您现在的位置是:首页 >技术交流 >ICLR‘22论文解读 Coordination Among Neural Modules Through a Shared Global Workspace网站首页技术交流
ICLR‘22论文解读 Coordination Among Neural Modules Through a Shared Global Workspace
ICLR’22论文解读 Coordination Among Neural Modules Through a Shared Global Workspace
成电研一er本周论文详细解读
全文1w字+,请耐心阅读,望对你的研究有所帮助!
Coordination Among Neural Modules Through a Shared Global Workspace基本信息
论文下载链接:https://arxiv.org/abs/2103.01197v2
发布时间信息:
[v1] Mon, 1 Mar 2021 18:43:48 UTC (2,119 KB)
[v2] Tue, 22 Mar 2022 21:31:37 UTC (2,678 KB)
摘要
深度学习已经从用单一隐藏状态表示示例的方法转向了使用丰富结构化状态的方法。例如,Transformer通过位置进行分段,面向对象的架构将图像分解为实体。在所有这些架构中,不同元素之间的交互通过成对交互进行建模:Transformer利用自注意力来将来自其他位置的信息合并,面向对象的架构利用图神经网络来建模实体之间的交互。我们考虑如何通过全局协调和一致的综合表示来改进成对交互,以便用于下游任务。在认知科学中,提出了一种全局工作空间架构,其中功能专业化的组件通过一个共享的、带宽有限的通信通道共享信息。我们探讨了在深度学习中使用这种通信通道来模拟复杂环境的结构的方法。所提出的方法包括一个共享的工作空间,不同的专业模块之间通过它进行通信,但由于通信带宽的限制,专业模块必须争夺访问权。我们表明,容量限制具有合理的基础,因为(1)它们鼓励专业化和组合性,(2)它们促进了本来独立的专家的同步。
1.引言
深度学习已经朝着更加结构化的模型方向发展,不同信息被不同组件处理并分离开来。这种引入的结构和知识分离提高了泛化能力、模型规模扩展以及长程依赖性(Berner等,2019; Vinyals等,2019; Brown等,2020)。这也引发了如何在这种架构中实现不同组件之间的协调和统一性的问题。回顾到上个世纪80年代,AI的关注点不是在学习上而是在构建多组件体系结构上,并研究智能是如何从这些简单、功能专一的组件相互作用中产生的(Fodor,1983; Braitenberg,1986; Minsky,1988; Brooks,1991)。这些专业模块中的每一个都是计算机程序的典型组件,就像一个子程序,它实现了从特定的输入内容到特定的输出内容的一个狭窄的、预先指定的功能。通过适当的通信和协调,一组专家可以实现复杂、动态和灵活的行为模式。
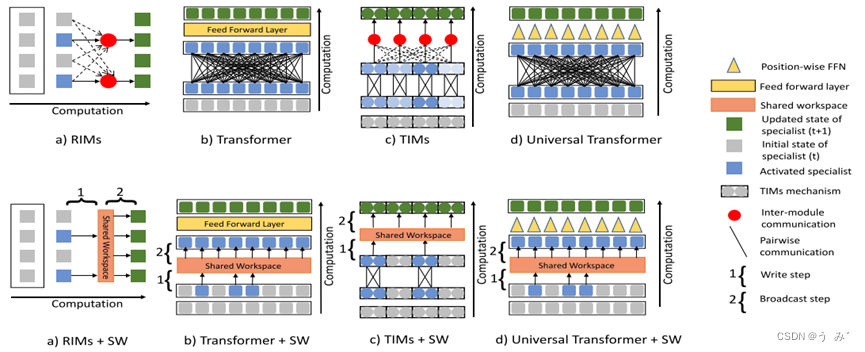
图1:
步骤1:一组专门模块执行它们自己的默认处理; 在特定的计算阶段,专家的子集根据输入变得活跃。 步骤2:活跃的专家可以在共享的全局工作区中写入信息。 步骤3:向所有专家广播工作区的内容。
举个具体的例子,考虑一下专家驾驶汽车的任务。一个专家可能会根据道路上的线路监控汽车的位置,另一个专家可能会根据感知数据调整驾驶方向。此外,当某些事件发生时,比如响亮的声音,到达路线上的关键十字路口,或接近前面的汽车时,可能会有专家提供警报。为了正确地执行驾驶汽车的任务,所有这些专家需要协调地交互,并相互传播各自的信息。
可以说,现代ML和人工智能尚未开发出广泛的体系结构框架,用于学习专业模块以及它们应该如何交互,而经典观点缺乏一个清晰的故事,说明如何在这些框架中成功地进行学习。在本文中,我们将利用基于端到端学习、可微记忆和注意力机制的现代机器学习工具,重新审视这一经典观点。受认知神经科学中的全局工作空间理论的启发(Baars,1993; Dehaene et al.,1998; Shanahan and Baars,2005; Shanahan,2006; 2010; 2012; Dehaene et al.,2017),我们认为,如果专家的训练鼓励他们通过共享工作空间的瓶颈有效地相互通信,那么专家系统的架构将产生更大的灵活性和泛化能力。(如图1)。
1.1 分布式专家模块
从计算的角度来看,由稀疏相互作用的专家模块组成的复杂多组件架构具有良好的可扩展性(例如,可以无缝添加更多的专家模块)、更高的鲁棒性(系统可以容忍个别专家模块的删除或更改)和更高的效率(信息主要在本地处理,减少了专家模块之间通信的成本)。但是,模块化还需要建立跨专家模块之间的共享兼容表示形式的机制,这是一种共享的内部语言。 虽然任务的某些部分可能会由独立的专家模块解决,但当专家模块之间存在统计、功能或因果依赖关系时,同步是至关重要的。
1.2 通过共享的工作空间实现一致性
共享工作空间的一致性。在认知神经科学中,全局工作空间理论(GWT)(Baars,1993;Dehaene等,2017)提出了一种允许专家模块之间相互作用的架构。 GWT的关键观点是存在一个共享表示,有时称为黑板,有时称为工作空间,可以被任何专家模块修改,并且将被广播到所有专家模块,同时写入访问受限以保持一致性。 我们对写访问限制的解释是,它源于高级概念之间联合分布的一种假设。在本文中,我们探讨了一种类似于GWT提出的通信和协调方案,适用于现代神经网络架构,如Transformer(Vaswani等,2017;Dehghani等,2018;Parmar等,2018;Radford等,2019;Brown等,2020)和基于注意力的模块化架构(Goyal等,2019;Rahaman等,2020;Mittal等,2020a;Goyal等,2020;Madan等,2021)。
在我们的示例中,工作空间可以用于通过优先考虑提供各种警报的专家模块(响亮的声音、街上有孩子的存在)来覆盖默认行为,从而允许响应此类警报的专家模块接管行为,以取代默认的驾驶例程。这种情况意味着在共享工作空间中对信号进行优先级排序至关重要。
1.3 共享的通信通道需要通用的表示
要让众多的专业模块进行合作,需要一种共同的语言(Baars, 1997)。例如,在驾驶场景中,警报可能来自听觉或视觉处理专家,但无论来源如何,都必须在工作空间中放置危险信号,以覆盖默认行为,无论该行为是由无线电调谐专家还是驾驶专家控制的。虽然专业模块可以预先连接到兼容的通信接口上,但我们将对一个体系结构进行建模,在这个体系结构中,一组专业模块经过协调训练,这应该会导致一种共享的语言(Colagrosso和Mozer, 2005)。在内部,个别专家可以使用为他们服务的任何形式的表示,但他们的输入和输出需要与其他专家保持一致,以便同步。例如,一个不寻常的事件,比如车轮下的重击声,可能之前没有经历过,但仅仅是新奇的信号就可能压倒违约专家。如果没有一个全局沟通渠道,专家们将不得不学习通过两两互动进行沟通,这可能会限制在新情况下的行为协调:全局沟通确保了知识的可交换性,以实现系统的泛化。
图2: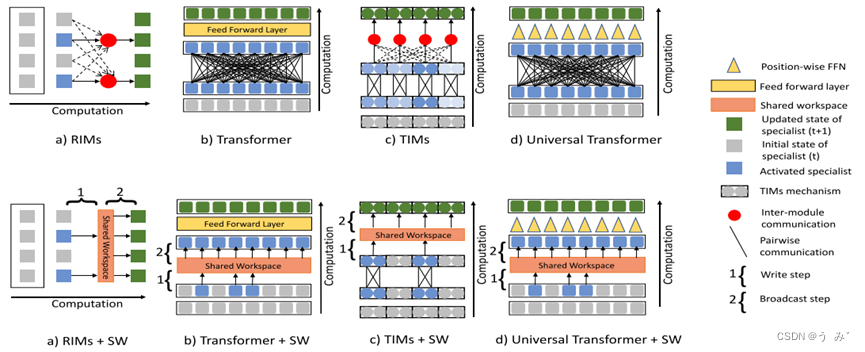
图2:使用共享工作区在RIMS、Transformers、TIMS和Universal Transformers (UT)中创建全局一致性。 (上半部分)所有这四个架构都使用成对通信(使用关键值关注)来建立各个专业模块之间的一致性。在RIMS(Goyal et al.,2019)和TIMS(Lamb et al.,2021)中,这些专家是相互竞争的独立模块,不同的专家模块在输入数据的基础上进行竞争,以确定哪个模块将控制状态更新。在Transformers(Vaswani et al.,2017)和Universal Transformers(Dehghani et al.,2018)的案例中,每个专家模块都与不同的位置相关联。激活的专家用蓝色阴影表示,强度取决于激活的程度。 在Universal Transformers的情况下,每个位置的状态更新动态在所有层和所有位置上共享(用黄色三角形表示)。(下半部分)我们用一个共享的工作空间来代替两两交流,从而在不同的专家之间建立全局一致性。使用共享工作区的通信是一个两步过程(如图中1和2所示)。 在第一步(1)中,专家争夺对共享工作区的写访问权,导致其中的一个子集被激活(蓝色),并且只有被激活的专家在工作区上执行写操作。 在第二步(2)中,共享工作区的内容被广播给所有专家。
2.通过共享工作空间同步神经模块
我们研究了一种神经结构,类似于GW模型,其中多个稀疏通信的专业模块通过共享的工作记忆进行交互。特别地,我们通过添加共享工作空间并允许模块(每个代表一个实体)在每个计算阶段竞争写入访问来扩展Transformer(Vaswani等人,2017)、注意力和基于插槽的模块化结构(Goyal等人,2019)。
键值注意力是该模型中隐藏状态更新的核心。这种注意力广泛用于自我注意力模型,并在各种任务中表现出色(Bahdanau等人,2014;Vaswani等人,2017;Santoro等人,2018)。键值注意力基于查询向量与每个值关联的键向量的匹配选择输入值。为了允许微分,从而更易于学习,选择是软性的,并计算所有值的凸组合。这种机制使得可以动态改变输入来源和共享工作空间的更新方式。它还使得专业人员的输出和记忆元素成为置换不变量:它们应该被视为从专业人员的内容中由注意力机制选择的一个无序元素集合。更确切地说,软性注意力使用查询的乘积(表示为维度为 N r × d Nr×d Nr×d的矩阵Q,其中 N r Nr Nr个查询, d d d是每个查询的维度)与每个对象相关联的键作为矩阵 K T K^T KT ( N o × d ) (No×d) (No×d)中的一行。经过softmax标准化后,得到的凸权重用于合并值Vi(矩阵V的第i行):softmax应用于其参数矩阵的每一行,产生一组凸权重。在我们的实验中,我们使用多头点积注意力。
2.1 神经模块的成对交互
我们的神经模块同步方法非常通用,几乎不受任务、领域或特定架构的限制,唯一的要求是模型由多个专业模块组成,它们要么独立操作,要么具有仅需成对匹配模块的稀疏交互。我们的目标是探索如何引入共享工作空间可以帮助这些模块变得更好地同步和协调。我们展示了共享工作空间在同步方面的实用性,包括(a) Transformers(Vaswani等人,2017),在这种情况下,位置之间的所有交互都是通过注意力完成的,以及(b) 类似于RIM(Goyal等人,2019)的基于插槽的架构,其中所有模块之间的成对交互都是通过注意力完成的。在基于插槽的架构中,每个插槽的内容与一个专业模块相关联,而在Transformers中,与不同位置相关联的不同实体充当专业模块(图2)。
Transformers和RIMs都利用自注意机制在模块之间共享信息,通常以成对的方式实现,即每个专业模块都关注其他每个专业模块。相反,我们通过一个容量有限的共享工作空间来促进专业模块之间的信息共享。在这个框架中,在每个计算阶段,不同的专业模块竞争访问共同的工作空间。而工作空间的内容则同时广播到所有专业模块。
2.2 符号表示
输入经过一系列计算阶段进行处理,这些阶段由
t
t
t索引,每个阶段都对
n
s
n_s
ns个实体进行操作(例如,在基于插槽的体系结构(如RIM)中有
n
s
n_s
ns个不同的模块,在Transformer的情况下有
n
s
n_s
ns个不同的位置[即
n
s
n_s
ns个token])。这些
n
s
n_s
ns个专家模块中的每一个都具有不同的内部
n
h
n_h
nh维状态
h
t
k
h_t^k
htk,其中
k
∈
1
,
.
.
.
,
n
s
k∈{1,...,n_s}
k∈1,...,ns。专家模块通过共享的工作空间相互通信,该空间被分为
n
m
n_m
nm个内存插槽,每个插槽包含一个包含
n
l
n_l
nl个元素的向量,表示为M = [
m
1
m_1
m1; . . .
m
j
m_j
mj; . . .
m
(
n
m
)
m_(n_m)
m(nm)] 。共享工作空间在不同的计算阶段更新,即在递归体系结构中的不同时间步长和在Transformer的不同层中。在每个计算阶段t中,不同的专家模块竞争写入共享工作空间,但所有专家模块都可以从当前状态的工作空间中读取。对于自回归任务,我们可以将信息共享限制在前面的位置,并为每个位置保留单独的工作空间版本。
理解 :对于transformer而言,每一个encoder层都会进行一次共享工作空间的更新。
n
m
n_m
nm行,
n
l
n_l
nl列的共享空间
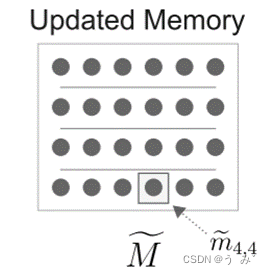
2.3 三个步骤
步骤1:处理输入以获取每个专家的实体表示
第一步是提议方法之外的内容,它涉及处理输入以形成不同专家的初始表示向量。可以使用不同的常见深度学习架构来形成不同专家的表示。例如,Transformers从一个矩阵 n s × n h n_s×n_h ns×nh开始,其行被初始化为序列每个位置的 n h n_h nh维嵌入。基于插槽的递归架构(如RIMs)由单层递归结构组成,在计算阶段t的隐藏状态 h t h_t ht被分解为 n s n_s ns个专家的子状态 h t k ( k = 1 , . . . , n s ) h_t^k(k=1,...,n_s) htk(k=1,...,ns)。
在提议的方案中,在每个计算阶段内,不同专家的隐藏状态更新遵循两个步骤的过程。首先,专家们竞争并写入共享工作空间。其次,来自工作空间的信息被广播到所有专家,如下所述。
步骤2:将信息写入共享工作空间
各个专家竞争将信息写入共享工作空间,其中共享工作空间的内容需要根据来自不同专家的新信息进行更新。这一步确保只有关键信号才能进入共享工作空间,从而防止工作空间混乱。让矩阵R表示所有专家的组合状态(即,
h
t
k
∀
k
∈
1
,
.
.
.
,
n
s
h_t^k ∀k ∈ {1,...,n_s}
htk∀k∈1,...,ns作为R的行)。为了实现专家之间竞争将信息写入工作空间,我们使用一个键-查询-值注意机制。在这种情况下,查询是当前工作空间存储内容状态的函数,由矩阵M表示(一行表示一个记忆存储槽),即,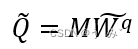
键和值是专家信息的函数,即由R表示的函数。我们应用点积注意力机制来得到更新的记忆矩阵:
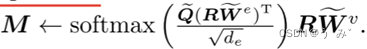
使用普通的softmax来写入M会导致不同专家之间进行标准的软竞争以写入共享工作空间。我们也可以使用top-k softmax(Ke等人,2018)来选择允许写入共享工作空间的固定数量的专家:基于softmax之前的值,选择具有最高值的固定数量k的专家,让他们可以写入共享工作空间。使用top-k softmax进行选择是硬选择和软选择的混合方式。我们将所选的专家集合表示为
F
t
F_t
Ft。值得注意的是,我们可以多次应用注意机制,将不同专家的信息提炼到共享工作空间中。在这里,共享工作空间的内容以RMC(Santoro等人,2018)中提出的门控方式进行更新。请参阅附录C节了解更多细节。
步骤3:从共享工作空间中广播信息

2.4 共享工作空间促进的交互的好处
用共享工作空间促进的交互代替神经模块之间的成对交互,可以实现以下功能:
1. 神经模块之间的高阶交互
共享工作空间中的两步写入-读取过程首先允许每个内存插槽存储当前输入的“filtered summary”,其中“过滤器”由该插槽的先前状态(写入步骤的“查询”)确定。然后神经模块总结这些插槽中包含的信息并更新它们的状态。因此,与成对交互不同,在共享工作空间设置中神经模块之间传递的消息也包括高阶交互项,即同时包含多个模块的交互项。自然而然地,高阶交互需要在神经模块之间传递的消息处于同一表示空间中,这正是我们通过仅允许通过单一全局通道进行消息传递所要实现的。
2. 基于内存持久性的动态过滤
在共享工作空间SW中,记忆槽的内容在某个时间步中在过滤和总结当前输入信息方面起着关键作用。内存的持久性贯穿整个情节,1)使内存层能够根据其到目前为止看到的内容对信息进行总结和过滤,2)理想情况下应该能够实现更好的泛化性能,因为模型能够为特定的输入动态修改其过滤机制。相比之下,Set Transformers(Lee等,2019)中的“诱导点”在训练后是固定的,因此瓶颈无法针对任何新的输入进行实时调整。我们在第4节中展示了几项任务的比较。通过将共享工作空间的性能与a)2×Self-Attention(以模拟无全局通信的高阶交互)和b)没有内存持久性的版本进行比较,我们展示了这两个属性的重要性(in Appendix D)。
共享工作空间用于同步不同专家的计算复杂度。为了鼓励全局协调,Transformer和基于插槽的循环架构依赖于通过注意机制捕获的成对交互(传统方法)。不幸的是,这种注意机制的计算复杂度随着专家数量的增加呈二次增长。在这里,我们提出了一种方法,使用共享工作空间创建不同专家之间的全局一致性,并在此过程中替换传统点积注意力的成对交互。因此,所提出方法的计算复杂度与专家数量成线性关系(本文方法)。在我们的实验中,记忆槽的数量基本上是恒定的,这表明这种方法具有非常良好的可扩展性,而且明显比二次复杂度更低。作为一个参考点,人类工作记忆槽的数量(Baars,1993)实际上非常小(不到10个槽)。
3. 相关工作
这项工作借鉴了历史上一些学者的思路,例如 Minsky (1988)、Braitenberg (1986) 和 Fodor (1983),他们认为,为了能够应对各种条件和任务,一个智能系统应该由许多相互作用的专业模块或程序组成,而不是一个单一的“一刀切”的实体。尽管模块化架构已经是许多研究方向的研究对象,如 Jacobs 等人 (1991)、Bottou 和 Gallinari (1991)、Ronco 等人 (1997)、Reed 和 De Freitas (2015)、Andreas 等人 (2016)、Rosenbaum 等人 (2017)、Fernando 等人 (2017)、Shazeer 等人 (2017)、Rosenbaum 等人 (2019) 和 Goyal 和 Bengio (2020),但我们在这里专注于通过在所有专家之间共享全局工作空间来实现专家模块之间的协调和同步的机制。
此前已有研究探讨了在循环神经网络(Graves等人,2014;2016;Santoro等人,2018)中引入基于插槽的记忆的方法。在transformers,中,Burtsev和Sapunov(2020)引入了存储记忆令牌并将其与序列令牌一起处理的方法,而Dai等人(2019)(Transformer-XL)则提出将长序列分为较小的段,并在处理当前段时使用先前段的激活状态进行记忆。在此基础上,Rae等人(2019)提出了将先前段的激活状态存储在压缩记忆中的方法。然而,这些方法并没有限制记忆写入的稀疏性和竞争性。最近在这个方向上的一些研究包括全局神经工作空间(GNW)模型(Dehaene和Changeux,2011),该模型将全局工作空间确定为由具有长程轴突过程的兴奋性金字塔形神经元网络连接额叶和顶叶皮层。
此外,使用共享工作空间以建立不同专家之间的协调性而不是使用all-pair communication具有额外的好处,因为它允许我们解决自我注意力的 O ( n 2 ) O(n^2) O(n2)复杂度问题。这使得我们的工作与Transformer中降低点积注意力计算复杂度的先前工作有关。Lee等人(2019)引入了ISAB模块,该模块在集合之间进行映射并包含两个点积注意力层。在第一层中,使用一组可训练参数作为查询,将输入集合的元素作为键;在第二层中,将第一层的输出作为键,并将输入集合作为查询。然而,与本文不同的是,中间状态(对应于第一层的输出)在不同层之间不保持。
与我们的工作同时进行的(Jaegle等人,2021)还介绍了使用潜在瓶颈来解决二次复杂度的想法,但存在重要的差异。例如,在Perceiver中,潜在瓶颈迭代地查询有关不同位置的信息,并且不维护不同专家的表示。更具体地说,在我们提出的方法中,不同的专家将信息写入工作空间,然后从共享工作空间中读取信息。在Perceiver中,潜在瓶颈迭代地从一组位置读取信息。我们还展示了所提出的想法在基于插槽的模型和变换器中的适用性。
理解与的不同点:在Perceiver中,潜在瓶颈是一种将输入向量映射为较小向量的函数,通过多次迭代来获取输入的全局信息。在这个过程中,潜在瓶颈会查询不同位置的信息,但不会维护不同专家的表示。因此,在Perceiver中,不同的专家不能写入信息。
所提出的模型可以看作是将模块化结构(Andreas等人,2016;Goyal等人,2019)、记忆网络(Graves等人,2014;Santoro等人,2018)和专家混合模型(Jacobs等人,1991)等不同的思想进行了整合,从而在一个统一的架构中结合了它们的优点。该模型被分解为一组专家(融合了模块化的特点)。通过使用共享工作空间,该模型在不同的专家之间实现了协调(在神经图灵机中,只有一个单独的专家,即没有任何模块化)。多个专家可以同时活跃(通常在专家混合模型中不是这种情况)。
4.实验
在这里,我们简要概述了应用共享工作空间思想的任务,并引导读者参考附录获取更多实验 (附录G),包括每个任务的详细说明和模型的超参数设置。这些实验旨在:(a)展示共享工作空间的应用可以在多种具有挑战性的基准任务中提高模型的结果,以此证明该技术的实用性和广泛性;(b)展示共享工作空间可以通过提高模型性能而不需要全部成对交互,解决不同专家之间的协调问题。最后,为了展示我们模型的广泛适用性,我们将共享工作空间整合到TIMs (Lamb等,2021)、SCOFF (Goyal等,2020)和BRIMs (Mittal等,2020)中,并展示了在每个模型的默认通信方法上的改进。
4.1 通过使用共享工作空间来理解视觉输入
使用共享工作空间在不同专家之间共享信息时引入了瓶颈。由于工作空间的大小通常比专家数量小得多,因此可以交换的信息量是有限的。我们假设通过有限容量的工作空间进行通信应该会鼓励模型关注下游目标所必需的相关信息。我们在一组具有视觉挑战性的基准测试上测试了这个假设。在我们的实验中,我们使用Transformers或RIMs作为骨干网络。我们考虑基于不同重要属性的Transformers变体。
- Transformers [TR]:基于自注意力的多层架构(Vaswani等,2017),层之间共享参数。
- Set transformer [ISAB]:将自注意力替换为ISAB模块(Lee et al.,2019)的Transformer变体。
- Sparse Transformers [STR]:使用注意力矩阵的稀疏因式分解(Child et al.,2019)的Transformer变体。
- High Capacity Transformers [TR+HC]:与TR相同,但在不同层使用不同的参数。
- 带有软竞争机制的共享工作区Transformer [TR+SSW]:使用软竞争机制,不同位置的Transformer之间相互竞争写入共享工作区。
- 带有top-k竞争机制的共享工作区Transformer [TR+HSW]:使用top-k竞争机制,不同位置的Transformer之间相互竞争写入共享工作区。
有关所有下面描述的任务的更详细说明,请参阅附录部分E。
4.2 检测等边三角形
我们首先使用一个简单的玩具任务来测试我们的假设,即模型应该在图像中检测出等边三角形(Ahmad and Omohundro, 2009)。每个图像的大小为64×64,包含3个随机放置的点簇。对于等边三角形,这些点簇的中点彼此等距。这是一个二元分类任务,模型必须预测三个给定的点簇是否形成等边三角形。为了将图像馈送到Transformer中,我们遵循视觉Transformer(Dosovitskiy et al., 2020)中使用的相同方法。我们首先将图像分成相等大小的4×4块,将每个块视为Transformer的不同输入位置。为了正确解决这个任务,模型只需要关注相关信息,即包含点簇的块。因此,在这里使用有限容量的共享工作空间应该是有用的。我们的结果(在图3中展示)证实了这个假设。我们可以看到,共享工作空间的Transformer的注意力收敛速度更快,达到了比基线Transformer更高的准确性。我们的方法也明显优于Set Transformer。
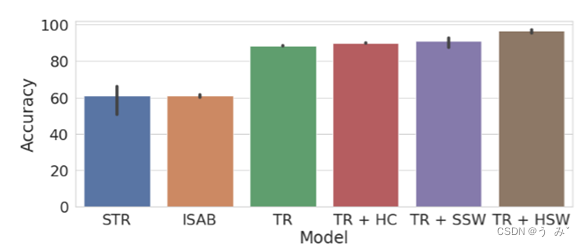
图3:检测等边三角形
在这里,我们将具有共享工作空间的Transformer的性能与其他Transformer基线进行比较,并绘制了每个模型的测试精度。
4.3 关系推理:Sort-of-CLEVR
关系推理中,模型的任务是回答有关各种物体及其与其他物体之间关系的某些属性的问题。模型将呈现一张图像和一个与该图像相关的问题。这个任务具有明显的稀疏结构,因为为了正确回答问题,它只需要考虑问题提及的特定物体子集。对于这个任务,我们使用Sort-of-CLEVR数据集(Santoro等人,2017)。Sort-of-CLEVR中的每个图像大小为75×75,包含6个随机放置的具有6种可能颜色和2种可能形状的几何形状。每个图像都有10个关系问题和10个非关系问题。非关系问题只考虑单个对象的属性。另一方面,关系问题考虑多个对象之间的关系。关于问题的更多细节请参见附录图8。模型的输入由图像和相应的问题表示组成。我们首先像视觉Transformer(Dosovitskiy等人,2020)一样获得一个大小相同的补丁序列的表示。我们将生成的补丁序列与问题的表示连接起来,并将组合后的序列传递给Transformer。Sort-of-CLEVR有一个有限的可能答案,因此这个任务被设置为分类任务。

我们在图4中呈现了这个任务的结果。我们观察到使用共享工作空间的Transformer收敛速度更快,并在关系问题和非关系问题方面优于基线。共享内存的卓越性能可以归因于这个任务的固有稀疏性。例如,在非关系问题中,模型只需要注意到问题中提到的一个对象即可正确回答它,而关系问题只考虑图像中的一小部分对象,因此稀疏性对这两种类型的问题都有帮助。因此,共享工作空间的有限容量迫使模型只注意相关信息。
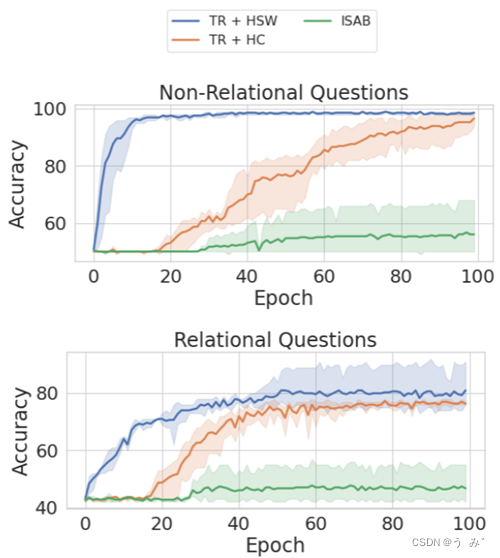
图4:Sort-of-CLEVR关系推理的比较
在Sort-of-CLEVR数据集中,关系问题和非关系问题的收敛速度比较。我们可以看到,所提出的模型在两种情况下都比基线模型收敛得快。
今天就先写这么多啦,友友们如果有兴趣,可以留言噢!
后面再把论文写完整,并附上自己认为可以创新的地方!!!
都看到这啦,点个赞叭叭






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结