您现在的位置是:首页 >技术杂谈 >BERT+TextCNN实现医疗意图识别项目网站首页技术杂谈
BERT+TextCNN实现医疗意图识别项目
简介BERT+TextCNN实现医疗意图识别项目
BERT+TextCNN实现医疗意图识别项目
一、说明
本项目采用医疗意图识别数据集CMID传送门
数据集示例:
{
"originalText": "间质性肺炎的症状?",
"entities": [{"label_type": "疾病和诊断", "start_pos": 0, "end_pos": 5}],
"seg_result": ["间质性肺炎", "的", "症状", "?"],
"label_4class": ["病症"],
"label_36class": ["临床表现"]
}
模型使用BERT、TextCNN实现意图分类
二、BERT模型加载
使用苏建林开发的bert4keras深度学习框架加载BERT模型
from bert4keras.backend import keras,set_gelu
from bert4keras.models import build_transformer_model # 加载BERT的方法
from bert4keras.optimizers import Adam # 优化器
set_gelu('tanh')
1.定义函数加载BERT
def build_bert_model(config_path , checkpoint_path , class_nums) : # config_path配置文件的路径 checkpoint_path预训练路径 class_nums类别的数量
bert = build_transformer_model(
config_path = config_path ,
checkpoint_path = checkpoint_path ,
model = 'bert' ,
return_keras_model= False)
# 在BERT模型输出中抽取[CLS]
cls_features = keras.layers.Lambda(lambda x:x[:,0],name='cls-token')(bert.model.output) # [:,0]选取输出的第一列,BERT模型的输出中[CLS]在第一个位置 shape = [batch_size ,768]
all_token_embedding = keras.layers.Lambda(lambda x:x[:,1:-1],name='all-token')(bert.model.output) # 获取第2列至倒数第二列的所有token shape = [batch_size ,maxlen-2,768] 除去CLS、SEP
# textcnn抽取特征
cnn_features = textcnn(all_token_embedding, bert.initializer) # 输入all_token_embedding shape = [batch_size,cnn_output_dim]
# 将cls_features 与 cnn_features 进行拼接
concat_features = keras.layers.concatenate([cls_features,cnn_features] ,axis= -1)
# 全连接层
dense = keras.layers.Dense (
units= 512, # 输出维度
activation = 'relu' , # 激活函数
kernel_initializer= bert.initializer # bert权重初始化
)(concat_features) # 输入
# 输出
output = keras.layers.Dense (
units= class_nums, # 输出类别数量
activation= 'softmax', # 激活函数 (多分类输出层最常用的激活函数)
kernel_initializer= bert.initializer # bert权重初始化
)(dense) # 输入
model = keras.models.Model(bert.model.input,output) # (bert.model.input输入,output输出)
print(model.summary())
return model
2.实现TextCNN
def textcnn(input,kernel_initializer) :
# 3,4,5
cnn1 = keras.layers.Conv1D(
256, # 卷积核数量
3, # 卷积核大小
strides= 1, # 步长
padding= 'same', # 输出与输入维度一致
activation='relu', # 激活函数
kernel_initializer = kernel_initializer # 初始化器
)(input) # shape = [batch_size ,maxlen-2,256]
cnn1 = keras.layers.GlobalAvgPool1D()(cnn1) # 全局最大池化操作 shape = [batch_size ,256]
cnn2 = keras.layers.Conv1D(
256, # 卷积核数量
4, # 卷积核大小
strides=1, # 步长
padding='same', # 输出与输入维度一致
activation='relu', # 激活函数
kernel_initializer=kernel_initializer # 初始化器
)(input)
cnn2 = keras.layers.GlobalAvgPool1D()(cnn2) # 全局最大池化操作 shape = [batch_size ,256]
cnn3 = keras.layers.Conv1D(
256, # 卷积核数量
5, # 卷积核大小
strides=1, # 步长
padding='same', # 输出与输入维度一致
kernel_initializer=kernel_initializer # 初始化器
)(input)
cnn3 = keras.layers.GlobalAvgPool1D()(cnn3) # 全局最大池化操作 shape = [batch_size ,256]
# 将三个卷积结果进行拼接
output = keras.layers.concatenate([cnn1,cnn2,cnn3],
axis= -1)
output = keras.layers.Dropout(0.2)(output) # 最后接Dropout
return output
3.程序入口
if __name__ == '__main__':
config_path = '.chinese_L-12_H-768_A-12\bert_config.json'
checkpoint_path = '.chinese_L-12_H-768_A-12\bert_model.ckpt'
class_nums = 13
build_bert_model(config_path , checkpoint_path , class_nums)
其中BERT模型文件可以自行在Github中下载,也可私信。
当程序开始加载模型时,表示运行成功。
切记!运行代码前,检查TensorFlow、bert4keras等第三方库的版本是否一致,否则容易报错!
4.本项目第三方库以及对应的版本
pyahocorasick==1.4.2
requests==2.25.1
gevent==1.4.0
jieba==0.42.1
six==1.15.0
gensim==3.8.3
matplotlib==3.1.3
Flask==1.1.1
numpy==1.16.0
bert4keras==0.9.1
tensorflow==1.14.0
Keras==2.3.1
py2neo==2020.1.1
tqdm==4.42.1
pandas==1.0.1
termcolor==1.1.0
itchat==1.3.10
ahocorasick==0.9
flask_compress==1.9.0
flask_cors==3.0.10
flask_json==0.3.4
GPUtil==1.4.0
pyzmq==22.0.3
scikit_learn==0.24.1
三、数据预处理
抽取CMID.json中的数据,并划分为训练集与测试集
从中选取13个类别作为最终意图分类的标签
定义
病因
预防
临床表现(病症表现)
相关病症
治疗方法
所属科室
传染性
治愈率
禁忌
化验/体检方案
治疗时间
其他
1.抽取数据
def gen_training_data(row_data_path) :
label_list = [line.strip() for line in open('./dataset/label', 'r' ,encoding='utf8')]
print(label_list)
# 映射id,为每一条数据添加id
label2id = {label : idx for idx, label in enumerate(label_list)}
data = []
with open('./dataset/CMID.json','r',encoding='utf8') as f :
origin_data = f.read()
origin_data = eval(origin_data)
label_set = set()
for item in origin_data :
text = item['originalText']
label_class = item['label_4class'][0].strip("'")
if label_class == '其他' :
data.append([text , label_class ,label2id[label_class]])
continue
label_class = item["label_36class"][0].strip("'") # 所有的意图标签都从label_36class中取出
label_set.add(label_class)
if label_class not in label_list:
continue
data.append([text, label_class ,label2id[label_class]])
print(label_set)
data = pd.DataFrame(data , columns=['text','label_class','label'])
print(data['label_class'].value_counts())
data['text_len'] = data['text'].map(lambda x : len(x)) # 序列长度
print(data['text_len'].describe())
plt.hist(data['text_len'], bins=30, rwidth= 0.9, density=True)
plt.show()
del data['text_len']
data = data.sample(frac = 1.0)
# 将数据集拆分为测试集和训练集
train_num = int(0.9*len(data))
train , test = data[:train_num],data[train_num:]
train.to_csv('./dataset/train.csv', index=False)
test.to_csv('./dataset/test.csv', index = False)
2.加载训练数据集
# 加载训练数据集
def load_data(filename) :
df = pd.read_csv(filename , header= 0 )
return df[['text','label']].values
3.数据集信息可视化
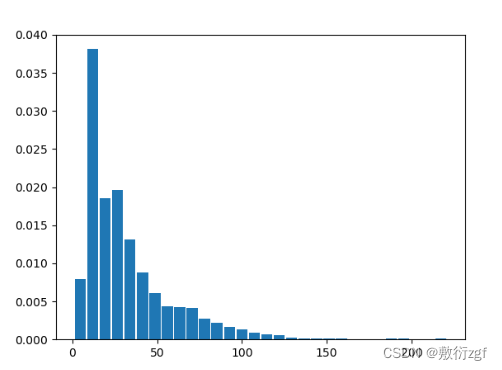
数据样本长度基本上在100以内,此时在BERT模型中可以设置样本最大长度为128.
4.划分的训练集与测试集示例
训练集

测试集

四、模型训练
1.定义配置文件以及超参数
# 定义超参数和配置文件
class_nums = 13
maxlen = 128
batch_size = 32
config_path = './chinese_rbt3_L-3_H-768_A-12/bert_config_rbt3.json'
checkpoint_path = './chinese_rbt3_L-3_H-768_A-12/bert_model.ckpt'
dict_path = './chinese_rbt3_L-3_H-768_A-12/vocab.txt'
tokenizer = Tokenizer(dict_path)
2.定义数据生成器,将样本传递到模型中
# 定义数据生成器 将数据传递到模型中
class data_generator(DataGenerator) :
"""
数据生成器
"""
def __iter__(self , random = False):
batch_token_ids , batch_segment_ids , batch_labels = [] , [] , [] # 对于每一个batchsize的训练,包括 token 分隔符segment 标签label三者的序列
for is_end, (text , label ) in self.sample(random):
token_ids , segments_ids = tokenizer.encode(text , maxlen=maxlen) # [1,3,2,5,9,12,243,0,0,0] 编码token和分隔符segment序列,按照最大长度进行padding
batch_token_ids.append(token_ids)
batch_segment_ids.append(segments_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end :
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids =sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids , batch_segment_ids] ,batch_labels
batch_token_ids,batch_segment_ids,batch_labels = [],[],[]
3.程序入口
if __name__ == '__main__':
# 加载数据集
train_data = load_data('./dataset/train.csv')
test_data = load_data('./dataset/test.csv')
# 转换数据集
train_generator = data_generator(train_data,batch_size)
test_generator = data_generator(test_data,batch_size)
model = build_bert_model(config_path, checkpoint_path ,class_nums)
print(model.summary())
model.compile(
loss='sparse_categorical_crossentropy', # 离散值损失函数 交叉熵损失
optimizer=Adam(5e-6),
metrics=['accuracy']
)
earlystop = keras.callbacks.EarlyStopping(
monitor='var_loss',
patience= 3,
verbose=2,
mode='min'
)
bast_model_filepath = './chinese_L-12_H-768_A-12/best_model.weights'
checkpoint = keras.callbacks.ModelCheckpoint(
bast_model_filepath ,
monitor = 'val_loss',
verbose= 1,
save_best_only=True,
mode='min'
)
model.fit_generator(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=test_generator.forfit(),
validation_steps=len(test_generator),
shuffle=True,
callbacks=[earlystop,checkpoint]
)
model.load_weights(bast_model_filepath)
test_pred = []
test_true = []
for x, y in test_generator:
p = model.predict(x).argmax(axis=1)
test_pred.extend(p)
test_true = test_data[:1].tolist()
print(set(test_true))
print(set(test_pred))
target_names = [line.strip() for line in open('label','r',encoding='utf8')]
print(classification_report(test_true , test_pred ,target_names=target_names))
五、运行
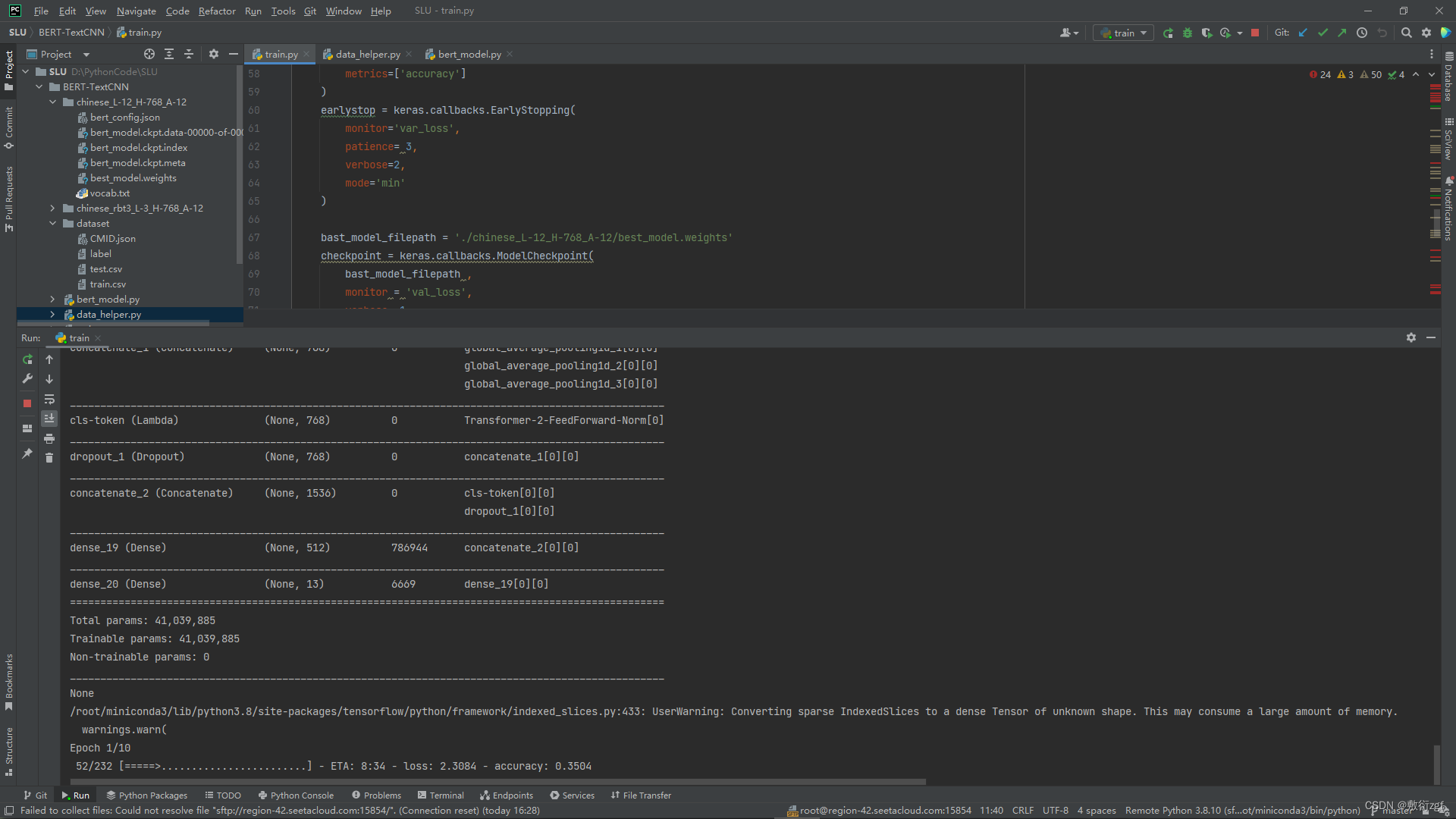
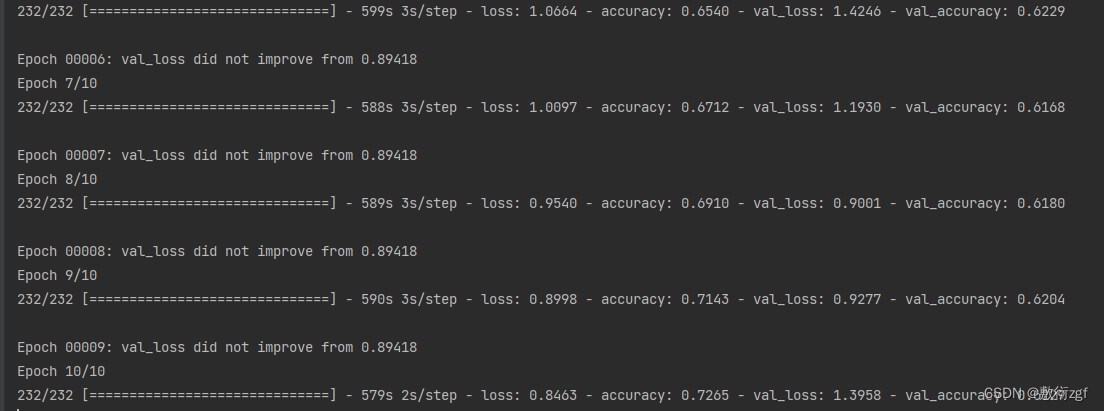
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结