您现在的位置是:首页 >其他 >Redis详解网站首页其他
Redis详解
简介Redis详解
课程目标:
1
、
Redis
概述
2
、下载与安装
3
、使用
Redis
1. 概述
1.1 互联网架构的演变历程
● 第1阶段
○ 数据访问量不大,简单的架构即可搞定!
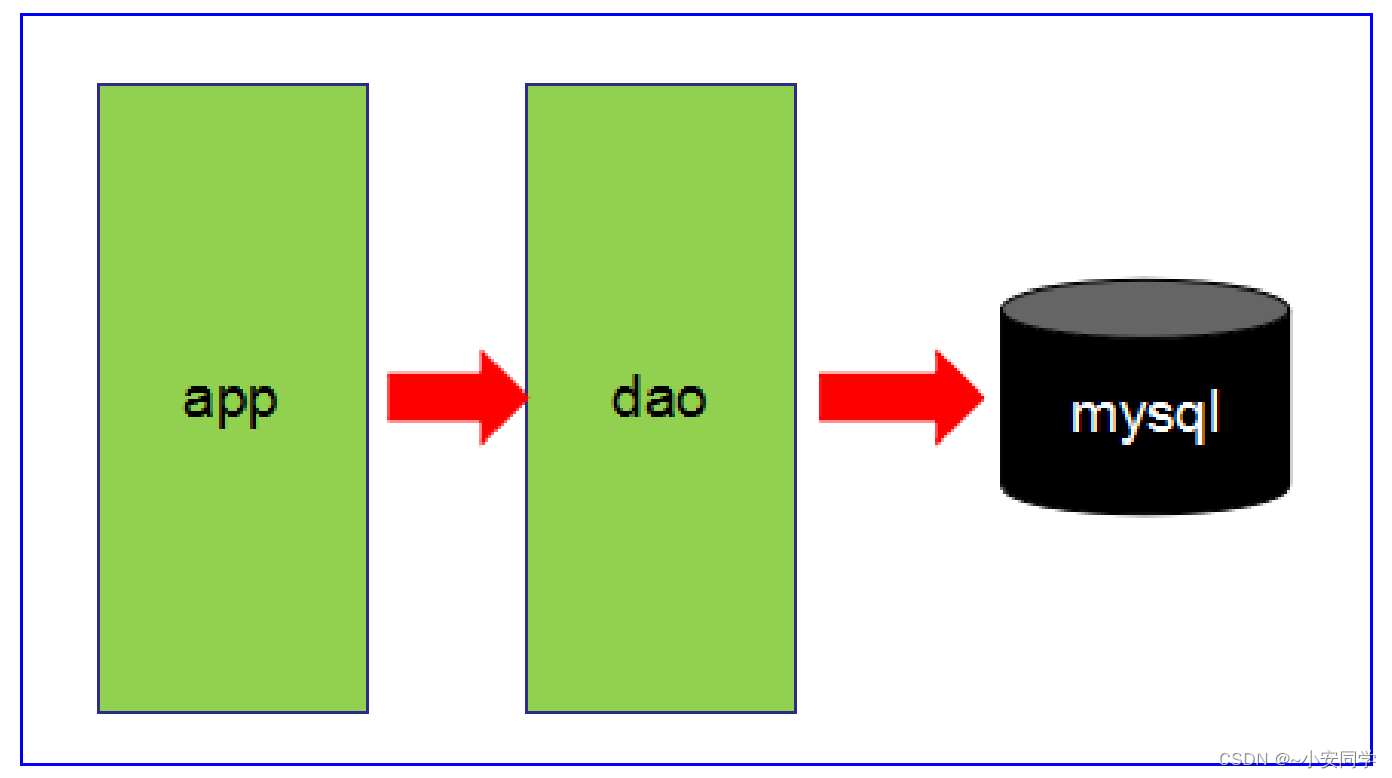
● 第2阶段
○ 数据访问量大,使用缓存技术来缓解数据库的压力。
○ 不同的业务访问不同的数据库
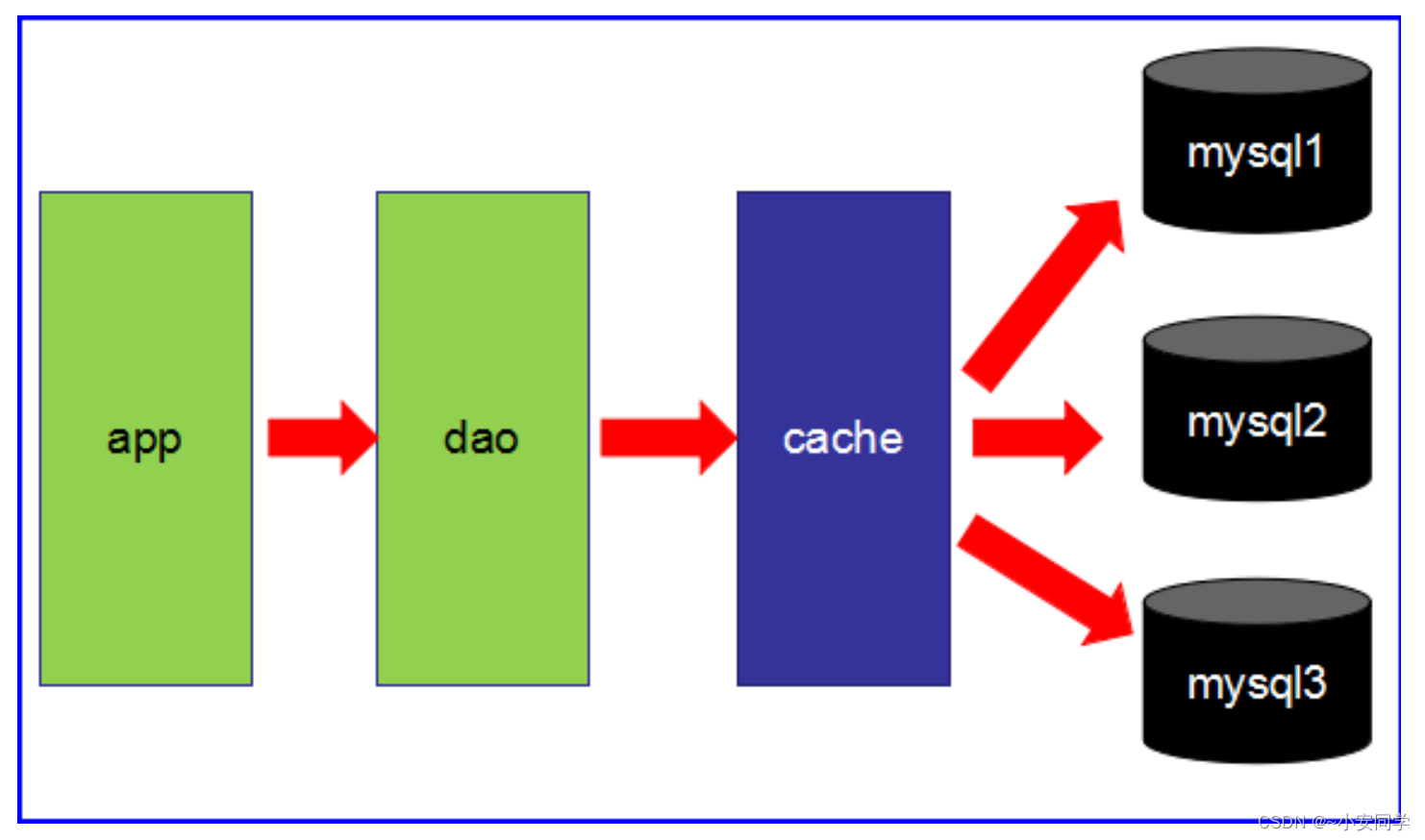
● 第3阶段
○ 主从读写分离。
○ 之前的缓存确实能够缓解数据库的压力,但是写和读都集中在一个数据库上,压力又来了。
○ 一个数据库负责写,一个数据库负责读。分工合作。愉快!
○ 让master(主数据库)来响应事务性
(增删改)
操作,让
slave
(从数据库)来响应非事务性
(查询)
操作,然后再采用主从复制来把
master
上的事务性操作同步到
slave
数据库中
○ mysql的master/slave
就是网站的标配!

● 第4阶段
○ mysql的主从复制,读写分离的基础上,mysql
的主库开始出现瓶颈
○ 由于MyISAM使用表锁,所以并发性能特别差
○ 分库分表开始流行,mysql也提出了表分区,虽然不稳定,但我们看到了希望
○ 开始吧,mysql集群

1.2 Redis入门介绍
● 互联网需求的3高
○ 高并发,高可扩,高性能。
● Redis 是一种运行速度很快,并发性能很强,并且运行在内存上的
NoSql
(
not only sql
)数据库
● NoSQL数据库 和 传统数据库 相比的优势
○ NoSQL数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
○ 而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段 简直就是一个噩梦。
● Redis的常用使用场景
○
缓存
,毫无疑问这是
Redis
当今最为人熟知的使用场景。在提升服务器性能方面非常有效;一 些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis
中,因为
redis
是放在内存中的可以很高效的访问;
○
排行榜
,在使用传统的关系型数据库(
mysql oracle
等)来做这个事儿,非常的麻烦,而利
用
Redis
的
SortSet(
有序集合
)
数据结构能够简单的搞定;
○
计算器/
限速器
,利用
Redis
中原子性的自增操作,我们可以统计类似用户点赞数、用户访问
数等,这类操作如果用
MySQL
,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API
的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
○
好友关系
,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好
友、共同爱好之类的功能;
○
简单消息队列
,除了
Redis
自身的发布
/
订阅模式,我们也可以利用
List
来实现一个队列机制, 比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB
压力,完全
可以用
List来完成异步解耦;
○
Session共享
,以
jsp
为例,默认
Session
是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis
保存
Session
后,无论
用户落在那台机器上都能够获取到对应的
Session
信息。
1.3 Redis/Memcache/MongoDB对比
都是
nosql
数据库的著名代表
1.3.1 Redis和Memcache
● Redis和
Memcache
都是内存数据库。不过
memcache
还可用于缓存其他,例如图片、视频等。
● memcache 数据结构单一
kv
,
redis
更丰富一些,还提供
list
,
set
,
hash
等数据结构的存储,有
效的减少网络
IO
的次数。
● 虚拟内存–Redis
当物理内存用完时,可以将一些很久没用到的
value
交换到磁盘。
●
存储数据安全
–memcache
挂掉后,数据没了(没有持久化机制);
redis
可以定期保存到磁盘(持久化)。
● 灾难恢复–memcache
挂掉后,数据不可恢复
; redis
数据丢失后可以通过
RBD
或
AOF
恢复。
1.3.2 Redis和MongoDB
● redis和
mongodb
并不是竞争关系,更多的是一种
协作共存
的关系。
● mongodb本质上还是硬盘数据库,在复杂查询时仍然会有大量的资源消耗,而且在处理复杂逻辑
时仍然要不可避免地进行多次查询。
● 这时就需要redis
或
Memcache
这样的内存数据库来作为中间层进行缓存和加速。
● 比如在某些复杂页面的场景中,整个页面的内容如果都从mongodb
中查询,可能要几十个查询语
句,耗时很长。如果需求允许,则可以把整个页面的对象缓存至
redis
中,定期更新。这样 mongodb和
redis
就能很好地协作起来。
1.4 分布式数据库CAP原理
● 传统的关系型数据库事务具备ACID
:
○ A:原子性
○ C:一致性
○ I:独立性
○ D:持久性
● 分布式数据库的CAP:
○ C(Consistency
):强一致性
■ “all nodes see the same data at the same time”,即更新操作成功并返回客户端后,
所
有节点在同一时间的数据完全一致
,这就是分布式的一致性。一致性的问题在并发系 统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的 问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
○ A(Availability
):高可用性
■ 可用性指“Reads and writes always succeed”,即
服务一直可用
,而且要是正常的响应
时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访 问超时等用户体验不好的情况。
○ P(Partition tolerance
):分区容错性
■ 即分布式系统在遇到
某节点或网络分区故障时,仍然能够对外提供满足一致性或可用 性
的服务
。
■ 分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运 转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的 机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
1.4.2 CAP理论
● CAP理论提出就是针对分布式数据库环境的,所以,
P
这个属性必须容忍它的存在,而且是必须 具备的。
● 因为P
是必须的,那么我们需要选择的就是
A
和
C
。
● 大家知道,在分布式环境下,为了保证系统可用性,通常都采取了复制的方式,避免一个节点损
坏,导致系统不可用。那么就出现了每个节点上的数据出现了很多个副本的情况,而数据从一个 节点复制到另外的节点时需要时间和要求网络畅通的,所以,当P
发生时,也就是无法向某个节 点复 制数据时,这时候你有两个选择:
○ 选择可用性 A,此时,那个失去联系的节点依然可以向系统提供服务,不过它的数据 就不能保证是同步的了(失去了C
属性)。
○ 选择一致性C,为了保证数据库的一致性,我们必须等待失去联系的节点恢复过来, 在这个过程中,那个节点是不允许对外提供服务的,这时候系统处于不可用状态(
失去 了
A
属性
)
。
● 最常见的例子是读写分离,某个节点负责写入数据,然后将数据同步到其它节点,其它节点提 供读取的服务,当两个节点出现通信问题时,你就面临着选择A
(继续提供服务,但是数据不保 证准确),C
(用户处于等待状态,一直等到数据同步完成)。
1.4.3 CAP总结
● 分区是常态,不可避免,三者不可共存
●
可用性和一致性是一对冤家
○ 一致性高,可用性低
○ 一致性低,可用性高
● 因此,根据 CAP
原理将
NoSQL
数据库分成了满足
CA
原则、满足
CP
原则和满足
AP
原则三 大类:
○ CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
○ CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
○ AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
2. 下载与安装
2.1 下载
● redis:
http://www.redis.net.cn/

● 图形工具:https://redisdesktop.com/download
2.2 安装
虽然可以在安装在
windows
操作系统,但是官方不推荐,所以我们一如既往的安装在
linux
上
1. 上传
tar.gz
包,并解压
tar -zxvf redis-5.0.4.tar.gz
2. 安装
gcc
(必须有网络)
yum -y install gcc忘记是否安装过,可以使用 gcc -v 命令查看gcc版本,如果没有安装过,会提示命令不存在
3. 进入redis
目录,进行编译
make
4. 编译之后,开始安装
make install2.3 安装后的操作
2.3.1 后台运行方式
● redis默认不会使用后台运行,如果你需要,修改配置文件
daemonize=yes
,当你后台服务启动的
时候,会写成一个进程文件运行。
vim /opt/redis-5.0.4/redis.confdaemonize yes
● 以配置文件的方式启动
cd /usr/local/bin
redis-server /opt/redis-5.0.4/redis.conf2.3.2 关闭数据库
● 单实例关闭
redis-cli shutdown● 多实例关闭
redis-cli -p 6379 shutdown2.3.3 常用操作
● 检测6379
端口是否在监听
netstat -lntp | grep 6379端口为什么是 6379 ?6379 在是手机按键上 MERZ 对应的号码,而 MERZ 取自意大利歌女 Alessia Merz 的名字。MERZ 长期以来被 antirez ( redis 作者)及其朋友当作愚蠢的代名词。
● 检测后台进程是否存在
ps -ef|grep redis2.3.4 连接redis并测试
redis-cli
ping2.3.5 HelloWorld
# 保存数据
set k1 china
# 获取数据
get kl2.3.6 测试性能
● 先 ctrl+c
,退出
redis
客户端
redis-benchmark
● 执行命令后,命令不会自动停止,需要我们手动ctrl+c
停止测试
[root@localhost bin]# redis-benchmark
====== PING_INLINE ======
100000 requests completed in 1.80 seconds # 1.8秒处理了10万个请求,性能要看笔记
本的配置高低
50 parallel clients
3 bytes payload
keep alive: 1
87.69% <= 1 milliseconds
99.15% <= 2 milliseconds
99.65% <= 3 milliseconds
99.86% <= 4 milliseconds
99.92% <= 5 milliseconds
99.94% <= 6 milliseconds
99.97% <= 7 milliseconds
100.00% <= 7 milliseconds
55524.71 requests per second # 每秒处理的请求数量2.3.7 默认16个数据库
vim /opt/redis-5.0.4/redis.conf
127.0.0.1:6379> get k1 # 查询k1
"china"
127.0.0.1:6379> select 16 # 切换16号数据库
(error) ERR DB index is out of range # 数据库的下标超出了范围
127.0.0.1:6379> select 15 # 切换15号数据库
OK
127.0.0.1:6379[15]> get k1 # 查询k1
(nil)
127.0.0.1:6379[15]> select 0 # 切换0号数据库
OK
127.0.0.1:6379> get k1 # 查询k1
"china2.3.8 数据库键的数量
dbsize
redis
在
linux
支持命令补全(
tab
)
2.3.9 清空数据库
● 清空当前库
flushdb● 清空所有(16个)库,慎用!!
flushall2.3.10 模糊查询(key)
模糊查询
keys
命令,有三个通配符:
● *:通配任意多个字符
# 查询所有的键
keys *
# 模糊查询k开头,后面随便多少个字符
keys k*
# 模糊查询e为最后一位,前面随便多少个字符
keys *e
# 双 * 模式,匹配任意多个字符:查询包含k的键
keys *k*
● ?:通配单个字符
# 模糊查询k字头,并且匹配一个字符
keys k?
# 你只记得第一个字母是k,他的长度是3
keys k??● []:通配括号内的某一个字符
# 记得其他字母,就第二个字母可能是a或e
keys r[ae]dis2.3.11 键(key)
● exists key:判断某个key是否存在
127.0.0.1:6379> exists k1
(integer) 1 # 存在
127.0.0.1:6379> exists y1
(integer) 0 # 不存在
● move key db:移动(剪切,粘贴)键到几号库
127.0.0.1:6379> move x1 8 # 将x1移动到8号库
(integer) 1 # 移动成功
127.0.0.1:6379> exists x1 # 查看当前库中是否存在x1
(integer) 0 # 不存在(因为已经移走了)
127.0.0.1:6379> select 8 # 切换8号库
OK
127.0.0.1:6379[8]> keys * # 查看当前库中的所有键
1) "x1"
● ttl key:查看键还有多久过期(-1
永不过期,
-2
已过期)
● time to live 还能活多久
127.0.0.1:6379[8]> ttl x1
(integer) -1 # 永不过期
● expire key 秒:为键设置过期时间(生命倒计时)
127.0.0.1:6379[8]> set k1 v1 # 保存k1
OK
127.0.0.1:6379[8]> ttl k1 # 查看k1的过期时间
(integer) -1 # 永不过期
127.0.0.1:6379[8]> expire k1 10 # 设置k1的过期时间为10秒(10秒后自动销毁)
(integer) 1 # 设置成功
127.0.0.1:6379[8]> get k1 # 获取k1
"v1"
127.0.0.1:6379[8]> ttl k1 # 查看k1的过期时间
(integer) 2 # 还有2秒过期
127.0.0.1:6379[8]> get k1
(nil)
127.0.0.1:6379[8]> keys * # 从内存中销毁了
(empty list or set)
● type key:查看键的数据类型
127.0.0.1:6379[8]> type k1
string # k1的数据类型是会string字符串3. 使用Redis
3.1 五大数据类型
● 操作文档:
http://redisdoc.com/
3.1.1 字符串String
● set/get/del/append/strlen
127.0.0.1:6379> set k1 v1 # 保存数据
OK
127.0.0.1:6379> set k2 v2 # 保存数据
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
127.0.0.1:6379> del k2 # 删除数据k2
(integer) 1
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379> get k1 # 获取数据k1
"v1"
127.0.0.1:6379> append k1 abc # 往k1的值追加数据abc
(integer) 5 # 返回值的长度(字符数量)
127.0.0.1:6379> get k1
"v1abc"
127.0.0.1:6379> strlen k1 # 返回k1值的长度(字符数量)
(integer) 5
● incr/decr/incrby/decrby:加减操作,操作的必须是数字类型
○ incr:意思是increment,增加
○ decr:意思是decrement,减少
127.0.0.1:6379> set k1 1 # 初始化k1的值为1
OK
127.0.0.1:6379> incr k1 # k1自增1(相当于++)
(integer) 2
127.0.0.1:6379> incr k1
(integer) 3
127.0.0.1:6379> get k1
"3"
127.0.0.1:6379> decr k1 # k1自减1(相当于--)
(integer) 2
127.0.0.1:6379> decr k1
(integer) 1
127.0.0.1:6379> get k1
"1"
127.0.0.1:6379> incrby k1 3 # k1自增3(相当于+=3)
(integer) 4
127.0.0.1:6379> get k1
"4"
127.0.0.1:6379> decrby k1 2 # k1自减2(相当于-=2)
(integer) 2
127.0.0.1:6379> get k1
"2"
● getrange/setrange:类似between...and...
○ range:范围
127.0.0.1:6379> set k1 abcdef # 初始化k1的值为abcdef
OK
127.0.0.1:6379> get k1
"abcdef"
127.0.0.1:6379> getrange k1 0 -1 # 查询k1全部的值
"abcdef"
127.0.0.1:6379> getrange k1 0 3 # 查询k1的值,范围是下标0~下标3(包含0和3,共
返回4个字符)
"abcd"
127.0.0.1:6379> setrange k1 1 xxx # 替换k1的值,从下标1开始提供为xxx
(integer) 6
127.0.0.1:6379> get k1
"axxxef
● setex/setnx
○
set
with
ex
pir
:添加数据的同时设置生命周期
127.0.0.1:6379> setex k1 5 v1 # 添加k1 v1数据的同时,设置5秒的声明周期
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k1
(nil) # 已过期,k1的值v1自动销毁
○
set
if
n
ot e
x
ist
:添加数据的时候判断是否已经存在,防止已存在的数据被覆盖掉
127.0.0.1:6379> setnx k1 sun
(integer) 0 # 添加失败,因为k1已经存在
127.0.0.1:6379> get k1
"laosun"
127.0.0.1:6379> setnx k2 sun
(integer) 1 # k2不存在,所以添加成功
● mset/mget/msetnx
● m:
more
更多
127.0.0.1:6379> set k1 v1 k2 v2 # set不支持一次添加多条数据
(error) ERR syntax error
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # mset可以一次添加多条数据
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
3) "k3"
127.0.0.1:6379> mget k2 k3 # 一次获取多条数据
1) "v2"
2) "v3"
127.0.0.1:6379> msetnx k3 v3 k4 v4 # 一次添加多条数据时,如果添加的数据
中有已经存在的,则失败
(integer) 0
127.0.0.1:6379> msetnx k4 v4 k5 v5 # 一次添加多条数据时,如果添加的数据
中都不存在的,则成功
(integer) 1
● getset:先get
后
set
127.0.0.1:6379> getset k6 v6
(nil) # 因为没有k6,所以get为null,然后将k6v6的值添加到数据库
127.0.0.1:6379> keys *
1) "k4"
2) "k1"
3) "k2"
4) "k3"
5) "k5"
6) "k6"
127.0.0.1:6379> get k6
"v6"
127.0.0.1:6379> getset k6 vv6 # 先获取k6的值,然后修改k6的值为vv6
"v6"
127.0.0.1:6379> get k6
"vv6"3.1.2 列表List(未完待续......)
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结