您现在的位置是:首页 >学无止境 >微服务体系网站首页学无止境
微服务体系
简介微服务体系
目录
结构
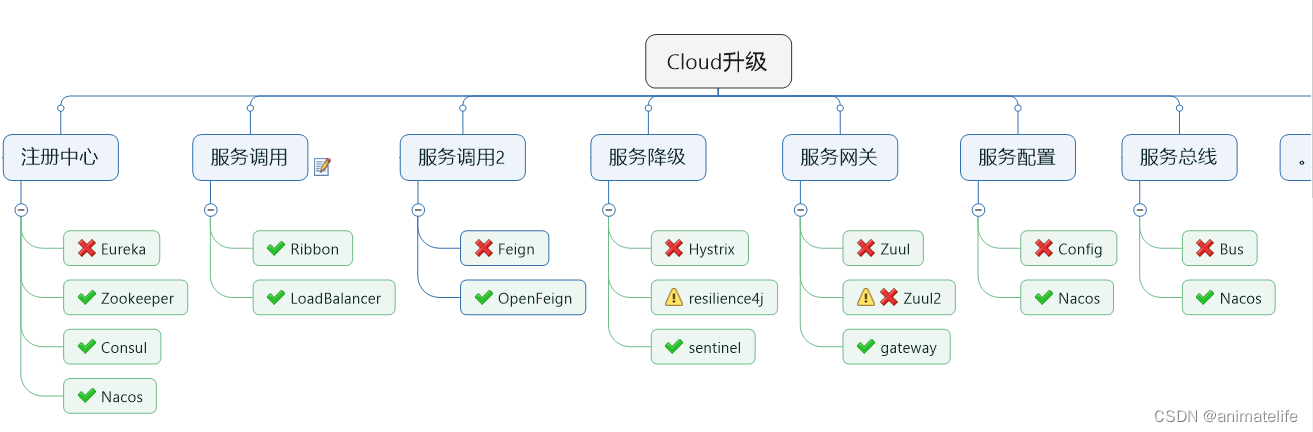
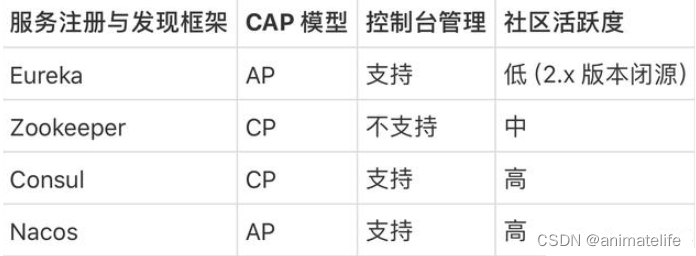
服务注册中心
- 提供服务治理、服务注册
Eureka


- Eureka Server 作为服务注册中心,本身也是一个 微服务
- Eureka Client 就是注册进 Eureka Server 的微服务,可以调用其它同样作为 Eureka Client 注册进 Eureka Server 的微服务
- Eureka 的自我保护机制

- 就是宁肯保留可能过时、错误的微服务注册信息,也不去剔除这个微服务

- 解决办法,在 Eureka Server 以及 所有注册到 Eureka Server 的服务配置中分别添加如下内容
# 在Eureka服务端禁用自我保护模式,默认为 true
eureka.server.enable-self-preservation=false
# 默认90s,改成2s
eureka.server.eviction-interval-timer-in-ms=2000
# Eureka客户端向服务端发送心跳的时间间隔,单位为秒(默认是30秒)
eureka.instance.lease-renewal-interval-in-seconds=1
# Eureka服务端在收到最后一次心跳后等待时间上限,单位为秒(默认是90秒),超时将剔除服务
eureka.instance.lease-expiration-duration-in-seconds=2
Zookeeper

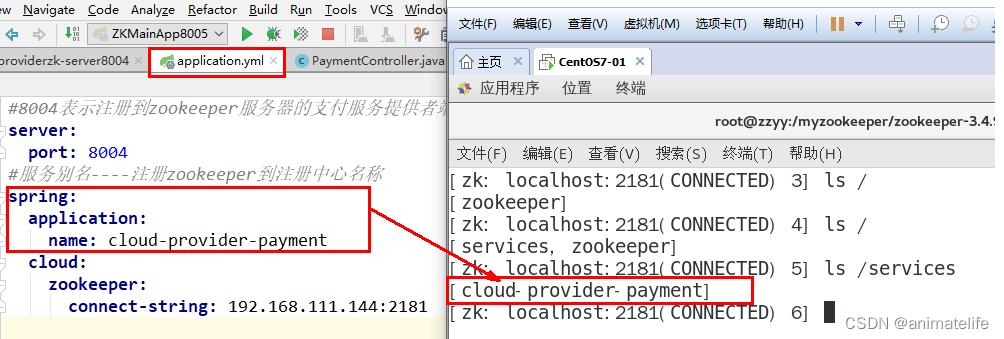
- 在服务器上安装 Zookeeper
- 在服务器上启动 Zookeeper 并将服务注册进去以后,查看服务注册信息
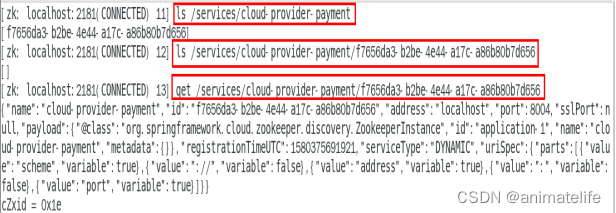
- 服务下线一会后,服务注册信息直接被删除,说明用的是临时节点,服务重新上线后,又获得新的流水号
Consul


- 具体使用参照官网,有详细教程
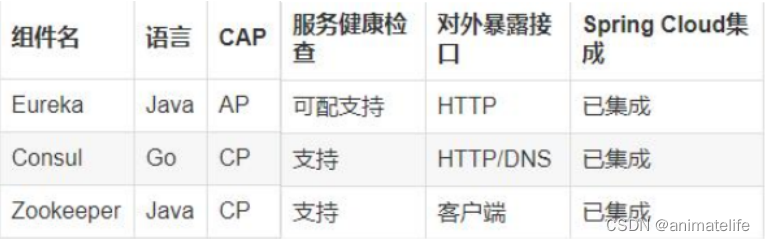
上面三者的对比


Ribbon 负载均衡负载均衡
-
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套 客户端 负载均衡 的工具
-
主要功能是提供客户端的软件负载均衡算法和服务调用,支持自定义的负载均衡算法
-
Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等
-
在配置文件中列出 Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器

-
集中式 LB 与 进程内 LB


-
负载均衡算法的实现:Ribbon 核心组件 IRule
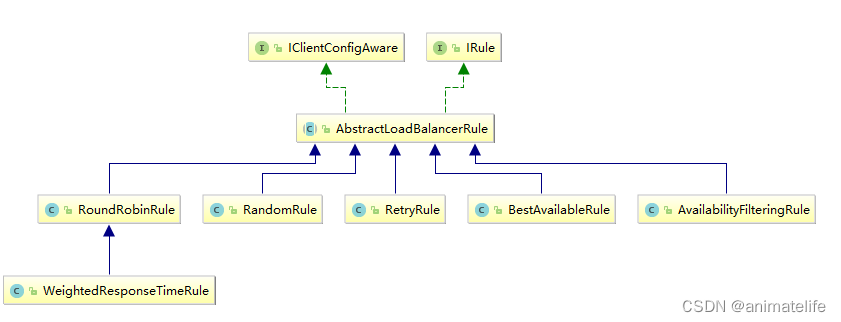

OpenFeign 远程服务调用
- OpenFeign 是一个声明式 WebService 客户端,使用 OpenFeign 能让编写Web Service 客户端更加简单
- 只需要在需要在本服务端新建一个接口,接口名和被调用的服务实现的接口名相同,接口的抽象方法和被调用的服务的具体方法名相同,包括注解,然后在这个接口上加
@FeignClient注解,就能像是客户端一样,发送请求调用别的服务 - OpenFeign 与Eureka 、Ribbon 组合使用以支持负载均衡,支持可拔插式的编码器和解码器,支持了Spring MVC标准注解和HttpMessageConverters(意味着可以直接返回Json)
- 使用 OpenFeign 的服务消费端,默认可以承受的 RT 为1s,通过配置修改
#设置feign客户端超时时间(OpenFeign默认支持ribbon)
ribbon:
#指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间
ReadTimeout: 5000
#指的是建立连接后从服务器读取到可用资源所用的时间
ConnectTimeout: 5000
- OpenFeign 的日志,就是对 OpenFeign 接口的调用情况进行监控和输出
- 创建配置类设置全局的日志级别

- 修改配置文件,指定要开启日志功能的服务
- 创建配置类设置全局的日志级别
Hystrix
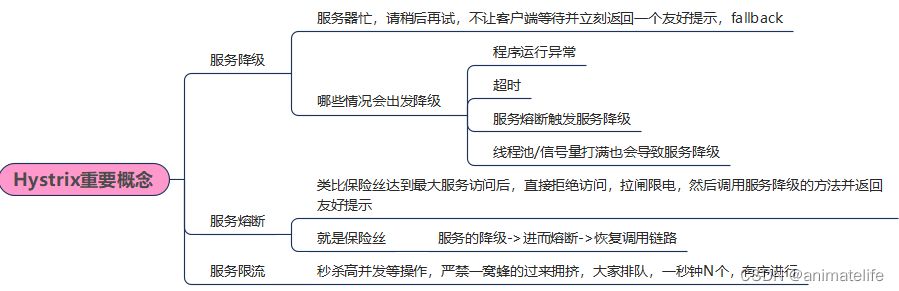

服务熔断
- 服务熔断是一种机制,利用到了服务降级,一般用在服务提供者的 service 层的方法上
- 熔断的作用是:在时间窗口内,达到要求的请求总数 且 错误率(可能是错误/可能是超时)达到 60%(有60%的请求都进入服务降级),则开启熔断(该服务的请求一直处于降级状态)
- 熔断结束:还是相同的时间窗口内,达到要求的请求总数 且 错误率(可能是错误/可能是超时)低于 60%,则关闭熔断
- 熔断打开—>熔断关闭,是一个动态调整的过程,这个过程称之为熔断半开,在时间窗口内,会尝试让部分请求(默认是熔断后5s左右开始)不进入降级,然后 正确的请求总数+ 时间窗口内 达到熔断结束的条件,则熔断结束
- 上面所说的 正确请求、错误,都是指请求的回复,正确的请求=正常的回复,错误=服务降级(fallbackMethod)的回复
常见的设置
@HystrixCommand(fallbackMethod = "str_fallbackMethod",
groupKey = "strGroupCommand",
commandKey = "strCommand",
threadPoolKey = "strThreadPool",
commandProperties = {
// 设置隔离策略,THREAD 表示线程池 SEMAPHORE:信号池隔离
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
// 当隔离策略选择信号池隔离的时候,用来设置信号池的大小(最大并发数)
@HystrixProperty(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 配置命令执行的超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutinMilliseconds", value = "10"),
// 是否启用超时时间
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
// 执行超时的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnTimeout", value = "true"),
// 执行被取消的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnCancel", value = "true"),
// 允许回调方法执行的最大并发数
@HystrixProperty(name = "fallback.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 服务降级是否启用,是否执行回调函数
@HystrixProperty(name = "fallback.enabled", value = "true"),
// 是否启用断路器
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
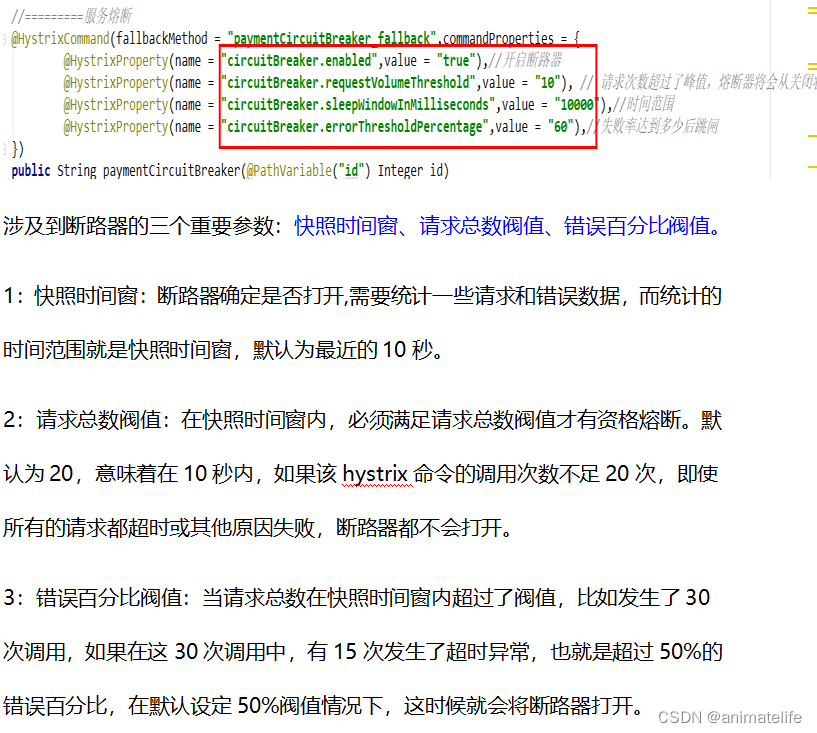
// 该属性用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为 20 的时候,
// 如果滚动时间窗(默认10秒)内仅收到了19个请求, 即使这19个请求都失败了,断路器也不会打开。
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"),
// 该属性用来设置在滚动时间窗中,表示在滚动时间窗中,在请求数量超过
// circuitBreaker.requestVolumeThreshold 的情况下,如果错误请求数的百分比超过50,
// 就把断路器设置为 "打开" 状态,否则就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
// 该属性用来设置当断路器打开之后的休眠时间窗。 休眠时间窗结束之后,
// 会将断路器置为 "半开" 状态,尝试熔断的请求命令,如果依然失败就将断路器继续设置为 "打开" 状态,
// 如果成功就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.sleepWindowinMilliseconds", value = "5000"),
// 断路器强制打开
@HystrixProperty(name = "circuitBreaker.forceOpen", value = "false"),
// 断路器强制关闭
@HystrixProperty(name = "circuitBreaker.forceClosed", value = "false"),
// 滚动时间窗设置,该时间用于断路器判断健康度时需要收集信息的持续时间
@HystrixProperty(name = "metrics.rollingStats.timeinMilliseconds", value = "10000"),
// 该属性用来设置滚动时间窗统计指标信息时划分"桶"的数量,断路器在收集指标信息的时候会根据
// 设置的时间窗长度拆分成多个 "桶" 来累计各度量值,每个"桶"记录了一段时间内的采集指标。
// 比如 10 秒内拆分成 10 个"桶"收集这样,所以 timeinMilliseconds 必须能被 numBuckets 整除。否则会抛异常
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "10"),
// 该属性用来设置对命令执行的延迟是否使用百分位数来跟踪和计算。如果设置为 false, 那么所有的概要统计都将返回 -1。
@HystrixProperty(name = "metrics.rollingPercentile.enabled", value = "false"),
// 该属性用来设置百分位统计的滚动窗口的持续时间,单位为毫秒。
@HystrixProperty(name = "metrics.rollingPercentile.timeInMilliseconds", value = "60000"),
// 该属性用来设置百分位统计滚动窗口中使用 “ 桶 ”的数量。
@HystrixProperty(name = "metrics.rollingPercentile.numBuckets", value = "60000"),
// 该属性用来设置在执行过程中每个 “桶” 中保留的最大执行次数。如果在滚动时间窗内发生超过该设定值的执行次数,
// 就从最初的位置开始重写。例如,将该值设置为100, 滚动窗口为10秒,若在10秒内一个 “桶 ”中发生了500次执行,
// 那么该 “桶” 中只保留 最后的100次执行的统计。另外,增加该值的大小将会增加内存量的消耗,并增加排序百分位数所需的计算时间。
@HystrixProperty(name = "metrics.rollingPercentile.bucketSize", value = "100"),
// 该属性用来设置采集影响断路器状态的健康快照(请求的成功、 错误百分比)的间隔等待时间。
@HystrixProperty(name = "metrics.healthSnapshot.intervalinMilliseconds", value = "500"),
// 是否开启请求缓存
@HystrixProperty(name = "requestCache.enabled", value = "true"),
// HystrixCommand的执行和事件是否打印日志到 HystrixRequestLog 中
@HystrixProperty(name = "requestLog.enabled", value = "true"),
},
threadPoolProperties = {
// 该参数用来设置执行命令线程池的核心线程数,该值也就是命令执行的最大并发量
@HystrixProperty(name = "coreSize", value = "10"),
// 该参数用来设置线程池的最大队列大小。当设置为 -1 时,线程池将使用 SynchronousQueue 实现的队列,
// 否则将使用 LinkedBlockingQueue 实现的队列。
@HystrixProperty(name = "maxQueueSize", value = "-1"),
// 该参数用来为队列设置拒绝阈值。 通过该参数, 即使队列没有达到最大值也能拒绝请求。
// 该参数主要是对 LinkedBlockingQueue 队列的补充,因为 LinkedBlockingQueue
// 队列不能动态修改它的对象大小,而通过该属性就可以调整拒绝请求的队列大小了。
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "5"),
}
)
public String strConsumer() {
return "hello";
}
public String str_fallbackMethod()
{
return "*****fall back str_fallbackMethod";
}
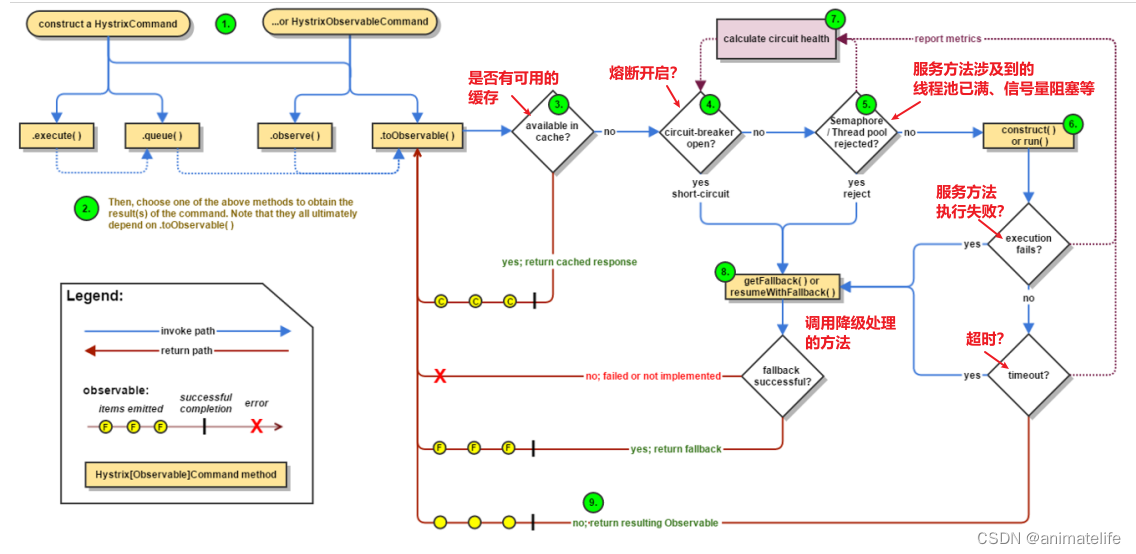
Hystrix 工作流程
Hystrix-DashBoard 的使用
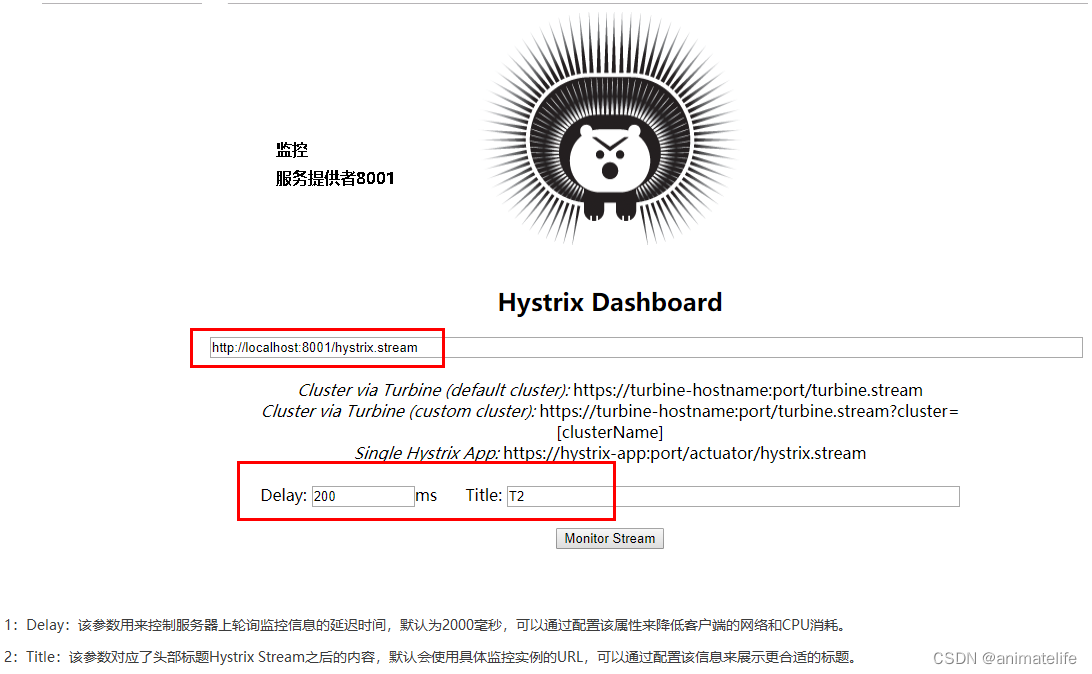
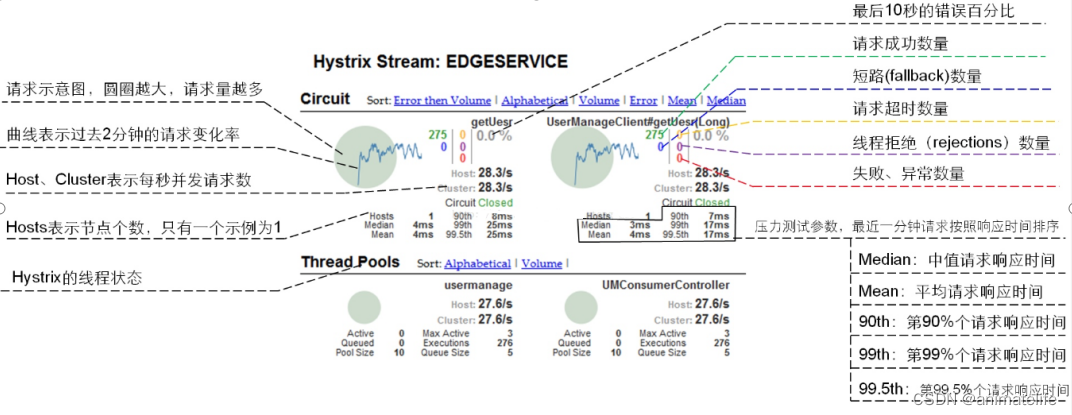
- 监听了几个服务,就有几个 圆圈
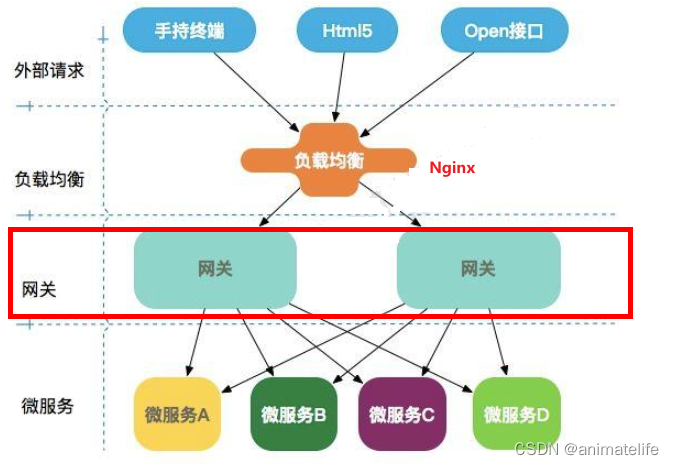
SpringCloud Gateway
- SpringCloud Gateway 使用的 Webflux 中的 reactor-netty 响应式编程组件,底层使用了Netty通讯框架,基于异步非阻塞模型
- 简单来说,因为使用了 响应式编程 + 异步非阻塞IO ,所以速度很快
- 可以用来:反向代理、鉴权、流量控制、熔断、日志监控、编码设置、解决跨域等
核心

- Route(路由):路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
- 静态路由:写死了 路由映射的 地址(自己理解,方便记忆)
- 动态路由:从注册中心,根据服务名获取相应的多个服务实例,加上 lb 负载均衡 协议,实现动态路由
- Predicate(断言):参考的是Java8的 java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数、路径等),如果请求与断言相匹配则进行路由
- 接受一个输入参数返回一个布尔值
- 可以多个 Predicate 组合使用,跟多使用详情参考官网
- Filter(过滤):指的是 Spring 框架中 Gateway Filter的实例,使用过滤器,可以对请求,在其被响应前 和 响应后,对请求进行修改
- Gateway Filter 的只有两个 阶段,请求被处理前(pre)、请求被处理后(post)
- 按照作用的范围,分为 全局过滤器(GlobalFilter)和 网关过滤器(GatewayFilter )
- 使用详情参考官网,一般使用自定义过滤器
- GlobalFilter:对所有请求有效
- GatewayFilter:只对 某个 或 某组 路由映射到的路径有效
- 还可以自定义过滤器
工作流程
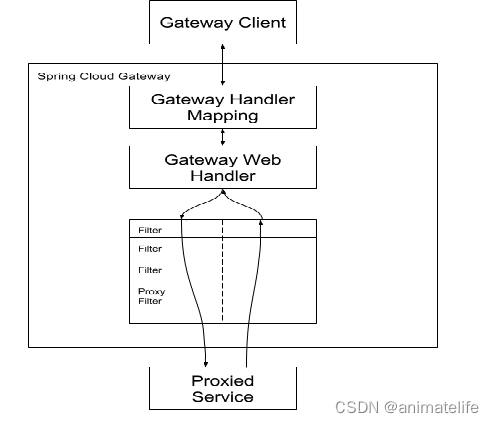
- 核心逻辑:路由转发(映射) + 过滤链
SpringCloud Config 分布式配置中心
- SpringCloud Config 为各个不同微服务应用的所有环境(比如测试环境、生产环境等)提供了一个中心化的外部配置, 分为服务端和客户端两部分
- Config Server,称为分布式配置中心,它是一个独立的微服务应用,与 git 等版本管理工具相连,从 git 库中读取配置文件
- Config Client ,就是通过 Config Server 获取配置项的所有微服务应用
- 产生的问题:不能够自动的动态刷新,如果环境管理员修改了 git 上的配置文件的配置项,Config Server 能获取到最新的配置项,但是 Config Client 不能
- 解决动态刷新的两种方式
- 每一个 Config Client 都引入 Actuator 依赖,放开 web 方式所有的监控端点,在需要读取配置项的类上添加注解 @RefreshScope
- 每次修改玩配置文件后,需要对每一个需要随之更新配置项的 Config Client ,通过对
http://Config Client 的IP:Config Client 的端口号/actuator/refresh发送 post请求,实现更新
- 每次修改玩配置文件后,需要对每一个需要随之更新配置项的 Config Client ,通过对
- 使用 SpringCloud Bus 消息总线
- 依然需要发送 post请求,不过只需要对 Config Server 在地址
http://Config Server 的IP:Config Server 的端口号/actuator/refresh发送 post请求,实现更新 - 上面发送 post请求,实际上是广播的方式,通过 SpringCloud Bus 更新所有 Config Client 的配置项
- 指定更新某些 Config Client 的配置项,可以通过对地址
http://Config Server 的IP:Config Server 的端口号/actuator/refresh/Config Client的应用名:Config Client的端口号发送 post请求,实现更新
- 依然需要发送 post请求,不过只需要对 Config Server 在地址
- 每一个 Config Client 都引入 Actuator 依赖,放开 web 方式所有的监控端点,在需要读取配置项的类上添加注解 @RefreshScope
bootstrap.yml配置文件
- 所有 Config Client 需要在自己的类路径下增加一个 bootstrap.yml 配置文件(用于配置从分布式配置中心的读取配置)
- applicaiton.yml 是用户级的资源配置项,bootstrap.yml 是系统级的,优先级更加高,bootstrap.yml 比 application.yml 先加载
Bootstrap Context作为 Spring 应用的Application Context的父上下文,初始化的时候,Bootstrap Context负责从外部源加载配置属性并解析配置,这两个上下文共享一个从外部获取的EnvironmentBootstrap属性有高优先级,默认情况下,它们不会被本地配置覆盖Bootstrap context和Application Context有着不同的约定,所以新增了一个bootstrap.yml文件,保证Bootstrap Context和Application Context配置的分离
SpringCloud Bus 消息总线
- SpringCloud Bus是用来将分布式系统的节点(各个微服务)与轻量级消息系统(目前只支持 RabbitMQ 和 Kafka)链接起来的框架
- 消息总线:使用轻量级的消息代理来构建一个共用的消息主题,由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线
解决分布式配置中心的动态刷新问题
- 两种方案如下所示,但是只采用通过 Config Server 实现刷新的方式
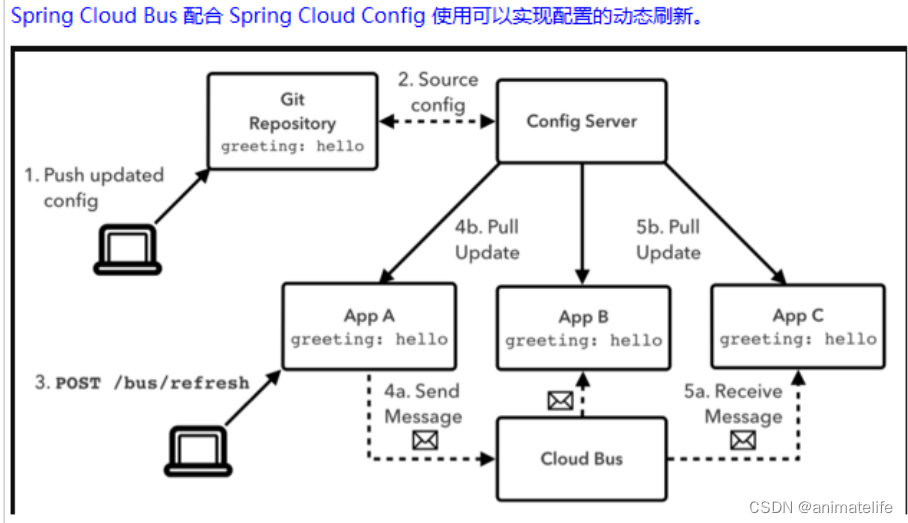
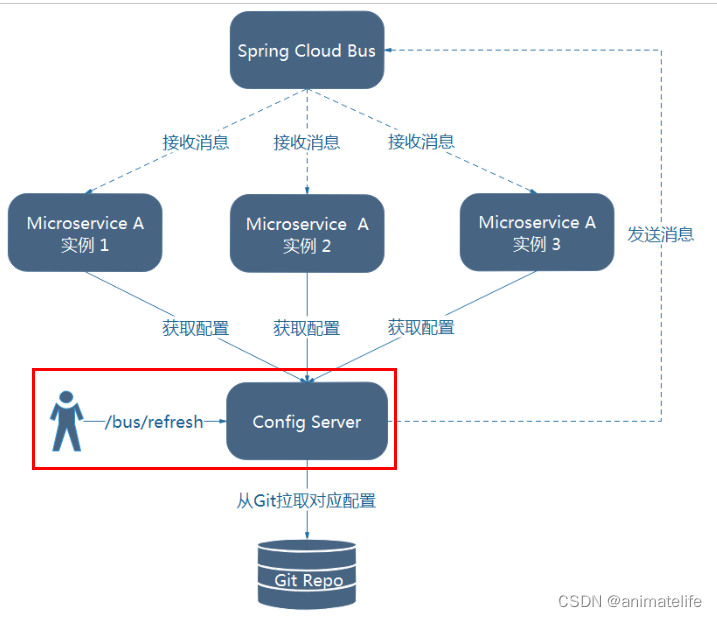
- 实现原理:Config Client 实例都监听 MQ 中同一个 Topic (默认是 springCloudBus),当一个服务刷新数据的时候,它会把这个信息放入到这个 Topic 中,这样其它监听同一 Topic 的服务就能得到通知,然后去更新自身的配置
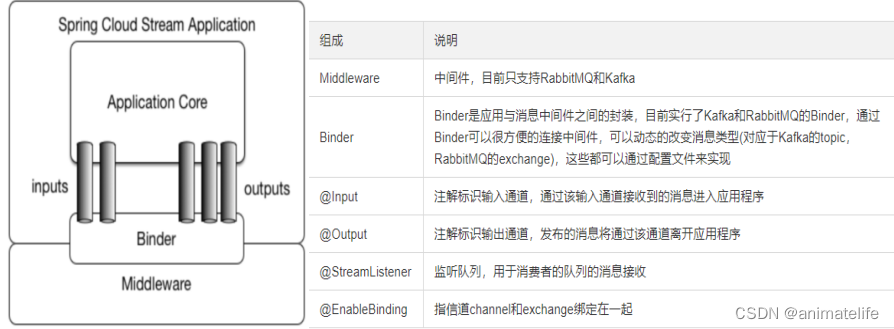
SpringCloud Stream 消息驱动
- 屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型,目前仅支持RabbitMQ、Kafka
- Stream 中的消息通信方式遵循了发布-订阅模式,消息生产者将Exchange/Topic的消息广播给消息消费者
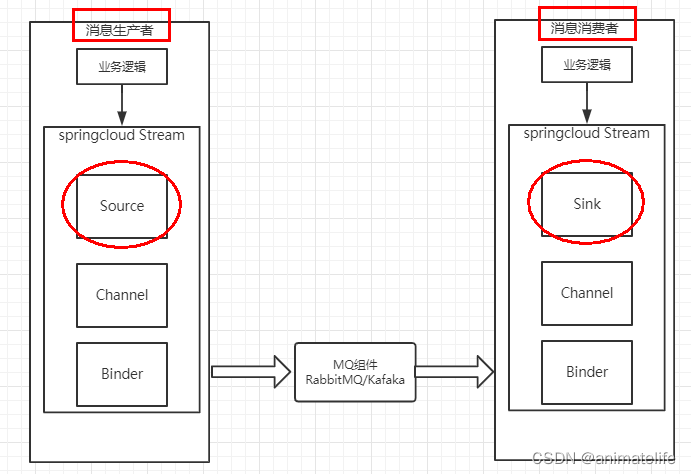
- Channel 通道,是队列Queue的一种抽象,就是下图的Input、Output
- Source和Sink,简单的可理解为Spring Cloud Stream自身,从Stream发布消息就是输出(Source),接受消息就是输入(Sink)
持久化与重复消费
- 将消费消息的微服务应用放置于同一个group中,就能够保证消息只会被其中一个应用消费一次
- 不同的组是可以同时消费同一条消息的,同一个组内会发生竞争关系,只有其中一个可以消费同一条消息
- 持久化的使用:当服务消费者下线,而消息生产者还在生产消息时,只有明确指定分组的消费者应用才能在上线后,消费到之前没上线时生产者生产的消息
SpringCloud Sleuth 分布式请求链路跟踪
- Sleuth 链路跟踪,ZipKin提供了图形展示
- 实际上现在它们已经整合到一个jar包了:spring-cloud-starter-zipkin
- 但是 zipkin 客户端需要根据官网,单独启动,开启 web 图形化界面
- 关于链路追踪的原理
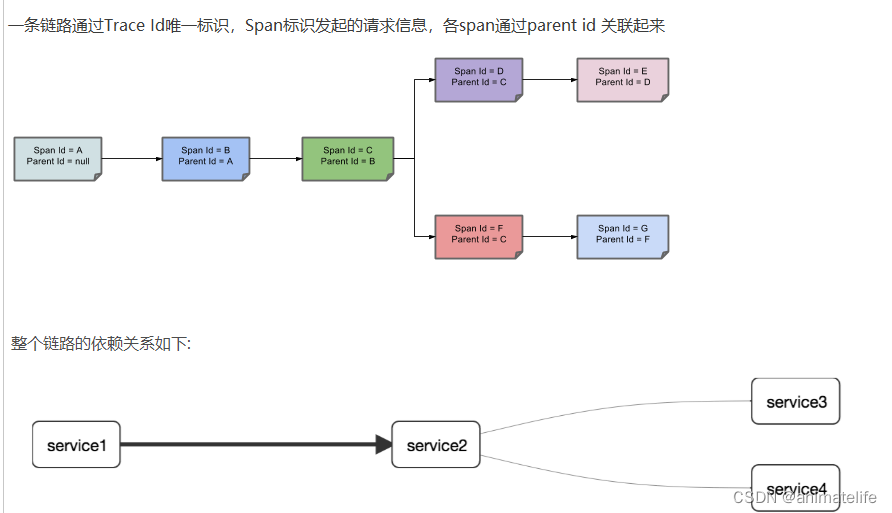
- Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
- span:表示调用链路来源,通俗的理解span就是一次请求信息
- 只需要在需要链路追踪的微服务应用中引入 spring-cloud-starter-zipkin 依赖,然后修改相应的配置文件即可
- 以上步骤完成后,可以通过 打开浏览器访问:http://zipKin启动的机器IP:9411 得到想要追踪的链路信息
SpringCloud Alibaba
Nacos
- Nacos: Dynamic Naming and Configuration Service
- Nacos = Eureka+Config +Bus
- 替代Eureka做服务注册中心
- 替代 Config + Bus 做服务分布式配置中心
- Nacos 客户端的下载和安装,参考官网
- web 图形化界面登录地址:
http://Nacos实例的机器IP:8848/nacos
- web 图形化界面登录地址:
Nacos 作为注册中心
- Nacos 支持AP和CP模式的切换
- 切换方法:
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP[AP]'
- 切换方法:
- AP模式下只支持注册临时实例,当前主流的服务如 Spring cloud 和 Dubbo 服务,都适用于AP模式,AP模式为了服务的可能性而减弱了一致性
- CP模式下则支持注册持久化实例,此时则是以 Raft 协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误
- nacos 的依赖 spring-cloud-starter-alibaba-nacos-discovery 中,包含了 Ribbon ,所以会自带负载均衡
Nacos 作为配置中心
- 配置文件需要是
bootstrap.yml,用于配置从分布式配置中心的读取配置,具体原因参考bootstrap.yml配置文件

- 根据 Data Id 加载配置文件
- 根据官方文档要求 匹配格式为
${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension} - 即假设配置文件中
spring.application.name的值为consumer-order-group,spring.profile.active的值为dev,spring.cloud.nacos.config.file-extension的值为yml - 那么在 nacos 默认情况下匹配到的配置文件为 public.default_group.consumer-order-group-dev.yml
- 默认情况下 NameSpace 为 public,Group 为 default_group
- 根据官方文档要求 匹配格式为
- 根据分组(Group )加载配置文件
- 在 Data Id 相同的情况下,根据配置文件中的
spring.cloud.nacos.config.group的值加载配置文件
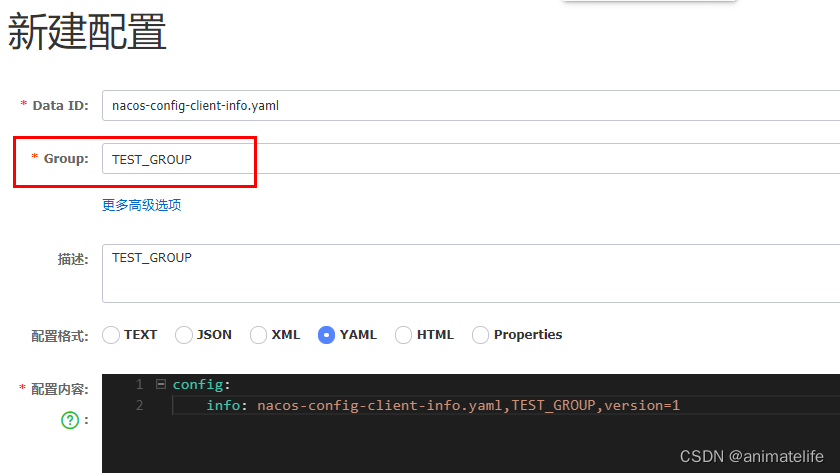
- 在 Data Id 相同的情况下,根据配置文件中的
- 根据命名空间(namespace)加载配置文件
- 在 Data Id 、Group 相同的情况下,根据配置文件中
spring.cloud.nacos.config.namespace的值加载配置文件 - NameSpace 的值为命名空间的 Id,在创建命名空间时生成
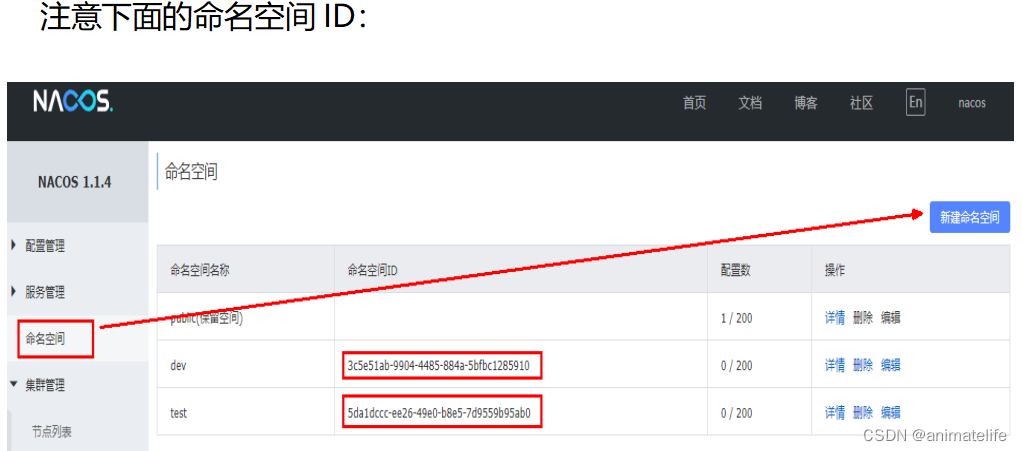
- 在 Data Id 、Group 相同的情况下,根据配置文件中
- 配置文件的实际加载顺序应该是:NameSpace—>Group—>Data Id,除了 Data Id都有默认值
持久化(Linux环境)
- Nacos会记录配置文件的历史版本默认保留30天,此外还有一键回滚功能,回滚操作将会触发配置更新

- 在没有配置外部数据库的情况下,配置信息会持久化存储到 Nacos 内嵌的 数据库 derby
- 配置外部数据库的方法
- 在 nacos 的存放目录下的
conf目录中,有一个文件 nacos-mysql.sql - 在 mysql 中执行这个 sql 脚本中的语句
- 外部数据库,目前只支持 mysql
- 还是在
conf目录中 ,修改 application.properties 文件,增添如下内容
spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=root db.password=root - 在 nacos 的存放目录下的
集群搭建
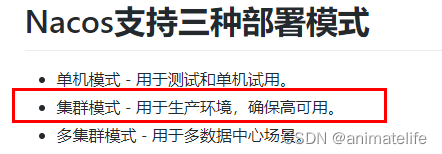
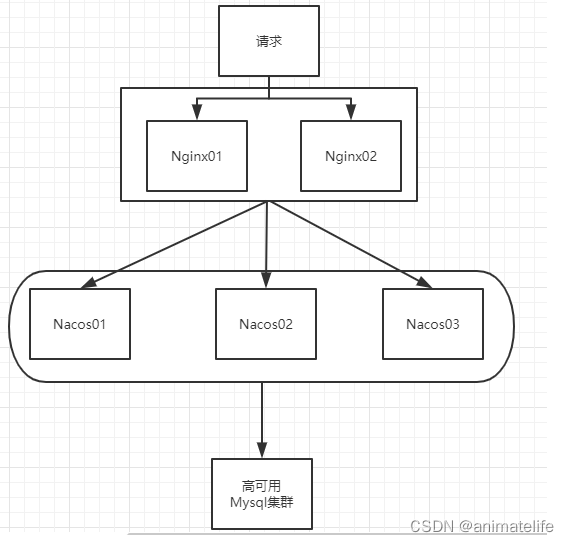
- 梳理出3台 nacos 的不同服务端口号,官方提示,nacos 的集群至少三台
- 修改 nacos 的存放目录下的
conf目录中的 cluster.conf(copy of cluster.conf.example),内容是3台 nacos 实例的 IP:端口号

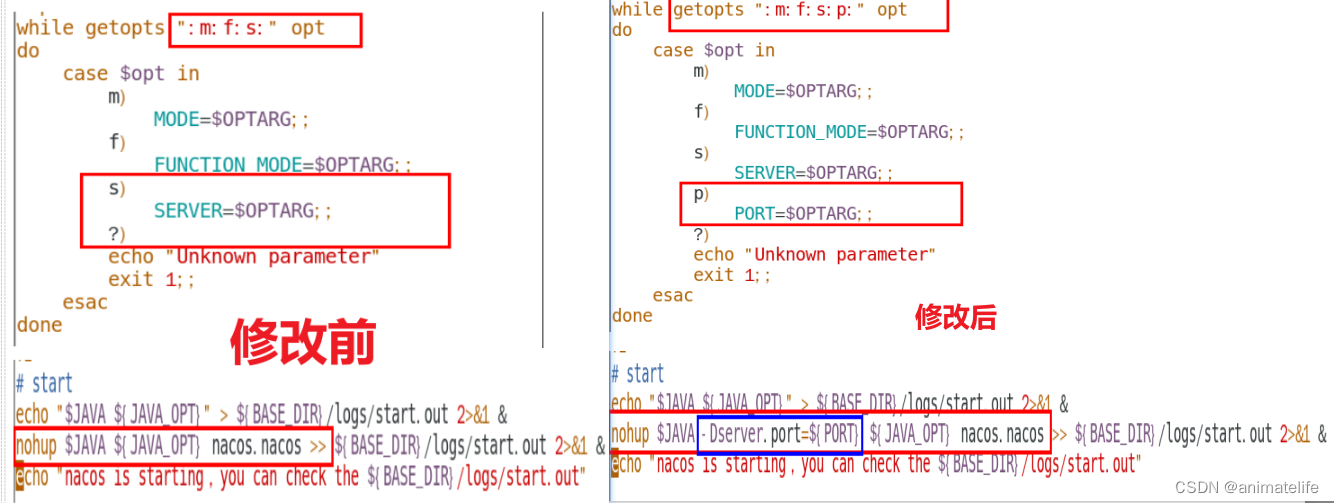
- 修改 3台 nacos 存放目录下的
bin文件夹中的 startup.sh (copy of startup.sh)使得执行这个启动的shell脚本时,能够指定启动的端口,如./startup.sh -p 3333
- 配置 Nginx 用作 3台 nacos 的负载均衡
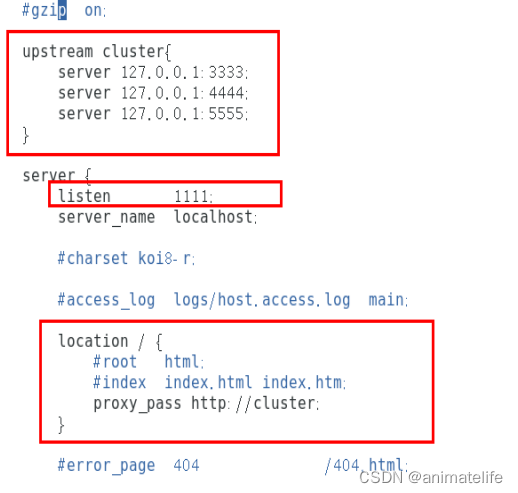
- 配置 3台 nacos 的外部数据库 参考
持久化(Linux环境), 3台 nacos 都需要配置一次 - 上述完成后,需要注意,无论是作为注册中心,还是作为配置中心、或者是登录 web 图形化界面,使用的地址应该是Nginx配置的 vip的 IP 和端口号,
http://vip的IP:vip的端口号/nacos
Sentinel
- Sentinel 的使用分为两步骤
- 在需要使用的微服务中导入依赖
spring-cloud-starter-alibaba-sentinel - 从官网得到控制台的 jar,按照指定方式运行
- 在需要使用的微服务中导入依赖
- Sentinel 的默认监控级别,和 Hystrix 一样都是 Controller 的方法级别
- Sentinel 控制台的默认用户和密码都是 sentinel
- Sentinel 默认使用懒加载,登录 web 端的控制台,可能会发现没有任何显示,需要先对引入 Sentinel 的服务进行调用
流控
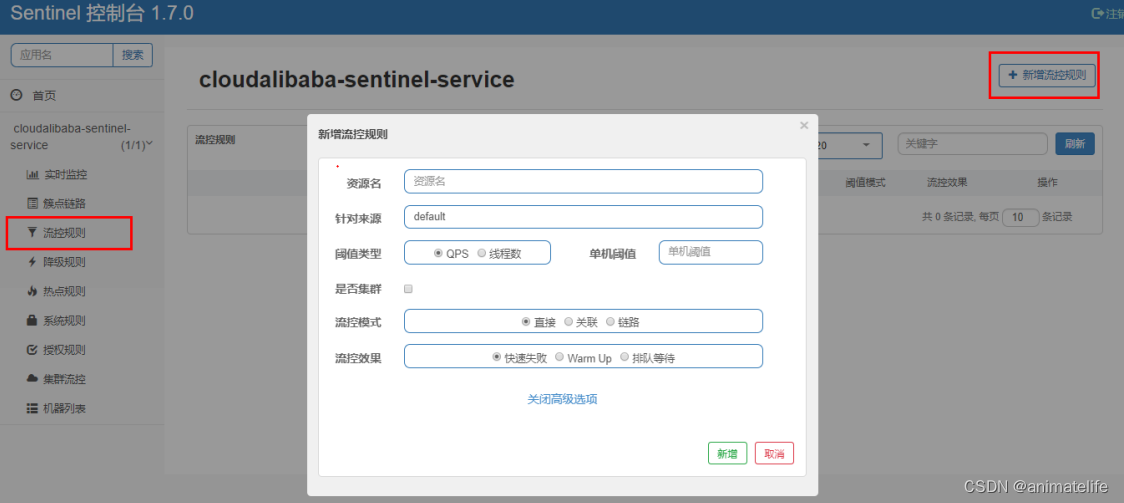

- 代码无需有任何入侵
- 一旦达到流控的标准,就会返回浏览器端
Blocked by Sentinel (flow limiting)的错误提示页面
降级


- 代码无需有任何入侵
- 一旦达到降级的标准,就会返回浏览器端
Blocked by Sentinel (flow limiting)的错误提示页面 - 与 Hystrix 不同的是,没有
半开状态,时间窗口过后就自动关闭降级,开始新一轮的监控
热点key限流
- 热点即经常访问的数据,很多时候我们希望统计或者限制某个热点数据中访问频次最高的TopN数据,并对其访问进行限流或者其它操作
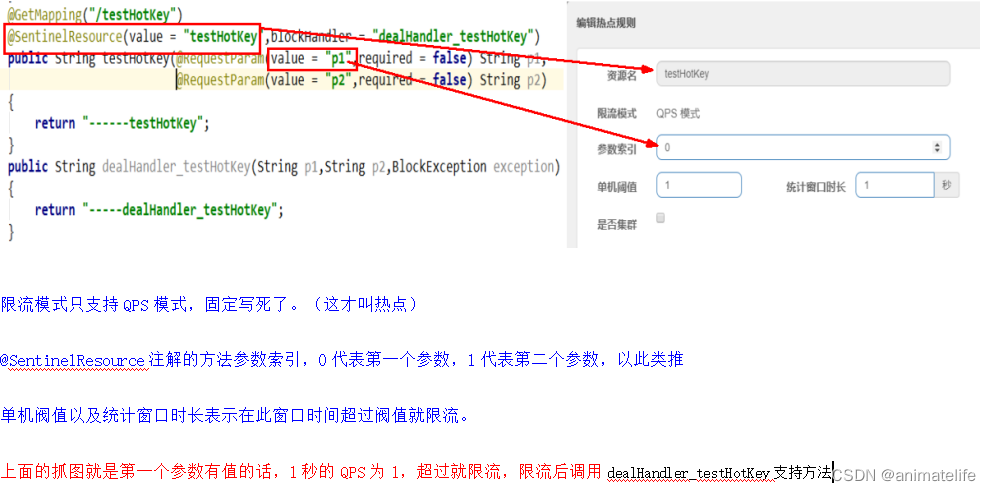
- 代码无需有任何入侵,但是当不指定
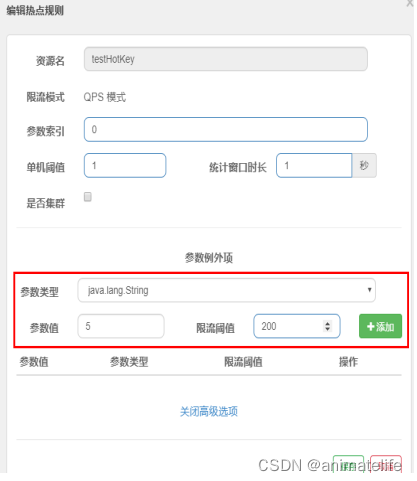
blockHandler会导致返回给客户端的错误页面不友好,所以还是入侵好了 - 还可以根据参数的值区别限流,如图所示就是当第一个请求参数
p1的值为"5"时,限流的条件就变成了 QPS>200 - 热点参数的注意点:参数必须是基本类型或者String
系统规则
- 这是针对整个微服务的限流规则,一般不轻易设置

- 关于这几个指标,官网都有解释,Load 看不懂
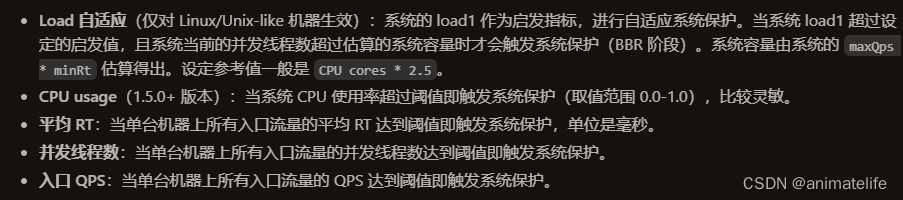
- 代码无需有任何入侵
自定义限流后的处理
- 上面的多种功能,总结起来都是在做限流,限流的处理手段就是降级,只不过 进入降级的条件变多了
- 降级 是需要 设置一个
fallbackMethod作为兜底的,但是前面的设置中都是直接在控制台控制(除了热点key限流),没有对代码有任何入侵,返回给客户端的都是 Sentinel 自带的默认 错误页面(其实就返回一句话,比如Blocked by Sentinel (flow limiting)) - 自定义限流后的处理,就是指定一个
fallbackMethod作为兜底,参考热点key限流可以给每个被限流的方法都设置一个blockHandler(类似fallbackMethod,但负责范围不同)- 方式一:给每个方法都参考
热点key限流设置单独的blockHandler - 方式二:多个方法共用一个
blockHandler - 方式三:前面两种方式都会让
blockHandler方法出现在业务代码中,可以创建一个类作为blockHandlerClass,里面有许多blockHandler方法以供自定义限流后的处理
- 方式一:给每个方法都参考
- 总结:自定义限流后的处理是通过
@SentinelResource注解实现的,其中的属性大致如下(更多详细信息参考官网 or 源码)

fallback与blockHandler的区别在于,前者可以处理所有异常(除了exceptionsToIgnore指定的异常),后者仅能处理满足在 Sentinel 中设置的限流、降级后抛出的BlockExceptionfallback与blockHandler相同之处在于,指向的兜底方法,与原方法必须满足:1.返回值类型相同、2.参数列表相同,可以额外多一个 Throwable/BlockException 的参数、3.必须和原方法在同一个类中、4.必须为static方法fallbackClass与blockHandlerClass相同之处在于,其中专门用于兜底的方法,必须是static方法- 代码本身发生异常的同时,触发了限流的异常
BlockException,此时blockHandler起作用
Sentinel 规则持久化
- 一旦我们重启应用,在 sentinel 上配置的限流规则将消失,生产环境需要将配置规则进行持久化
- 将限流配置规则持久化进Nacos保存
-
在项目的配置文件中,原来 sentinel 的配置下增加数据源的配置
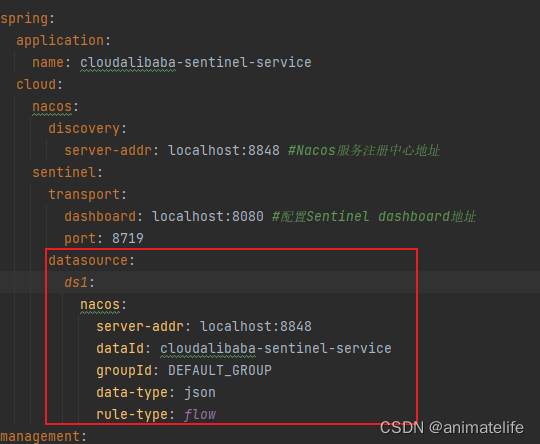
-
在 nacos 新建配置文件
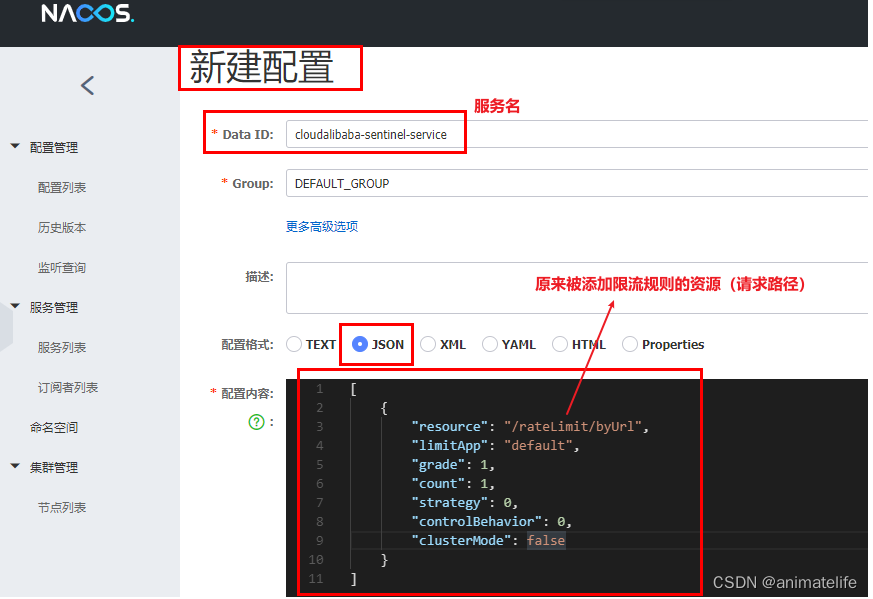
resource:资源名称; limitApp:来源应用; grade:阈值类型,0表示线程数,1表示QPS; count:单机阈值; strategy:流控模式,0表示直接,1表示关联,2表示链路; controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待; clusterMode:是否集群
-
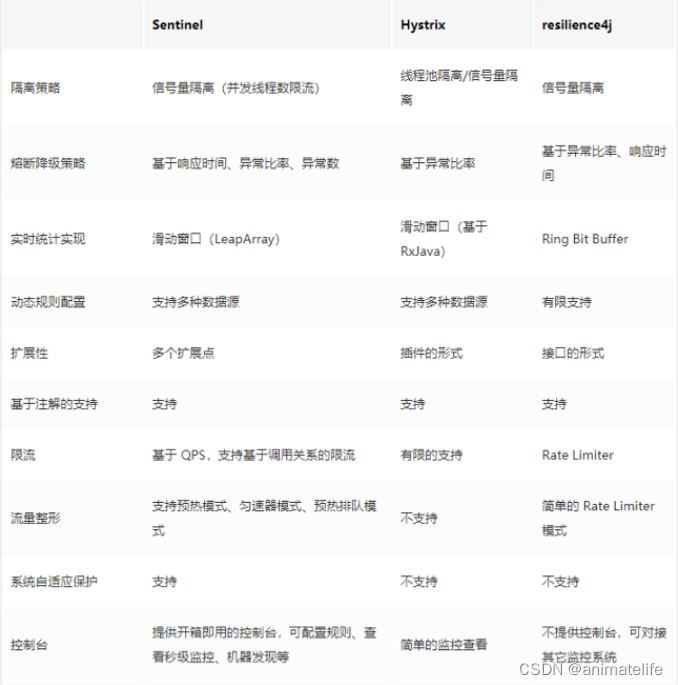
几种熔断框架的对比
Seata 处理分布式事务
- 一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,需要实现要么同时成功,要么同时失败,就会产生分布式事务问题
- 一个典型的分布式事务有四部分组成
- 全局唯一的事务ID
- Transaction Coordinator (TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
- Transaction Manager ™:控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
- Resource Manager (RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
- Seata 的四种事务模式:AX、TCC、Saga、XA(具体的事务模型参考官网)
- 以 基于 Nacos + OpenFeign + Mysql + Seata AX 为基础的,分布式事务框架搭建(具体应用实例见个人gitee)
- 下载 Seata Server
- 修改 Seata Server 存放目录中的conf目录下的file.conf配置文件,如下图所示的三个地方
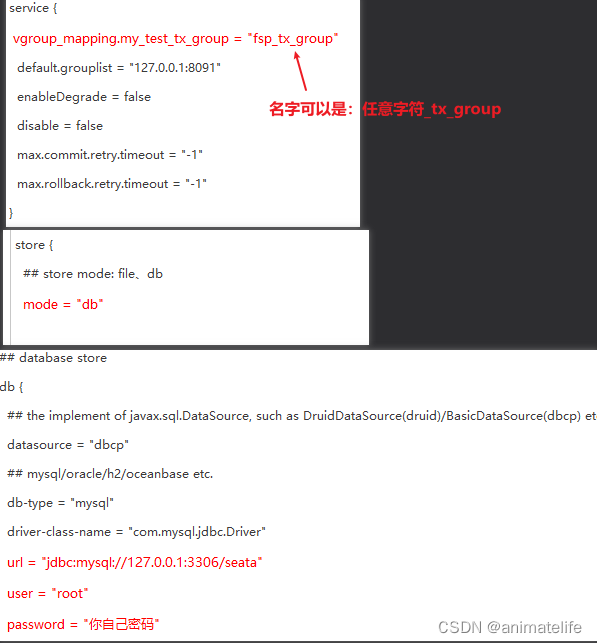
- mysql 数据库新建库
seata,执行 Seata Server 存放目录中的conf目录下的 db_store.sql - 修改 Seata Server 存放目录中的conf目录下的 registry.conf 配置文件

- 然后按序启动 Nacos、Seata Server
- 修改 Seata Server 存放目录中的conf目录下的file.conf配置文件,如下图所示的三个地方
- 下载 Seata Server
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结