您现在的位置是:首页 >技术交流 >MongoDB索引网站首页技术交流
MongoDB索引
提示:以下是本篇文章正文内容,MongoDB 系列学习将会持续更新

官方文档:https://www.mongodb.com/docs/manual/indexes
一、索引介绍
索引是一种用来快速查询数据的数据结构。B+Tree 就是一种常用的数据库索引数据结构,MongoDB 采用 B+Tree 做索引,索引创建在 colletions 上。MongoDB 不使用索引的查询,先扫描所有的文档,再匹配符合条件的文档。 使用索引的查询,通过索引找到文档,使用索引能够极大的提升查询效率。
数据结构动态模型:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
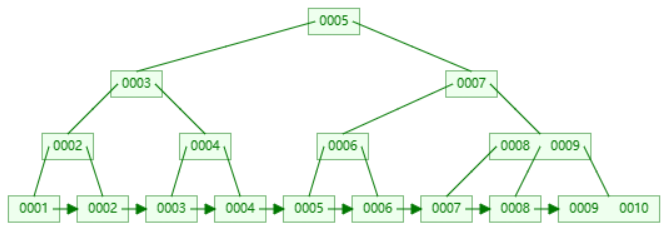
索引的分类:
- 按照索引包含的字段数量,可以分为单键索引和组合索引 (复合索引)。
- 按照索引字段的类型,可以分为主键索引和非主键索引。
- 按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引。其中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记录的指针。
- 按照索引的特性不同,又可以分为唯一索引、稀疏索引、文本索引、地理空间索引等。
二、索引操作
①创建索引
db.collection.createIndex(keys, options)
- Key 值为你要创建的索引字段,1 按升序创建索引, -1 按降序创建索引
- 可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false |
| name | String | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | Integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | Index Version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | Document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | String | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | String | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
# 创建索引, 默认索引名为title_1
db.book.createIndex({title:1})
# 创建唯一索引
db.book.createIndex({title:1},{unique:true})
# 创建复合索引
db.products.createIndex(
{ title: 1, favCount: -1 } ,
{ name: "title_favCount" }
)
②查看索引
// 查看索引信息
db.collection.getIndexes()
// 查看索引键
db.collection.getIndexKeys()
// 查看索引占用空间。is_detail为0则只显示所有索引的总大小,为1显示每个索引的大小及总大小
db.collection.totalIndexSize(is_detail)
③删除索引
// 删除集合指定索引
db.collection.dropIndex("索引名称")
// 删除集合所有索引
db.collection.dropIndexes()
三、索引类型
3.1 单键索引 (Single Field Indexes)
//在某一个特定的字段上建立了唯一的单键索引
db.book2.createIndex({title:1})
3.2 复合索引 (Compound Index)
//复合索引是多个字段组合而成的索引
db.book2.createIndex({type:1,favCount:1})
3.3 多键索引 (Multikey Index)
准备 inventory 集合:
db.inventory.insertMany([
{ _id: 1, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] },
{ _id: 2, type: "food", item: "bbb", ratings: [ 5, 9 ] },
{ _id: 3, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] },
{ _id: 4, type: "food", item: "ddd", ratings: [ 9, 5 ] },
{ _id: 5, type: "food", item: "eee", ratings: [ 5, 9, 5 ] }
])
创建多键索引:
//在数组的属性上建立索引。针对该数组的任意值都会定位到该文档,既多个索引入口或者键值
db.inventory.createIndex( { ratings: 1 } )
查询:
> db.inventory.find({ratings:{$in:[8]}})
{ "_id" : 1, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
{ "_id" : 3, "type" : "food", "item" : "ccc", "ratings" : [ 9, 5, 8 ] }
创建复合多键索引:
db.inventory.createIndex( { item:1,ratings: 1} )
3.4 地理空间索引 (Geospatial Index)
假设商家的数据模型如下:
db.restaurant.insert({
restaurantId: 0,
restaurantName:"兰州牛肉面",
location : {
type: "Point",
coordinates: [ -73.97, 40.77 ]
}
})
创建一个 2dsphere 索引:
db.restaurant.createIndex({location : "2dsphere"})
查询附近10000米商家信息:
db.restaurant.find( {
location:{
$near :{
$geometry :{
type : "Point" ,
coordinates : [ -73.88, 40.78 ]
} ,
$maxDistance:10000
}
}
} )
$near 查询操作符,用于实现附近商家的检索,返回数据结果会按距离排序。
$geometry 操作符用于指定一个 GeoJSON 格式的地理空间对象。type=Point 表示地理坐标点,coordinates 则是用户当前所在的经纬度位置;
$maxDistance 限定了最大距离,单位是米。
3.5 全文索引 (Text Indexes)
数据准备:
db.stores.insert([
{ _id: 1, name: "Java Hut", description: "Coffee and cakes" },
{ _id: 2, name: "Burger Buns", description: "Gourmet hamburgers" },
{ _id: 3, name: "Coffee Shop", description: "Just coffee" },
{ _id: 4, name: "Clothes Clothes Clothes", description: "Discount clothing"},
{ _id: 5, name: "Java Shopping", description: "Indonesian goods" }
])
创建索引:
//通过建立文本索引来实现简易的分词检索。$text 操作符可以执行文本检索。
db.stores.createIndex( { description: "text" } )
查询:
> db.stores.find({$text: {$search: "java coffee shop"}})
{ "_id" : 3, "name" : "Coffee Shop", "description" : "Just coffee" }
{ "_id" : 1, "name" : "Java Hut", "description" : "Coffee and cakes" }
3.6 Hash索引 (Hashed Indexes)
不同于传统的 B-Tree 索引,哈希索引使用 hash 函数来创建索引。在索引字段上进行精确匹配,但不支持范围查询,不支持多键 hash; Hash 索引上的入口是均匀分布的,在分片集合中非常有用。
db.users.createIndex({username : 'hashed'})
3.7 通配符索引 (Wildcard Indexes)
MongoDB 的文档模式是动态变化的,而通配符索引可以建立在一些不可预知的字段上,以此实现查询的加速。MongoDB4.2 引入了通配符索引来支持对未知或任意字段的查询。
准备商品数据,不同商品属性不一样:
db.products.insert([
{
"_id" : 1,
"product_name" : "Spy Coat",
"product_attributes" : {
"material" : [ "Tweed", "Wool", "Leather" ],
"size" : { "length" : 72, "units" : "inches"}
}
},
{
"_id" : 2,
"product_name" : "Spy Pen",
"product_attributes" : {
"colors" : [ "Blue", "Black" ],
"secret_feature" : { "name" : "laser", "power" : "1000", "units" : "watts"}
}
},
{
"_id" : 3,
"product_name" : "Spy Book"
}
])
创建通配符索引:
db.products.createIndex( { "product_attributes.$**" : 1 } )
查询:通配符索引可以支持任意单字段查询 product_attributes 或其嵌入字段
db.products.find( { "product_attributes.size.length" : { $gt : 60 } } )
db.products.find( { "product_attributes.material" : "Leather" } )
db.products.find( { "product_attributes.secret_feature.name" : "laser" } )
- 通配符索引不兼容的索引类型或属性。(Compound、TTL、Text、2d、2dsphere、Hashed、Unique)
- 通配符索引是稀疏的,不索引空字段。因此,通配符索引不能支持查询字段不存在的文档。
- 通配符索引为文档或数组的内容生成条目,而不是文档/数组本身。因此通配符索引不能支持精确的文档/数组相等匹配。通配符索引可以支持查询字段等于空文档 {} 的情况。
如,不支持 db.products.find({ "product_attributes.colors" : [ "Blue", "Black" ] } )
四、索引属性
4.1 唯一索引 (Unique Indexes)
通过建立唯一性索引,可以保证集合中文档的指定字段拥有唯一值。
// 创建唯一索引
db.book2.createIndex({title:1},{unique:true})
// 复合索引支持唯一性约束
db.book2.createIndex({title:1, type:1},{unique:true})
// 多键索引支持唯一性约束
db.inventory.createIndex({ratings:1},{unique:true})
4.2 部分索引 (Partial Indexes)
部分索引仅对满足指定过滤器表达式的文档进行索引。
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)
查询:
// 符合条件,使用索引
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )
// 不符合条件,不能使用索引
db.restaurants.find( { cuisine: "Italian" } )
注意:唯一约束结合部分索引使用导致唯一约束失效的问题。
// 只有满足筛选器表达式的文档,才满足唯一约束。
db.users.createIndex(
{ username: 1 },
{ unique: true, partialFilterExpression: { age: { $gte: 21 } } }
)
4.3 稀疏索引 (Sparse Indexes)
索引的稀疏属性确保索引只包含具有索引字段的文档的条目,索引将跳过没有索引字段的文档。
# 只对包含xmpp_id字段的文档进行索引
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )
注意:稀疏索引会导致查询和排序操作的结果集不完整。
db.scores.insertMany([
{"userid" : "newbie"},
{"userid" : "abby", "score" : 82},
{"userid" : "nina", "score" : 90}
])
db.scores.createIndex( { score: 1 } , { sparse: true } )
// 使用稀疏索引
db.scores.find( { score: { $lt: 90 } } )
// 不使用稀疏索引,以返回完整的结果
db.scores.find().sort( { score: -1 } )
// 想使用稀疏索引,使用hint()显式指定索引, 但结果集不完整
db.scores.find().sort( { score: -1 } ).hint( { score: 1 } )
4.4 TTL索引 (TTL Indexes)
TTL索引需要声明在一个日期类型的字段中,TTL 索引是特殊的单字段索引,MongoDB 可以使用它在一定时间或特定时钟时间后自动从集合中删除文档。
db.log_events.insertOne( {
"createDate": new Date(),
"logMessage": "Success!"
} )
创建TTL索引:
db.log_events.createIndex( { "createDate": 1 }, { expireAfterSeconds: 20 } )
修改过期时间:
db.runCommand({
collMod:"log_events",
index:{keyPattern:{createDate:1},expireAfterSeconds:600}
})
注意:
- TTL 索引只能支持单个字段,并且必须是非 _id 字段。
- TTL 索引不能用于固定集合。
- TTL 索引无法保证及时的数据清理,MongoDB 会通过后台的 TTLMonitor 定时器来清理老化数据,默认的间隔时间是1分钟。当然如果在数据库负载过高的情况下,TTL 的行为则会进一步受到影响。
- TTL 索引对于数据的清理仅仅使用了
remove命令,这种方式并不是很高效。因此TTL Monitor在运行期间对系统CPU、磁盘都会造成一定的压力。相比之下,按日期分表的方式操作会更加高效。
4.5 隐藏索引 (Hidden Indexes)
隐藏索引对查询规划器不可见,不能用于支持查询。通过对规划器隐藏索引,用户可以在不实际删除索引的情况下评估删除索引的潜在影响。如果影响是负面的,用户可以取消隐藏索引,而不必重新创建已删除的索引。4.4新版功能。
// 创建隐藏索引
db.restaurants.createIndex({ borough: 1 },{ hidden: true });
// 隐藏现有索引
db.restaurants.hideIndex( { borough: 1} );
db.restaurants.hideIndex( "索引名称" )
// 取消隐藏索引
db.restaurants.unhideIndex( { borough: 1} );
db.restaurants.unhideIndex( "索引名称" );
五、explain 执行计划
db.collection.find().explain(<verbose>)
| verbose 模式 | 描述 |
|---|---|
| queryPlanner | 默认输出模式。执行计划的详细信息,包括查询计划、集合信息、查询条件、最佳执行计划、查询方式和 MongoDB 服务信息等 |
| exectionStats | 最佳执行计划的执行情况和被拒绝的计划等信息 |
| allPlansExecution | 选择并执行最佳执行计划,并返回最佳执行计划和其他执行计划的执行情况 |
stage 状态:
| 状态 | 描述 |
|---|---|
| COLLSCAN | 全表扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 根据索引检索指定文档 |
| SHARD_MERGE | 将各个分片返回数据进行合并 |
| SORT | 在内存中进行了排序 |
| LIMIT | 使用limit限制返回数 |
| SKIP | 使用skip进行跳过 |
| IDHACK | 对_id进行查询 |
| SHARDING_FILTER | 通过mongos对分片数据进行查询 |
| COUNTSCAN | count不使用Index进行count时的stage返回 |
| COUNT_SCAN | count使用了Index进行count时的stage返回 |
| SUBPLA | 未使用到索引的$or查询的stage返回 |
| TEXT | 使用全文索引进行查询时候的stage返回 |
| PROJECTION | 限定返回字段时候stage的返回 |
执行计划的返回结果中尽量不要出现以下 stage:
- COLLSCAN (全表扫描)
- SORT (使用sort但是无index)
- 不合理的 SKIP
- SUBPLA (未用到index的$or)
- COUNTSCAN (不使用index进行count)
总结:
提示:这里对文章进行总结:
本文是对MongoDB的学习,先认识了MongoDB的数据存储结构和索引数据结构,又学习了如何创建、查看、删除索引,最后深入学习了索引的多种类型和属性。之后的学习内容将持续更新!!!





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结