您现在的位置是:首页 >技术教程 >PointNet:利用深度学习对点云进行3D分类和语义分割网站首页技术教程
PointNet:利用深度学习对点云进行3D分类和语义分割
PointNet:利用深度学习对点云进行3D分类和语义分割
参考自,PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
代码仓库地址为:https://github.com/charlesq34/pointnet/
介绍
这次介绍的是一个比较基础的工作,针对空间点云,进行分类或者语义分割的框架,现在通常也被用作对RGB-D图像进行特征提取的部分。
该工作的目的就是,输入点云信息,得到每一个点的语义,或者是得到整个点云代表的物体信息。
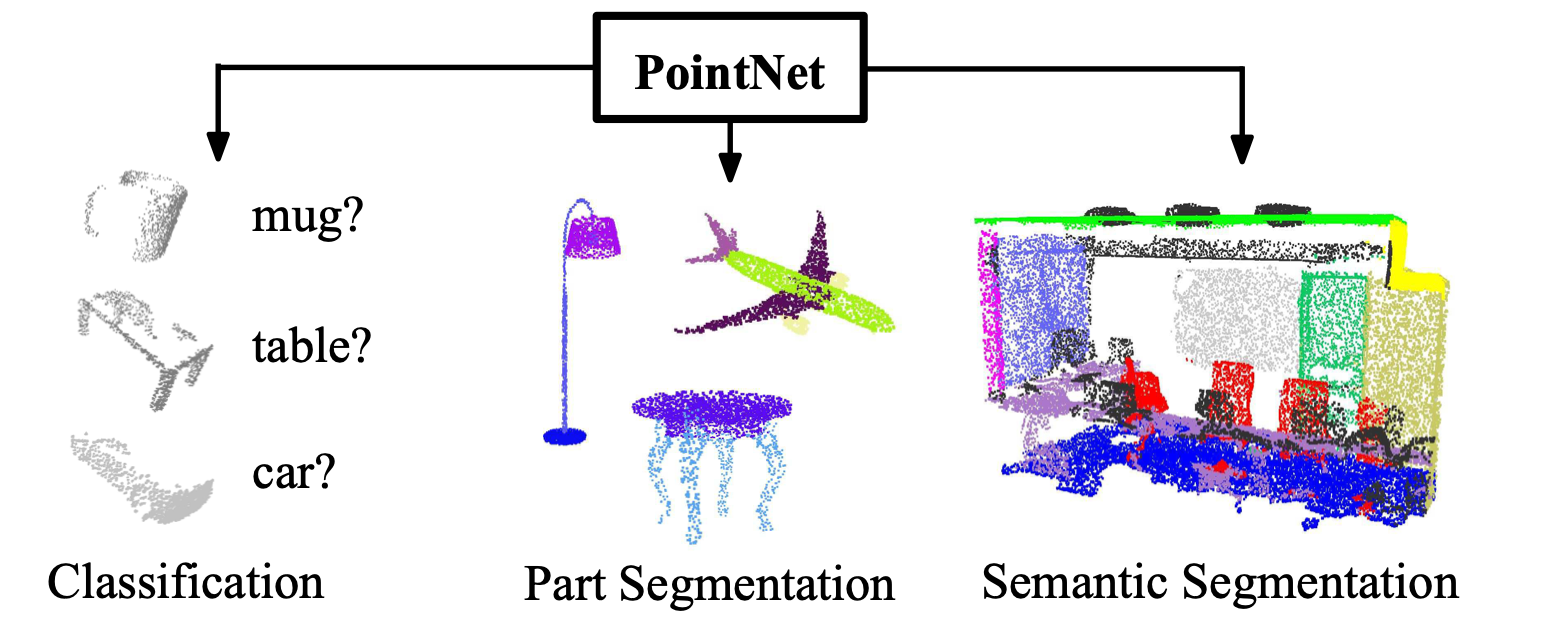
如上图所示,该工作可以对点云数据进行分类,语义分割,部分分割等。
具体细节
首先,我们假设点云为一系列点的集合,记为 { P 1 , P 2 , . . . , P n } {P_1, P_2, ...,P_n} {P1,P2,...,Pn}
每一个点,都有坐标 ( x , y , z ) (x,y,z) (x,y,z),以及代表色彩的通道值,如果是rgb,那就是3个通道的值
这里直接给出整个PointNet的结构图
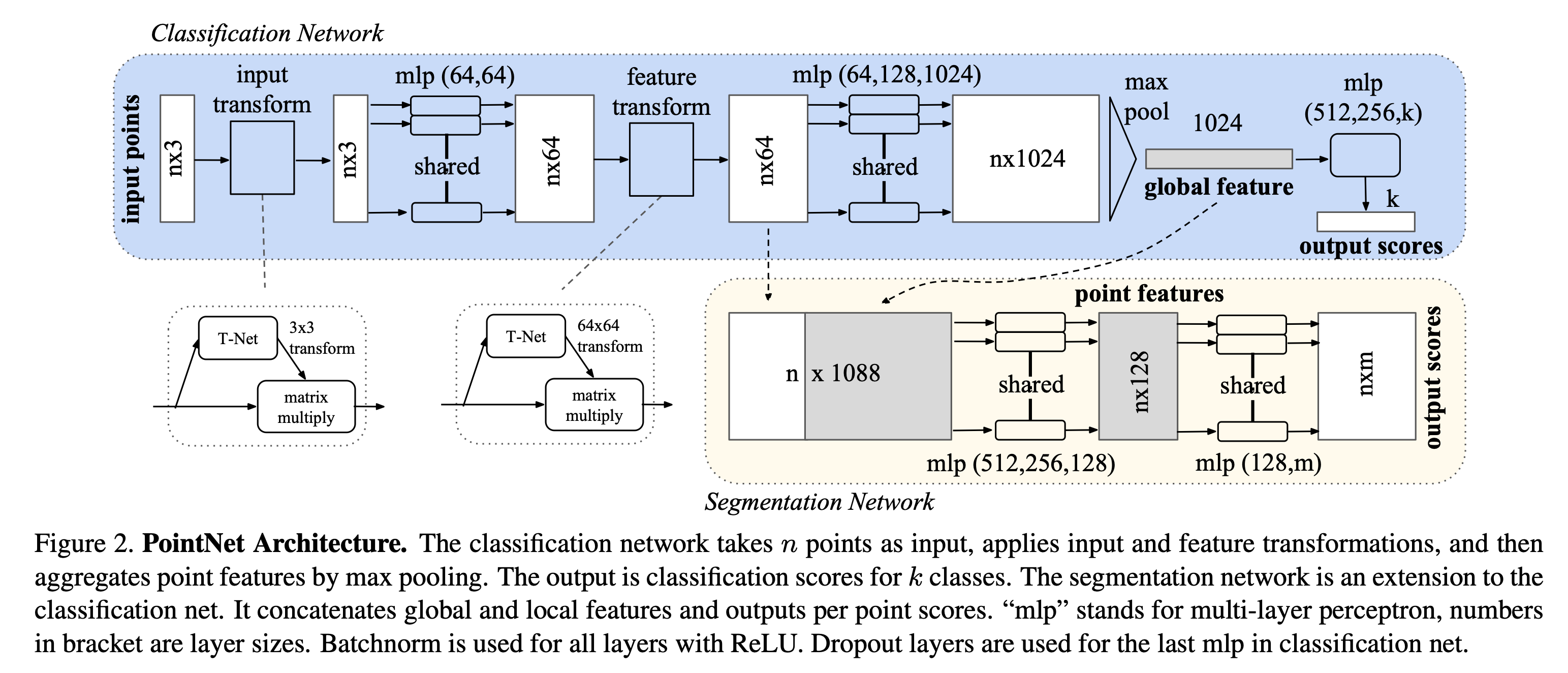
我们首先来看蓝色背景的部分,代表一个分类网络,输入是一个 n × 3 n imes 3 n×3 的点云信息,其中 n n n 是点的数目, 3 3 3 代表着空间坐标的维度
最终输出一个 k k k 维的分数,代表对 k k k 个物体的分类置信度。
我们来仔细看一下处理的过程:
1. Input Transform
这一部分由一个T-Net和矩阵乘法构成,最终输出的形状还是 n × 3 n imes 3 n×3
通过分析其代码,可以知道,该T-Net由3个卷积层,1个最大池化层以及2个线性层组合而成
最终输出一个 3 × 3 3 imes 3 3×3 的变换矩阵,然后右乘上输入(输入的形状是 n × 3 n imes 3 n×3 )得到 n × 3 n imes 3 n×3 的输出
直觉上看,就是用一个小的网络学习一个线性变换,对输入的点云做处理
2. MLP
代码中使用的是两个卷积层:
- 先用一个 1 × 3 1 imes 3 1×3 的卷积,输出通道数为 64 64 64
- 然后是一个 1 × 1 1 imes 1 1×1 的卷积,输出通道也是 64 64 64
所以最终的输出是 n × 64 n imes 64 n×64 的形状
3. Feature Transform
和先前一样,用T-Net输出一个 64 × 64 64 imes 64 64×64 的线性变换矩阵右乘上去
4. MLP
用三个 1 × 1 1 imes1 1×1 的卷积,将通道数直接提升到了 1024 1024 1024,输出的形状也就是 n × 1024 n imes 1024 n×1024
本质上和线性层是一样的
5. MaxPool
过一个MaxPool,kernel大小设置成 1 × n 1 imes n 1×n ,直接得到一个 1024 1024 1024 维的特征向量
6. MLP
最后直接用三个线性层,将输出转换成 k k k 维的分类置信度
语义分割的细节
这里合并了两个特征,形状分别是 n × 64 n imes 64 n×64 和 1024 1024 1024
将 1024 1024 1024 长度的特征向量复制 n n n 次,接在 64 64 64 维的向量后面,便得到 n × 1088 n imes 1088 n×1088 的输出
过一系列MLP,最终输出 n × m n imes m n×m 形状的矩阵, m m m 代表语义分割的类别
实验分析
物体分类
首先是在ModelNet40数据集上分类的准确率
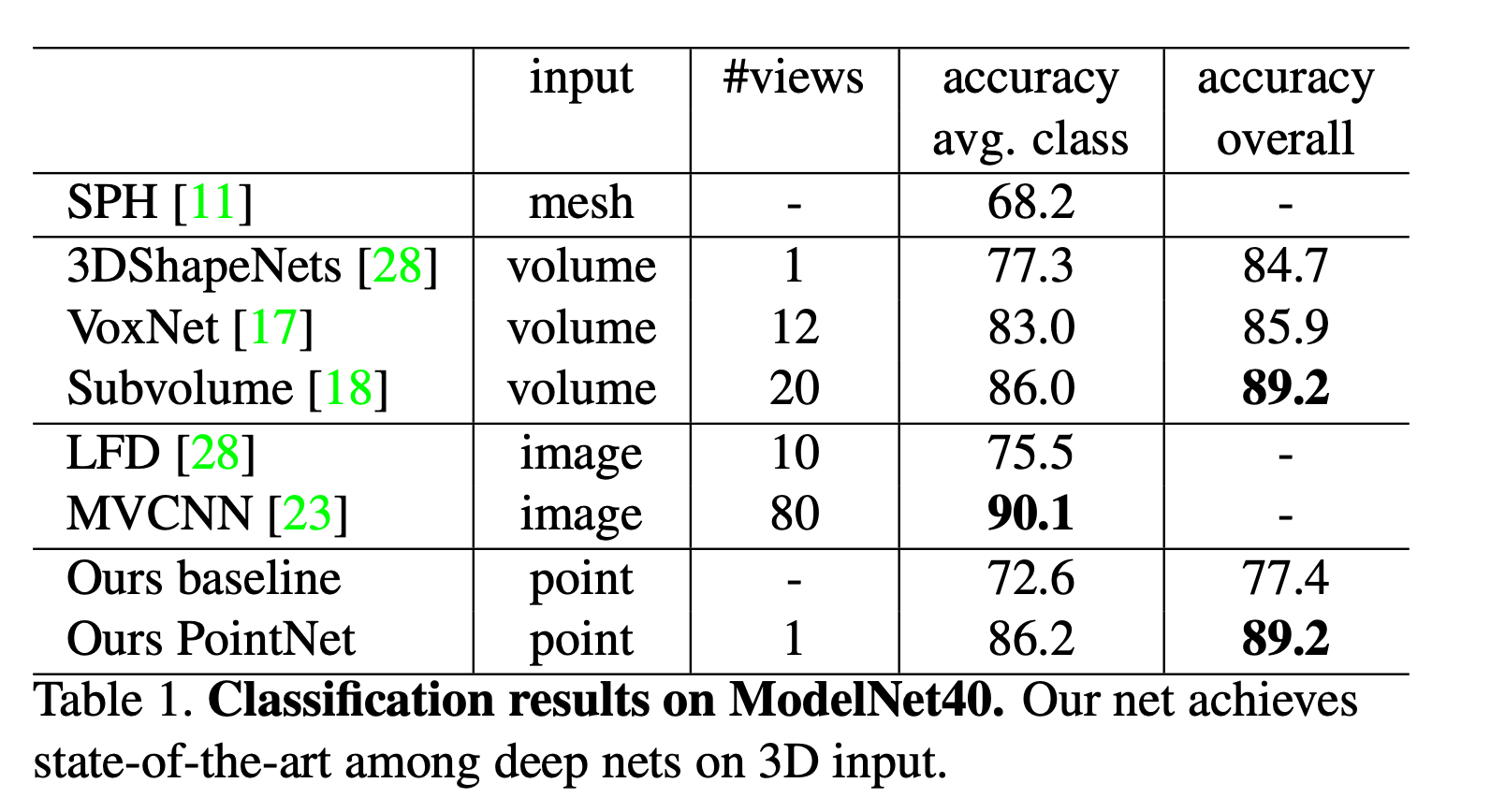
基本上在3D输入上达到了SOTA的性能,整体正确率为89.2%。
语义分割
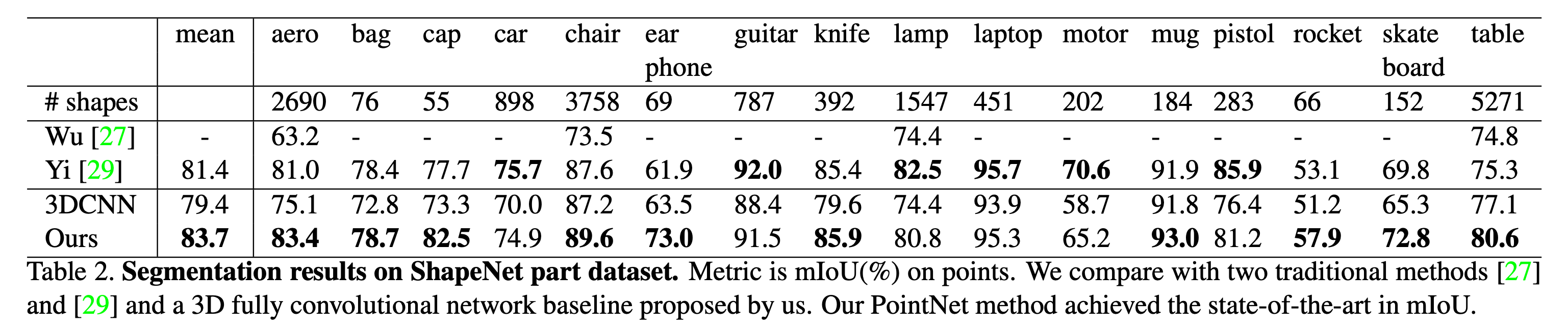
可以看到,比起3D全卷积的baseline,mIoU也是达到SOTA的性能






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结