您现在的位置是:首页 >学无止境 >神经网络语言模型(NNLM)网站首页学无止境
神经网络语言模型(NNLM)
简介神经网络语言模型(NNLM)
1 为什么使用神经网络模型?
- 解决
独热编码无法解决词之间相似性问题- 使用神经网络语言模型中出现的词向量 C w i C_{wi} Cwi代替
- C w i C_{wi} Cwi就是单词对应的 Word Embedding 值 【词向量】
- 解决
独热编码占用内存较大的问题
2 什么是神经网络模型?
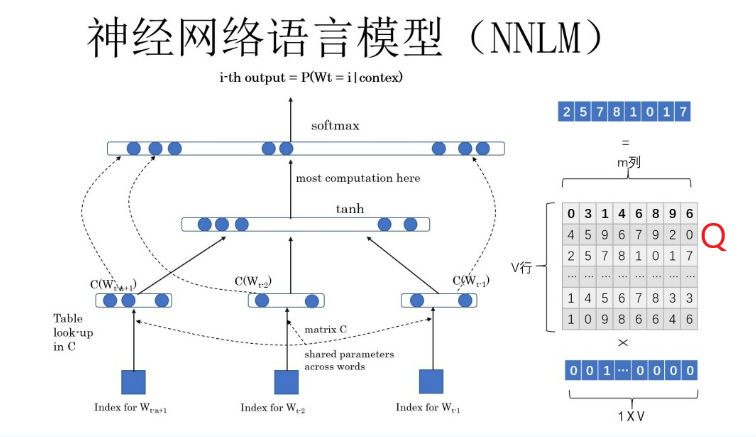
-
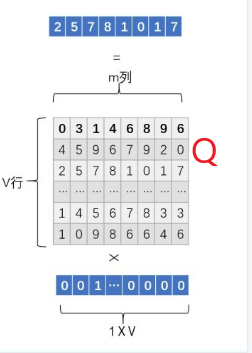
Q矩阵相关参数Q矩阵:从one-hot编码生成新的词向量Q矩阵是参数,需要学习训练,刚开始用随机值初始化Q矩阵,当这个网络训练好之后,Q矩阵的内容被正确赋值,每一行代表一个单词对应的Word embedding值参数 含义 Q Q Q V ∗ m V*m V∗m的矩阵,模型参数 V V V 词典大小,词的个数,有几个词就有几行 m m m 新词向量的大小
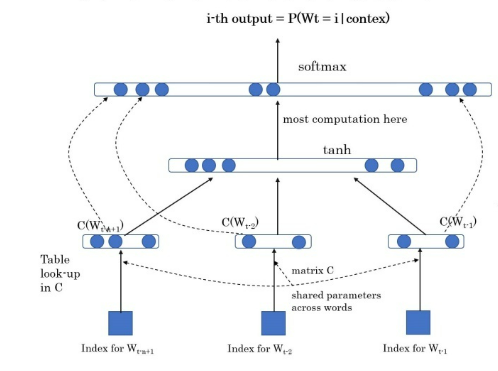
-
神经网络相关参数参数 含义 W W W word缩写,表示单词t t t target缩写,表示目标词【标签词】n n n 窗口大小,上下文的大小(即周围的单词有多少个)称为窗口大小C C C 就是Q 矩阵,需要学习的参数函数
- 举例:
-
文本:
You say goodbye and I say hello单词 index You0say1goodbye2and3I4hello5 -
窗口大小
n=2,t从2开始,下标从0开始contexts target contexts index target index [You ,say][goodbye][0,1][2][say ,goodbye][and ][1,2][3][goodbye, and][I][2,3][4][and, I][say ][3,4][1][I ,say][hello][4,1][5]
-
3. 代码实现
3.1 语料库预处理代码
def preprocess(sentences_list,lis=[]):
"""
语料库预处理
:param text_list:句子列表
:return:
word_list 是单词列表
word_dict:是单词到单词 ID 的字典
number_dict 是单词 ID 到单词的字典
n_class 单词数
"""
for i in sentences_list:
text = i.split(' ') # 按照空格分词,统计 sentences的分词的个数
word_list = list({}.fromkeys(text).keys()) # 去重 统计词典个数
lis=lis+word_list
word_list=list({}.fromkeys(lis).keys())
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # 词典的个数,也是softmax 最终分类的个数
return word_list, word_dict, number_dict,n_class

3.2 词向量创建
def make_batch(sentences_list, word_dict, windows_size):
"""
词向量编码函数
:param sentences_list:句子列表
:param word_dict: 字典{'You': 0,,,} key:单词,value:索引
:param windows_size: 窗口大小
:return:
input_batch:数据集向量
target_batch:标签值
"""
input_batch, target_batch = [], []
for sen in sentences_list:
word_repeat_list = sen.split(' ') # 按照空格分词
for i in range(windows_size, len(word_repeat_list)): # 目标词索引迭代
target = word_repeat_list[i] # 获取目标词
input_index = [word_dict[word_repeat_list[j]] for j in range((i - windows_size), i)] # 获取目标词相关输入数据集
target_index = word_dict[target] # 目标词索引
input_batch.append(input_index)
target_batch.append(target_index)
return input_batch, target_batch
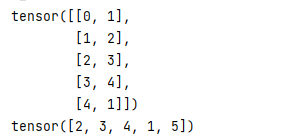
3.3 NNLM模型类
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m) # 矩阵Q (V x m) V 表示word的字典大小, m 表示词向量的维度
self.H = nn.Linear(windows_size * m, n_hidden, bias=False) #
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(windows_size * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
X = self.C(X) # X : [batch_size, n_step, m]
X = X.view(-1, windows_size * m) # [batch_size, n_step * m]
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
3.4 完整代码
import torch
import torch.nn as nn
import torch.optim as optim
def preprocess(sentences_list,lis=[]):
"""
语料库预处理
:param text_list:句子列表
:return:
word_list 是单词列表
word_dict:是单词到单词 ID 的字典
number_dict 是单词 ID 到单词的字典
n_class 单词数
"""
for i in sentences_list:
text = i.split(' ') # 按照空格分词,统计 sentences的分词的个数
word_list = list({}.fromkeys(text).keys()) # 去重 统计词典个数
lis=lis+word_list
word_list=list({}.fromkeys(lis).keys())
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # 词典的个数,也是softmax 最终分类的个数
return word_list, word_dict, number_dict,n_class
def make_batch(sentences_list, word_dict, windows_size):
"""
词向量编码函数
:param sentences_list:句子列表
:param word_dict: 字典{'You': 0,,,} key:单词,value:索引
:param windows_size: 窗口大小
:return:
input_batch:数据集向量
target_batch:标签值
"""
input_batch, target_batch = [], []
for sen in sentences_list:
word_repeat_list = sen.split(' ') # 按照空格分词
for i in range(windows_size, len(word_repeat_list)): # 目标词索引迭代
target = word_repeat_list[i] # 获取目标词
input_index = [word_dict[word_repeat_list[j]] for j in range((i - windows_size), i)] # 获取目标词相关输入数据集
target_index = word_dict[target] # 目标词索引
input_batch.append(input_index)
target_batch.append(target_index)
return input_batch, target_batch
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m) # 矩阵Q (V x m) V 表示word的字典大小, m 表示词向量的维度
self.H = nn.Linear(windows_size * m, n_hidden, bias=False) #
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(windows_size * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
X = self.C(X) # X : [batch_size, n_step, m]
X = X.view(-1, windows_size * m) # [batch_size, n_step * m]
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
if __name__ == '__main__':
m = 2 # 词向量的维度
n_hidden = 2 # 隐层个数
windows_size = 2
sentences_list = ['You say goodbye and I say hello'] # 训练数据
word_list, word_dict, number_dict,n_class=preprocess(sentences_list)
print('word_list为: ',word_list)
print('word_dict为:',word_dict)
print('number_dict为:',number_dict)
print('n_class为:',n_class)
#
input_batch, target_batch = make_batch(sentences_list, word_dict, windows_size) # 构建输入数据和 target label
# # 转为 tensor 形式
input_batch,target_batch = torch.LongTensor(input_batch), torch.LongTensor(target_batch)
print(input_batch)
print(target_batch)
model = NNLM()
# 损失函数定义
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
# 采用 Adam 优化算法 学习率定义为 0.001
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training 迭代 2000次
for epoch in range(2000):
optimizer.zero_grad() # 梯度归零
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 250 == 0:
print('Epoch:', '%d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() # 反向传播计算 每个参数的梯度值
optimizer.step() # 每一个参数的梯度值更新
# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1]
print(list(predict))
# Test
print([number_dict[n.item()] for n in predict.squeeze()])

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结