您现在的位置是:首页 >学无止境 >语义分割总结网站首页学无止境
语义分割总结
文章目录
0. 前言
语义分割是一种计算机视觉领域的图像分割技术,旨在将图像中的每个像素分配到其对应的语义类别中。与传统的图像分割技术不同,语义分割旨在对图像进行更精细的划分,以识别出图像中每个像素的语义含义。在语义分割中,每个像素被标记为属于一个预定义的语义类别,例如人、车、路、树等等。与此相比,传统的图像分割方法通常仅仅将图像分成前景和背景两个部分。
语义分割可以应用于各种计算机视觉任务,如自动驾驶、目标检测、图像分析和医学图像分析等,常用的网络架构包括全卷积网络(FCN)、U-Net和SegNet等。
1. 数据集
用于语义分割神经网络训练的数据集有很多,这些数据集通常都是由人工标注的图像和相应的标签组成。以下是一些常用的语义分割数据集:
- Pascal VOC:一个用于视觉对象识别和检测的基准数据集。它是由英国牛津大学计算机视觉小组于2005年至2012年期间创建的。该数据集包含20个不同的对象类别,如人、车、飞机、狗等,并且在每个图像中都有一组手动标记的对象边界框,用于指示每个对象在图像中的位置和大小。Pascal VOC数据集包含多个版本,每个版本都有其自己的训练和测试集。其中,2007年版本包含2501个训练图像和2510个测试图像,而2012年版本包含17125个训练图像和11540个测试图像。
- COCO:一个大规模的图像识别、对象检测、分割和场景理解的基准数据集。该数据集由微软公司于2014年发布,旨在提供更具挑战性和现实性的场景。COCO数据集包含超过33万张图像,其中包括超过80个不同的对象类别,如人、动物、交通工具、食品、电子产品等。每个图像都有多个对象实例,而且对象可能会重叠或遮挡。除了对象边界框外,COCO数据集还提供了每个对象的精确分割掩码。这使得COCO数据集成为了一个重要的分割任务的基准数据集。
- Cityscapes:面向自动驾驶和场景理解的基准数据集,由德国德累斯顿工业大学和美国卡内基梅隆大学联合发布。该数据集包含来自德国和其他欧洲城市的街道场景图像和相应的注释信息。Cityscapes数据集包含5000张高分辨率的图像,其中包括50个不同的城市街道场景。每个图像都提供了不同季节、不同天气和不同时间的视角,以便更好地反映真实世界的场景变化。Cityscapes数据集还提供了精确的像素级别标注,包括道路、建筑物、行人、车辆等对象的分割掩码和实例级别的注释信息。
- ADE20K:该数据集由美国麻省理工学院计算机科学和人工智能实验室发布,包含了超过2万张图像和400个对象类别。ADE20K数据集中的图像来自不同的场景,如室内、室外、城市、自然景观等,并且覆盖了不同的语境和场景复杂度。每张图像都被手动注释,包括像素级别的标注和场景标签。标注信息包括物体边界框、物体实例分割、场景区域分割等,能够有效地反映真实场景的多样性和复杂性。
- CamVid:CamVid数据集是一个语义分割的基准数据集,包含了由剑桥大学计算机实验室收集的视频序列和对应的像素级别标注信息。该数据集主要用于道路场景分割的研究和评估。CamVid数据集包含了701个视频图像序列,每个序列都包含了数百张分辨率为480×360的图像。这些图像涵盖了道路、人行道、建筑物、交通标志、汽车、行人等常见的道路场景。每个图像都被标注了32个不同的对象类别,包括路面、车辆、建筑物、人、树木等。
这些数据集覆盖了许多不同的场景和对象类别,并且包含了大量的图像和标注数据,可以用于训练和评估各种不同的语义分割神经网络模型。
2. 经典网络
经典的语义分割神经网络模型包括FCN,SegNet,U-Net,DeepLab和PSPNet,这些神经网络模型在语义分割任务中都具有一定的优势,并且在不同的场景和数据集上表现出了良好的性能。同时,还有许多基于这些模型的改进和扩展,可以进一步提高语义分割的精度和效率。
2.1 FCN
论文:Fully Convolutional Networks for Semantic Segmentation
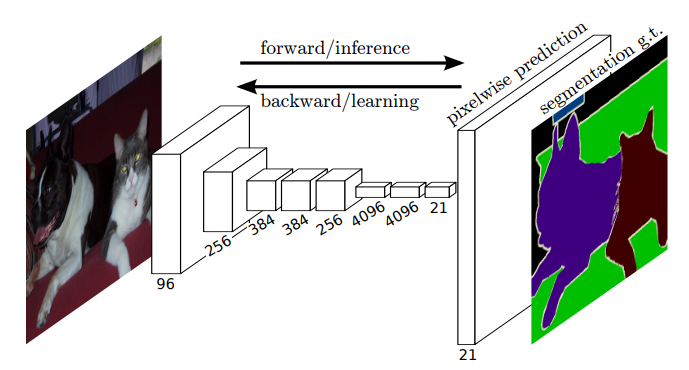
FCN是第一个专门用于语义分割的神经网络模型,通过将全连接层替换为卷积层,实现了端到端的像素级别的预测。FCN网络框架如下图所示,输入一张图像,经过全卷积网络得到S×S×(类别数+1)的特征图,然后通过上采样得到与输入图像分辨率一致的热力图,热力图包含了每个像素的类别信息。
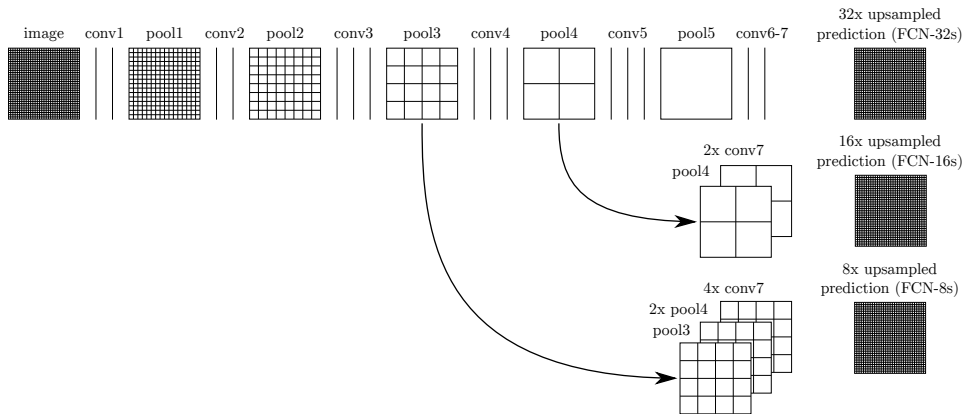
如果仅对最后一层卷积输出进行上采样,得到的分割结果并不理想,因为随着分辨率的减小,丢失了过多的细节信息。因此,FCN中提出了跳级结构,将不同阶段的特征进行结合,融合了局部信息和全局信息,能够获取更加精细和准确的分割结果。跳级结构示意图如下,论文中将最后一层卷积(conv7)输出直接上采样32倍的网络称为FCN-32s;将pool4输出与上采样两倍的conv7输出逐元素相加,然后经过16倍上采样得到最终预测结果,将该网络称为FCN-16s;同理,结合pool3、pool4和conv7的网络称为FCN-8s。直觉上来看,FCN-8s利用了更多的特征预测热力图,应该具有最高的分割精度,论文中的实验证明也确实如此。
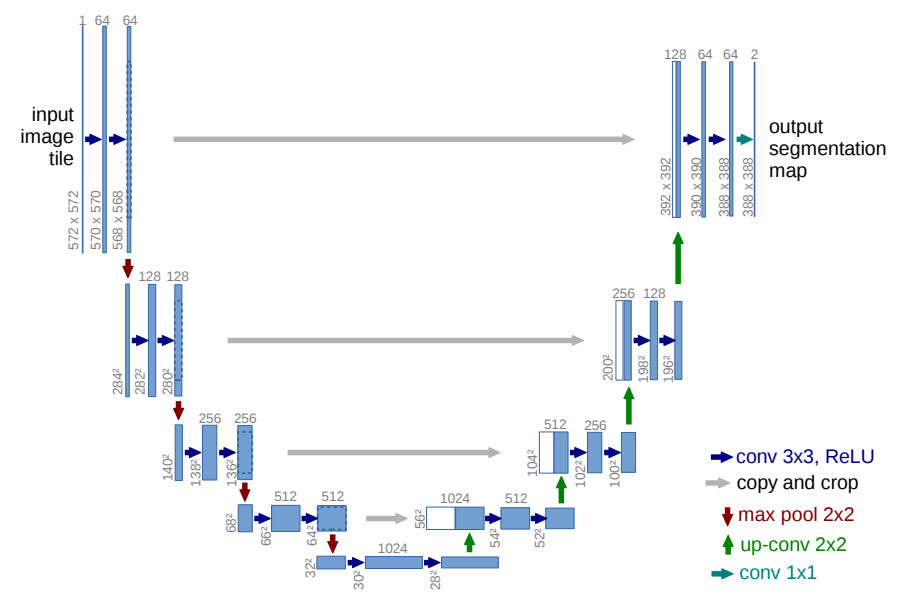
2.2 U-Net
U-Net: Convolutional Networks for Biomedical Image Segmentation
U-net 的设计初衷是为了解决医学图像分割问题,由于效果确实很好,后来也被广泛的应用于image-to-image领域。U-Net网络可以分为encoder、decoder和特征融合3个部分,其中encoder负责特征提取,decoder负责信息恢复,特征融合使用跨层跳跃连接,不同于FCN采用add的方式进行融合,U-Net采用的是concat。
2.3 DeepLab
DeepLab v1:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
DeepLab v1使用VGG-16作为基础模型,并对其进行了以下修改以适应语义分割任务:
① 将最后三个全连接层(fc6, fc7, fc8)改成卷积层
② 将最后两个池化层(pool4, pool5)步长由2改成1,并将最后三个卷积层(conv5_1, conv5_2, conv5_3)的dilate rate 设置为2
③ 输出层通道数改为21(20个类别,1个背景)
两个创新点:
① 减少下采样次数避免过多的信息丢失,同时通过使用空洞卷积保证感受野
② 全连接条件随机场后处理改善分割结果

DeepLab v2:Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
在DeepLab v1的基础上做了两点改进:
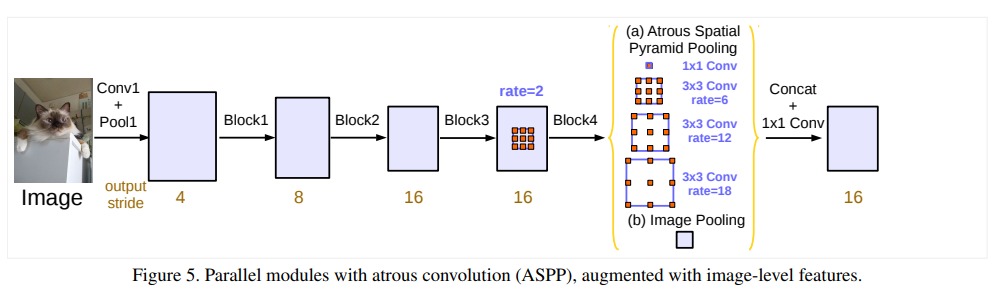
① 引入了ASPP(Atrous Spatial Pyramid Pooling,膨胀空间金字塔池化)策略,在给定的输入特征图上以不同采样率的空洞卷积并行采样,以多个尺度捕获目标和图像的上下文内容,从而获得更好的分割性能。
② 将VGG-16替换为ResNet-101

DeepLab v3:Rethinking Atrous Convolution for Semantic Image Segmentation
① 通过级联空洞卷积block,在控制特征图分辨率的同时保证较大感受野
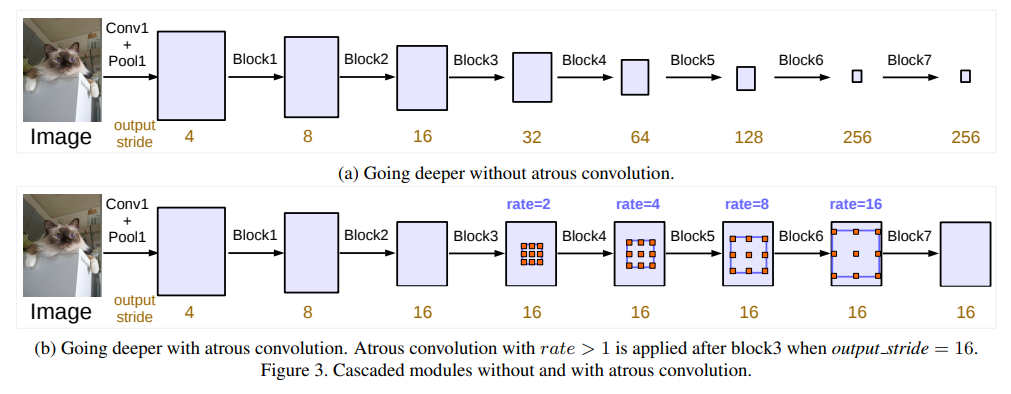
② 改进ASPP模块
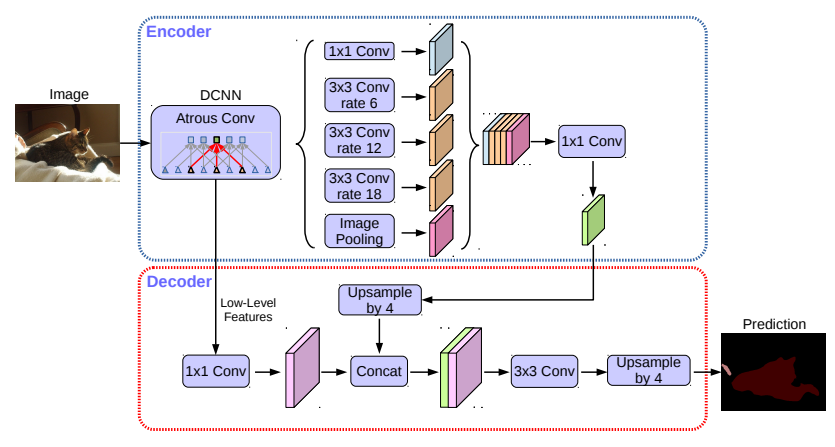
DeepLab v3+:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
改进点:
① 添加解码模块,融合低级特征和高级特征
② 使用改进的Xception网络作为backbone
③ 在ASPP中使用深度可分离卷积,在基本不影响模型效果的前提下减少计算量
2.4 PSPNet
论文:Pyramid Scene Parsing Network
亮点:使用金字塔池化模块融合多尺度特征
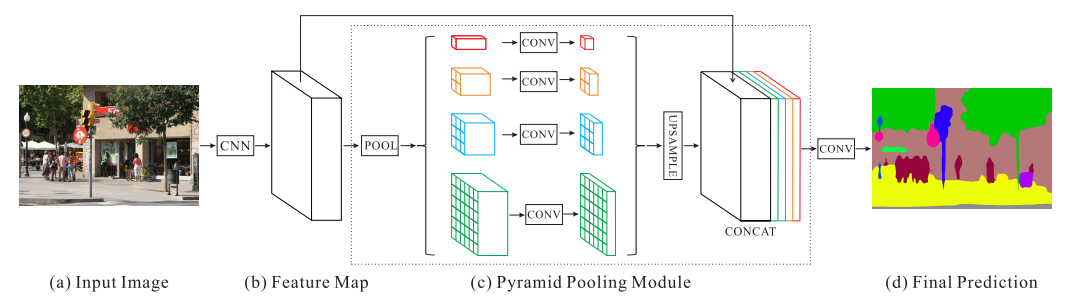
金字塔池化模块:POOL表示采用1x1、2x2、3x3和6x6四种不同尺寸的pooling操作得到多个尺寸的特征图,并通过1x1卷积来减少通道数。然后通过双线性插值(UPSAMPLE)将分辨率恢复到Feature Map大小,然后在通道上将原始feature和多尺度feature进行拼接。
2.5 SegNet
论文:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
SegNet由一个编码器网络和一个对应的解码器网络以及一个像素级分类层组成
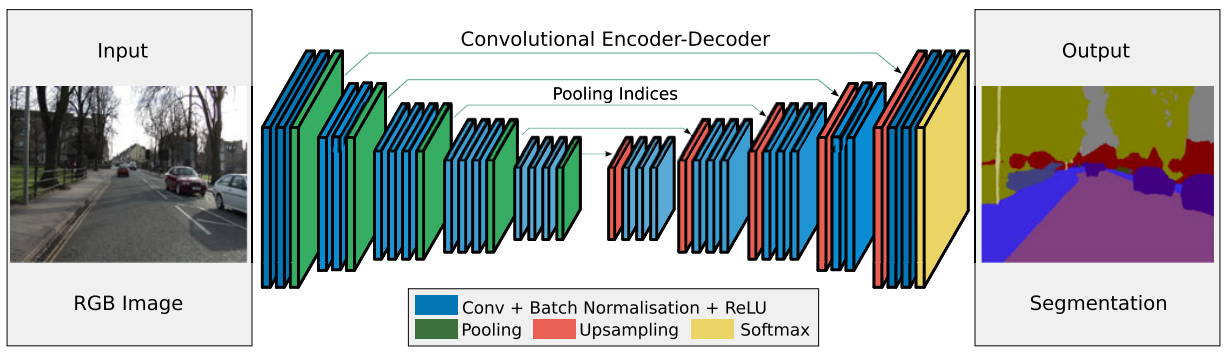
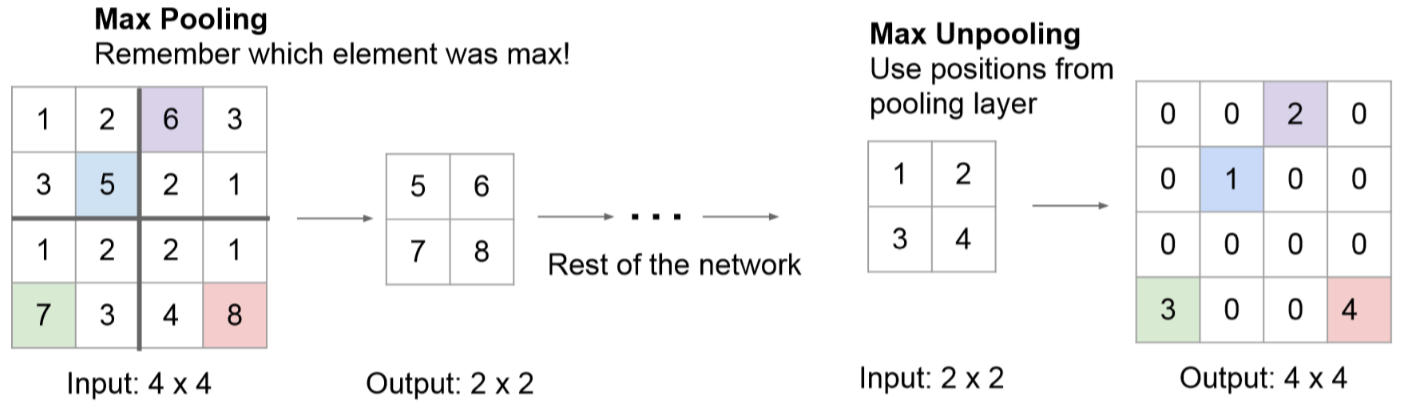
亮点:解码器使用在对应编码器的最大池化步骤中计算的池化索引来执行非线性上采样,这与反卷积相比,减少了参数量和运算量,而且消除了学习上采样的需要。
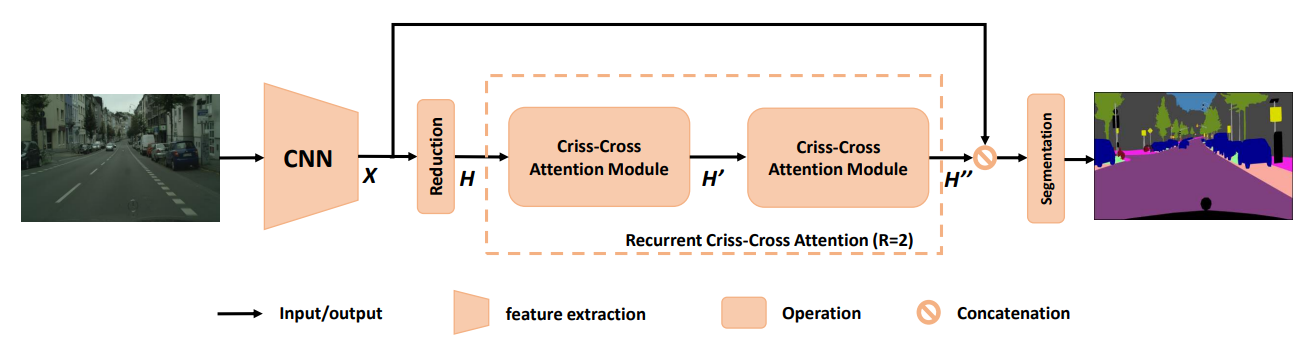
2.6 CCNet
CCNet: Criss-Cross Attention for Semantic Segmentation
创新点:提出了十字交叉注意力模块,能够获得密集的上下文信息,保持长距离的空间依赖性,并且相比non-local模块计算量较小。
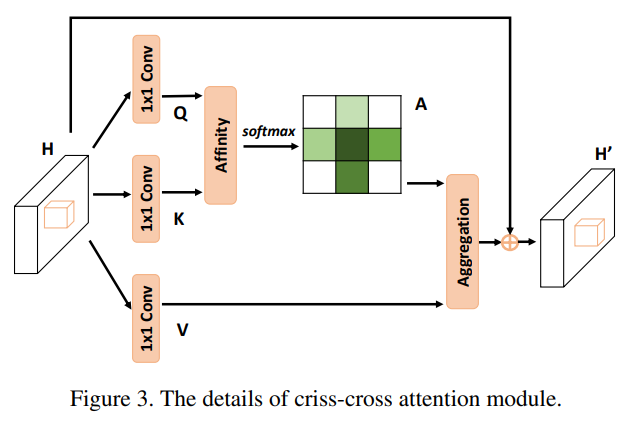
下图为十字交叉注意力模块的结构,可以看到,其实就是non-local模块的一种改进,都是通过key和query生成attention map,然后作用到value上。
通过循环两次十字交叉注意力模块,建立特征图中任意两个位置之间的依赖关系。为什么要循环两次呢?论文中也做了解释,loop1中,左下角和右上角没有建立依赖关系,第二次通过左上角和右下角的传递,实现了左下和右上依赖关系的建立。

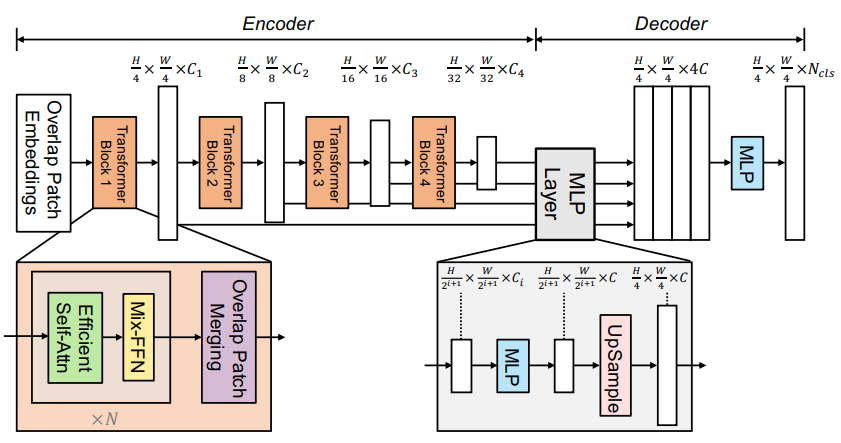
2.7 SegFormer
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
3. 损失函数
-
Cross-Entropy Loss
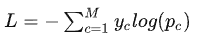
-
Weighted Cross Entropy Loss
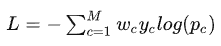
-
Dice Loss
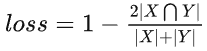
-
Focal Loss
Focal Loss for Dense Object Detection
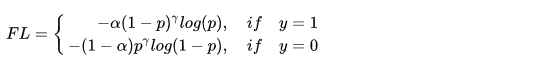
-
Lovasz-Softmax Loss
The Lovasz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks -
OHEM(Online Hard Example Mining)
4. 评价指标
- PA
- CPA
- MPA
- IOU
- mIOU
5. 最新进展
(2023.4) Segment Anything
项目地址:https://github.com/facebookresearch/segment-anything
项目主页:https://segment-anything.com/
分割一切,号称CV领域的ChatGPT,无需额外训练,分割效果极佳!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结