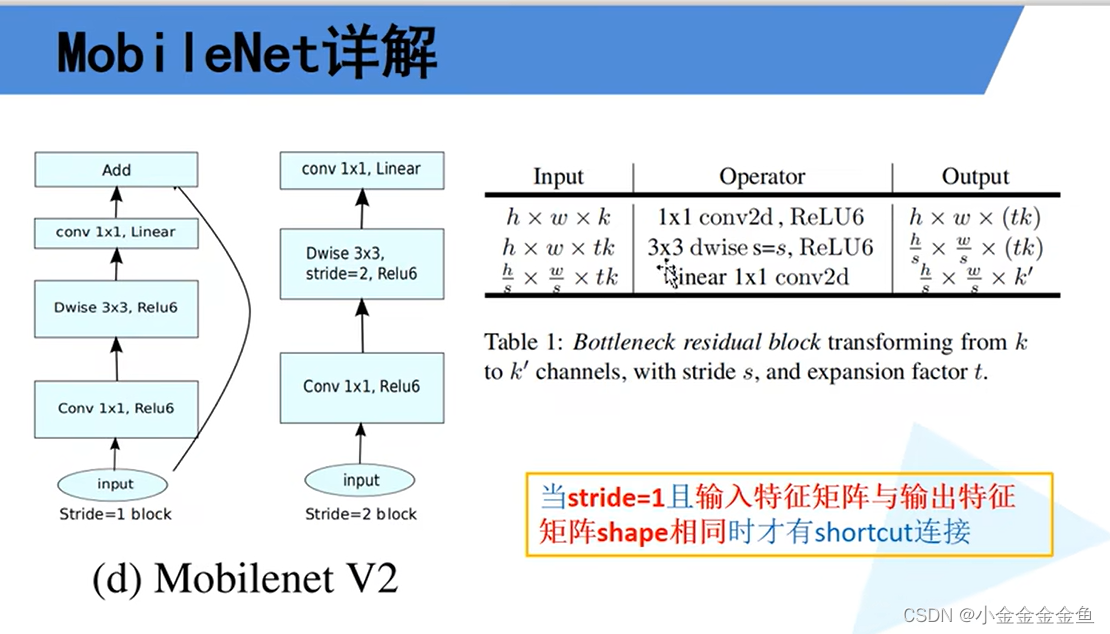
对于输入特征矩阵,高x宽x深度:
使用1*1卷积核(个数tk)进行升维处理,所以深度变为tk
↓
进行dw卷积:输出深度与输入深度一样
步距为s,输入特征矩阵的高和宽缩减为原来的1/s倍
↓
1x1的卷积层:采用降维操作,所采用的卷积核个数为k’,所以将特征矩阵的深度变为k’。
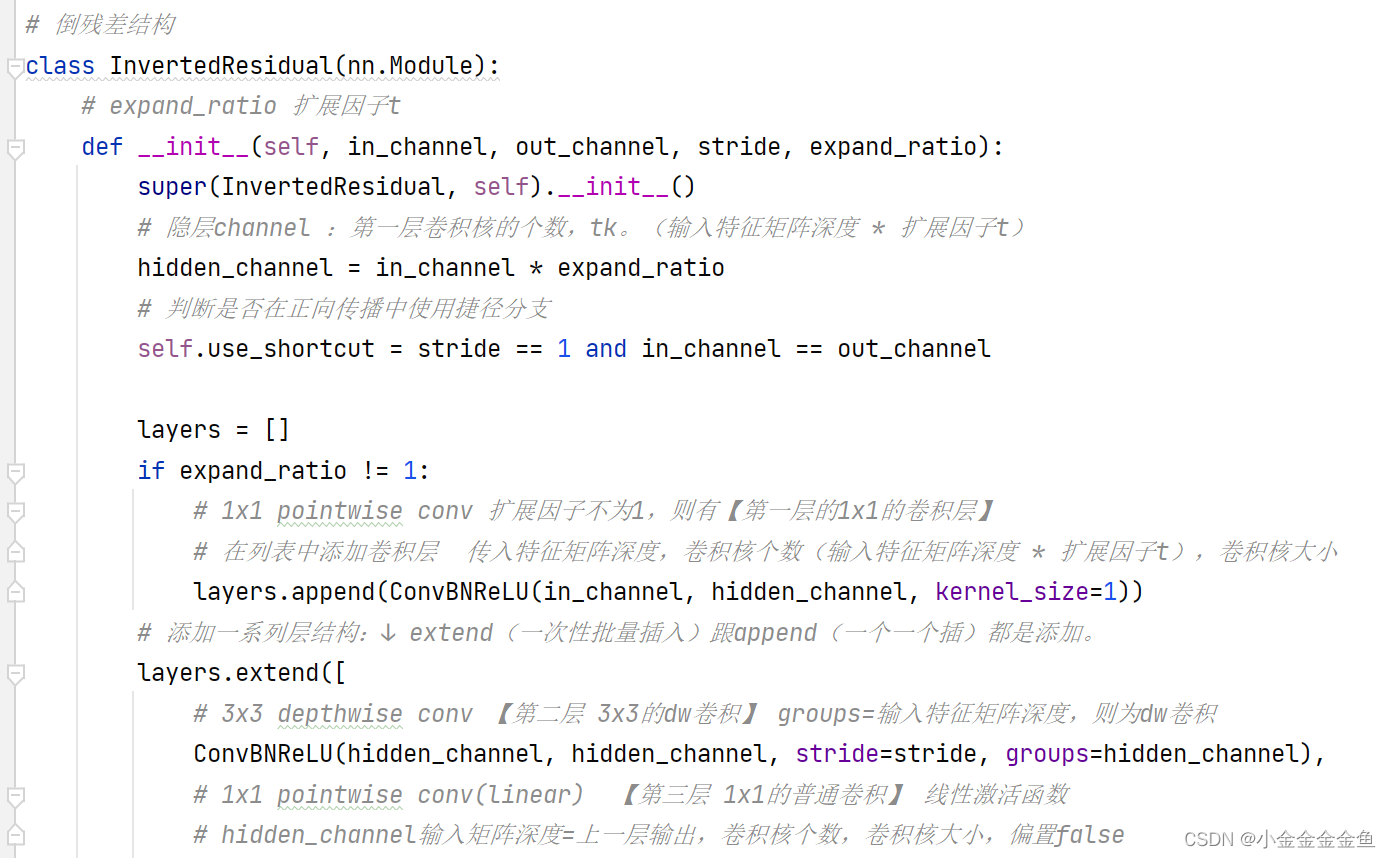
在MobileNetV2网络的到残差结构中,不是每一个倒残差结构中都有shortcut捷径分支(上图右下角框)

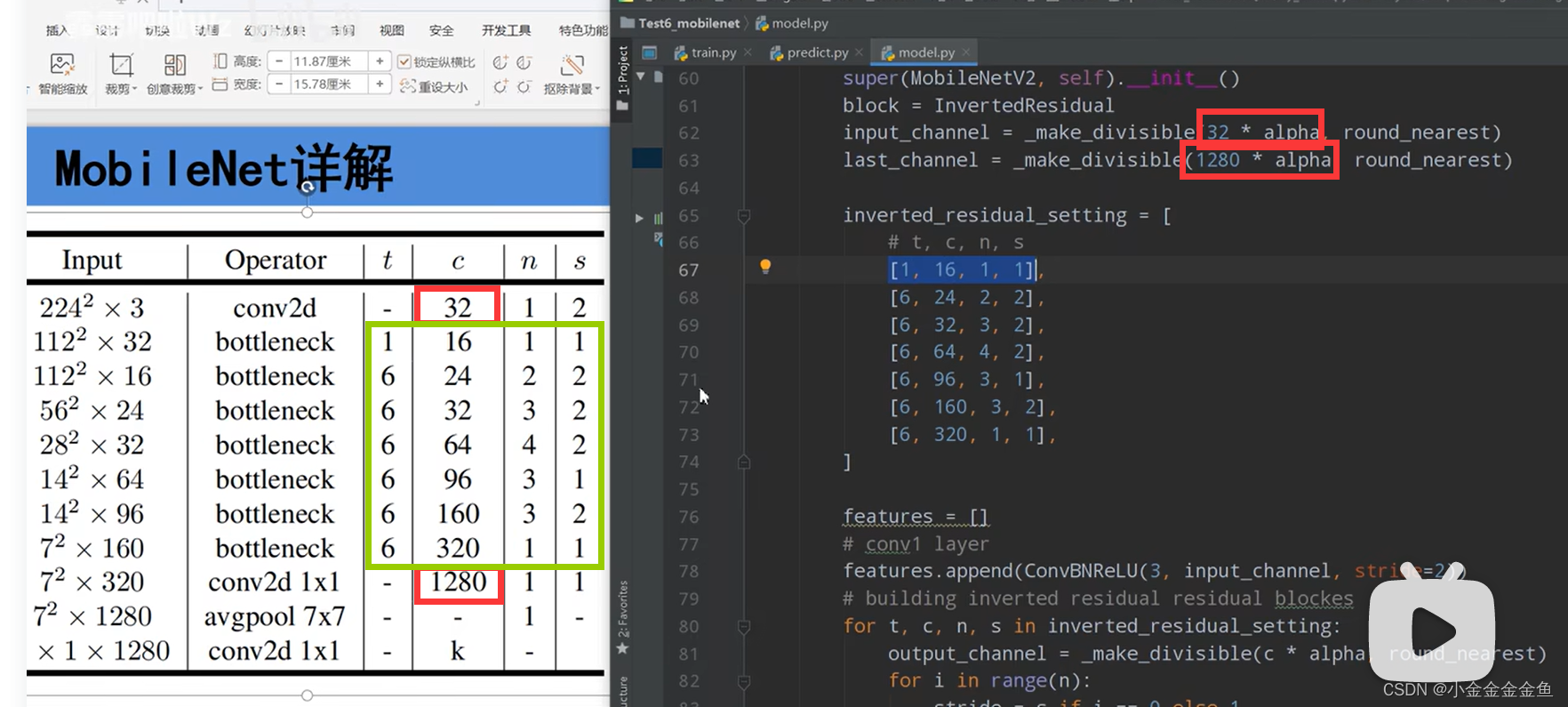
每一个block所对应的第一层的bottleneck的步距,其他的都是等于1。若n=2,则bottleneck重复两次,第一层的步距为表里那个s,第二层的就是1。
拓展因子:升维的倍速
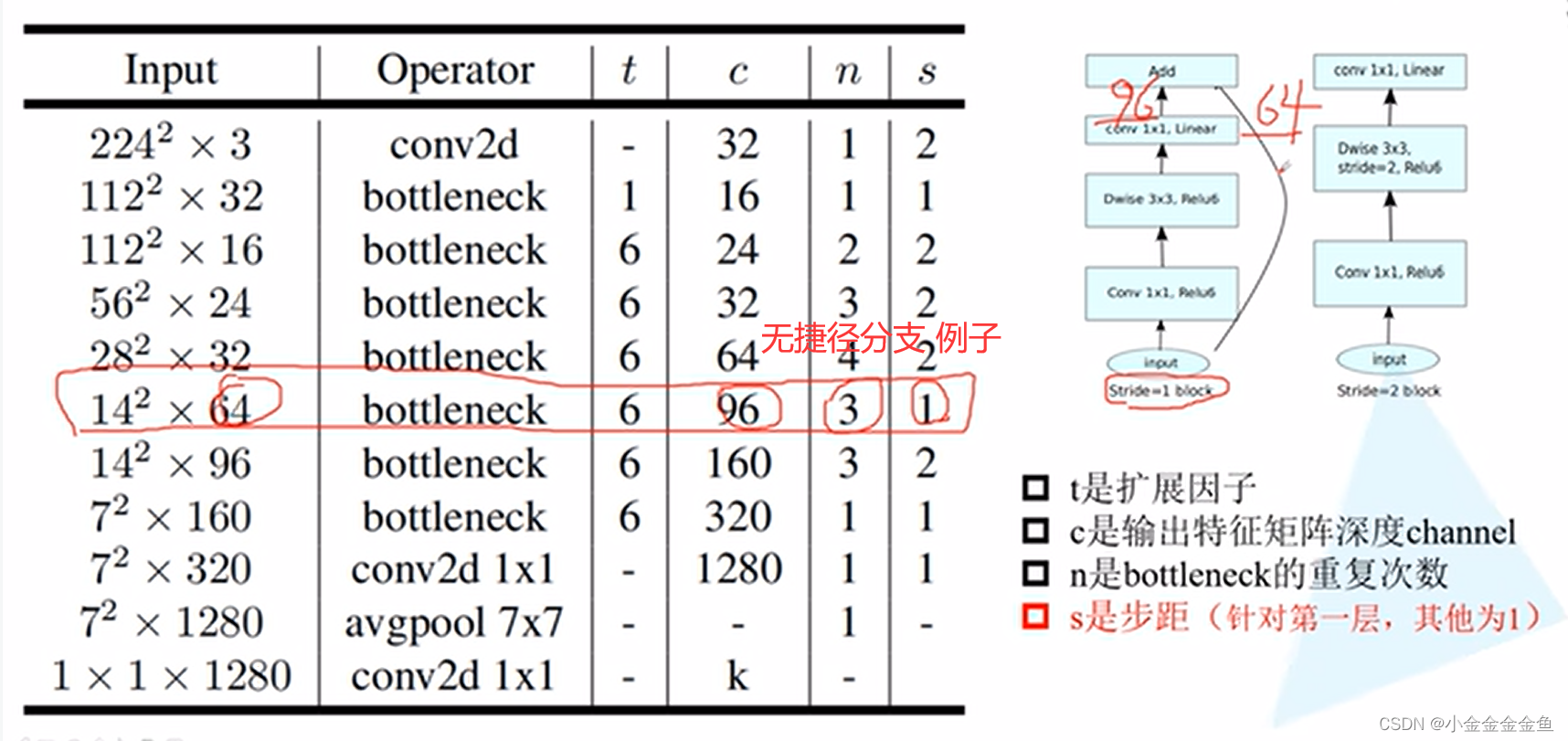
↓这个卷积层与全连接层的作用一样,k为分类个数

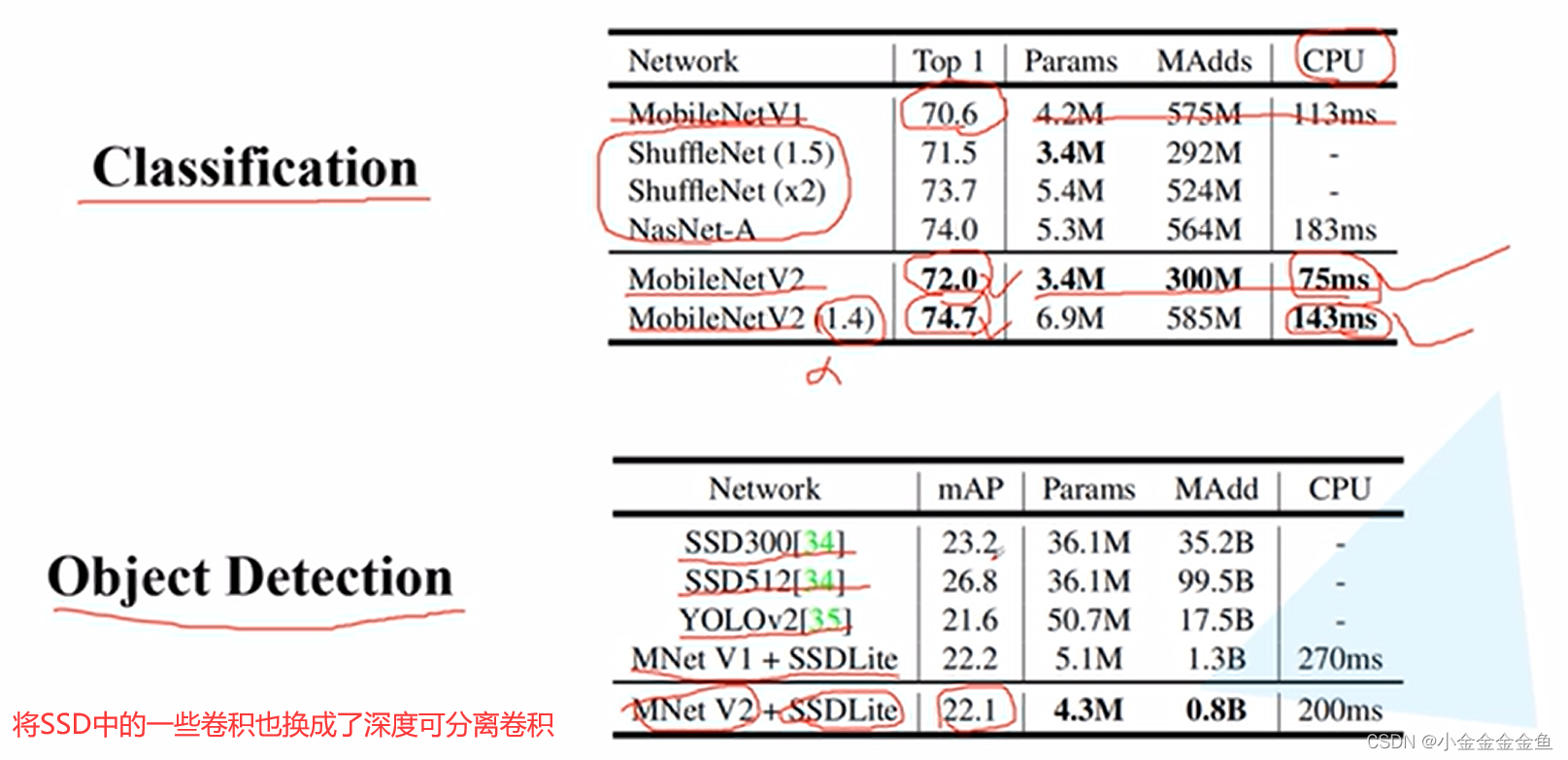
基本上已经实现,在移动设备以及嵌入设备上跑深度学习模型了。
使用pytorch搭建MobileNetV2并基于迁移学习训练
modelv2.py
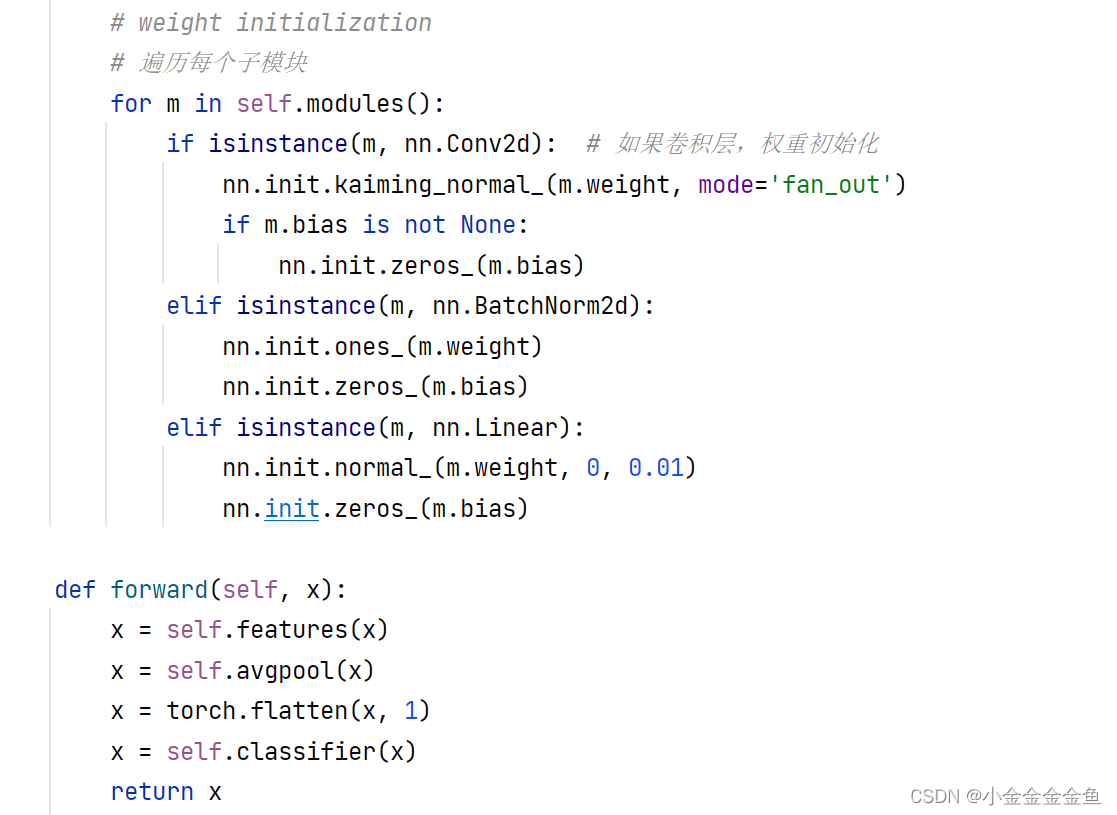
- 定义基础操作:
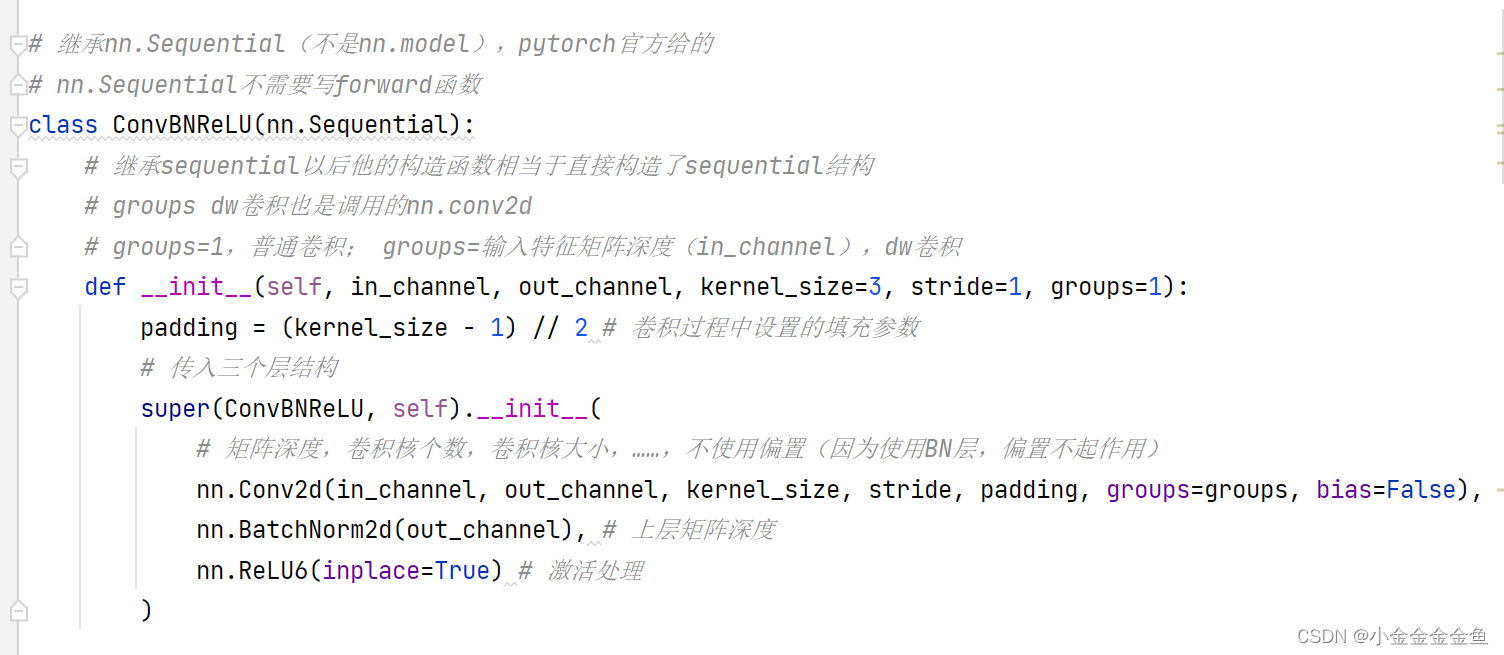
-
搭建倒残差结构
-
MobileNetV2网络结构



train.py
-
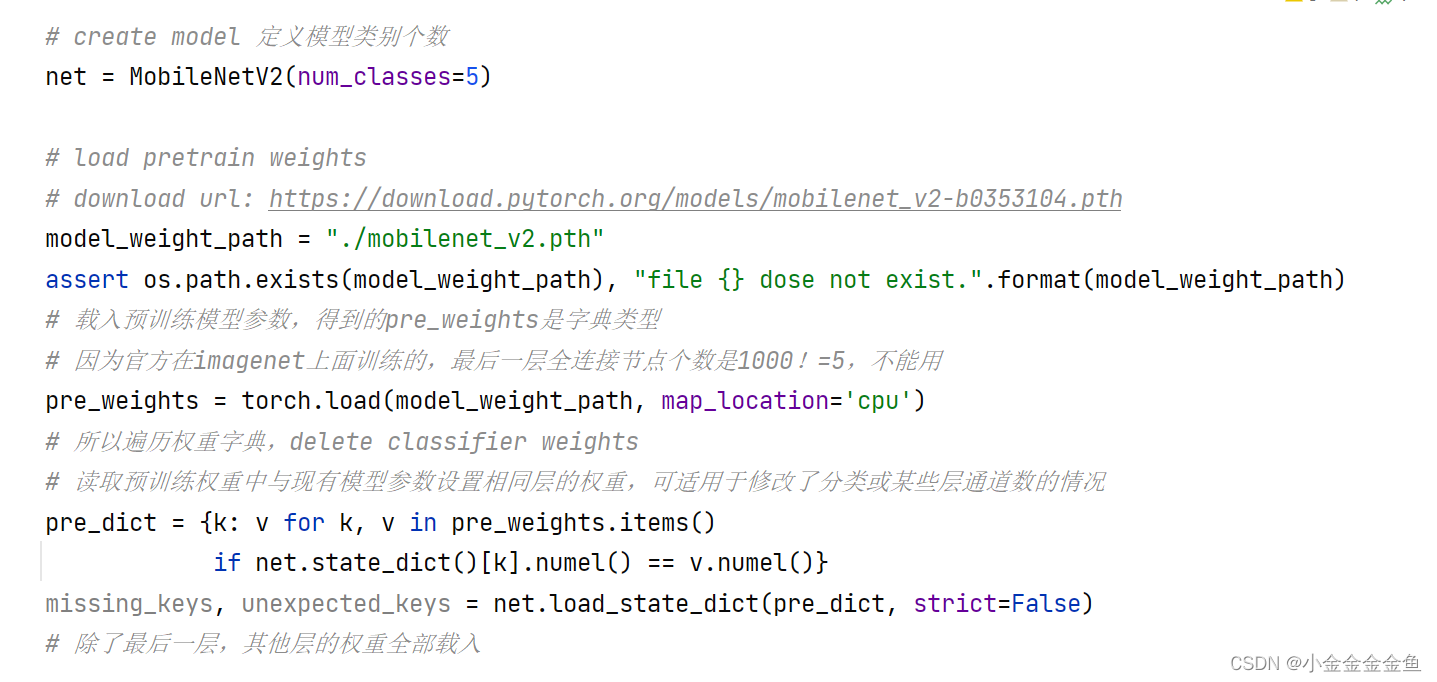
模型权重加载
下载预训练权重

与之前训练脚本不一样的地方: -
实例化模型

up训练时发现,同样都是调整最后一层,在CPU上训练,pytorch的速度比tensorflow慢得多。

↑ “理论上”
可能涉及到一些计算机底层的知识。
predict.py
使用与训练过程中相同的预处理方法
……
载入图片
……
添加batch维度
……
实例化模型
……
载入train.py中训练好的模型权重
……
禁止在预测过程中跟踪误差梯度信息
……
squeeze压缩batch维度
softmax 输出 → 概率分布
argmax 获取最大预测值所对应的索引





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结