您现在的位置是:首页 >其他 >基于人脸表情的情绪识别网站首页其他
基于人脸表情的情绪识别
1.前言
作为一个在人脸识别领域有一定经验的人,我在过去的项目中涉及了很多与人脸识别相关的任务。我整理了一些项目,但由于学业繁重,整理这些内容一直是断断续续的。最近正值五一假期,我想利用这个时间来整理一篇关于人脸表情识别的文章。这项技术可以识别出人的基本情绪,例如开心、悲伤等,具有广泛的应用价值。
2.相关工作
以我有限的知识来讲的话,基于人脸表情的情绪识别通常包括两个主要任务:人脸检测和人脸表情分类。人脸检测是指在输入图像中检测和定位人脸的位置和大小,为后续的表情识别提供基础数据;人脸表情分类是指将输入的人脸图像分为多个情感类别,例如愤怒、厌恶、恐惧、开心、伤心、惊讶和中性等。

目前,人脸识别( Facial Recognition, FR)精度已经超过人眼,人脸表情识别作为FR技术的一个重要组成部分,在计算机视觉、人机交互和情感计算中有着广泛的研究前景,包括人机交互、情绪分析、智能安全、娱乐、网络教育、智能医疗等。人脸表情识别的主要框架分为三个步骤:图像预处理、人脸检测和表情分类,如图所示。

本文采取Fer2013数据集,由35887张人脸图片组成,该数据集包含28709个训练样本,3859个验证样本和3859个测试样本。均为48×48的灰度图像。

3.项目实现
3.1 OpenCV人脸检测
基于OpenCV的人脸检测算法是目前非常流行的一种实现方法,它通过使用级联分类器(Cascade Classifier)来检测图像中的人脸。下面是一个基于Python的人脸检测代码示例:
import cv2
# 加载级联分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 加载图像并进行灰度化处理
img = cv2.imread('test.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 进行人脸检测
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 绘制矩形框标识人脸位置
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,0,255), 2)
# 显示结果图像
cv2.imshow('result', img)
cv2.waitKey(0)
人脸检测就是用来判断一张图片中是否存在人脸的操作。如果图片中存在人脸,则定位该人脸在图片中的位置;如果图片中不存在人脸,则返回图片中不存在人脸的提示信息。人脸检测是表情识别中必不可少的环节,其检测效果的好坏,将直接影响整个系统的性能优劣。如图所示,蓝色矩形框代表了从图片中检测到的人脸图像位置。

3.2Mini-Xception网络
本文表情分类的网络架构采用Mini-Xception卷积神经网络,其结构如图所示。其中包含4个残差深度可分离卷积块,每个卷积之后对卷积层进行批量归一化(BathNorm)操作及ReLu激活函数。最后一层采用全局平均池化层和softmax激活函数进行预测。
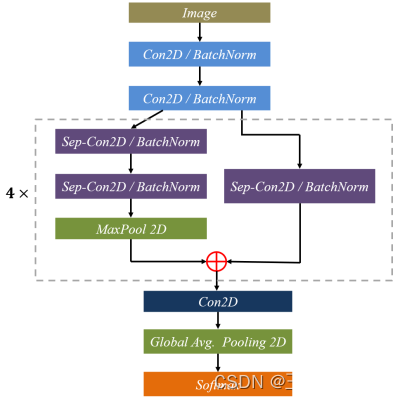
构造的mini-Xception网络模型,其优点在于删除了传统神经网络的全连接层并使用深度可分离卷积替代传统的卷积层,显著降低了训练参数量并缩短了训练时间,提高了模型的泛化能力。Mini-Xception网络的Python实现如下,具体采用Keras框架实现:
from keras.layers import Input, Conv2D, BatchNormalization, Activation, SeparableConv2D
from keras.layers import MaxPooling2D, GlobalAveragePooling2D, Dense, Dropout
from keras.models import Model
def mini_Xception(input_shape, num_classes):
# 定义输入层
inputs = Input(shape=input_shape)
# 第一个卷积块
x = Conv2D(8, (3, 3), strides=(1, 1), padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第二个卷积块
x = SeparableConv2D(16, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(16, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第三个卷积块
x = SeparableConv2D(32, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(32, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第四个卷积块
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
x = Dropout(0.5)(x)
x = SeparableConv2D(64, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(64, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第五个卷积块
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
x = Dropout(0.5)(x)
x = SeparableConv2D(128, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(128, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 全局平均池化和输出层
x = GlobalAveragePooling2D()(x)
outputs = Dense(num_classes, activation='softmax')(x)
# 创建模型
model = Model(inputs=inputs, outputs=outputs)
return model
4.实验结果与分析
4.1模型训练
本文的研究基于 Keras 深度学习框架搭建Mini-Xception模型,采用经预处理的Fer2013表情数据集进行模型训练。在训练结束后会将训练的模型保存为hdf5文件到指定文件夹下,训练过程结果输出如图。
4.2 结果分析
随着训练的不断进行,尽管其训练曲线不断波动,但训练集和验证集的准确率保持逐渐提升,最终两条曲线均达到平稳状态,得到的训练曲线如图所示。

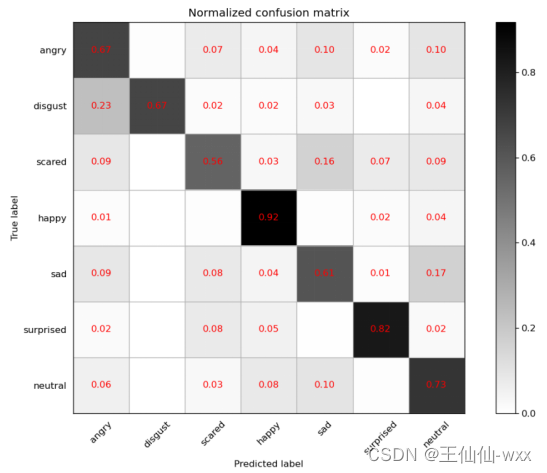
训练完成后,选取验证集准确率最佳的模型参数,最终在测试集进行测试验证。本文利用混淆矩阵对模型在测试集上的效果进行评估,其混淆矩阵的结果如图所示。Mini-Xception 对Happy的识别率可达92%,而对Scared的识别度最低仅为56%,可能是因为不同表情的数量不均衡导致。在识别过程中可以观察到,Sad和Scared, Angry和Disgust 的识别难度较大。
4.3 应用测试
为了更好应用于日常的表情识别场景,检测实际的表情识别性能,结合前面章节介绍的人脸检测和表情识别算法,设计了实际场景下的表情识别过程,其识别过程如图所示。

首先获取图像并进行预处理,然后利用Haar级联分类器检测人脸位置,对人脸位置区域利用Mini-Xception进行表情识别,最终将表情识别的结果显示并输出。根据以上流程,本文基于PyQt5设计了表情识别系统界面。该系统界面如图19所示,其大致功能如下:
(1)可选择模型文件后基于该模型进行识别;
(2)打开摄像头识别实时画面中的人脸表情;
(3)选择一张人脸图片,对其中的表情进行识别。

5.参考文献
- Zeng Z H, Pantic M, Roisman G I, et al. A survey of affect recognition methods: audio, visual, and spontaneous expressions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(1): 39-58.
- Ekman P, Friesen W V. Constants across cultures in the face and emotion[J]. Journal of Personality and Social Psychology, 1971, 17(2): 124-129.
- Ojala T, Pietikäinen M, Harwood D. A comparative study of texture measures with classification based on featured distributions[J]. Pattern Recognition, 1996, 29(1): 51-59.
- Albiol A, Monzo D, Martin A, et al. Face recognition using HOG – EBGM[J]. Pattern Recognition Letters, 2008, 29(10): 1537-1543.
- Viola P, Jones M J. Robust Real-Time Face Detection[J]. International Journal of Computer Vision, 2004, 57(2):137-154.
- Neubeck A, Gool L. Efficient Non-Maximum Suppression[C]// International Conference on Pattern Recognition. IEEE Computer Society, 2006.
- Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 7-12, 2015. Boston, MA, USA. IEEE, 2015:1-9.
- Chollet F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 21-26, 2017. Honolulu, HI. IEEE, 2017: 1800-1807.
- Wang M, Liu B, Foroosh H. Design of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial “Bottleneck” Structure[EB/OL]. [2020-03-15]. http://arxiv.org/abs/1608.04337.
- Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]. 32nd International Conference on Machine Learning, ICML, 2015, 2015(1): 448-456.
- Goodfellow I J, Erhan D, Luc Carrier P, et al. Challenges in representation learning: a report on three machine learning contests[J]. Neural Networks, 2015(64): 59-63.
- Kingma D P, Ba J L. Adam: A method for stochastic optimization[J]. 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings, 2015: 1-15.






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结