您现在的位置是:首页 >其他 >【C++】CUDA期末复习指南上(详细)网站首页其他
【C++】CUDA期末复习指南上(详细)
? 博客主页:?@披星戴月的贾维斯
? 欢迎关注:?点赞?收藏?留言
?系列专栏:? C/C++专栏
?请不要相信胜利就像山坡上的蒲公英一样唾手可得,但是请相信,世界上总有一些美好值得我们全力以赴,哪怕粉身碎骨!?
?一起加油,去追寻、去成为更好的自己!

文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
前言
现在也已经有很多学校陆陆续续进入到了考试月,想必不少同学和我一样在准备期末考,提前祝贺大家在期末考中都能取得自己满意的成绩,现在我和和大家一起分享一篇CUDA期末复习指南,希望对大家有帮助。
?1、早期的GPU编程
GPU图形处理器Graphics Processing Unit,是现在常用的设备。
提供一些基本的操作,对内存中的图像着色,显示在屏幕上。
GPU会处理一个复杂的多边形集合,即需要着色的图片映像,然后给这些多边形图上纹理,在进行光照和阴影处理。
一个重要的进步:可编程着色器programmable shader,GPU运行一些用来计算图片效果的小程序。GPU中的着色器就不是固定的,可以通过下载不同的着色器,来进行着色。这就是最初的通用图形处理器General Purpose Graphical Processor Unit, GPGPU。
GPU处理单元功能不再是固定的,CUDA是首次实现了可编程显卡,向程序员提供了一个真正通用的GPU编程语言。
GPU的基本架构以及与CPU的交互
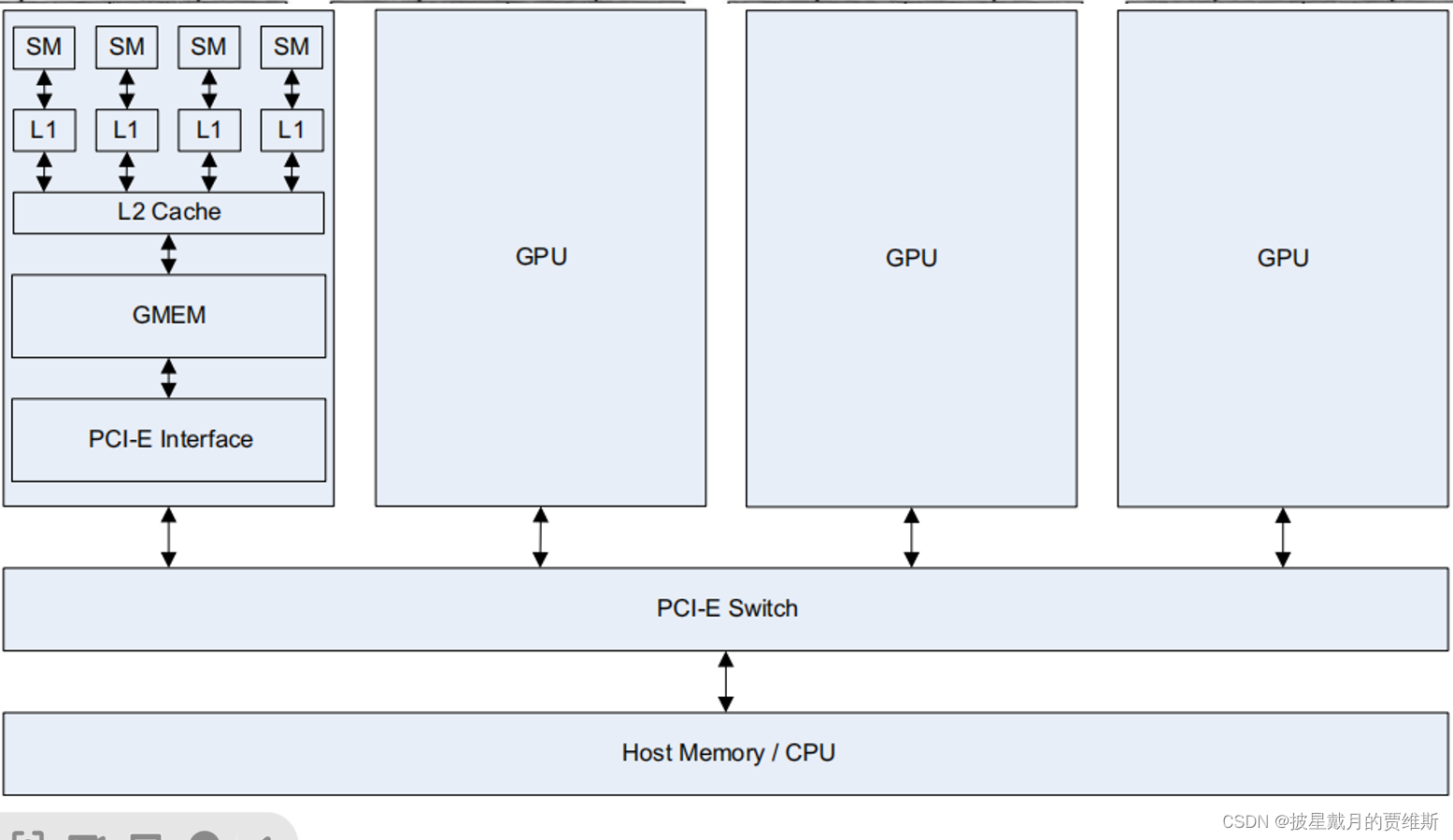
解释:一个GPU内有许多流处理器簇(Streaming Multiprocessor,SM),类似CPU的核。
SM和共享存储(一级缓存)连接在一起,然后又与相当于SM间互联开关的二级缓存相连。
数据先是在主机的全局存储中,然后被主机取出并使用。主机将数据通过PCI-E互联开关直接送往GPU的存储空间。PCI-E互联开关的传输速度比任何一个互联网快很多。
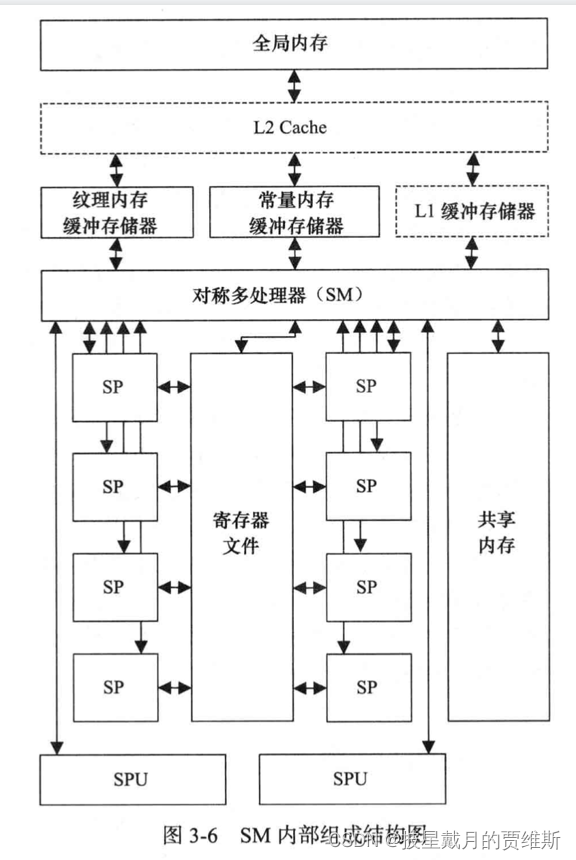
流处理器SM内部组成结构图
?2、串行/并行问题 并发性 局部性
?并行程序标准
两个并行程序设计标准,OpenMP和MPI
线程模型比较适合OpenMP,进程模式适用于MPI。
在GPU环境下,就需要混合在一起。CUDA使用一个线程块(block)构成的网格(grid)。可以看成是一个进程(线程块)组成的队列(网格),进程间没有通讯。每个进程(线程块)内部有很多线程,这些线程以批处理的方式运行,成为线程束(warp)。
?并发性
首要内涵是,对于一个特定的问题,不考虑那种并行架构,只关注求解方法中哪些操作是可以并行执行的。
算法中可能会有一段不易并行的阶段,被称为瓶颈
CUDA将问题分解成线程块的网格,每块包含多个线程。块可以按照任意顺序执行,易并行问题,块容易按照任意顺序执行
线程网格(grid)->线程块(block)->线程(thread)
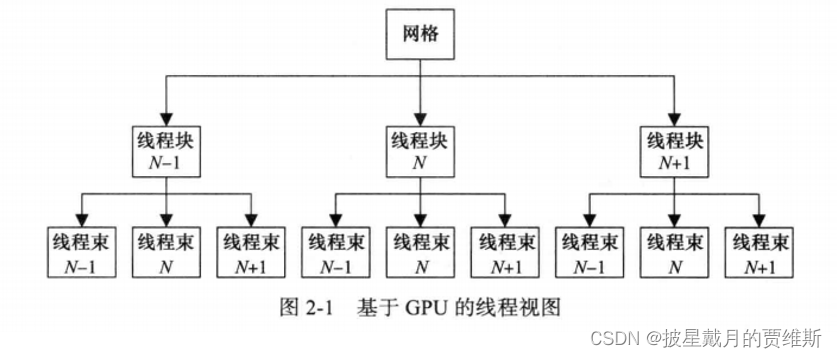
网格中的块可以被分配到任意一个有空闲槽的SM上。可以采用轮询调度策略,确保分配到每个SM上的块数基本相同。对于大部分内核程序而言,分块的数量应该是GPU中物理SM数量的八倍或者更多倍。
?局部性
计算性能的提高已经从受限于处理器运算吞吐率,发展到迁移数据成为首要限制因素。
局部性问题通过多级缓存来解决。当任务被多次重复执行,缓存作用会充分发挥。
工作基础是空间局部性和时间局部性。之前被访问过的数据很可能还要被再次访问(时间局部性);刚被访问过的数据附近的数据也很可能马上被访问到(空间局部性)。
脏数据指的是缓存中被程序修改过的数据。脏数据必须在新数据装入前写回到全局内存,也就是说如果需要全局内存访问,需要先把缓存中的数据写回到内存中,再访问内存数据。
?3、任务/数据并行
?任务并行
操作系统,多任务
操作系统,它实现的是一种任务并行的并行处理,各个进程是不同的、无关的。多个CPU核心运行不同的应用程序。
基于任务的并行适合于粗粒度的并行。
就GPU而言,粗粒度并行处理是由GPU卡和CPU内核程序来执行。GPU有两种方法来支持流水线并行处理模式。一是,若干个内核程序被一次排列成一个执行流,然后不同的执行流并发执行。二是,多个GPU协同工作,可以通过主机或者PCI-E总线,在不同GPU之间传递数据。
?数据并行:
关注数据及其所需的变换,不是待执行的任务
基于数据的并行适合于细粒度的并行。
弗林分类法
SIMD (Single Instruction Multiple Data)单指令多数据
MIMD (Multiple Instruction Multiple Data)多指令多数据
SISD (Single Instruction Single Data)单指令单数据
MISD (Multiple Instruction Single Data)多指令单数据
**常用的并行模式:
循环
派生/汇聚:先串行,然后遇到并行区,并行处理,然后再汇聚串行处理。采用数据的静态划分来实现常用于并发事件数量事先不确定的问题。遍历树形结构,路径搜索等。
分条/分块:绝大多数并行处理方法。比如:矩阵计算大气海洋模型
分而治之:把大问题分解称小问题
**
?4、GPU硬件结构
4.1?内存的分类
| 内存类型 | 访问权限 |
|---|---|
| 全局内存 | 可读可写 |
| 常量内存 | 仅可读 |
| 纹理内存 | 一般仅可读 |
| 寄存器内存 | 可读可写 |
| 局部内存 | 可读可写 |
| 共享内存 | 可读可写 |
GPU有流处理器簇、流处理器。
GPU实际上是一个SM的阵列,每个SM包含N个核
一个GPU设备包含多个SM,这是GPU具有可扩展性的关键因素。
每个SM有一个寄存器文件,是能够以与SP相同速度工作的存储单元。不同型号GPU,寄存器文件大小不相同,用来存储SP上运行的线程内部活跃的寄存器。
每个SM内部访问的共享内存,是程序可控的高速缓存。与CPU内部的高速缓存不同,没有自动完成数据替换的硬件逻辑,完全由程序控制。
每个SM都设置有总线访问纹理内存、常量内存、全局内存。
纹理内存是针对全局内存的特殊视图,用来存储差值计算所需的数据
常量内存存储只读数据。
每个SM还有两个以上的专用单元(Special-Purpose Unit, SPU),SPU专门执行诸如正弦余弦函数/指数函数操作等特殊硬件指令。
内核函数:global void kernel<<<1, 1>>>();
__global__告诉编译器,这个函数可以在设备上运行的。
<<<一个线程块,每个线程块一个线程>>>
<<<gridDim, blockDim>>>(具体的函数传参)
cuda设备属性

?5、GPU与CPU差别
任务/数据并行:
GPU与CPU在缓存上的一个重要差别是缓存一致性”问题。
缓存一致性系统,一个内存写操作需要通知所有核的各个级别缓存,所有核看到的内存视图是一样的。随着核数量增多,通知的开销迅速增大,限制了一个处理器中的核数量不能太多。
非缓存一致系统,系统不会自动更新其他核的缓存。需要程序员写清楚每个处理器核输出的各自不同的目标区域。从程序角度,这支持一个核只负责一个输出或者一个小的输出集。
CPU一般缓存一致,GPU是非缓存一致的,因此GPU可以在一个芯片内有大量的核心。
GPU的方式,对于多数据的处理方式更灵活;CPU只能用指令集里固化的数据处理方式。
?6、GPU函数
- cudaMalloc:cudaMalloc 是CUDA中的一个函数,用于在设备端(GPU)分配一段内存空间。第一个参数是地址的二重指针,我们可以强制转换为(void**)类型的,第二个参数是申请的地址大小。
举例:
HANDLE_ERROR( cudaMalloc( (void**) &dev_a, N * sizeof(int) ) );
- cudaMemcpy:cudaMemcpy 是 CUDA 中用于在主机(CPU)和设备(GPU)之间进行内存数据传输的函数。它的函数原型如下:
cudaError_t cudaMemcpy(
void *dst,
const void *src,
size_t count,
cudaMemcpyKind kind
);
dst 为目标内存地址,在数据传输过程中将接收数据; src 是源内存地址,数据将从这里传输到目标地址; count 是要传输的数据字节数; kind 是传输数据的方式。
cudaMemcpyHostToHost :从主机复制数据到主机;
cudaMemcpyHostToDevice :从主机复制数据到设备;
cudaMemcpyDeviceToHost :从设备复制数据到主机;
cudaMemcpyDeviceToDevice :从设备复制数据到设备。
举例:
HANDLE_ERROR( cudaMalloc( (void**) &dev_a, N * sizeof(int) ) );
- cudaFree
cudaFree 是 CUDA 中用于释放设备(GPU)上已分配内存的函数。
使用举例:
HANDLE_ERROR( cudaFree(dev_a ));
- cudaGetDeviceCount
cudaGetDeviceCount 是 CUDA 中用于查询当前主机上可用 GPU 设备数量的函数。
举例:
int deviceCount;
HANDLE_ERROR( cudaGetDeviceCount(&deviceCount) );
- cudaGetDeviceProperties
cudaGetDeviceProperties 函数是CUDA提供的一种API,用于获取指定设备的属性信息。它的函数原型为
cudaError_t cudaGetDeviceProperties(
struct cudaDeviceProp* prop,
int device
);
其中, prop 是一个指向 cudaDeviceProp 结构体的指针,用于存储设备属性的详细信息。
device 表示要查询的设备的编号。请注意,在调用该函数之前,必须使用 cudaSetDevice 函数将要查询的设备设置为当前设备。
代码示例:
int main()
{
int deviceCount;
HANDLE_ERROR( cudaGetDeviceCount(&deviceCount) );
if (deviceCount == 0) {
printf("There is no available CUDA device.
");
return 0;
}
int dev = 0;
HANDLE_ERROR( cudaSetDevice(dev) );
cudaDeviceProp prop;
HANDLE_ERROR( cudaGetDeviceProperties(&prop, dev) );
printf("Device Name: %s
", prop.name);
printf("Total Global Memory: %ld bytes
", prop.totalGlobalMem);
printf("Number of Multi-Processors: %d
", prop.multiProcessorCount);
printf("Clock Rate: %d MHz
", prop.clockRate / 1000);
printf("Max Threads per Block: %d
", prop.maxThreadsPerBlock);
return 0;
}
- cudaMallocHost
cudaMallocHost 是一种在主机上分配固定内存的 CUDA API 函数。
使用方法:
int* host_data;
size_t size = 1024 * 1024 * sizeof(int); // 申请 1MB 内存
HANDLE_ERROR( cudaMallocHost(&host_data, size) );
cudaFreeHost(host_data);
- cudaFreeHost
cudaFreeHost 函数用于释放由 cudaMallocHost 函数分配的主机内存空间。
?总结
本文总共总结多个考点,都是很有可能被考到的,同学们可以收藏起来看,下期我们将会继续介绍cuda函数,以及几个可能会考编程题的重要编程题汇总,感谢大家的支持,一起进步!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结