Spring可以通过以下方法来避免循环依赖:
-
构造函数注入:使用构造函数注入来注入依赖项,这是一种比较安全的方式,因为在对象创建时就会注入依赖项,可以避免循环依赖。
-
Setter方法注入:使用Setter方法注入依赖项,Spring会在对象创建后调用Setter方法来注入依赖项,这种方式也可以避免循环依赖。
-
使用@Lazy注解:使用@Lazy注解来延迟依赖项的注入,这样可以避免循环依赖。
-
使用@DependsOn注解:使用@DependsOn注解来指定bean创建的顺序,可以避免循环依赖。
-
使用 @Lookup 注解: 在这种情况下,Spring 容器会在每次调用 @Lookup 注解修饰的方法时,返回一个新的 bean 实例。这样,就可以确保两个 bean 之间没有直接的依赖关系。
-
spring自带的三级缓存【使用代理】: (默认)使用 AOP 代理来实现 bean 之间的依赖关系。在编译时就解决循环依赖问题。
三级缓存的作用是 Spring IoC 的难点,搞清楚它的原理和背后的原因非常有必要!
前言
spring bean 的 创建三步:
-
创建bean类的实例
-
注入属性
-
bean对象的初始化
单例模式
一般在单例模式中,会使用双重检查锁定(Double-Checked Locking)来保证线程安全。双重检查锁定是为了避免多个线程同时进入临界区,以及提高性能。具体来说:
- 第一个检查是为了保证只有少量线程能够进入临界区。这种方式可以减少锁的竞争,提高性能。
- 第二个检查是为了保证在多个线程中只有一个线程能够创建实例。
这样可以避免(多个实例并行请求建立单例对象时,都卡在synchronized锁那里,当一个线程已经创建完实例后,)在实例已经存在的情况下,多个线程继续创建实例,从而浪费资源。
```
public class Singleton {
private static volatile Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
```
在上面的代码中,我们使用了双重检查锁定来确保只有一个实例被创建。首先,在第一个检查中,我们检查实例是否已经被创建。如果没有,我们进入同步块。在同步块中,我们再次检查实例是否已经被创建。如果没有,我们创建一个新的实例。由于我们使用了volatile关键字,这确保了在并发环境下的可见性和正确性。
源码
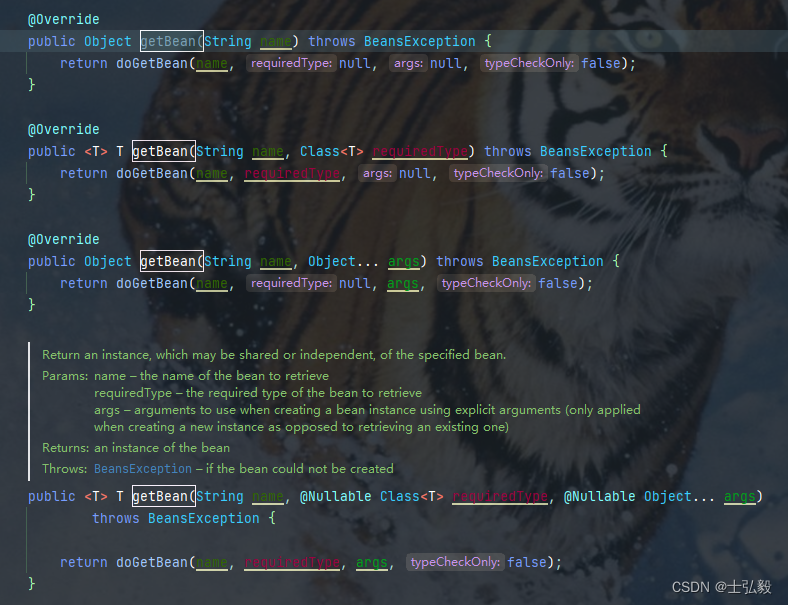
spring中bean 的创建是由 AbstractBeanFactory#getBean() 触发的。
循环依赖过程分析
AbstractBeanFactory#getBean() --> AbstractBeanFactory#doGetBean() --> DefaultSingletonBeanRegistry#getSingleton()
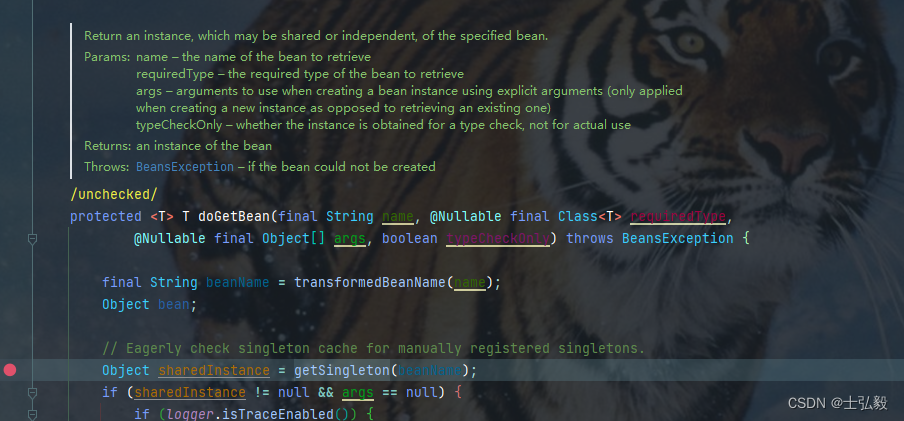
在触发 bean 的加载时,会先从缓存中获取 bean,也就是会调用 DefaultSingletonBeanRegistry#getSingleton() 方法。
跟一下 AbstractBeanFactory#getBean(java.lang.String) 的源码,会发现它会调用 DefaultSingletonBeanRegistry#getSingleton()
:
源码一
DefaultSingletonBeanRegistry#getSingleton()
从三级缓存中获取单例对象
默认的单例bean注册器 DefaultSingletonBeanRegistry#getSingleton()
~~~
// 参数allowEarlyReference:允许早期引用 【默认是true】:
protected Object getSingleton(String beanName, boolean
allowEarlyReference) {
// 从一级缓存中 快速检查有没有 完全初始化的现有实例
Object
singletonObject = this.
singletonObjects.get(beanName);
//
类似于单例模式的双锁校验。 一级缓存 中没有 beanName, 且 beanName 正在创建中
if (
singletonObject
== null && this.isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.
singletonObject) {
//现在 二级缓存中查
singletonObject = this.
earlySingletonObjects.get(beanName);
// 判断 等于null才处理,避免多个竞争锁的线程都走一遍创建
//(加判定后,都去读二级缓存就可以了),且允许早期引用时才继续
if (
singletonObject
== null &&
allowEarlyReference) {
// 先去三级缓存中 查询 ,三级缓存有时才创建!
ObjectFactory<?> singletonFactory = this.
singletonFactories.get(beanName);
if (
singletonFactory
!=
null) {
// 获取引用对象存于三级缓存中, 再存入 earlySingletonObjects,并返回此对
//象。 对应三级缓存中删除相应工厂类
singletonObject = singletonFactory.getObject();
this.
earlySingletonObjects.put(beanName,
singletonObject);
this.
singletonFactories.remove(beanName);
}
}
}
}
return
singletonObject;
}
~~~
以上就是三级缓存的代码。其中:
cache of singleton objects: bean name to bean instance.
用于存放已经完全初始化好的 bean
cache of early singleton objects: bean name to bean instance.
用于存放
bean 的早期引用
(只实例化类,还没初始化的对象)(
已经创建,尚未完全初始化的单例对象)(循环依赖时才会存放并使用)
cache of singleton factories: bean name to ObjectFactory.
用于存放三级缓存 ObjectFactory 获取到的工厂对象(都会存放,循环依赖时才会使用)
批注
与 单例模式 同理,在产生循环依赖的问题时, 在二级缓存查询前就外就开始加了 synchronized的重量级锁 锁住了 singletonObject 对象,
当在并发的情况下,其他要 创建 bean /类的实例化 的线程都得处于等待的过程。
当一个线程创建完后,其他线程 判断 等于null才处理,避免多个竞争锁的线程都走一遍创建(加判定后,都去读二级缓存就可以。
这样确保只有一个线程 去走第三缓存并创建bean!
第三缓存,乍一看并没有什么特殊的意义,因为锁内的第二缓存已经线程安全的!可以用局部变量代替第三缓存(反正第三缓存用后即删了)。硬说与线程安全有和关联的话,可能是 和 三级缓存 singletonFactories 的注入/赋值有什么关联了,但此方法中并没有三级缓存的插入。三级缓存的插入在 同类下的方法中 DefaultSingletonBeanRegistry#addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory)进行插入的。说明得确保先有对应的工厂类才会去处理并创建bean实例对象。
个人感觉 此处已经与 线程安全没有啥关系了,和spring的设计思路和思想有关吧~
此方法中没有三级缓存
singletonFactories 的数据来源,即数值的插入!数据来源在 同类 DefaultSingletonBeanRegistry 下的方法中 addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory)
:
源码二
DefaultSingletonBeanRegistry#
addSingletonFactory
()
现在开始找找 三级缓存
singletonFactories
的数据来源 !!
/**
如有必要 添加给定的单例工厂以构建指定的单例。 要求对单例进行急切注册,例如能够解析循环引用。
参数singletonFactory 是 beanName和单例bean的工厂。
*/
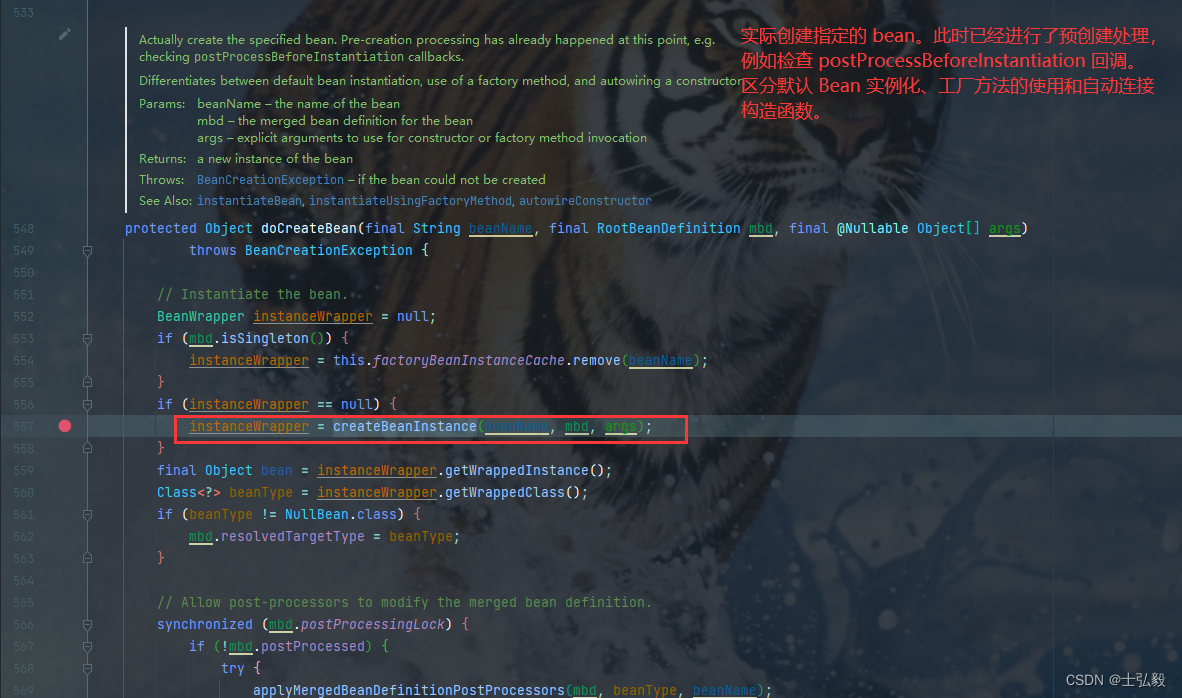
这个类的调用在 AbstractAutowireCapableBeanFactory# doCreateBean()中
:
源码三
AbstractAutowireCapableBeanFactory
#
doCreateBean
()
在bean类的 实例化之前,就已经开始准备 bean提前引用的对象 了
// 中间代码忽略。。。。。。。
在 AbstractAutowireCapableBeanFactory# doCreateBean() 中可见:
-
实例化bean类 createBeanInstance(beanName, mbd, args);
-
。。。。。。
-
第三级缓存的数值来源准备, 调用了方法:
getEarlyBeanReference(): 【源码四 见详情】
-
populateBaen 装填属性
-
获取
单例对象 getSingleton (查 一二三级缓存)
-
hasDependentBean(beanName) 查询是否有依赖的bean并处理
-
。。。。。
-
初始化 bean 实例/对象
源码四
AbstractAutowireCapableBeanFactory
#
getEarlyBeanReference
()
工厂类预先生成代理
getEarlyBeanReference方法,* 获取指定 bean 的早期引用,通常用于解析循环引用。
/**
* Obtain a reference for early access to the specified bean, typically for the purpose of resolving a circular reference.
获取引用以便提前访问指定的 Bean,通常用于解析循环引用。
* @param beanName – Bean 的名称(用于错误处理目的)。 the name of the bean (for error handling purposes)
* @param mbd – Bean 的合并 Bean 定义 . the merged bean definition for the bean
* @param bean - – 原始 Bean 实例 。 the raw bean instance
* return :要公开为 Bean 引用的对象。 the object to expose as bean reference
*/
protected Object
getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof
SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (
SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
这个工厂的作用就是判断这个对象是否需要代理,如果否 直接返回,如果需要 则创建代理对象 并返回。
Spring AOP : 自动代理创建机制 (APC)
一个APC其实是一个SmartInstantiationAwareBean
PostProcessor
, 它会介入每个bean的 类实例化 和 对象的初始
化
,检测bean的特征。如果该bean符合某些特征,比如有拦截器需要应用到该bean,那么该APC就会为它自动创建一个代理对象,使用相应的拦截器包裹住该bean。
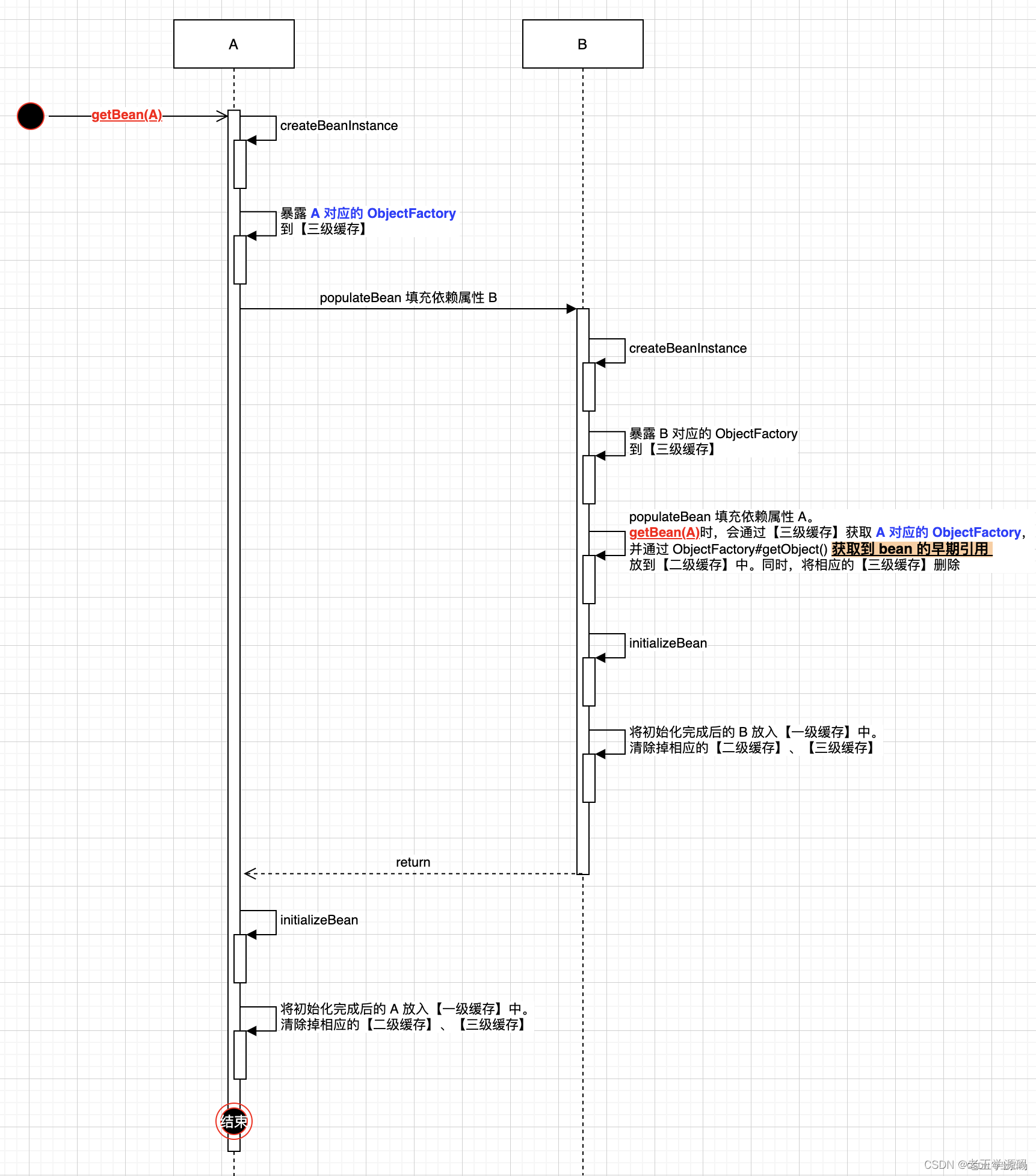
循环依赖 流程图
在有循环依赖的情况下:(A --> B --> A 的场景)
A 第一次加载时,会将 A 对应的 ObjectFactory 放到三级缓存中;
当 B 创建完实例后,进行 populateBean 填充依赖时,会通过 getBean(A) 来获取 bean A,这时会使用 A 对应的三级缓存 ObjectFactory 来获取 bean A 的早期引用。
总结
问题 : spring为什么要用三级缓存?二级缓存不能实现么 ?
上述: 一级缓存 存 已经完全初始化的bean单例的对象,
二级缓存 存 类已实例化还初始化的不完全对象,
三级缓存 存的是创建类实例的工厂类对象(这一级缓存的时间还早于装填属性,在检测到循环依赖之前。)
在二级缓存没有时,再去获取这个工厂类对象,并将结果存于二级缓存也是可行的!但是:
正常的代理的对象初始化后期调用生成的,是基于后置处理器PostProcessor的,若提早的代理就违背了Bean定义的生命周期。所以spring在一个三级缓存放置一个工厂,如果产生循环依赖 ,那么就会调用这个工厂提早的得到代理的对象。







 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结