您现在的位置是:首页 >学无止境 >详解MySQL慢SQL定位、分析网站首页学无止境
详解MySQL慢SQL定位、分析
目录
1.概述
解决慢SQL的问题无非3步:
- 定位慢SQL
- 分析慢SQL
- 优化慢SQL
本文将按顺序介绍前两步该怎么做,第三步将会在后续的文章中详细讨论。
2.慢SQL定位
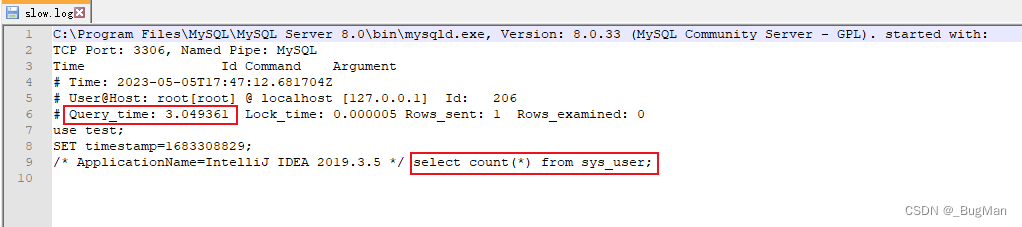
mysql自带了慢sql日志这个功能,会记录下慢SQL,以下是使用方法。
开启慢sql统计:
SET GLOBAL slow_query_log = on; //开启慢sql统计开关设置判断为慢sql的阈值(单位秒):
SET GLOBAL long_query_time = 1;设置日志位置:
set global slow_query_log_file="D:\slow.log";我在sys_user这个自己建的表里插入了一百万条数据,简单执行一个数量统计的SQL就会触发慢sql的阈值被记录下来:
3.SQL性能分析
3.1.例子
三张表,course(课程表)、teacher(教师表)、teacherCard(教师信息表),表关系如下:

建表语句:
create table course_info
(
cid bigint primary key,
name varchar(255),
_desc varchar(255)
) engine = innodb
default charset = utf8;
create table teacher_info
(
tid bigint primary key,
name varchar(255),
_desc varchar(255)
) engine = innodb
default charset = utf8;
create table school_timetable
(
id bigint primary key,
tid bigint,
cid bigint
)engine = innodb
default charset = utf8;数据:
insert into course_info value(1,'计算机组成原理','介绍计算机的体系结构');
insert into course_info value(2,'数据结构','介绍如何高效的组织数据');
insert into course_info value(3,'操作系统','介绍如何管理调度计算机的资源');
insert into course_info value(4,'JAVA','天下第一的编程语言');
insert into teacher_info value(1,'冯诺依曼','现代计算机之父');
insert into teacher_info value(2,'图灵','计算机科学之父');
insert into teacher_info value(3,'林纳斯托瓦兹','Linux之父');
insert into teacher_info value(4,'詹姆斯高斯林','java之父');
insert into school_timetable value(1,1,1);
insert into school_timetable value(2,2,2);
insert into school_timetable value(3,3,3);
insert into school_timetable value(4,4,4);3.2.SQL性能分析
可以通过explain关键字来对SQL进行性能分析,MySQL的EXPLAIN是一个查询优化工具,用于分析查询语句的执行计划,它会清晰的展示MySQL将会如何执行某个查询语句,包括执行的步骤、执行顺序、使用的索引、访问表的方式、以及如何连接表等。
以这条SQL为例:
explain select * from teacher_info;我们能得到以下结果集:

结果集包含以下参数:
| 参数 | 作用 |
|---|---|
| id | 编号 |
| select_type | 查询类型 |
| table | 表 |
| type | 连接类型 |
| possible_keys | 预测用到的索引 |
| key | 实际用到的索引 |
| key_len | 实际用到的索引长度 |
| ref | 本次查询引用了哪些字段,哪些数据进行查找 |
| rows | 完成当前查询,预计所要读取的行数 |
| Extra | 额外的信息 |
下面对一些核心参数进行一下详细介绍。
3.3.参数说明
3.3.1.id
每条SQL都会有个id用来决定执行顺序,
id值同则由大向小降序执行。
explain
select * from teacher_info
UNION
SELECT * FROM school_timetable 
id值相同则由上往下顺序执行。
explain
select * from teacher_info
left join school_timetable on teacher_info.tid=school_timetable.tid
left join course_info on course_info.cid=school_timetable.cid;
3.3.2.select_type
select_type,查询类型,这个参数会有点绕,但是其实理解即可,它在调优里用处并不大。 
3.3.3.key_len
key_len,实际用到的索引长度,可以用来辅助判断复合索引内生效的部分。
假设我建立了一个复合索引:
CREATE INDEX cid_tid ON school_timetable (cid, tid)索引全部生效:
explain select * from school_timetable where cid=4 and tid=4
部分索引生效:
explain select * from school_timetable where cid=4
3.3.4.rows
完成当前查询,预计所要读取的行数,是个估计值,不准确。
explain select * from school_timetable where cid<4
3.3.5.type
type,查找方式,查询操作的访问类型,它描述了 MySQL 在执行查询时使用的访问方法。
整个执行计划中重中之重的一个参数,整个SQL优化就是围绕此参数进行优化。
常用的访问方法按速度排:
-
system:系统表的查询,仅返回一行结果,速度最快。 -
const:常量查询,这种类型的查询是基于常量条件进行的,例如主键或唯一索引的查询,MySQL 在查询过程中已经确定只有一条匹配的结果。 -
eq_ref:唯一索引访问,通过唯一索引查找。这种类型的查询通常用于使用主键或唯一索引进行关联查询,每个索引值只有一条匹配的结果。 -
ref:非唯一索引访问,通过非唯一索引查找。这种类型的查询通常用于使用非唯一索引进行查询,每个索引值可能有多条匹配的结果。 -
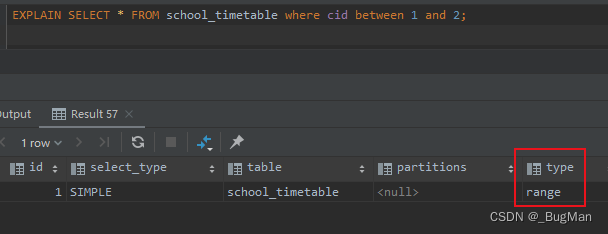
range:范围扫描,对索引使用了范围查找,例如使用BETWEEN、<、>等操作符进行的查询。 -
index:索引扫描,MySQL 使用非唯一索引进行扫描,表示在索引列上进行了查找。 -
ALL:全表扫描,MySQL 将对表中的每一行进行遍历。这种类型的查询通常发生在没有使用索引或无法使用索引的情况下,性能较差。
在实际工程中,前三种情况是很难达到的,基本没有什么适用场景,所以我们需要尽力保障能达到ref、range或者index,也就是至少要保证索引是有效的。
以下是前文表中出现以上情况的示例,由于system和eq_ref比较难造,暂时不包括:
const:

ref:

index:

range:
3.3.6.extra
这个字段表示查询后是否还要进行额外的操作再生成结果集。常见的值如下:
-
Using index: 表示查询使用了覆盖索引,即查询的数据可以直接从索引中获取,而无需进一步访问表数据。 -
Using where: 表示查询使用了WHERE条件进行过滤。 -
Using temporary: 表示查询需要创建临时表来处理结果集,通常发生在需要进行排序、分组或多表连接的情况下。 -
Using filesort: 表示查询需要进行排序操作,MySQL 无法使用索引进行排序,因此需要额外的文件排序操作。 -
Using index condition: 表示查询使用了索引条件进行过滤。 -
Using join buffer: 表示查询使用了连接缓冲区。 -
Distinct: 表示查询使用了DISTINCT关键字进行去重。 -
Full scan on NULL key: 表示在索引上执行全表扫描,但索引键值为空。 -
Range checked for each record: 表示对每条记录都进行了范围检查。 -
Using index for group-by: 表示查询使用了索引来进行分组操作。 -
Using index for order by: 表示查询使用了索引来进行排序操作。 -
Using index condition; Using where: 表示查询同时使用了索引条件和WHERE条件。
对于 SQL 调优来说,extra 字段是非常重要的。它提供了关于查询执行计划中的额外信息,可以帮助我们识别查询的性能瓶颈和优化的方向。
通过分析 extra 字段,我们可以判断以下情况:
-
是否使用了索引:
Using index表示查询使用了覆盖索引,可以避免访问表数据,提高查询性能。如果没有使用索引,可能需要考虑添加适当的索引来优化查询。 -
是否进行了排序:
Using filesort表示需要额外的文件排序操作,这可能导致性能下降。如果频繁出现文件排序,可能需要考虑优化查询或调整索引。 -
是否创建了临时表:
Using temporary表示需要创建临时表来处理结果集,可能会影响性能。需要审查查询语句并考虑是否可以避免使用临时表。 -
是否进行了全表扫描:
Using index表示使用了索引,而Using index; Using where表示同时使用了索引和WHERE条件进行过滤。如果出现Using index之外的情况,可能需要优化查询或调整索引以避免全表扫描。 -
是否使用了连接缓冲区:
Using join buffer表示使用了连接缓冲区,可能会影响查询性能。需要审查查询语句并考虑是否可以优化连接操作。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结