您现在的位置是:首页 >技术教程 >PyTorch实战4:猴痘病识别网站首页技术教程
PyTorch实战4:猴痘病识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第P4周:猴痘病识别
- 🍖 原作者:K同学啊|接辅导、项目定制
目录
本次实战主要学习内容:
- 调整网络结构使测试集accuracy到达88%
- 训练过程中保存效果最好的模型参数
一、搭建CNN网络结构
- 读取并加载本地数据以及数据增强可移步至PyTorch实战3:天气识别进行学习
- 卷积层、全连接层、池化层以及批量归一化层的详解可移步至PyTorch实战2:彩色图片识别(CIFAR10)
1、原文网络结构
1.1、网络结构赘述
代码定义了一个名为Network_bn的类,继承自nn.Module。
该类实现了一个卷积神经网络(CNN),包含了多个卷积层和池化层。
在类的初始化函数中,首先调用父类nn.Module的构造函数以进行初始化操作。
然后依次创建了六个神经网络层:
- 两个卷积层、两个Batch Normalization层、一个最大池化层和一个全连接层。
- 其中Conv2d函数用于创建二维卷积层,
- BatchNorm2d函数用于创建二维批量归一化层,
- MaxPool2d函数用于创建最大池化层,
- Linear函数用于创建全连接层。
网络结构详解:
- self.conv1是输入为3通道,输出为12通道,卷积核大小为5x5的卷积层;
- self.bn1是12通道的Batch Normalization层;
- self.conv2是输入为12通道,输出为12通道,卷积核大小为5x5的卷积层;
- self.bn2是12通道的Batch Normalization层;
- self.pool是2x2最大池化层;
- self.conv4是输入为12通道,输出为24通道,卷积核大小为5x5的卷积层;
- self.bn4是24通道的Batch Normalization层;
- self.conv5是输入为24通道,输出为24通道,卷积核大小为5x5的卷积层;
- self.bn5是24通道的Batch Normalization层;
- self.fc1是全连接层,输入大小为24x50x50,输出大小为类别数(len(classNames))。
具体实现了以下结构:
- 三层卷积层和两个池化层,用于提取特征
- 五个批次归一化(Batch Normalization)层,用于加速训练过程
- 一个全连接层,用于输出分类结果
1.2、前向传播实现
接下来是forward函数,该函数定义了数据的前向传递流程。
- 首先将输入x通过第一个卷积层conv1进行卷积,然后将卷积结果输入到第一个Batch Normalization层bn1中进行归一化处理,并通过激活函数F.relu进行非线性变换。
- 接着将处理结果输入到第二个卷积层conv2中进行卷积,再将卷积结果输入到第二个Batch Normalization层bn2中进行归一化处理,并通过激活函数F.relu进行非线性变换。
- 然后通过最大池化层pool进行下采样,缩小特征图的尺寸。然后将处理结果输入到第四个卷积层conv4中进行卷积,再将卷积结果输入到第四个Batch Normalization层bn4中进行归一化处理,并通过激活函数F.relu进行非线性变换。
- 接着将处理结果输入到第五个卷积层conv5中进行卷积,再将卷积结果输入到第五个Batch Normalization层bn5中进行归一化处理,并通过激活函数F.relu进行非线性变换。
- 最后通过最大池化层pool进行下采样,缩小特征图的尺寸。然后通过view函数将特征图展成一维向量,输入到全连接层fc1中进行分类。
具体来说,
- x = F.relu(self.bn1(self.conv1(x)))表示先通过卷积层和Batch Normalization层提取特征,再进行ReLU激活;
- x = F.relu(self.bn2(self.conv2(x)))同理;
- x = self.pool(x)表示进行2x2最大池化操作;
- x = F.relu(self.bn4(self.conv4(x)))同理;
- x = F.relu(self.bn5(self.conv5(x)))同理;
- x = self.pool(x)同理;
- x = x.view(-1, 245050)将特征张量展平为一维向量;
- x = self.fc1(x)表示通过全连接层得到分类结果。
1.3、原型网络结构
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
# 第1层卷积层:输入有3个channel,输出有12个channel,卷积核大小为5x5,步长为1,填充为0
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
# 第1个Batch Normalization层,有12个channel的输出
self.bn1 = nn.BatchNorm2d(12)
# 第2层卷积层:输入有12个channel,输出有12个channel,卷积核大小为5x5,步长为1,填充为0
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
# 第2个Batch Normalization层,有12个channel的输出
self.bn2 = nn.BatchNorm2d(12)
# 第1个池化层,窗口大小为2x2,步长为2
self.pool = nn.MaxPool2d(2,2)
# 第3层卷积层:输入有12个channel,输出有24个channel,卷积核大小为5x5,步长为1,填充为0
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
# 第3个Batch Normalization层,有24个channel的输出
self.bn4 = nn.BatchNorm2d(24)
# 第4层卷积层:输入有24个channel,输出有24个channel,卷积核大小为5x5,步长为1,填充为0
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
# 第4个Batch Normalization层,有24个channel的输出
self.bn5 = nn.BatchNorm2d(24)
# 全连接层:输入是24x50x50(24个24x24的feature map),输出是类别数
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
# 第1层卷积层+Batch Normalization层+ReLU激活函数
x = F.relu(self.bn1(self.conv1(x)))
# 第2层卷积层+Batch Normalization层+ReLU激活函数
x = F.relu(self.bn2(self.conv2(x)))
# 第1个池化层
x = self.pool(x)
# 第3层卷积层+Batch Normalization层+ReLU激活函数
x = F.relu(self.bn4(self.conv4(x)))
# 第4层卷积层+Batch Normalization层+ReLU激活函数
x = F.relu(self.bn5(self.conv5(x)))
# 第2个池化层
x = self.pool(x)
# 展开成一维张量
x = x.view(-1, 24*50*50)
# 全连接层
x = self.fc1(x)
return x
- 模型打印:

其中,ReLU激活函数在卷积层中使用以增强模型的非线性特征。所有层之间都使用了Batch Normalization技术,可以有效地加速训练过程并提高模型的稳定性。
2、调整网络结构
2.1、提升精度方案
可以考虑尝试以下几个调整来提升网络精度:
-
增加卷积层的数量和大小:增加卷积层的数量和大小可以提高网络的感受野,从而更好地捕捉图像的特征。可以尝试增加一些卷积层和调整卷积核的大小。
-
调整池化层的大小:池化层可以减小数据的维度,但是过大的池化层会导致信息丢失。可以尝试使用更小的池化层或者不使用池化层。
-
使用更深的网络结构:可以尝试使用更深的网络结构,如ResNet、DenseNet等,这些网络结构能够更好地解决梯度消失问题,从而使得模型训练更加稳定。
-
数据扩充(data augmentation):可以通过对训练数据进行随机裁剪、旋转、翻转等操作来扩充数据集,从而提高模型的泛化能力。
-
使用预训练的模型进行微调:可以使用在大规模数据集上预训练的模型,在本任务上进行微调,能够更好地利用已有数据集的信息,提高模型的精度。
-
调整超参数:可以尝试调整学习率、批量大小、优化器等超参数来获得更好的结果。
-
使用更多的正则化技术:可以尝试使用 Dropout、L2 正则化等技术来减少过拟合。
-
增加数据集:可以尝试增加训练数据的数量,或者通过数据增强技术来生成更多的数据样本,以便网络可以更好地学习数据特征。
2.2、网络结构调整
调整后的模型包括若干个卷积层和池化层,并使用批归一化层进行正则化。在输入数据后,模型通过这些卷积和池化操作将其转换为特征向量,并使用全连接层对其进行分类。这个模型与原始的卷积神经网络不同之处在于:
- 添加了一个新的卷积层,用于提取更多的特征;
- 在模型中添加了一个批归一化层,可以加速训练并提高准确率;
- 修改了全连接层的输入大小,以适应新的卷积层。
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(12),
nn.ReLU(),
nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(12),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(24),
nn.ReLU(),
nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(24),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=24, out_channels=48, kernel_size=5, stride=1, padding=0), # 添加了一个新的卷积层
nn.BatchNorm2d(48),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Linear(48 * 23 * 23, len(classNames)) # 修改了全连接层的输入大小
def forward(self, x):
x = self.features(x)
x = x.view(-1, 48 * 23 * 23)
x = self.classifier(x)
return x
- 模型打印:
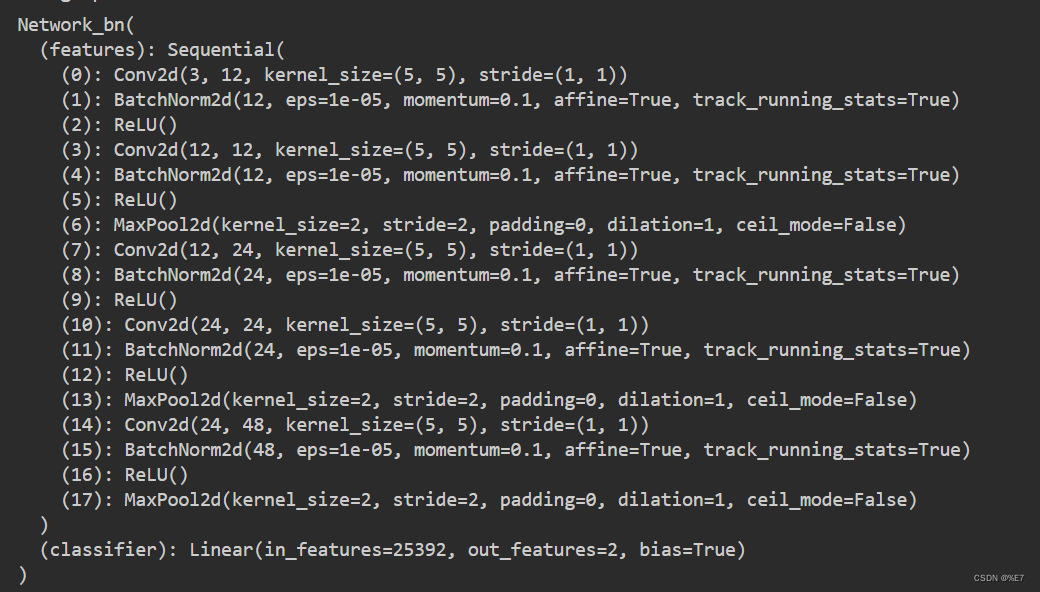
3、结果成效与对比
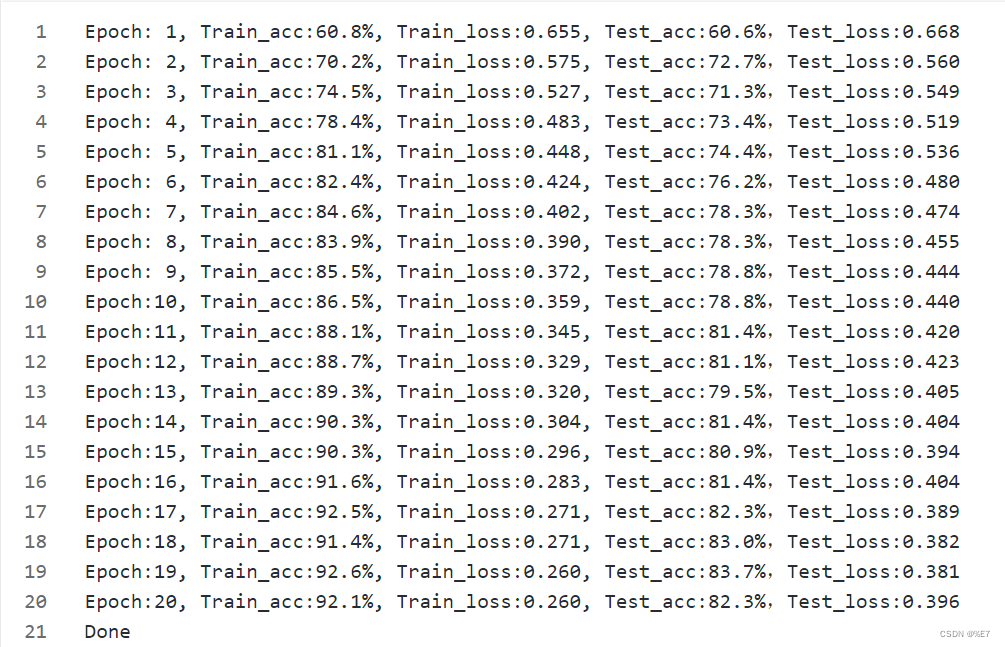
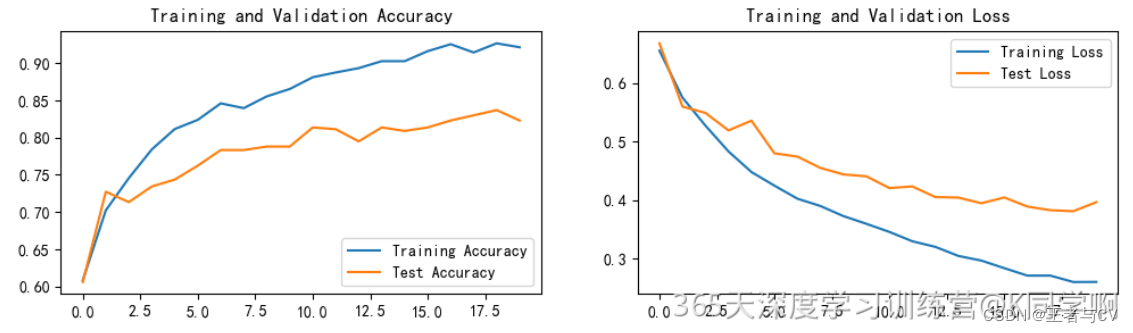
3.1、原模型结果可视化
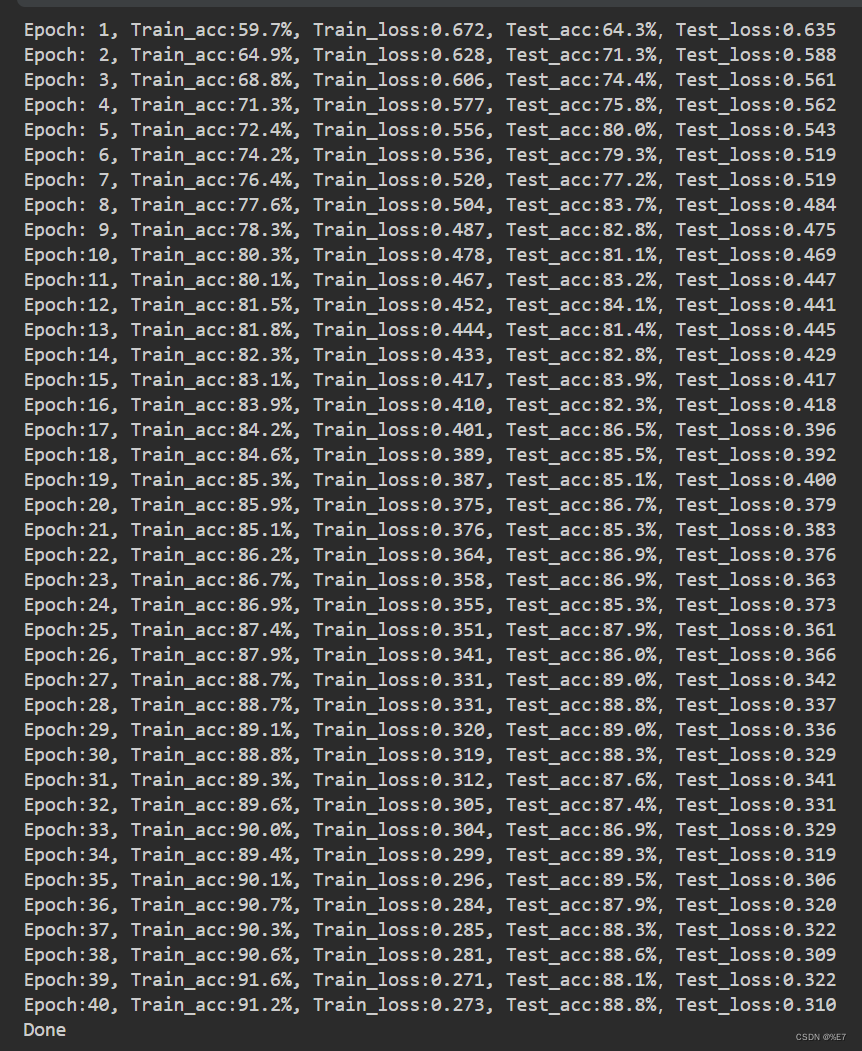
3.2、调整后结果可视化
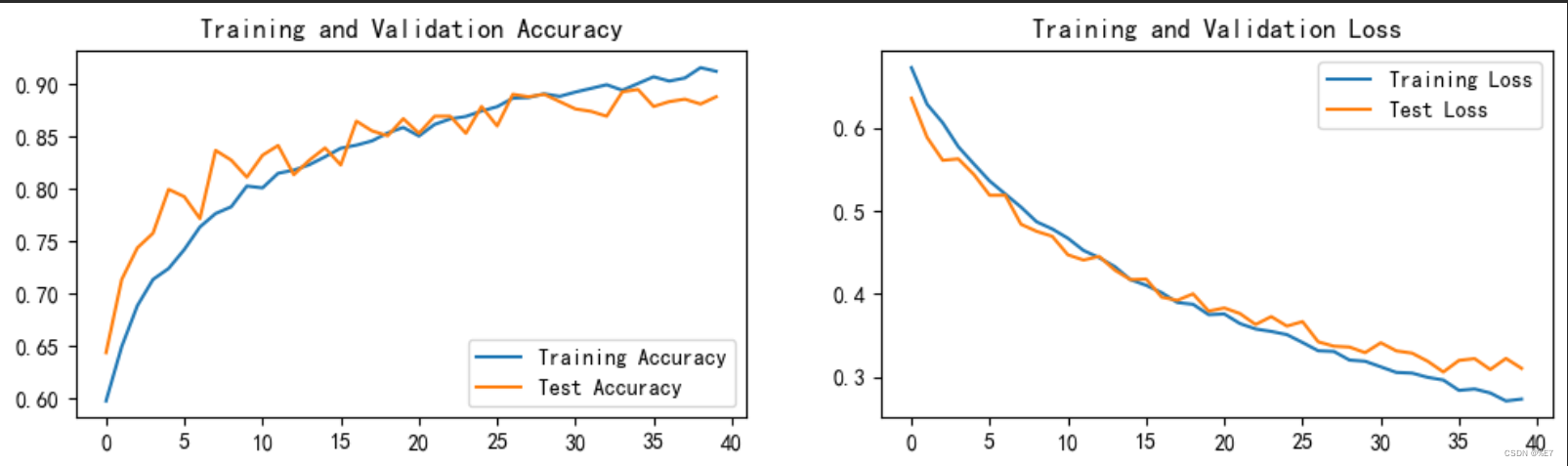
二、保存并加载模型
首先,将模型的参数保存到指定路径下的文件中。PATH 变量为保存的参数文件名,model.state_dict() 返回当前模型的参数字典,并使用 torch.save() 将其保存到 PATH 指定的文件中。
- 定义一个文件路径PATH,用于保存模型参数
- model.state_dict()函数返回一个字典对象,其中包含了模型中所有的可学习参数和缓存项
- torch.save()函数将这个字典保存到指定的文件路径中
- torch.load()函数将保存的参数加载回到模型中
- model.load_state_dict()函数将加载的参数复制到模型中
# 定义保存参数的文件路径
PATH = './model.pth'
# 保存模型参数到指定文件路径
torch.save(model.state_dict(), PATH)
接着,可以在需要使用这些参数的时候,通过 torch.load() 方法将之前保存的参数加载回来。其中,map_location 参数指定了模型应该加载到哪个设备上(例如CPU或GPU)。
model.load_state_dict(torch.load(PATH, map_location=device)) # 将参数加载到模型实例中
总体而言,这段代码的作用是实现了对训练好的神经网络模型进行持久化存储并在需要的时候重新加载模型参数。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结