您现在的位置是:首页 >技术杂谈 >基于营销类系统运营活动增长带来的数据库设计演进网站首页技术杂谈
基于营销类系统运营活动增长带来的数据库设计演进
一、前言
为了支持业务数据的不断增长,在数据库层面的性能提升主要体现在几个维度:1)数据降级;2)数据主题分而治之;3)实时交易转异步;4)硬件扩容,当然网上一堆互联网系统的介绍也很多。因此,我的这篇系统发展梳理主要服务于以下两个目的:
-
作为一个经验沉淀,用于给后续的系统设计作为一个避坑指南;
-
另外,也是证明其实系统架构这个事情本身就是一个动态发展的过程,世界上没有完美的架构,因为架构本来就是一个平衡的艺术,需要综合平衡工期、资源、成本等各种因素。我的理念是满足当前业务需求并适度设计以保证不需要的功能能快速剥离;再次重复一句,过渡设计还不如不设计,因为带来额外的成本。
二、一直在路上
1、业务探索阶段
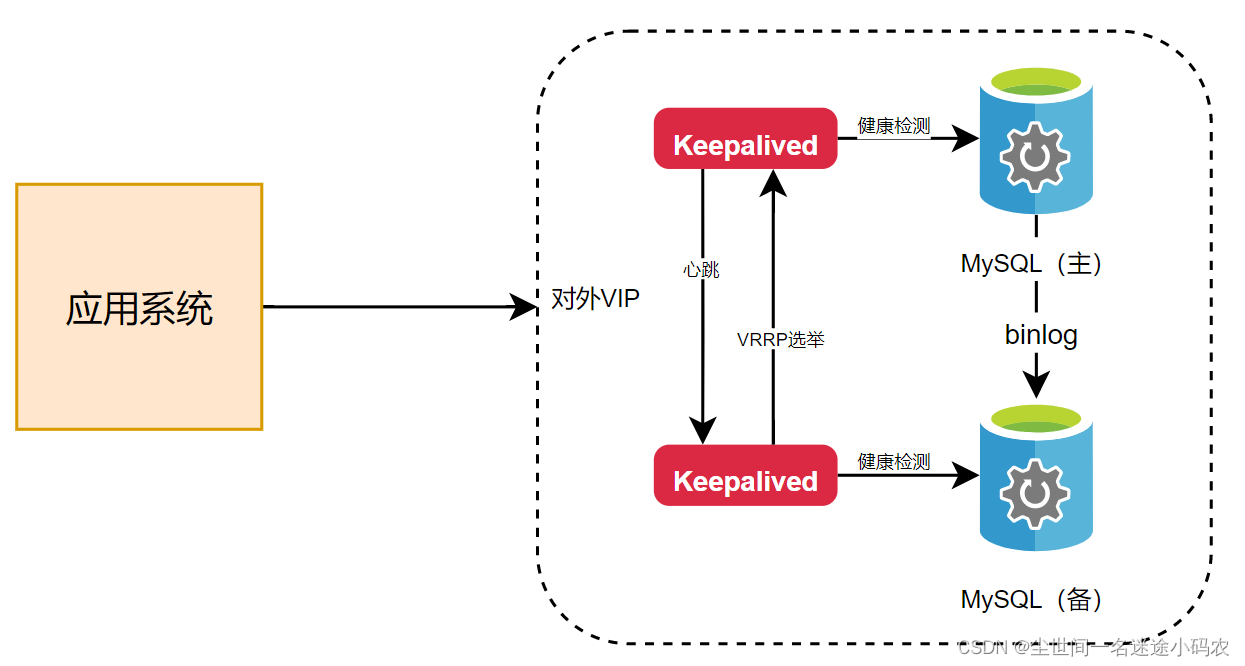
一开始呢,新系统刚建设投产,因为预期的业务量也不会很大,每天活动流量也就几个W,因此直接按照公司技术规范,直接1)数据库架构方面,搭建个MySQL的一主一从,通过keepalived进行故障自动切换来保障数据高可用;2)表设计方面,当年考虑到通用性,且当时业务也在尝试性做这个业务,具体后续的规划还是在不断变化中,因此我们在活动营销推送和营销权益发放这几个关键环节都分别各建一张通用表用来涵盖各种未来不可预知的场景,但是这种过渡设计反而给后面埋下了不少坑。
当时这样做的另外一个考虑点是在于,除了业务量不大和业务方向也在变化中以外,另外就是这套方案基本是的一个WEB经典三层架构+数据持久层的样板架构,直接使用的话没有太多的风险点,或者说风险规避措施都成型了的。
2、运营和数字化分析初步阶段
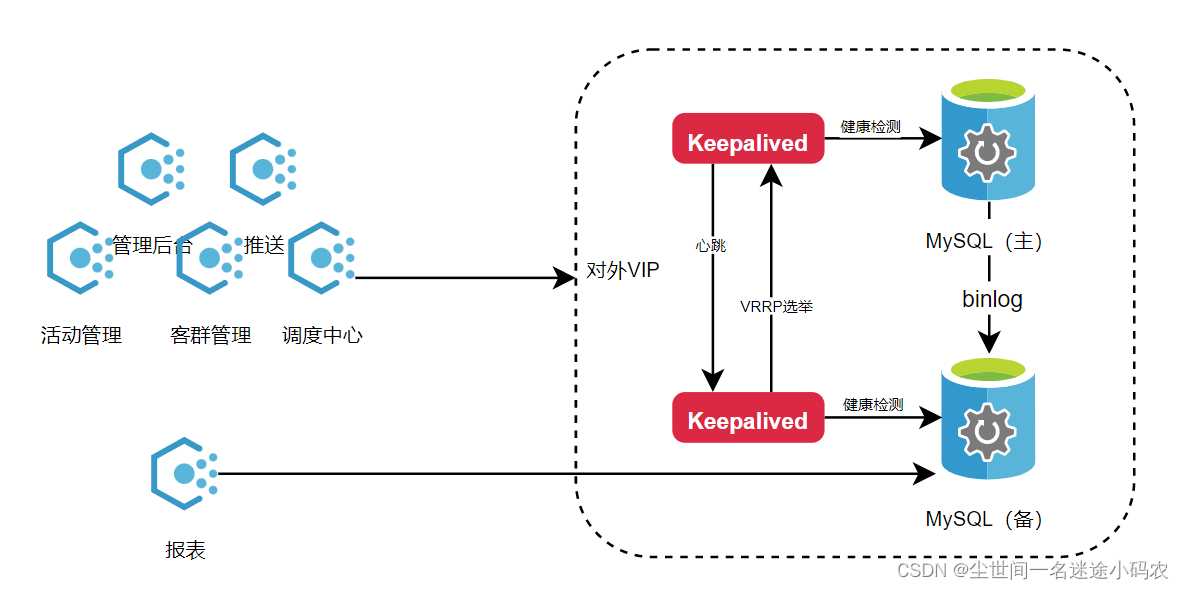
随着时间推移,活动也慢慢多起来,对接第三方的系统也比较多,该系统也慢慢变成了业务运营的工作台,因此各种场合或者每逢月底,运营需要高频次导出各种维度报表进行各种分析。因为报表需要的聚合数据或者关联表较多,因此存在较多的联表查询,所以在月底的时候当运营在导报表的时候系统就会出现系统卡顿或者系统缓慢的情况。
为了快速应对这种周期性的问题,后面把报表微服务直接指向从库,把所有报表查询或导出走从库处理,虽然会偶尔影响主从同步,但是不影响线上业务,暂时不碍事。
3、多活动灵活推送、开始上量阶段
然后,随着运营活动类型变得越来越多,每个活动的用户触达量有大有小,业务的要求是大小都要保,小的要快,大的要稳。业务背景是小活动也就几万客户的触达,一个中等活动大概是60~100万左右,但这里有几个历史架构遗留的问题,
-
之前的活动是没有优先级机制,一大一小撞在一起,资源会被大活动的抢占完导致小活动要发很久,但是大活动本身因为较大导致完成处理时间也较长,最终给人感觉就是大小两边的都没做好;
-
触达过程中存在高频的活动业务规则判断(这块是放到Redis)和客户维度的触达次数判断,而且营销系统本身除了自己业务运营外,还得承担其他系统的运营推送,因此经常出现互相影响,各个业务方也怨言很大。
因此,当时我们除了做应用层的代码改造外(这里不详述),从数据库和数据库相关的代码层也做了一系列改造:
一)业务隔离
针对其他上游系统的运营推送,做了隔离部署,从原本微服务做了迁出,避免交叉影响;
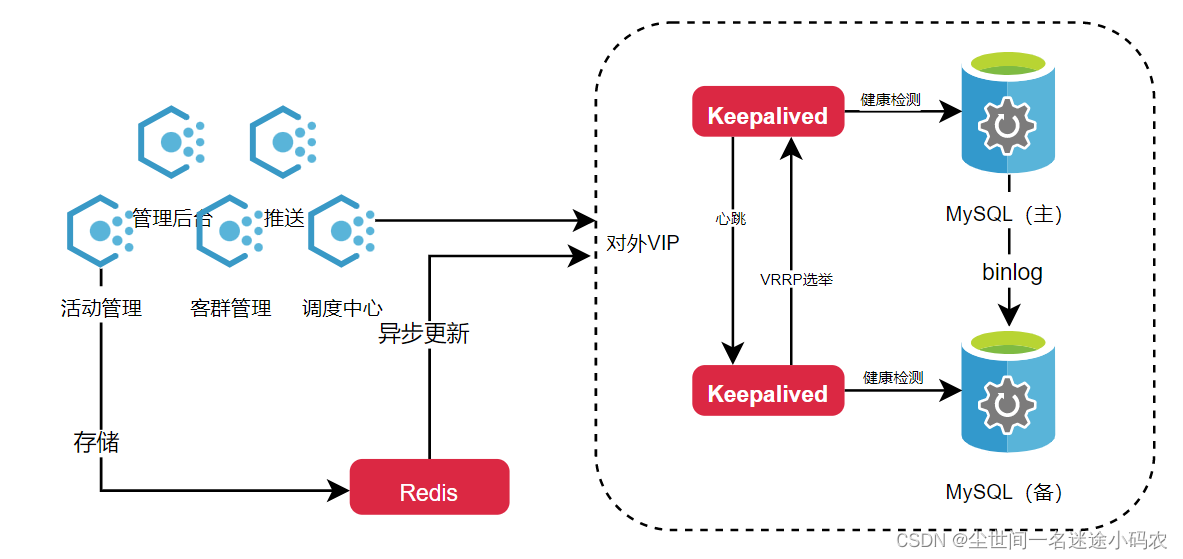
二)增加缓存、异步入库
针对自身运营的活动,因为按通用规则是需要以客户的累计推送次数为维度进行脱频处理,且以前量少的时候(以前业务方预估每天就推送5-6万)代码针对每条推送记录直接进行入库,但现在随随便便都60~100万的话就不能再这样搞了,因为每次的数据插入会导致数据库表的索引更新。因此,我们把推送记录1)改回累加推送次数,剔除非主要字段,减少对页空间的占用;2)把入库改回入redis,后续异步入库;
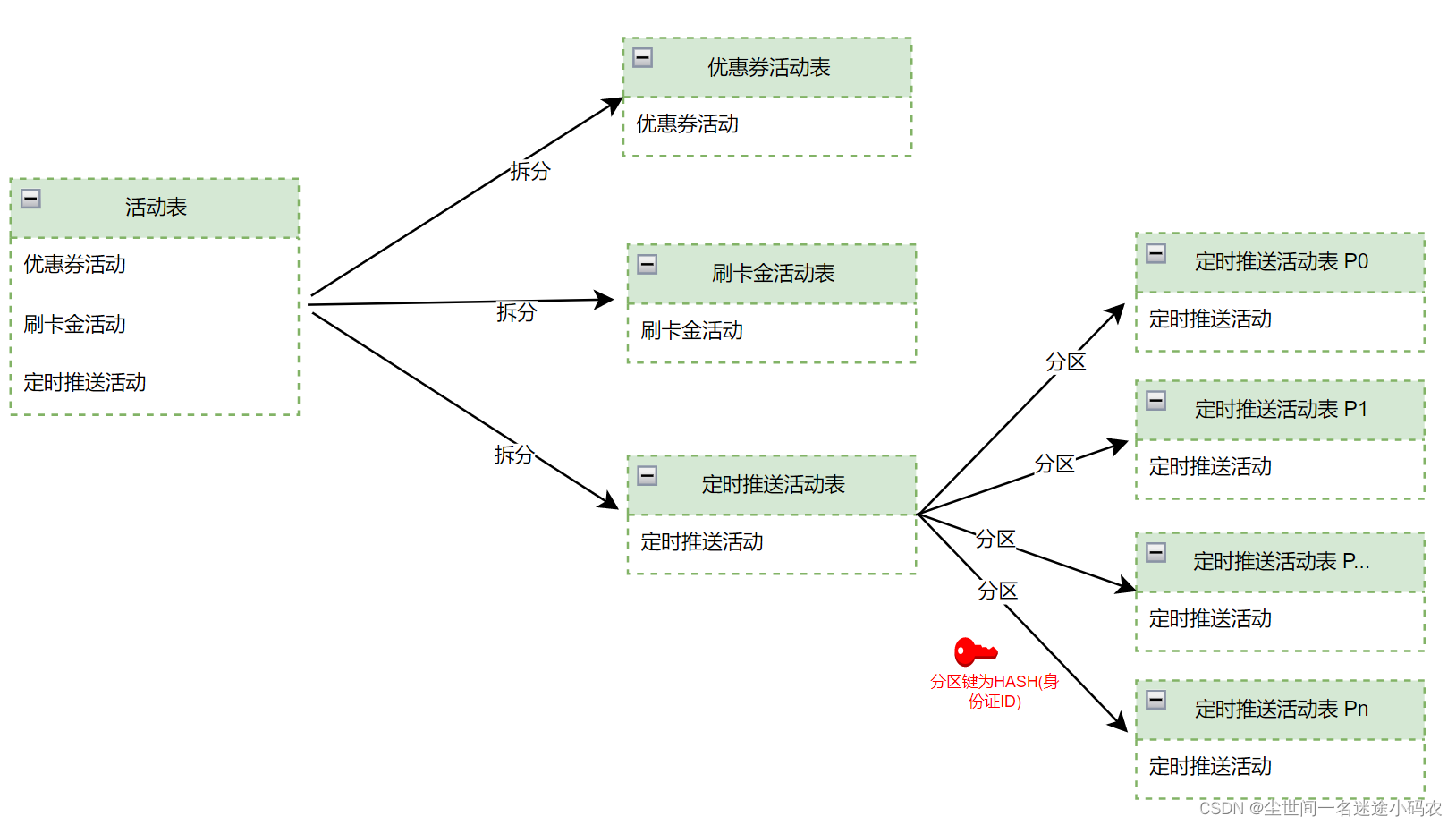
三)基于业务场景进行水平分表
针针对运营活动(如用户触达活动或环节)的几个主表,开始做按业务场景做分表(水平切分),关键还是要降低单表数据量;
四)主表改成分区表
同时,当然分区方式有很多种,有Range、HASH、List、混合分区。基于1)我们当时的C端用户的高频查询量、2)C端页面的查询交互流程(一进来会先查个人维度的汇总信息)、3)B端运营的统计分析类功能查询频次不高,且之前已做了备库查询,也能接受一丁点时延(10+秒)。同时,因为用户身份证也是索引键,因此针对部分主表按照用户身份证hash后作为分区键进行表分区,把物理单表变成多表(但是还是逻辑单表)。这样做的好处在于:
-
代码层面的改造量几乎可以忽略;
-
在C端查询时候可以按照分区键查询对应的分区,因为数据量少了因此效率也上来了;
-
因为数据较为均衡,因此查询落到对应的分区也比较平均,整体IO会趋向均衡;
-
B端用户虽然在查运营活动统计分析的时候可能要跨分区查询并合并结果,但因为跨分区查询是并发模式,因此效率一对冲起来算还好;
-
涉及到后续的数据备份或恢复,会更加友好,毕竟不需要任何情况都要全表备或恢复。
诚然,劣势也是有的。当你修改或者新增分区,则需要做表分区的Reorganize,重新对数据进行迁移,这样才能保证数据不会丢失;
4、大流量常规化阶段
再后来的2022年,业务开始侧重于针对某些业务场景做全量客群营销,这样就导致业务场景的数据不均衡(这里的不均衡指的是某几个业务场景对应的表数据量特别大,大概1个月左右1+亿数据)。随着业务场景越来越多,且每个场景推送量越来越大,开始慢慢来到深水区了。因为我们使用的是MySQL,其实MySQL单表如果上1个亿的数据就会开始出现瓶颈。看来分库分表是要上了,我们做了折中的妥协。
一)软硬件底层
-
把数据库盘从机械硬盘置换成SSD固态硬盘,从硬件层面进一步提升系统性能;
-
把数据库连接数按50%的增幅调大,后续观测连接数的使用情况;
二)分表
我们综合采用垂直分表和水平分表相结合的方案。
垂直分表
首先,垂直分表,我们把部分非关键字段迁移到一个新表,同时制定了团队内部规范,后续字段新增优先定义在新的表,尽量给原来的主表减减负。
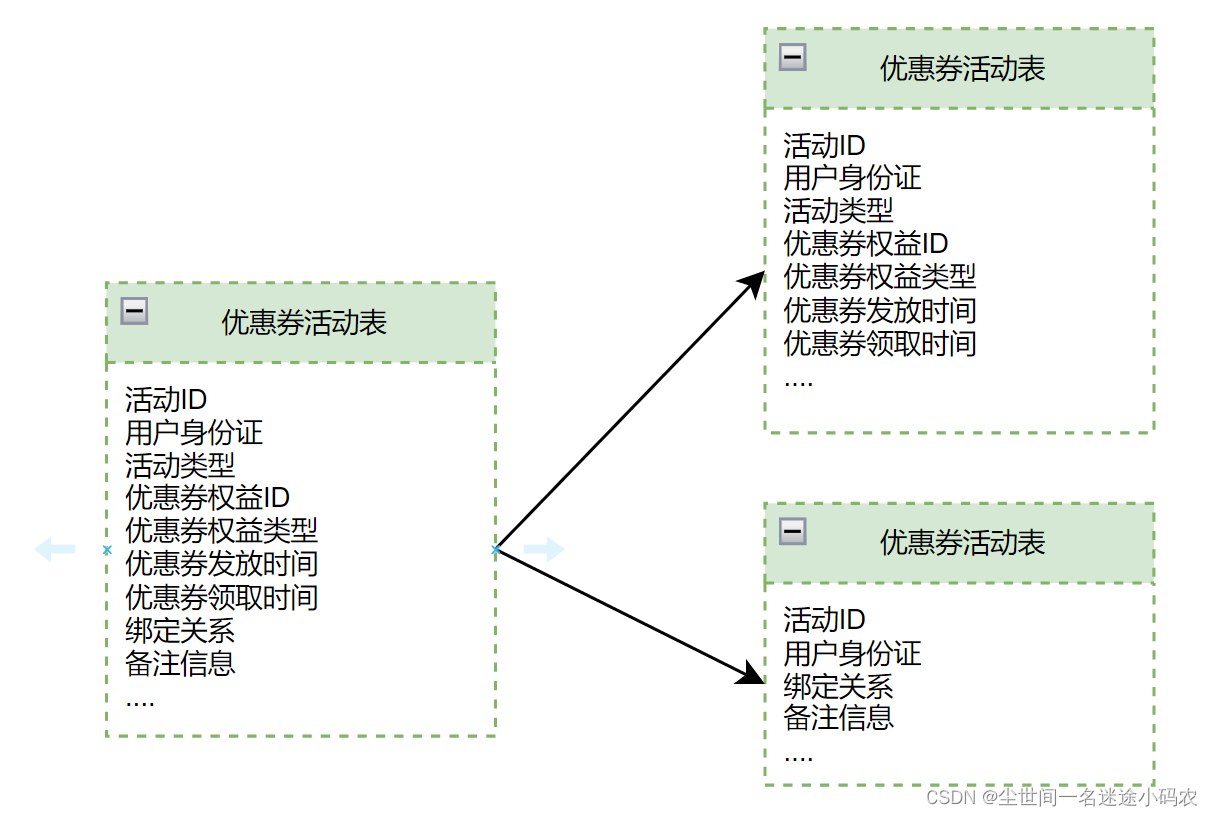
水平分表
接着,水平分表。那问题来了,究竟怎么切分会既能满足C端的高性能又能满足B端的低时延?我们这里做了些妥协和折中。
水平分表问题又是啥呢?
-
如果按用户身份证号hash后取模来做 的话,C端用户查询就不用跨分区且数据比较均衡;但是缺点也很明显,就是B端运营查询会带来多分区查询并且要做查询结果聚合。方法也有一大堆,要么就自己写个查询聚合层,要么就通过中间件(如ShardingJDBC);
-
如果按月份来做分区键的话,B端用户就比较好做了,因为目前运营做的活动基本不超过2个月,因此基本跨分区也就2个分区,影响不大;但是C端用户因为访问量比较大,且有些数据(或字段)需要汇总展示在C端页面,所以跨所有分区的情况是逃不掉了;方法倒是有,针对C端页面(因为是单页应用),每往下拉一次,最多只展示一个月数据(这样就保证每次请求只拿一个分区的数据);然后汇总数据这个在每次发生交易的时候把数据更新累计到另外一个新表(这样就保证不用跨分区后还得做聚合统计)
经过综合考虑,水平分表我们还是继续坚持第一个方案,毕竟现在中间件比较成熟了,最后我们比较了一圈MyCAT和ShardingJDBC,还是选择使用ShardingJDBC,具体有两个原因,1)这个在我司之前制定的中间件选型清单中;2)ShardingJDBC是从JDBC的架构上衍生出来的;
分布式主键
但是又有一个衍生问题出来了,既然要分表,那分布式主键肯定是绕不过的。目前我们针对不同的业务场景,有的使用UUID,有的使用snowflake,有的使用REDIS的INCR来实现自定义主键。
-
UUID,它的问题在于它是生成随机数,非单调递增数值。因为MySQL InnoDB存储引擎是使用B+树来实现,它通过聚簇索引(即主键索引)来查找数据的,因此它的叶子节点是按照主键的顺序递增来存储的。但是UUID本身的随机性会导致后面生成的主键可能会小于之前的主键,这样就会导致在每次INSERT都会产生潜在的页分裂,聚簇索引空间会变得很大,从而对MySQL性能影响很大。
-
Snowflake,它基于机器时钟来实现分布式唯一主键生成,因为我们本身是有NTP服务器来同步所有的服务器时间,时间不一致的概率较低;另外,虽然它有人所共知的时钟回拨问题,但因为我们另外一个小组已经做了二次改造封装了,因此目前看起来比较能满足我们的要求。
-
基于Redis的INCR实现的自定义主键,因为目前我们使用的Redis cluster模式(具体关于cluster模式可以看我的另外一篇分享《Redis Cluster你弄明白了吗?》),后续Redis如果有节点的迁入迁出又得考虑关联影响,且在整个改造中又牵涉多了Redis,感觉整个方案又变重了。
最后,综合考量运维成本、系统关联风险等因素,最终还是选择了snowflake的方案,同时外加针对二次封装后的snowflake进行异常告警及兜底处理。
同时,为了在一定程度解决B端的统计问题,针对不同的运营场景做了对应的对策改造。
-
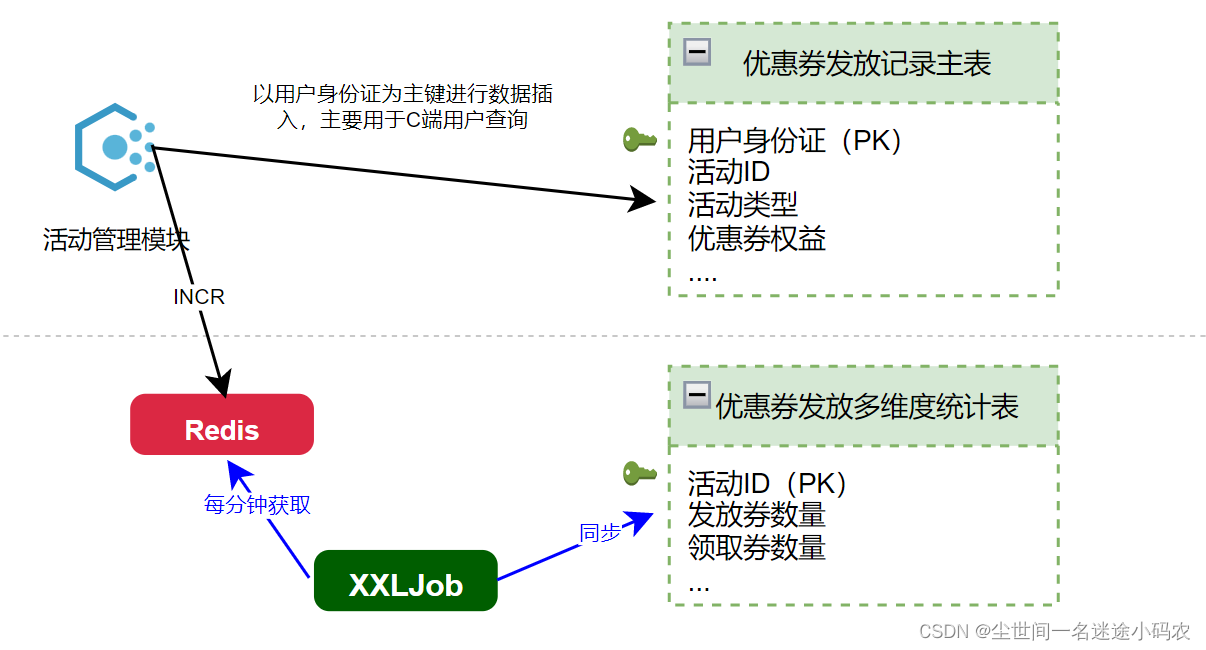
做数据冗余及异步化处理
针对聚合统计类的场景,则通过添加新的统计表来进行累计。但因为该字段一定涉及到高频读写,因此方案是先通过Redis的INCR做累加,然后XXLJOB每一分钟触发从Redis获取最新累计值并更新至统计表。例如,我们把部分需要统计的数据通过额外的新表进行累计(例如营销活动的累计发放量),避免每次统计的时候再实时获取主表数据进行实时聚合统计(毕竟1)逻辑不是单纯的单表count那么简单,涉及较多的统计规则;2)针对这种查询更多展示的是一个快照数据,因此1-2分钟的延时业务是完全可以接受的);
唯一的麻烦在于定期按活动维度做历史数据归档的时候,需要针对这两个表关联按照一定逻辑一起做才能保证数据一致性。
-
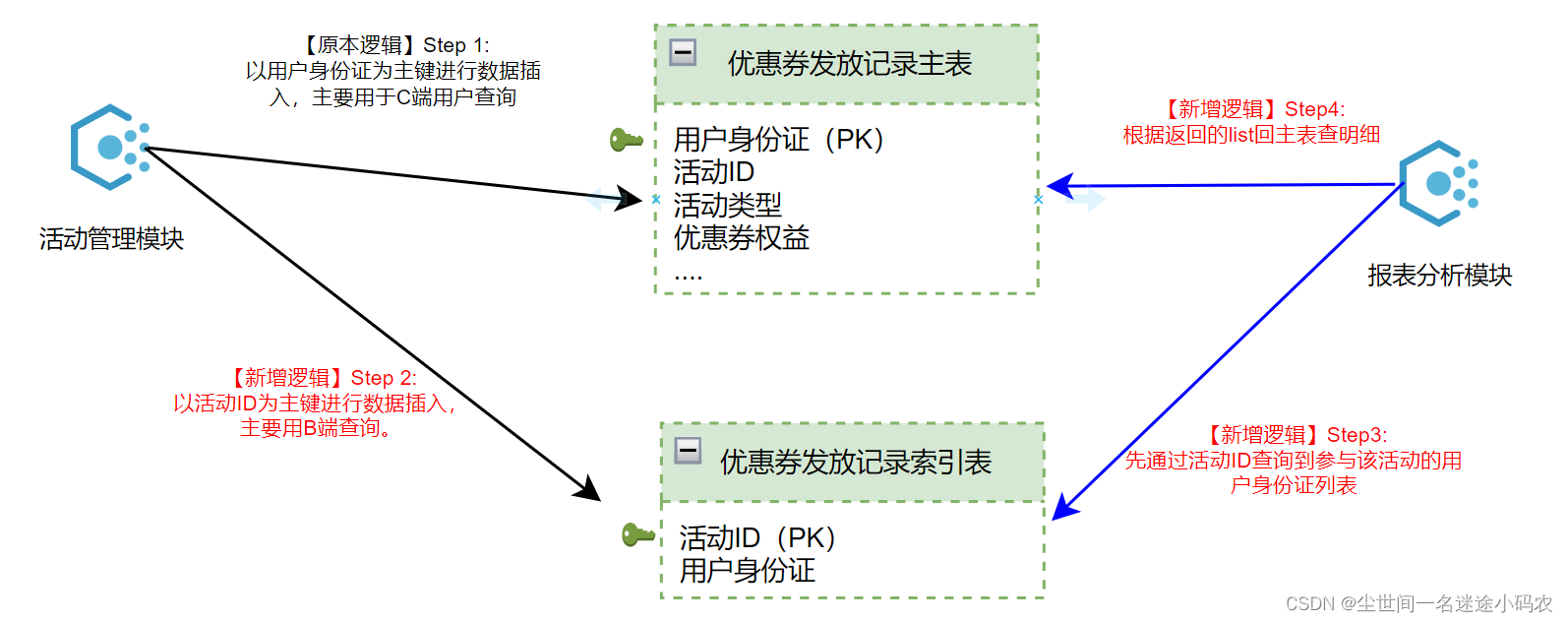
异构表索引
针对明细数据查询的场景,通过建立B端和C端的主键映射来满足两端的不同需求,但是考虑到活动数据后续会按活动维度进行数据归档或迁移且字段只有两个,因此索引表就直接采用单表。这里,在活动管理模块,针对新增的step2主要采用异步方式处理避免级联拖累C端;另外B端可以通过使用活动ID查询到参与该活动的用户身份证列表,接着使用该发放记录主表的主键查询明细。
三、后期展望
系统继续膨胀,业务量继续扩大,上述的方案据我的评估继续支撑未来2~3年应该问题不大的了;但是目前系统数据量在WEB应用系统层面已经是天花板了,也没有其他团队使用TiDB这种分布式数据库,所以目前我们在数据库层面在持续做两个事情:
-
进一步评估做微服务拆分,并适当的做一些分库处理;
-
主要在做TiDB的相应技术储备;






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结