您现在的位置是:首页 >技术杂谈 >05- 算法解读 R-CNN (目标检测)网站首页技术杂谈
05- 算法解读 R-CNN (目标检测)
要点:
- R-CNN可以说是利用深度学习进行目标检测的开山之作。
一 R-CNN算法
R-CNN可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次 在PASCAL VOC的目标检测竞赛中折桂,曾在2010年带领团队获得终身成就奖。
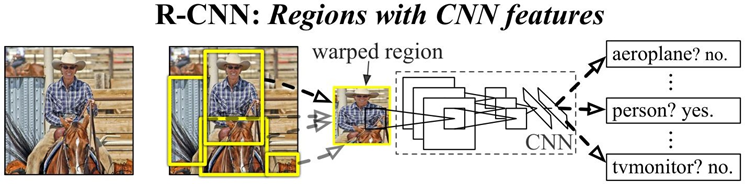
RCNN算法流程可分为4个步骤:
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM 分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
1.1 候选区域的生成
利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
Selective Search算法是一种基于目标检测的图像分割算法,它能够将图像分成多个区域,每个区域都具有相似的纹理、颜色和其他特征。这个算法可以用于物体识别和检测等计算机视觉任务中。
Selective Search算法的核心思想是通过不断合并相似的小块来生成更大的区域。具体来说,它首先将图像分成许多小块,然后计算这些小块之间的相似度,并将相似度高的小块合并成一个更大的超像素。这个过程会重复多次,直到整张图像都被分成若干个超像素。
在Selective Search算法中,相似度的计算可以使用多种方法,例如颜色直方图、边缘密度、纹理等。此外,为了提高算法的效率,Selective Search还可以使用快速的图像分割技术,如Felzenszwalb和Huttenlocher算法。
最终,Selective Search算法会生成一个超像素图像,其中每个超像素都代表了一个具有相似特征的图像区域。这个超像素图像可以作为物体检测和识别等计算机视觉算法的输入,从而提高其精度和效率。

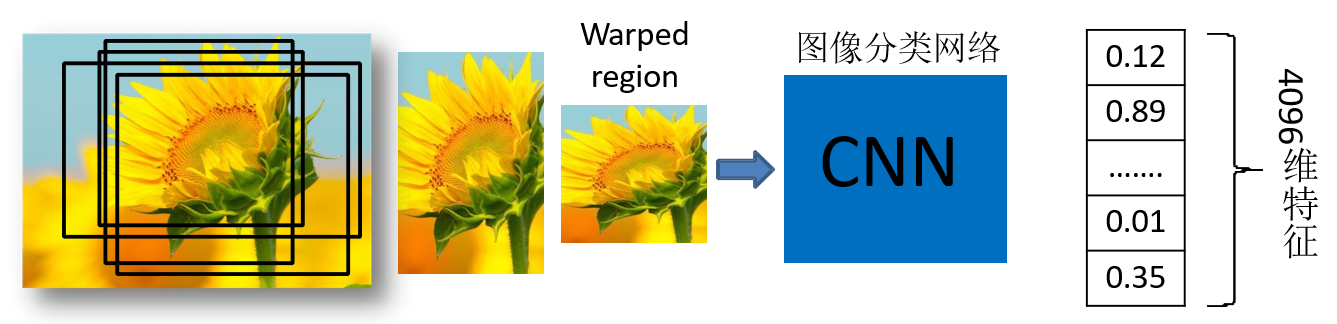
1.2 对每个候选区域,使用深度网络提取特征
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵。
1.3 特征送入每一类的SVM分类器,判定类别
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘, 获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别 对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重 叠建议框,得到该列即该类中得分最高的一些建议框。
将2000×4096的特征矩阵与20个SVM组成的权值矩阵4096×20 相乘,获得2000×20的概率矩阵,每一行代表一个建议框归于每个 目标类别的概率。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
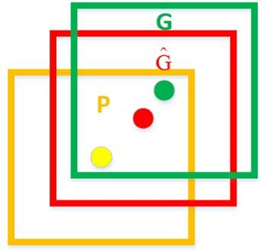
IoU(Intersection over Union) 表示(A∩B)/(A∪B)

1.4 使用回归器精细修正候选框位置
R-CNN框架

1.5 R-CNN存在的问题
-
测试速度慢 :测试一张图片约 53s(CPU) 。用 Selective Search 算 法 提取候选框用时约 2 秒,一张图像内 候选框之间存在 大 量重叠 ,提取特征操作冗余 。
-
训练速度慢 :过程及其繁 琐
-
训练所需空间大 :对于 SVM 和 bbox 回归训练,需要从每个图像中的每个目标候选 框 提取特征,并写入磁盘。对于非常深的网络,如 VGG16 ,从 VOC07 训练集上的 5k 图像上提取的特征需要数百 GB 的存储空间 。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结