您现在的位置是:首页 >技术杂谈 >【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型网站首页技术杂谈
【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型
论文地址:https://arxiv.org/pdf/2203.13474.pdf?trk=public_post_comment-text
相关博客
【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型
【自然语言处理】【大模型】CodeGeeX:用于代码生成的多语言预训练模型
【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型
【自然语言处理】【大模型】DeepMind的大模型Gopher
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
一、简介

程序合成(program synthesis)的目标是自动化编程过程,从而生成能够满足用户意图的计算机程序。程序合成面临两个关键的挑战:(1) 搜索空间难以处理;(2) 难以确定用户意图。为了解决搜索空间的问题,本文将程序合成任务形式化为语言建模过程,即基于前面的tokens预测下一个token的条件概率分布。
程序合成需要理解用户的意图。用户通常通过逻辑表达式、伪代码、输入-输出示例、或者自然语言表达意图。逻辑表达式和伪代码通常需要用户具有相关领域知识,成本比较高。输入-输出示例的代价更低一些,但可能没办法准确传递用户意图。因此,作者认为自然语言表达用户意图的最好形式。
本文提出了多轮程序合成方法,用户通过自然语言来逐步与合成系统进行沟通。采用多轮的方式有两个动机:
- 将长且复杂的用户意图分解为多个步骤,简化模型理解,从而增强程序合成。在多轮的方法中,模型可以专注在与子程序相关的意图上,避免费力的跟踪子程序之间复杂的依赖关系。
- 通常,代码会存在自然语言与编程语言交错的弱模式。这种模式就是通过程序员为代码添加注释形成的。使用语言建模的目标函数,这种交错模式可以为多轮程序合成提供弱监督信号。这种信号通常是有噪音且比较弱的,因此仅有部分数据有这种模式且注释可能不正确或者信息量不足。扩大模型和数据的规模可能会克服这种弱监督的不足。
本文还提出了一个多轮程序合成基准来衡量模型的多轮程序合成能力。针对该基准中的问题,模型需要多个步骤来合成程序,每个步骤都需要用户使用自然语言来指定意图。上图展示了一个从邮件地址抽取用户名的合成过程。
本文采用语言模型进行程序合成的基础想法。此外,还有4方面的贡献:
- 研究了自回归模型在scaling law下多轮程序合成的涌现;
- 利用这个能力引入了多轮程序合成范式;
- 利用一个新颖的多轮编程基准来定量研究其性质;
- 开源了模型的checkpoints以及自定义的训练库JAXFORMER;
对于程序合成,没有开源的大模型能够与Codex竞争。这阻碍了进步,考虑到训练这些模型需要的昂贵计算资源,仅有少量的机构可以使用。本文的开源贡献允许广大的研究者学习和改进这些模型,这极大的促进了研究的进步。
二、模型训练
模型采用标准的基于transformer的自回归语言模型,仅对模型参数量和训练语料的token数量进行改变动
1. 数据集
CodeGen模型族会在三个数据集上顺序训练:THEPILE、BIGQUERY和BIGPYTHON。
THEPILE是一个用于语言建模的825.18GB英文数据集。该数据集是基于22个高质量子集构造的,其中一个是从GitHub上收集的编程语言数据,占整个数据集的7.6%。基于该数据集训练的模型称为自然语言CodeGen模型(CodeGen-NL)。
多语言数据集BIGQUERY是Google公开数据集BigQuery的子集,其是由多种编程语言构成的。选择6种编程语言C、C++、Go、Java、JavaScript和Python进行多语言训练。称在BIGQUERY上训练的模型为多语言CodeGen模型(CodeGen-Multi)。
单语言数据集BIGPYTHON包含了大量python的数据。该数据集中包含了至2021年10月的公开、可获取且非个人的python代码。称在BIGPYTHON上训练的模型为单语言CodeGen模型(CodeGen-Mono)。
数据预处理:(1) 过滤;(2) 去重;(3) tokenization;(4) shuffling;(5) 拼接。
2. 模型
CodeGen使用自回归形式的transformer在自然语言和编程语言数据集上进行训练。模型尺寸包括:350M、2.7B、6.1B和16.1B。前3种尺寸允许直接与开源的大语言模型进行比较,GPT-NEO(350M,2.7B)和GPT-J(6B)。
CodeGen在数据集上按顺序训练。CodeGen-NL在THEPILE上第一个训练;CodeGen-Multi使用CodeGen-NL进行初始化,并在BIGQUERY上训练;CodeGen-Mono使用CodeGen-Multi进行初始化,并在BIGPYTHON上训练。
基于自然语言描述为条件的程序合成能力涌现,可能来源于模型和数据的尺寸、训练目标函数和训练数据本身。之所以称为"涌现",是因为没有在"注释-代码对"数据上进行训练。在自然语言任务上也观察到类似的现象,大规模无监督语言模型可以通过zero-shot的方式来解决未见过的任务。
三、单轮评估
现有程序合成基准 HumanEval包含164个手写Python编程问题。每个问题都会提供一段自然语言的prompt以及函数的签名和示例测试用例。模型需要根据prompt来补全函数,且该函数需要通过所有的测试用例。因为用户的意图被指定在单个prompt内并一次性提供给模型,将HumanEval看作是单论评估,以区别于后续的多轮评估。
1. HumanEval的效果是模型尺寸和数据尺寸的函数
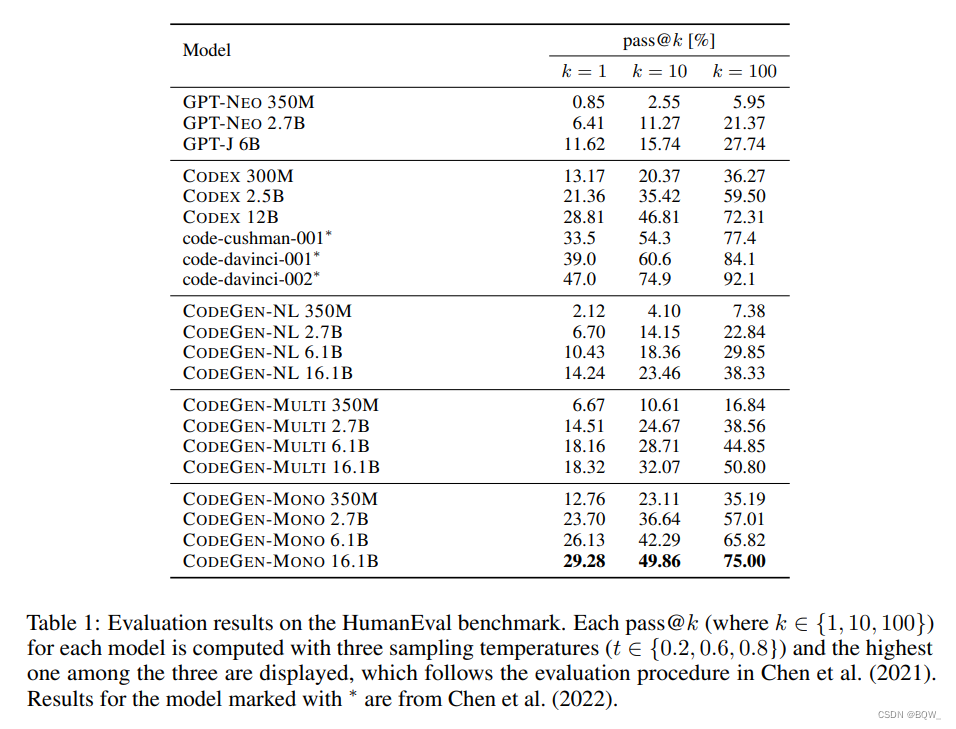
比较在HumanEval上的SOTA方案。此外,还比较了开源大语言模型GPT-NEO、GPT-J。这些大模型都是在THEPILE上训练的,因此类似于CodeGen-NL模型。
结果如上表1所示。CodeGen-NL模型优于或者相当于GPT-NEO和GPT-J模型。GodeGen-Multi大幅度超越了GPT-NEO、GPT-J和CodeGen-NL。在纯Python数据集上的微调模型CodeGen-Mono,程序合成能力显著改善。
2. 更好的用户意图理解可以产生更好的合成程序
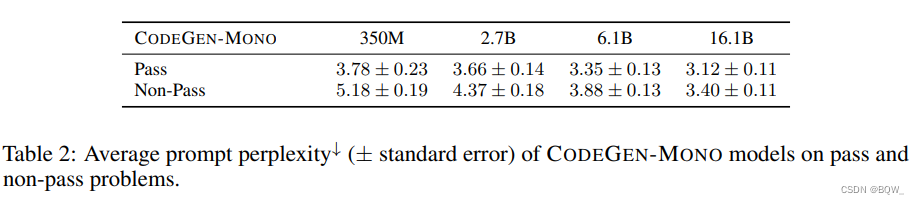
成功的程序合成系统高度的依赖于其是否很好的理解了用户意图。因为系统是基于语言模型的,prompt的困惑度可以作为系统对用户意图理解的一种代理。一个用户意图在模型下具有低困惑度,则用户描述的意图与模型预训练数据学习到的知识相兼容。
具体来说,将所有的问题划分为pass与non-pass。pass问题表示,200个样本中至少有一个样本通过了所有的测试用例;non-pass则是200个样本中没有样本能通过所有的测试用例。基于CodeGen-Mono模型,计算所有pass问题的平均困惑度,以及no-pass问题的困惑度。如上表2所示,pass问题要比non-pass问题具有更低的困惑度。这意味着,当用户的意图被模型更好的理解后,程序合成的效果会更好。
四、多轮评估
本小节提出并研究了多轮程序合成范式。程序合成被分解为多个步骤,合成系统在每个步骤中完成子程序的合成。为了测试这种范式,开发了新基准Multi-Turn Programming Benchmark(MTPB)。MTPB包含115个问题,每个问题包含多步骤自然语言描述。
1. 基准构造
本文的4位作者定义了115个问题。这些问题需要各种编程知识,包括:数学、数组操作、字符串操作、算法、数据科学等,这样每个类图的问题大致平衡。每个问题都构建一个三元组,包含:多轮的prompt P P P、测试用例的输入 I I I、测试用例的输出 O O O。设计多轮prompt P P P需要遵循两个约束:(1) 问题被分解为至少3轮;(2) 单轮无法解决这个问题。每个问题的作者都需要准备5个测试用例的输入 I I I和输出 O O O。
HumanEval要求补全部分定义的函数,而MTPB仅通过prompts,因此模型必须从头生成解决方案。这种自由形式的生成允许更有潜力的解决方案,但是需要模型能够生成测试用例输入的入口。例如,prompt:“Define a string named ‘s’ with value {var}”,测试用例输入var = 'Hello'将被形式化为"Define a string named ‘s’ with the value ‘Hello’"。
2. 多步编程能力随模型大小和数据大小而改变
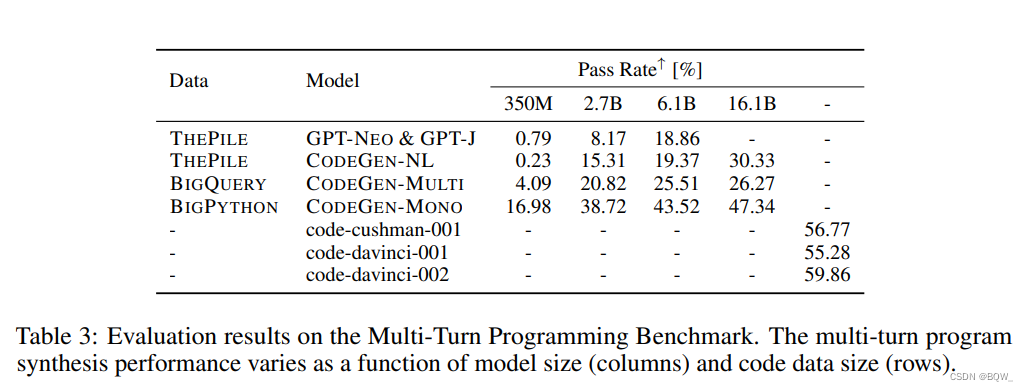
4. 通过多轮分解更好的理解用户意图

本文假设多轮分解能够增强模型理解用户意图的能力,并带来更好的程序合成能力。为了测试这个假设,我们通过拼接的方式将多轮指令形式化为单轮的形式。仍然使用prompt困惑度作为用户意图理解的代理。因此,比较了4个CodeGen-Mono模型在单轮和多轮prompt的困惑度。
上表4展示了单轮prompt和多轮prompt的困惑度(左)和通过率(右)。所有单轮的困惑度都比多轮的高,意味着多轮的方式能够更好的理解用户的意图。多轮方式的通过率比单轮高平均百分之十个点。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结