您现在的位置是:首页 >技术交流 >多模态的过渡态——latent modal网站首页技术交流
多模态的过渡态——latent modal
背景:
随着大模型的推进,单模态的大模型已经无法很好的满足现实工作的需要。很多科研团队和机构开始多模态的研究,多模态的几种机构在前面的文章已经介绍过,这部分不做过多介绍。最理想的多模态应该就是没有模态,单一的模型可以把各种的数据无差别的输入,根据控制需要可以生成出任何想要的输出结果,换句话说就是我们可以用一个模型对齐所有模态之间关系。要实现这样的目标至少是有三种架构:
1.把各种模态输入/输出拉横,分区块设计每个部分对应模态,通过任务设计,让一种输入数据预测输出数据的值,通过足够多数据训练,让模型学习到模态之间对应关系
2.训练时候输入/输出只有一种模态数据,通过训练模型可以学习到模态之间对应关系
3.把各种模态之间映射到一个统一的空间,在统一空间里通过对齐方式拉起模态之间映射关系
前两种架构是一阶段的训练方法,也就是说各种模态之间数据不需要经过映射到latent空间这一步骤。直接的可以对齐到各种模态各种粒度的信息对齐,理论上讲只要有足够多的数据,一阶段的模型表达能力是更强大。但因为数据收集难度、数据处理难度、训练代价、以及下游任务的推理算力需求。现在主流的多模态应该是两阶段的对齐训练架构。即:
1.先单独把每个模态数据映射到一个空间
2.然后通过多个模态数据对齐任务设计让模态对齐
但是在模态对齐过程中任务的设计又可以根据:是否考虑数据序列、训练任务难易度、训练任务通用度做更细粒度划分。不同任务设计下产出模型表现力也会有较大差异。
下面介绍的三个模型:clip、blip2、mini-chatgpt4差异如下:
1.clip:训练数据基本没有考虑数据之间序列、任务设计图文做相似的计算
2.blip2:训练数据基本没有考虑序列,任务设计:相似的计算、模态交融任务设计、VQA、图到文本生成
3.mini-chatgpt4:有考虑数据序列(单图多轮对话),图多轮对话式生成
过度态模型:
clip
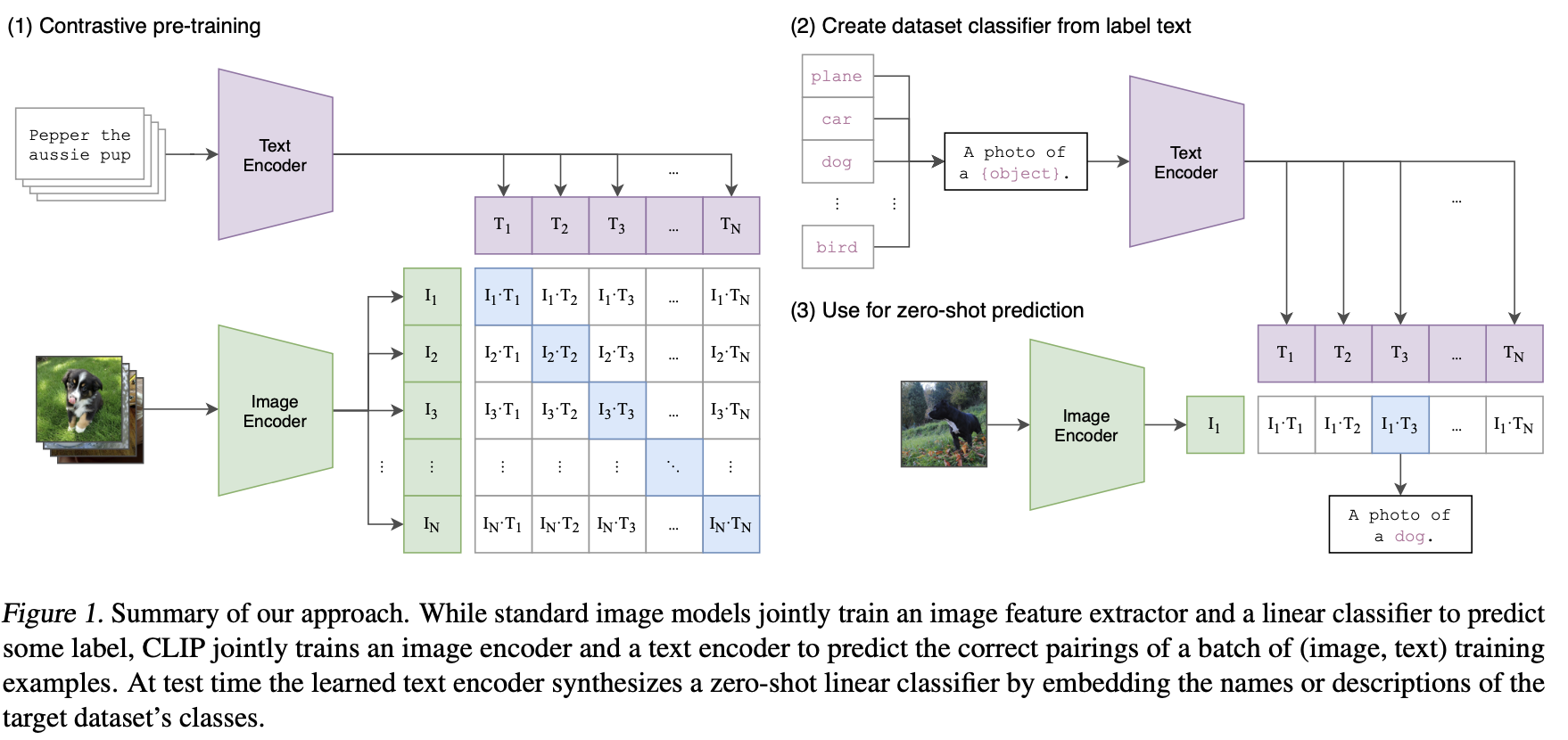
CLIP(Contrastive Language-Image Pre-Training)是一种基于(图像,文本)对的训练神经网络。它可以以自然语言指令为目标,根据给定的图像预测最相关的文本片段,拥有类似于GPT-2和3的零样本预测能力。CLIP在ImageNet“零样本”任务上与原始的ResNet50表现相同,而预测样本可以不在训练的原始1.28亿标记数据中中。
CLIP的训练任务包括:1.图文对相似度计算 2.给定图embbeding,通过文本指令预测图中物体类别。训练数据:网络爬取整理的400M的图文对,通过弱监督(应该是有多轮boost)。50万次互联网query,每次query召回2万条数据,图embedding尝试了:resnet、VIT两种架构抽取,文本embedding采用:63M参数12层 512输入长度 8 个attention头的transformer的Masked self-attention来抽取。数据量、转成prompt的图文分类对zeroshot表现和图文信息对齐,信息表征能力有较大提升。(任务设计、数据选择应该很重要)
blip2
大规模模型的端到端训练,视觉和语言前训练的成本已经变得越来越高昂。BLIP-2为了解决大模型训练贵的问题,提出一种通用且高效的前训练策略,可以从现有的 frozen 预训练图像编码器和 frozen 大型语言模型中Bootstrap 视觉和语言前训练。BLIP-2通过轻量级查询Transformer bridge了modality gap,该Transformer 在两个阶段前训练。第一阶段从 frozen 图像编码器中 Boot-strap 视觉语言表示学习。第二阶段从 frozen 语言模型中Bootstrap 视觉到语言生成学习。BLIP-2在各种视觉语言任务中实现了最先进的性能,尽管训练参数数量比现有方法要少得多。
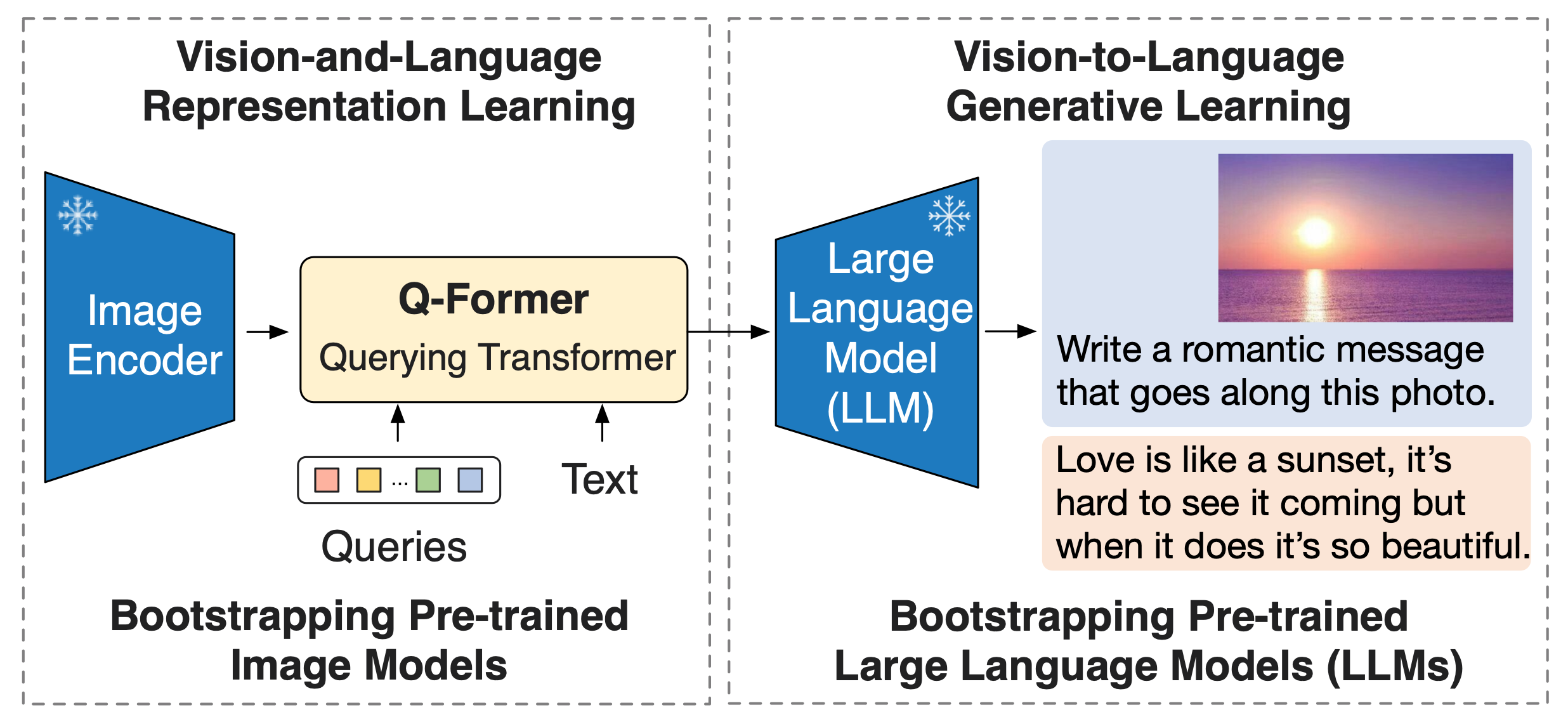
BLIP-2框架的概述。采用两阶段策略来预处理一个轻量级的查询Transformer,以解决两模态差异。第一阶段从冻结的图像编码器中Bootstrap视觉语言表示学习。第二阶段从冻结的LLM中Bootstrap视觉到语言生成学习,这可以实现zero-shot的图像到文本生成。

固定视觉预训练模型,通过三个任务来训练一个 Q-Former 将图像输入中的语义编码到一个和文本特征空间相似的特征空间中。具体来讲,模型基于 K 个可学习的 query 嵌入和 cross-attention 机制从图像中获取特征,三个任务包括:
1. 图文匹配:对输入的(图像,文本)二元组分类,判断其是否相关
2. 基于图像的文本生成:给定图像输入,生成对应的文本描述
3. 图文对比学习:拉近图像特征和对应文本特征的距离,增大其和无关文本特征的距离

将 Q-Former 的输出通过一个全联接网络输入给固定的大语言模型,通过【基于图像的文本生成】任务将与文本特征进行了初步对齐的视觉特征进一步编码为大语言模型可以理解的输入。
优点:
通过固定单模态的预训练模型,BLIP-2 大大减少了预训练所需的计算和数据资源。
仅用了 129M 的图文对,一台 16-A100(40G) 机器不足 9 天可以训练完最大规模的 BLIP-2
通过固定大语言模型的参数,BLIP-2 保留了大语言模型的 Instruction Following 能力。
缺点:
模型没有多模态的 In-Context-Learning 能力
minichatgpt4
blip2可以看出两阶段的训练方式,第一阶段是对图文表征能力学习,第二阶段是把图文embedding作为soft prompt来做prefix的文案生成。比clip只学习图文表征能力更进一步,通过生成的prompt指导文本生成方式来更好对齐图文在映射空间表达。
MiniGPT-4 的目标是将一个训练好的视觉编码器和先进的大型语言模型 (LLM) 对齐,使用 Vicuna 作为语言解码器,它基于 LLaMA构建,能够执行各种复杂的语言任务。对于视觉感知,我们使用与 BLIP-2 相同的视觉编码器,并将其训练的 Q 前体相结合。语言和视觉模型都是开源的。使用线性投影层,通过一个设计的对话模板,用一条路径将视觉编码器和 LLM 对齐。提出了一种两阶段的训练方法。
1.初始阶段涉及在大量的对齐图像文本对上预训练模型,以获取视觉-语言知识。
2.第二阶段,使用一个较小的但高质量的图像文本dataset,并使用设计的对话模板微调预训练模型,以提高模型的生成可靠性和可用性。

第一段预训练阶段
在第一段预训练阶段,设计任务让模型从 aligned image-text pairs 中获取视觉语言知识。利用注入的投影层的输出作为 LLM 的软prompt,促使它生成相应的真实文本。
在整个预训练过程中,两个预训练的视觉编码器和 LLM 都保持冻结,只有线性投影层进行预训练。使用公开的的 Concep- tual Caption , SBU 和 LAION 数据集来训练模型。经历了 20,000 训练步,批量大小为 256,涵盖了大约 5 百万个图像-文本对。使用了 4 块A100 (80GB) GPU,整个过程需要大约 10 小时。问题设计为图文embdding成soft prompt做文本生成:
<Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
在第一段预训练阶段之后, MiniGPT-4 表现出能够拥有丰富知识并对人类问题做出合理回答的能力。但是观察到它有时难以生成连贯的语言学输出,例如生成重复的词语或句子、破碎的句子或无关的内容。这些问题妨碍了 MiniGPT-4 与人类进行流畅的视觉对话的能力。
类似的问题在 GPT-3 中也存在。尽管 GPT-3 在广泛的语言数据集上进行了预训练,但它不能直接生成符合用户意图的语言学输出。通过从人类反馈中学习指令微调和强化学习,GPT-3 逐渐进化为 GPT-3.5,能够生成更加人性化的输出。这种现象与 MiniGPT-4 在第一段预训练阶段之后的状态类似。模型可能会在这一阶段难以生成流畅和自然的语言输出。
为了增强生成语言的自然度和提高模型的可用性,需要进行第二段对齐过程。虽然在 NLP 领域中,指令微调和对话数据集很容易获得,但在视觉语言领域中却没有类似的数据集。为了解决这个问题,需要精心设计一个高质量的图像文本数据集,专门用于对齐。该数据集随后用于第二段对齐过程中,用来MiniGPT-4 进行微调。
初始对齐图像-文本生成。在初始阶段,使用从第一段预训练阶段推导出来的模型生成一个给定图像的详细描述。为了让模型生成更详细的图像描述,设计了一个遵循vicuna 语言模型对话格式的prompt,如下所示:
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
在这个prompt中,表示线性投影层产生的视觉特征。
要识别不完整的句子,需要检查生成句子是否超过了80个词。如果未超过,可以添加另一个提示,###Human: Continue ###Assistant: ,,促使MiniGPT-4继续生成句子。通过将两个步骤的输出合并,可以创建一个更全面的图像描述。这种方法使模型能够生成更多具有详细和 informative 的图像描述。随机选择了5,000张概念标题数据集上的图像,并使用这种方法为每个图像生成相应的语言描述。
数据预处理 生成的图像描述仍然存在许多噪声和包含错误,例如重复单词或句子,以及包含不合理陈述的问题。为了减轻这些问题,使用ChatGPT来通过后续提示来优化描述。
后续处理 完成预处理后,手动检查每个图像描述是否正确,以确保其质量。具体而言,检查每个生成图像描述是否符合想要的格式,并手动优化生成的标题描述,通过删除ChatGPT无法检测的重复单词或句子。最终,只有大约3,500个图像-文本对满足我要求,这些对随后用于第二阶段对齐过程。
3.3 第二段超参数调优
在第二段超参数调优中,我们使用 curated high-quality image-text pairs curated 高质图像文本对进行超参数调优。在超参数调优中,我们使用以下模板中的预定义提示:
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
在 this 提示中, 代表我们随机采样的指令集,其中包含指令的变体,例如“详细描述这个图像”或“能否为我描述这个图像的内容”。重要的是指出,我们不使用该特定文本图像提示的回归损失。
因此,MiniGPT-4 现在能够产生更加自然和可靠的响应。此外,我们观察到模型的超参数调优过程非常高效,只需要 400 步的训练步骤,批量大小为 12,只需要短暂的 7 分钟就能完成 single A100 GPU。
优点:
1.研究表明,通过将冻结的视觉编码器和先进的大型语言模型 Vicuna 对齐,可以实现新兴的视觉-语言能力。
2.通过使用预训练的视觉编码器和大型语言模型,MiniGPT-4 实现了更高的计算效率。研究结果表明,仅训练一个投影层可以有效地将视觉特征与大型语言模型对齐。 MiniGPT-4 仅需要在 4 A100 GPU 上训练大约 10 小时。
3.仅仅使用公开数据集的 raw 图像-文本对将视觉特征与大型语言模型对齐并不能开发出表现良好的 MiniGPT-4 模型。它可能产生缺乏一致性(包括重复和破碎语句)的人造语言输出。解决这个问题需要使用高质量的、对齐良好的数据集,这显著改善了其可用性。
小结:
1.现在多模态多模型文本语言大模型,还是以图文对齐,文本生成为主导,还做不到图文一起生成
2.从clip到blip2到minichatgpt4,统一输入格式、统一任务设计已成为趋势
3.minichatgpt4也未能实现真正的in-context图文生成,只是第一阶段和第二阶段学习任务是一样,输入:图、文做softmax把表征和生成问题统一成生成任务,第二阶段数据格式一样只是有更长序列和更多要求用高质量人类筛选数据做aliment
4.从趋势看图文多模态,任务设计应该兼备输入为:instruct、图、文、content==>输出:图、文、content、annotate;这样方式才能真正做到in-context的图文多模态,解决in-context图文任务,把人类物理世界的时间序列变量引入
5.lantent modal学习后续是否会和raw rext、pixcel粒度数据融合或者说是更细粒度图文特征接入,解决细粒度图文可控性生成是个可以关注方向(当然这么做对训练数训练技巧、训练算力要求会很高)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结