您现在的位置是:首页 >学无止境 >【PyTorch深度学习】利用二维卷积神经网络CNN手写数字识别实战(附源码)网站首页学无止境
【PyTorch深度学习】利用二维卷积神经网络CNN手写数字识别实战(附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
在实际应用中,二维卷积神经网络的使用更加频繁,在图像处理、图像识别等方面,它有着非常广泛的应用,因此读者有必要掌握二维卷积神经网络的构成以及搭建。接下来这一小节,我们将使用PyTorch搭建二维卷积神经网络,用来识别MNIST手写数字数据集,对手写数字进行分类
(1) 数据集的导入和处理
本次实验使用的是MNIST数据集,该数据集是由美国国家标准与技术研究院收集整理的大型手写数据库,可以直接下载,常常用来训练网络,测试网络的准确率。数据集包含了60000个训练集和10000个测试数据集,分为图片和标签,图片是28×28的像素矩阵,标签为0~9共10个数字
首先要导入数据集,数据样本的格式为[data, label],第一个存放数据,第二个存放标签。此处使用torchvision.datasets导入数据集。其中包括设置数据集存放地址root,对数据格式进行调整transform(需要对数据进行归一化处理)。同时由于需要从网络上下载数据集,所以download应该设为True,数据集的下载时间通常比较慢,需要耐心等待。下载完成后,要利用DataLoader对训练集和测试集数据分别进行封装。封装的batch_size = 64,shuffle = True表示将数据进行打乱,num_workers = 0表示不需要多线程工作。具体实现代码如下
(2) 网络搭建
在数据集导入并处理完成后,就开始搭建二维卷积神经网络模型。首先对一些参数进行设定。num_classes = 10表示共有十种类别的数据图像,学习率lr = 0.001,迭代次数epoch = 20,运行设备device选择GPU(cuda)进行网络的测试优化。接着利用PyTorch搭建二维卷积神经网络,还是以继承nn.Module的方式创建ConvModule类。该网络由两层卷积层、两层最大池化层以及三层全连接层堆叠而成,激活函数选择ReLU函数。其中二维卷积函数Conv2d的主要参数如表所示:

其实在搭建卷积神经网络时,很多公式、函数等都是PyTorch打包封装好的,需要时直接调用就可以,非常容易上手。不过需要特别注意的是函数数据输入输出维度的确定,必须要确保数据维度在网络各个层次的变化与函数输入输出一致,这样模型才能正常运行,否则将会报错。关于维度的变化,建议亲自推导,这样将会加深对于卷积神经网络数据输入与输出维度的理解。另外,网络的损失函数选择了交叉熵损失函数,优化器选择了Adam优化,具体代码实现如下所示:
模型搭建完成以后,要定义训练函数和测试函数。两个函数的构成相差不大,均是使用for循环对data_loader的每个batch进行遍历,然后运行网络,记录每次迭代的损失,最后返回整个过程的平均损失和模型准确率。需要注意的是在训练函数中,要把网络指定为训练模式,每次更新参数前需要对梯度进行归零和初始化;在测试函数中则需要把网络指定为eval模式,测试时使用的参数时经过训练优化得到的,所以无需对权重和偏置求导,即卷积神经网络在with torch.no_grad的环境下运行。
(3) 模型训练
定义好训练和测试函数以后,就可以进行网络模型的训练了,首先分别创建了train_loss、train_acc、test_loss、test_acc四个列表,用于存储每一次迭代的Loss以及Acc,便于后面可视化展示。紧接着使用for循环进行训练迭代,每次迭代完都输出模型的损失以及准确率
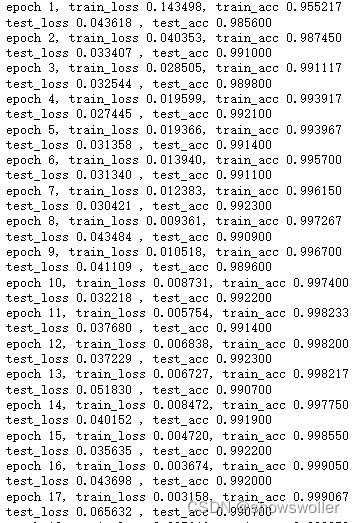
训练结果如下 包含损失值和精确值的变化
(4) 网络损失、准确率的可视化
在收到每次迭代返回的损失以及准确率以后,使用matplotlab库画出训练和测试时的损失曲线及准确率曲线,并且将曲线图像分别存储为’Loss.jpg’、’Acc.jpg’的jpg图片。具体代码实现如下

(5) 模型评估
网络经过20次迭代以后,训练集和测试集的损失由原来的0.31和0.18降到了0.04和0.10,准确率都达到98%,表明网络模型的训练效果非常可观,分类效果非常准确
(6)代码
最后 部分代码如下
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from PIL import Image
import torchvision
impor进行归一化处理,由于MINIST是一维的灰度图数据,所以mean和std只有一维
# Normalized_image = (image - mean) / std
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5])])
train_dataset = torchvision.datasets.MNIST(root="./Datasets/MNIST", train=True,
transform=transform, download=False)
test_dataset = torchvision.datasets.MNIST(root="./Datasets/MNIST", train=False,
transform=transform, download=False)
batch_size = 64
train_loader = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_wor
# pytorch封装卷积层
class ConvModule(nn.Module):
def __init__(self):
super(ConvModule, self).__init__()
# 定义两层卷积层:
self.conv2d = nn.Sequential(
# 第一层 input_size = (1,28,28)
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(inplace=True), # inplace表示是否进行覆盖计算
# 第二层
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(inplace=True),
)fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv2d(x)
# 将数据平整成一维
out = out.view(-1, 64 * 7 * 7)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.relu(out)
out = self.fc3(out)
return out
net = ConvModule().to(device)
criterion = nn.CrossEntropyLoss()
in() # 指定当前为训练模式
train_batch_num = len(data_loader) # 记录共有多少个epoch
total_loss = 0 # 记录LOSS
correct = 0 # 记录共有多少个样本被正确分类
sample_num = 0 # 记录样本数
# 遍历每个batch进行训练
for batch_id, (inputs, labels) in enumerate(data_loader):
# 将每个图片放入指定的device中
inputs = inputs.to(device).float()
# 将图片标签放入指定的device中
labels = labels.to(device).long()
# 梯度清零
optimizer.zero_grad()
#ss.backward()
optimizer.step()
# 累加loss
total_loss += loss.item()
# 找出每个样本值的最大idx,即代表预测此图片属于哪个类别
prediction = torch.argmax(output, 1)
# 统计预测正确的类别数量
correct += (prediction == labels).sum().item()
# 累加当前样本总数
sample_num += len(prediction)
# 计算平均loss和准确率
loss = total_loss / train_batch_num
acc = correct / sample_num
return loss, acc
def test_epoch(net, data_loader, device):
netle_num = 0
# 指定不进行梯度变化:
with torch.no_grad():
for batch_idx, (data, target) in enumerate(data_loader):
data = data.to(device).float()
target = target.to(device).long()
output = net(data)
loss = criterion(output, target)
total_loss += loss.item()
prediction = torch.argmax(output, 1)
correct += (prediction == target).sum().item()
sample_num += len(prediction)
loss = total_loss / test_batch_num
acc = correct / sample_num
return loss, acc
ss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
# 进行训练
for epoch in range(epochs):
train_loss, train_acc = train_epoch(net, data_loader=train_loader, device=device)
test_loss, test_acc = test_epoch(net, data_loader=test_loader, device=device)
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
test_loss_list.append(test_loss)
test_acc_list.append(test_acc)
print('epoch %d, train_loss %.6f, train_acc %.6f' % (epoch + 1, train_loss, train_acc))
print('test_loss %.6f , test_acc %.6f' % (test_loss, test_acc)) x = np.linspace(0, len(train_loss_list), len(train_loss_list))
plt.plot(x, train_loss_list, label="train_loss", linewidth=1.5)
plt.plot(x, test_loss_list, label="test_loss", linewidth=1.5)
plt.xlabel("epoch")
plt.
x = np.linspace(0, len(train_acc_list), len(train_acc_list))
plt.plot(x, train_acc_list, label="train_acc", linewidth=1.5)
plt.plot(x, test_acc_list, label="test_acc", linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
plt.savefig("Acc.jpg")
创作不易 觉得有帮助请点赞关注收藏~~~






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结