您现在的位置是:首页 >其他 >数据结构——链表网站首页其他
数据结构——链表
前言
链表是一种基础的线形数据结构,但是其与顺序表有着较大的差别。但是由于链表与顺序表均为线形结构,本篇将穿插对比分析它们在部分性能上的优劣性。建议萌新先学习顺序表,再来看链表。
【结构体解析】传送门:http://t.csdn.cn/iawZx。
【顺序表解析】传送门:http://t.csdn.cn/TZ5mw。
1 链表的基本思路
1.1 思路引入

相信大家一定都会串珠子,当我们有一根线和若干珠子的时候,我们可以把珠子一个一个地串到线上,这样就形成了一条链子。当被串成链子后,珠子就不会分散很,更加方便我们管理。这是一个简单的生活技巧。
1.2 基本思路
链表的思路其实就是参考了串珠子。如果我们把每一个数据存储在一个珠子里,再用某种方式将这些珠子串起来,不就形成一条链子了吗?这就是数据结构中的链表的基本思路。
在链表中,我们通常把这些存储数据的珠子称为节点。那么我们要怎么样将这些珠子串在一起呢?C语言的结构体提供了一种用法,叫做结构体的自引用。我们可以在结构体中声明一个与该结构体同类的指针,这样一来我们就可以通过在一个节点中保存下一个节点的地址的方式来将这些节点串在一起。
下面为代码和图片演示,这是一个节点的声明,这类节点中包含一个整型变量data和一个指针next,那么在该类节点中,每个节点可以存放一个整型数据和一个节点地址,通过地址又可以找到下一个节点。这样一来,只要我们能找到第一个节点,就能访问链表中任何一个节点。由于数据量是有限的,因此链表也不可能无限长,我们一般将链表中最后一个节点置空(防止越界访问)。
struct SListNode
{
int data;
struct SListNode* next;
};
1.3 注意事项
在我们的想象中,链表是一种线形结构,每个节点都被我们通过指针串在一起。但实际上,在内存当中,链表的各个节点的地址并不一定是连续的,而大概率是分散的。这里需要理解,我们是通过在节点中保存下一个节点的地址,再通过地址来找到下一个节点,而不是将所有节点移动到一块连续的空间。
这是与顺序表不同的地方。顺序表的数据是存储在一块连续的内存空间上的。
2 单链表
单链表,即单向链表。单向链表顾名思义,就是只有一个方向,也就是说只能通过前一个节点找到后一个节点,而不能从后一个节点找到前一个节点。
由于静态版数据结构在大部分场景下应用价值不大,本篇主要介绍动态版链表。
大部分链表OJ题都采用这种链表结构,如图(图中一个圆圈表示一个节点,圈内数字表示该节点所储存的数据,箭头表示节点中指向下一个节点的指针)。

2.1 接口
作为一种基础的数据结构,链表的基本功能当然也就是增删查改了。
而链表的基本思路是通过连接节点的方式将数据联系起来,那么我们的增加和删除数据其实要做的就是在合适的位置增加和删除节点。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SListNode;
// 动态申请一个节点
SListNode* BuySListNode(SLTDataType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDataType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDataType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDataType x);
// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDataType x);
// 单链表删除pos位置之后的值
void SListEraseAfter(SListNode* pos);
// 单链表的销毁
void SListDestroy(SListNode* plist); 2.2 创建新节点
通过前面的分析我们知道,当我们需要向链表中插入一个数据时,首先要创建一个新的节点,将数据存入该节点之中,然后再将该节点插入合适的位置。根据我们在顺序表中运用的函数复用的思想,由于我们在头插,尾插以及随机位置插入时都需要创建新的节点,因此我们可以直接将这个功能封装成一个函数。
这个功能与顺序表的容量检查较为类似,都是为了插入数据而开辟新的空间。但是需要注意,由于链表通过指针来链接,不能简单地通过realloc来实现扩容,因此当我们为新节点开辟完空间后,需要将该空间的地址返回,以便插入链表。
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
perror("malloc");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
2.3 插入数据
2.3.1 尾部插入
尾插需要在链表的尾部插入一个数据,那么我们就得先找到链表末尾的节点,并在它的后面插入一个新的节点。
如图将数据x尾插入链表。

而单链表的尾插比较麻烦的一点在于,由于其基本思路是通过前一个节点来找后一个节点,而不是像顺序表那样通过下标来找到尾部,因此我们需要通过遍历链表来找尾部节点。
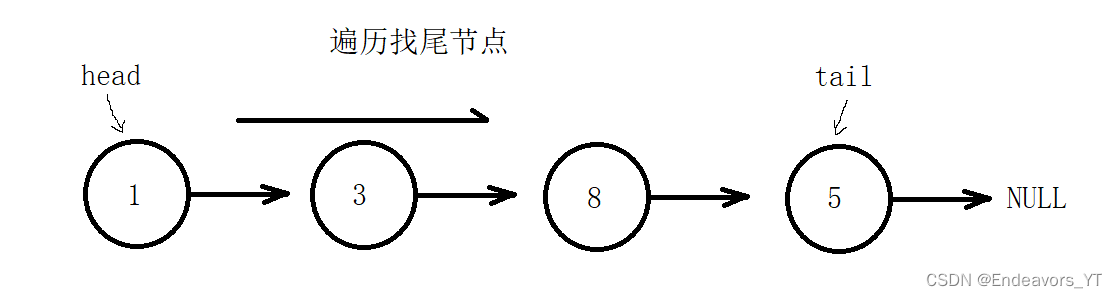
那么首先我们来分析如何通过遍历来找到尾节点。通过画图我们发现,尾节点(图中tail)有一个特点,它的next指针指向NULL,因此我们可以通过这个特点来找到尾节点。当我们拿到头节点(图中head)的地址时,我们可以通过头节点的next指针找到头节点的下一个节点,即图中数据为3的节点。同理,我们又可以通过该节点的next指针找到该节点的下一个节点......如此便形成了循环,我们就可以通过循环来执行该过程。如下方代码。
void SListPushBack(SListNode* plist, SLTDataType x)
{
assert(plist);
SListNode* newnode = BuySListNode(x);
SListNode* tail = plist;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}定义一个名为tail的指针用来找尾节点。首先将链表头结点的地址赋给tail,然后我们来看循环找尾节点。循环的条件是"tail->next",也就是说当tail指针指向的节点的下一个节点为空指针时,循环结束,否则进入循环,循环体内将tail->next赋值给tail,这个过程其实就是使tail指针指向后一个节点,如下图。
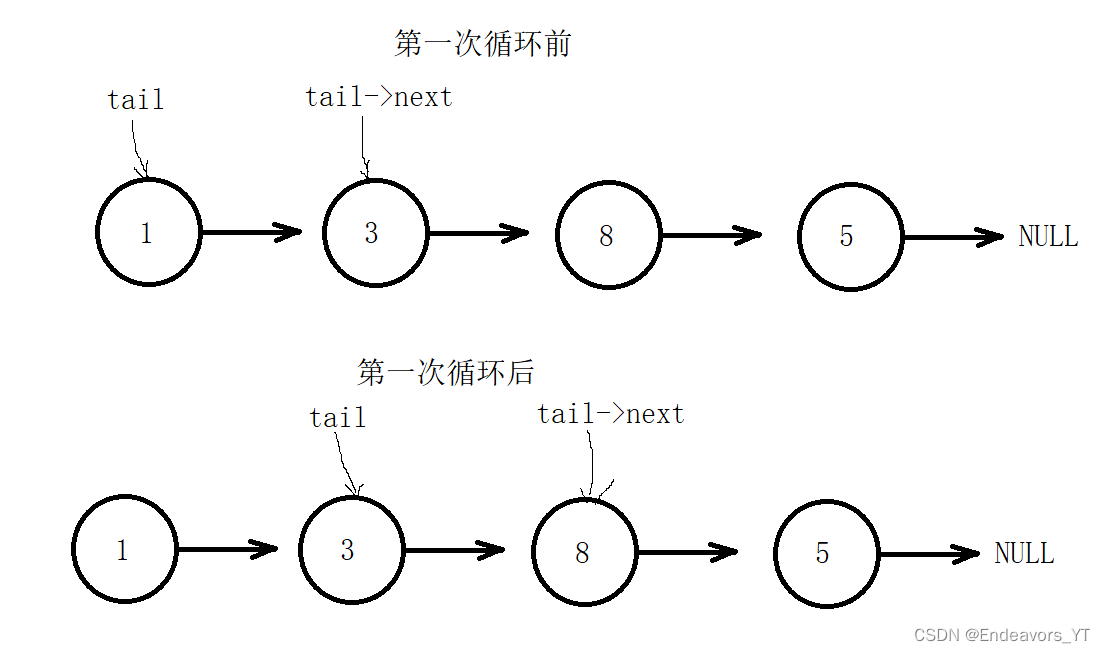
通过循环找到尾节点后,我们将创建好的新节点的地址赋给尾节点的next指针,就完成了尾插。
这就是单链表尾插一般情况的思路,但是相信大家都发现了,上面这个函数的参数与接口中声明的有所不同。在接口中,我们声明了一个SListNode**的二级指针,而这里只有一级指针,这是为什么呢?这里有一种特殊情况,当传入的链表为空链表时,即链表中没有一个节点时,tail指针的初始值就为空指针,我们访问tail->next就会出错。
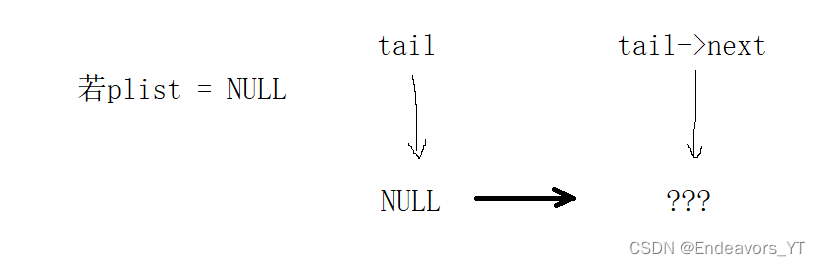
因此我们可以对这种情况单独讨论。当传入的链表为空链表时,直接将创建一个新节点并将新节点的地址作为链表的头节点即可。若不为空链表,则按照我们刚刚分析的方法来做。
由于这个操作会改变链表头节点的地址(从NULL变为新节点的地址),因此我们可以采用返回值的方式或者传址调用的方式来实现。由于需要改变的值是“ SListNode* ”类型的指针,因此采用传址调用时需要传入“ SListNode** ”类型的指针。
具体实现如下。
void SListPushBack(SListNode** pplist, SLTDataType x)
{
assert(pplist);
SListNode* newnode = BuySListNode(x);
if (*pplist == NULL)
{
*pplist = newnode;
}
else
{
SListNode* tail = *pplist;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}2.3.2 头部插入
有了尾插的经验,单链表的头插其实非常简单,只需要创建一个新的节点,再将原链表接在新节点的后面即可。
需要注意,头插之后链表的头节点也发生了改变,这类似于尾插的特殊情况,因此同样可以采用传入二级指针的方式来实现。
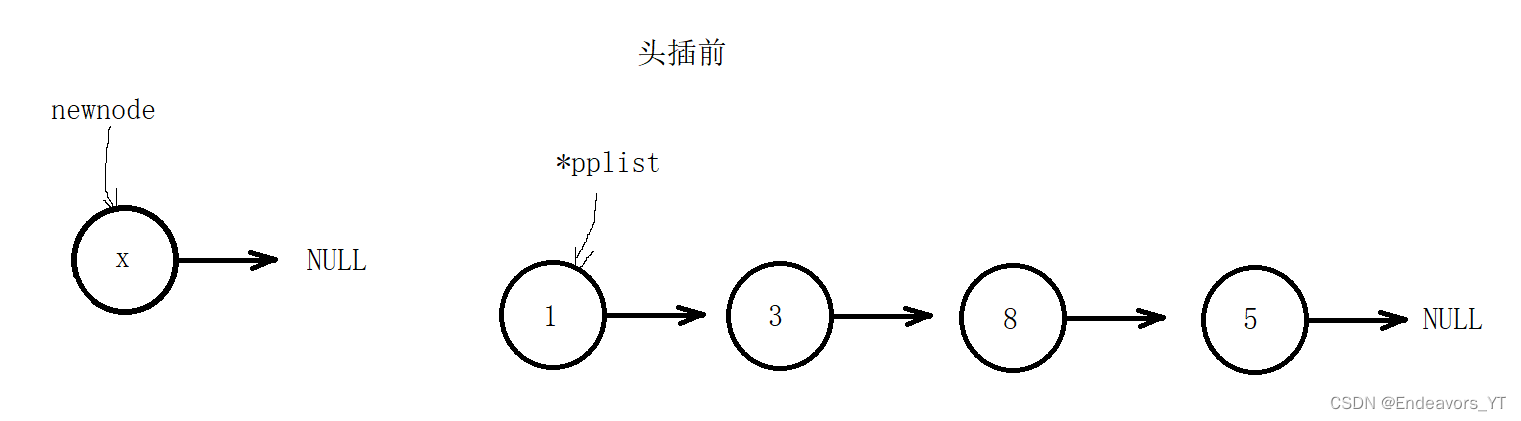

头插实现起来也非常简单,将链表头节点的地址赋给新节点的next指针,再将新节点作为新的头节点即可。
代码实现如下。
void SListPushFront(SListNode** pplist, SLTDataType x)
{
assert(pplist);
SListNode* newnode = BuySListNode(x);
newnode->next = *pplist;
*pplist = newnode;
}2.3.3 随机位置插入
随机位置插入即在所给定的随机位置插入,这个位置通常根据实际需求,运用相应的查找算法得出。
在顺序表中,我们通过下标的方式来找到插入位置,而在链表中,我们通常直接通过节点的地址来找到插入位置。
在进行插入时,又存在两种方式,一种是插入在给定位置之前,另一种是插入在给定位置之后,如下图。
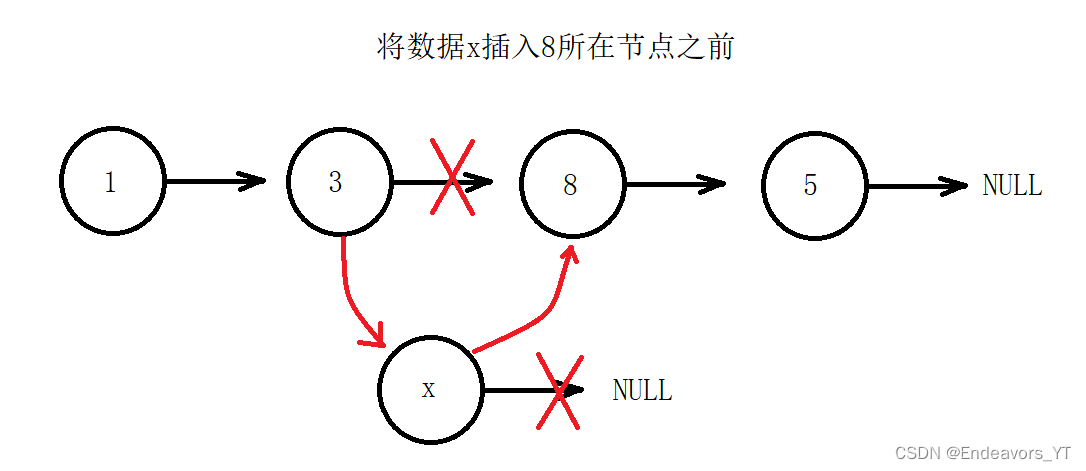
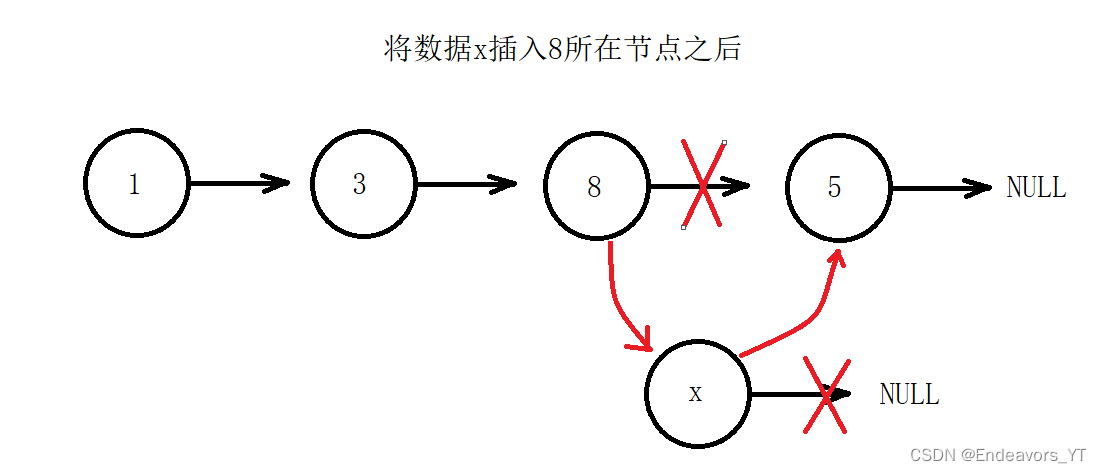
这是两种不同的随机插入思路,它们实现起来也是不同的。
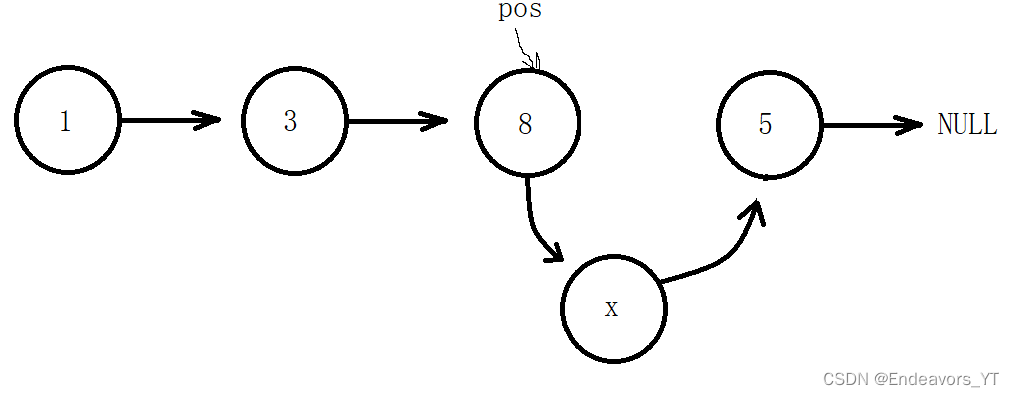
这里我介绍后者。如上图,我们需要将x插入8之后,也就是插入8和5之间。前提条件是我们已经获取到8所在节点的地址,假设为pos。
首先,我们通过8所在节点的next指针找到5所在节点,那么5所在节点的地址即为“ pos->next ”。我们将这个地址赋值给x节点的next指针,即将5节点接在x节点后面,如图。
然后,我们再将8节点的next指针重新赋值为x节点的地址,也就是将8节点与5节点断开,再将x节点接在8节点后面。这样一来就插入完成了。
在已经确定插入位置的前提下,随机位置插入并不难,但是需要注意,上述步骤的顺序最好不要交换,若先连接8节点和x节点则会造成5节点的地址丢失。
代码如下。
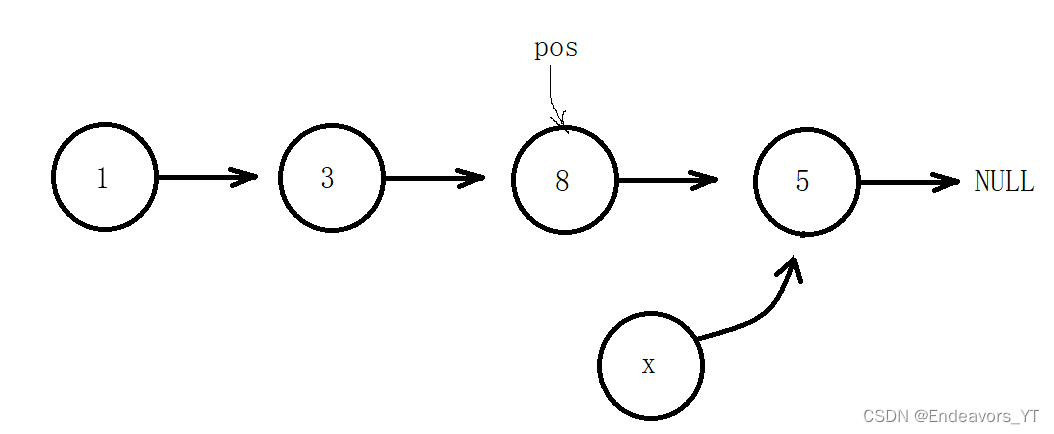
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}2.4 删除数据
2.4.1 尾部删除
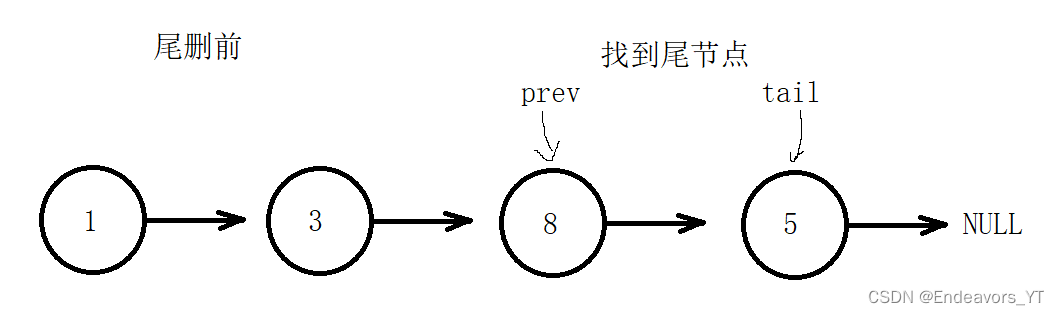
有了之前尾插的经验,我们已经了解了如何找到尾节点。那么当我们找到了尾节点后,我们只需要将尾节点删除,再将尾节点的前一个节点的next指针置空即可。
删除尾节点很简单,一个free函数就可以解决,但是由于单链表的单向性,当我们找到尾节点后,没法通过尾节点再重新找到尾节点的前一个节点。
这里我们可以采用双指针的方式,用一个名为tail指针的指针来找尾节点,另一个名为prev的指针始终保持在tail指针所指向的节点的前一个节点。这样一来,当tail指针找到尾节点时,prev指针自然就指向尾节点的前一个节点,我们再将prev指向的节点的next指针置空就可以了。
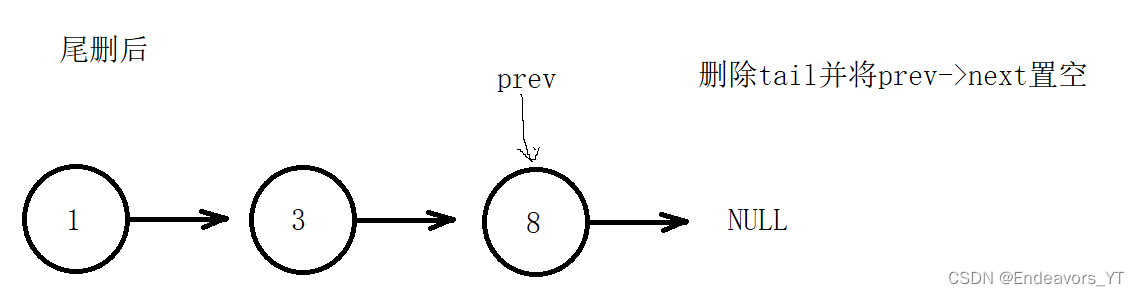
当然,在尾删时也有一种特殊情况,当链表只有一个节点时,第一个节点即为最后一个节点,也就没有所谓的前一个节点了。在这种情况下我们直接将该节点用free函数释放,再将链表的地址置空即可。代码如下。
void SListPopBack(SListNode** pplist)
{
assert(pplist);
assert(*pplist);
SListNode* tail = *pplist;
if (tail->next)
{
SListNode* prev = NULL;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
tail->next = NULL;
free(tail);
prev->next = NULL;
}
else
{
free(tail);
*pplist = NULL;
}
}2.4.2 头部删除
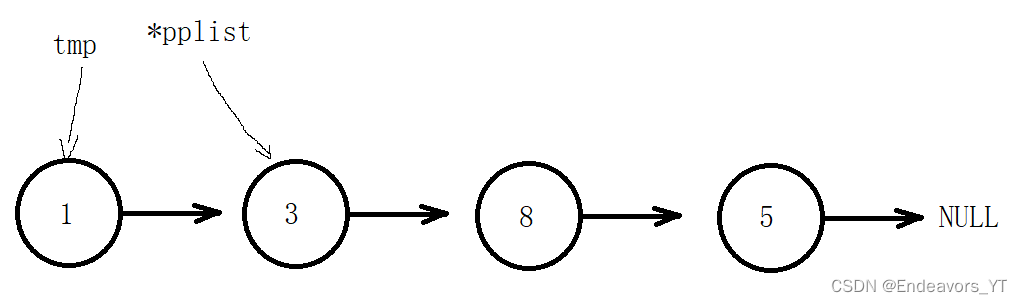
与插入一样,单链表的头删也比尾删简单得多。直接把头节点释放,再将第二个节点作为新的头节点即可。
话是这么说,但可不能一开始就把头节点直接释放了,否则我们就无法找到第二个节点的地址了。因此正确的做法应该是先创建一个临时变量tmp来保存头节点的地址,然后将链表的地址改为第二个指针的地址,最后再free释放tmp即可。

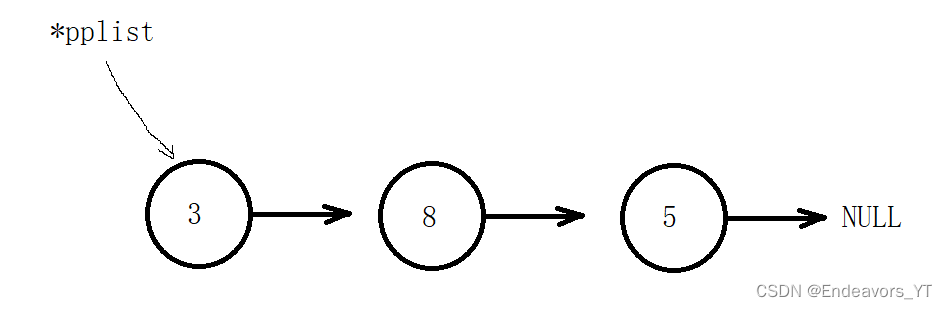
void SListPopFront(SListNode** pplist)
{
assert(pplist);
assert(*pplist);
SListNode* tmp = *pplist;
*pplist = tmp->next;
tmp->next = NULL;
free(tmp);
tmp = NULL;
}2.4.3 随机位置删除
随机位置删除也是建立在已经确定删除位置的基础上,同样可以删除该位置之前的节点或该位置之后的节点。这里介绍后者。
随机位置删除与头删的思路较为类似,也需要借助临时变量来保存地址。
首先,我们创建一个临时变量tmp保存pos位置的下一个节点的地址。
然后将tmp的下一个节点,也就是pos的下下个节点接在pos后面。
最后free释放tmp。
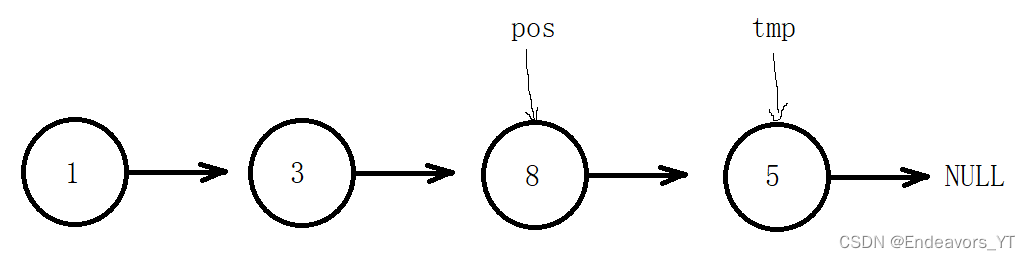
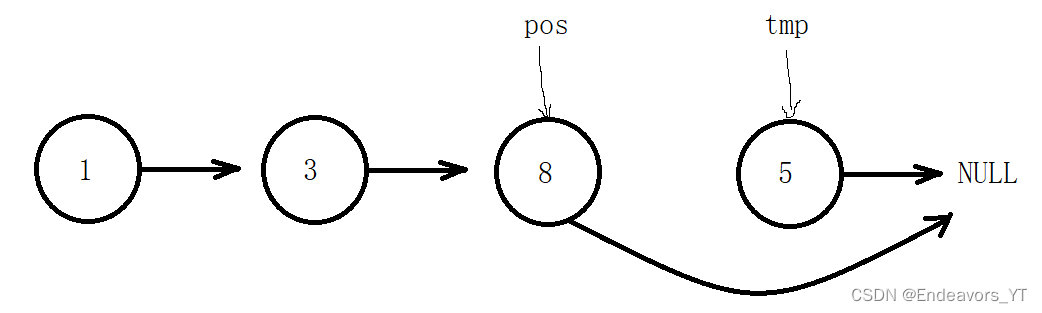
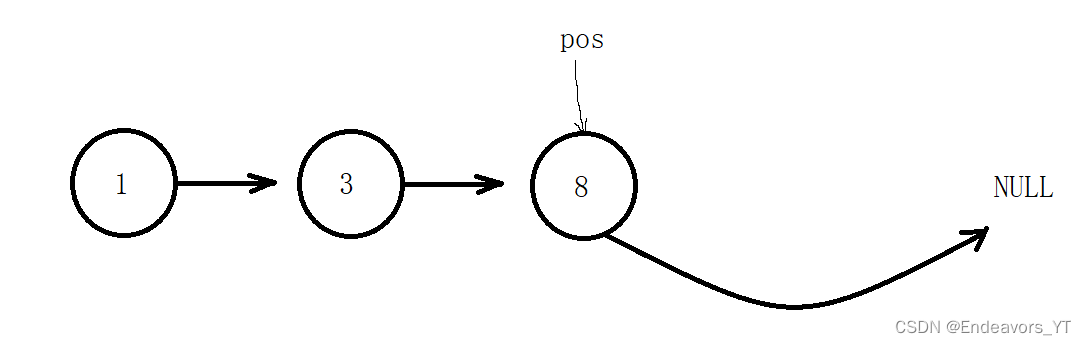
void SListEraseAfter(SListNode* pos)
{
assert(pos && pos->next);
SListNode* tmp = pos->next;
pos->next = tmp->next;
tmp->next = NULL;
free(tmp);
tmp = NULL;
}这里强调一点,只要是动态版链表,在内存堆区上开辟了空间,那么在每次进行删除操作时一定要用free函数释放相应节点,否则可能造成内存泄露。
2.5 销毁
当链表使用完毕后,当然也要进行销毁以防止占用空间。
这里最简单的方式就是采用头删。每次头删能删除一个节点,那么循环进行头删,直到将链表中所有节点都删除,不就完成了链表的销毁吗?因此我就不详细介绍了。
至于为什么不用尾删,大家可以参考头删和尾删的复杂度。
void SListDestroy(SListNode* plist)
{
assert(plist);
SListNode* pnext = plist->next;
while (pnext)
{
plist->next = NULL;
free(plist);
plist = pnext;
pnext = pnext->next;
}
plist->next = NULL;
free(plist);
plist = NULL;
}3 其它功能
3.1 哨兵位头节点
在单链表中,若我们需要进行插入和删除时,要改变头节点的地址,就要采用传入二级指针的方式。如果我们将链表的头节点空出来,不存放有效数据,而将链表的第二个节点作为一号节点,从一号节点开始存放有效数据,那么就可以通过这种头节点来找到链表的有效位置进行插入和删除。
我们将这样的头节点称为哨兵位头节点,如下图guard节点。
 3.2 双向链表
3.2 双向链表
这种链表就是在单链表的基础上给每个节点加上一个指向前一个节点的指针,这样的做法使得我们更方便得找到某个节点的上一个节点,这样一来,我们在进行尾删等操作时就可以不采用双指针的方式来保留尾节点前一个节点的地址了。如下图。

对于双向链表来说,由于它的结构对称,因此它的头和尾是需要人为定义的。
3.3 循环链表(链环)
我们在介绍单链表时提到要将尾节点的next指针置空。若不置空,而将其指向链表中任何一个节点,即在链表中形成一个环形结构。
至于所成的环的结构如何可以根据需求来确定,但如果完全成环,即所有节点均在环中,则需人为定义一个头节点,下图为两种不同的环。
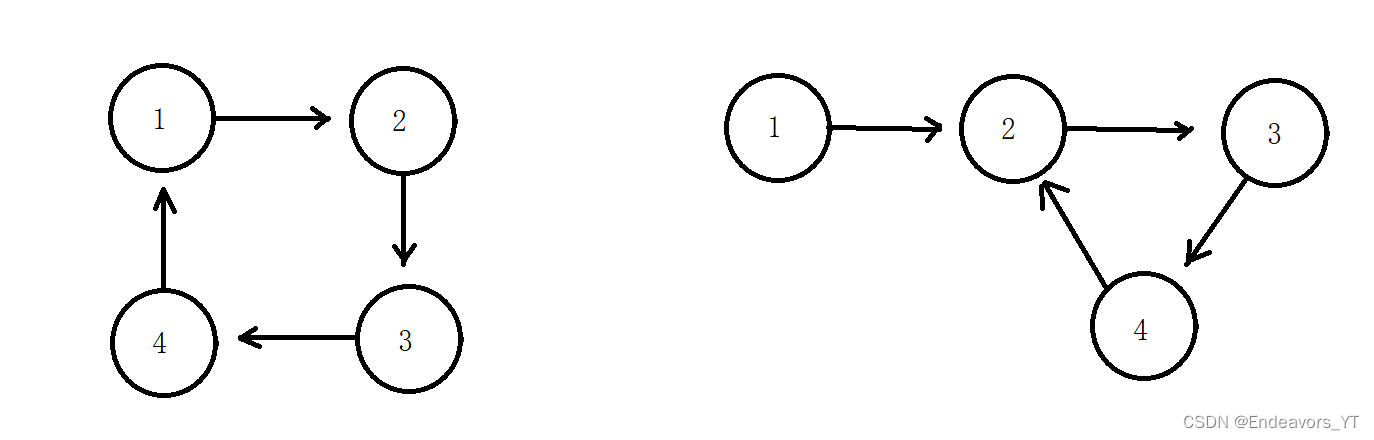
3.4 双向带头循环链表
我们把上面提到的三种结构结合起来,形成了一种我个人认为比较好用的链表结构,如下图。
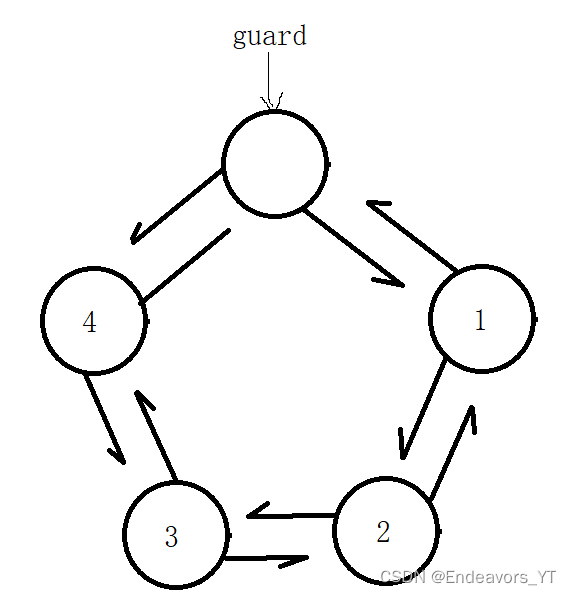
这种结构的好处在于将上述的三种结构的优劣互补,既有确定的头节点,结构又对称,如需进行尾插或者尾删,可以看做反方向的头插或者头删,大大提高了插入和删除的效率。
这个结构的源代码我就不放在文章中了,大家可以通过下方链接进入我的gitee仓库获取。
结束语
链表与顺序表都是基础线形数据结构,它们都有各自适用的场景。希望本文能帮助大家更好地理解链表结构。如果文章中有不正确的地方欢迎各位大佬指出。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结