您现在的位置是:首页 >技术交流 >[chapter 31][PyTorch][Early Stop& Dropout]网站首页技术交流
[chapter 31][PyTorch][Early Stop& Dropout]
前言
深度神经网络结构的过拟合是指 :
在训练集上的正确率很高, 但在测试集上的准确率很低.
为了缓解网络过拟合的问题,
其中一种常见的办法是使用 dropout ,Early Stop
目录:
1: Early Stop
2: Dropout
3: stochastic Gradient Descent
一 Early Stop
Early Stop的概念非常简单,在我们一般训练中,经常由于过拟合导致在训练集上的效果好,而在测试集上的效果非常差。因此我们可以让训练提前停止,在测试集上达到最好的效果时候就停止训练,而不是等到在训练集上饱和在停止,这个操作就叫做Early Stop。

二 Dropout
2.1 Dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
2.2 Dropout
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
在2012年,Alex、Hinton在其论文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止过拟合。并且,这篇论文提到的AlexNet网络模型引爆了神经网络应用热潮,并赢得了2012年图像识别大赛冠军,使得CNN成为图像分类上的核心算法模型。
。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。
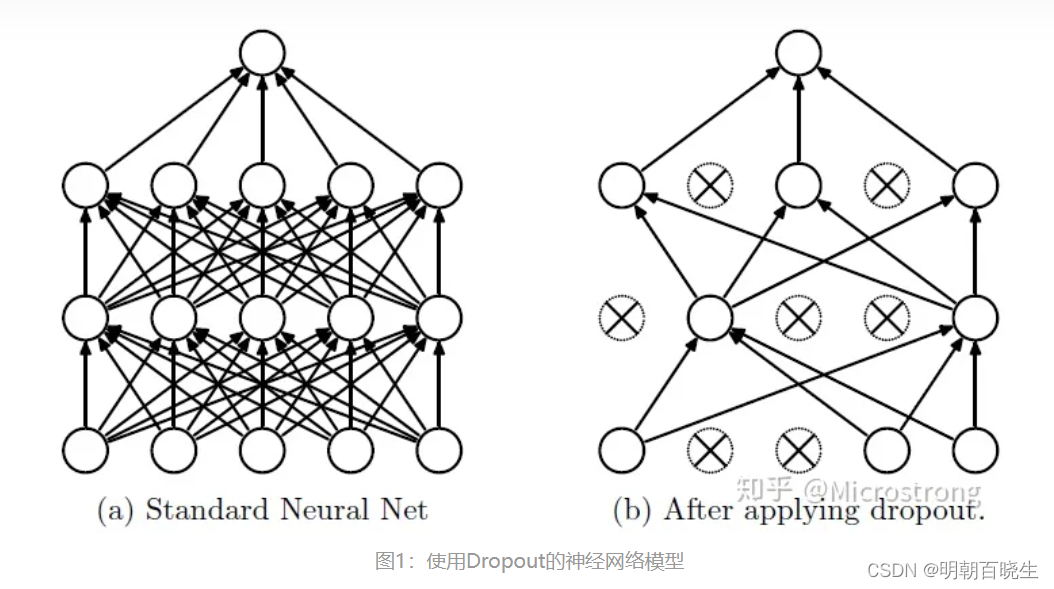
2.3 Dropout 网络结构
以DNN结构为例
默认神经元结构
增加Drop out 功能后的,神经元结构
2.4 dropout 前向传播原理
这里重点介绍一下Dropout 神经元输入d 产生的原理
某一层神经元输入向量为 ,
step1 : 生成每个输入单元对应的dropout 概率
r = torch.rand(k)
step2: 生成掩码向量
掩码向量
step3 生成dropout 输入向量 d
2.5 反向传播原理
所以
2.6 PyTorch 代码

要注意的下面两个API 作用是相反,第一是dropout,第二个是保留

train 的时候神经元需要dropout,但是测试的时候,要保留,通过eval 实现

三 stochastic Gradient Descent
原理比较简单,由于硬件限制,我们不会拿train 数据集中的所有样本训练,
假设样本总数为m,每轮训练只会随机选取部分数据集训练,batch size

dropout函数详解及反向传播中的梯度求导_dropout反向传播梯度如何计算_BrightLampCsdn的博客-CSDN博客





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结