您现在的位置是:首页 >技术教程 >在Transformer模块上用CNN网络搭建方式解决图像分类问题网站首页技术教程
在Transformer模块上用CNN网络搭建方式解决图像分类问题
来源:投稿 作者:摩卡
编辑:学姐
论文标题:DeepViT: Towards Deeper Vision Transformer
Motivation
本文受到传统CNN网络搭建方式的启发(深层的CNN网络可以学习到关于图像更加丰富和复杂的表示), 于是思考是否可以将这种搭建方式迁移到Transformer模块上, 以此搭建深度的Transformer网络结构处理图像分类问题。
但是在搭建过程中发现了一个反常识的问题:
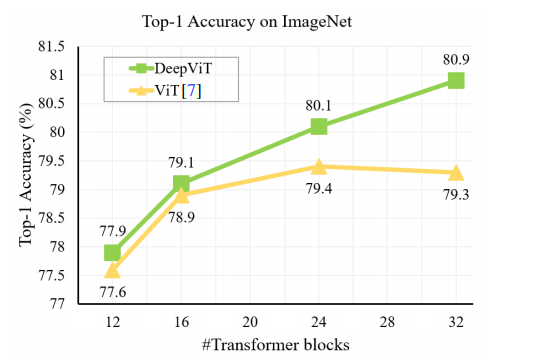
随着Transformer模块堆叠模型的深度变深,按照常理由于注意力模块数量变多模型的性能会相应的提高,但是试验结果表明在基线模型(ViT 2020年提出的纯Transformer模块搭建的图像分类模型)达到一定深度时(24层),模型效果达到最好,此后随着Transformer层数的增加分类效果会下降。
作者将这一现象称为attention collapse!
Analysis
为了研究清楚这一反常识现象,本文作者在基线模型的基础上进行研究,作者对每个Transformer模块与其相近的模块进行余弦相似度的计算(threshold=0.8),如果余弦相似度的值大于threshold,则将这两个相邻Transformer模块的attention map 视为相似。
其结果如下图所示:
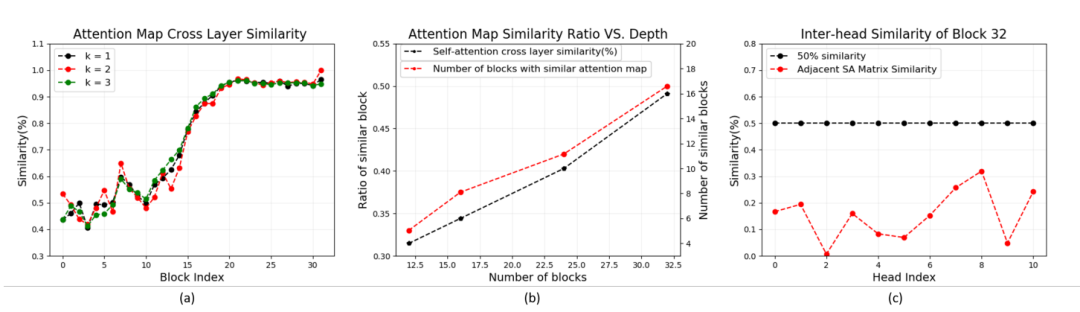
图a表示不同层数的Transformer模块与其邻近的(k=1, 2, 3)三个模块之间的相似度。由图可以看出,随着模型的加深不同Transformer模块的attention map 与其相邻模块的attention map 相似度不断增加。
图b表示不同层数具有相似attention map的Transformer模块占总模块的比例。由图可知,在深度达到32层时,有16个模块具有相似的attention map。
图c表示的是第32层Transformer模块中每个head所捕获的attention map 的相似度(此处的threshold=0.5, 也为余弦相似度),由图可知即使在深度很深的32层Transformer模块中不同head所获取到的attention map 并不相同。
Method
在经过上述分析后,作者提出了两种解决方法:
(1)扩大hidden layer中神经元的个数。
(2)提出了一种re-attention的方法代替self-attention。
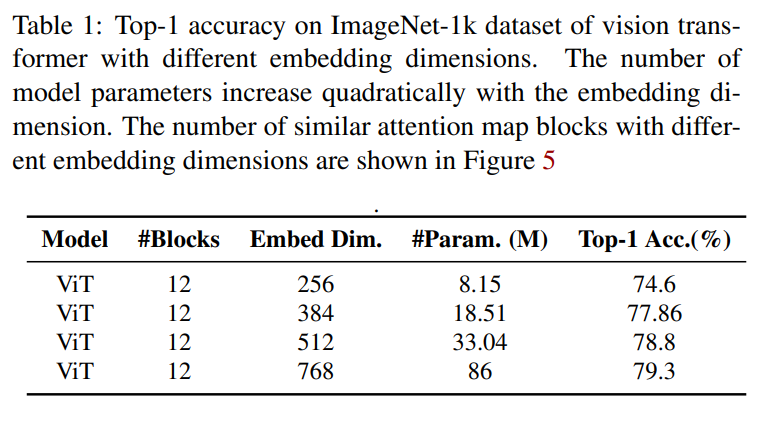
表1表示的是在基线模型上(ViT)12层上扩大hidden layer中神经个数。可以看到随着神经元个数的增加,在ImageNet Top-1Acc也会随之提高。不过该方法会增加计算资源的消耗。
Re-attention
此外在本文中作者还提出了一种解决方法:Re-attention方法。
公式如下:
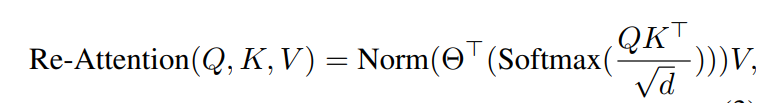
在原有Transformer attention的基础上引入了一个可学习转换矩阵(自己定义的)(H为Transformer模块中多头注意力head的个数)。
其模型图如下:
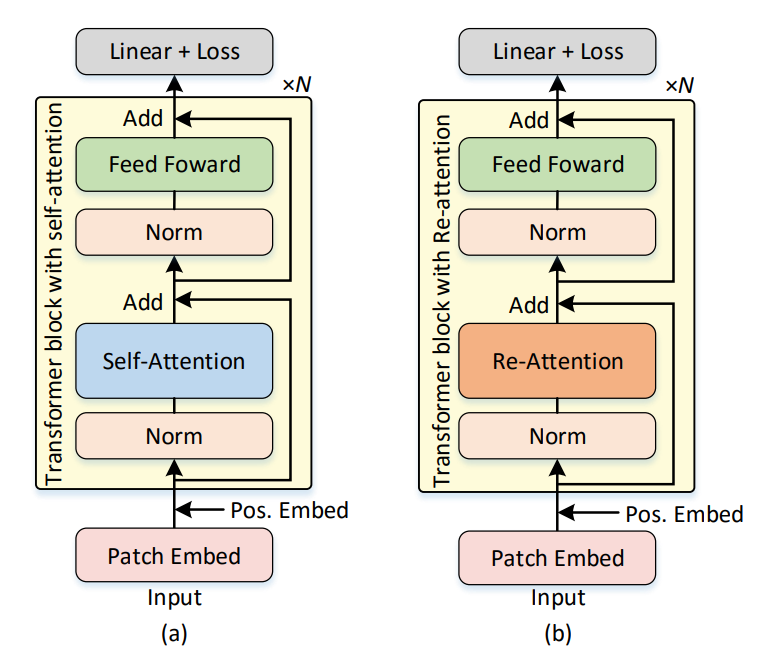
为了验证这一改进有没有效果,作者可视化了改进之后的Feature map(attention map*V)
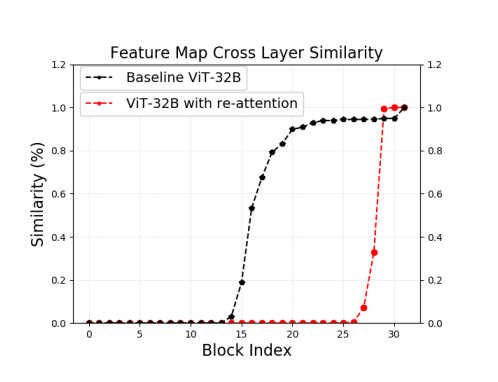
上图表明将self-attention换成re-attention机制后明显的缓解了attention collapse现象。
Result
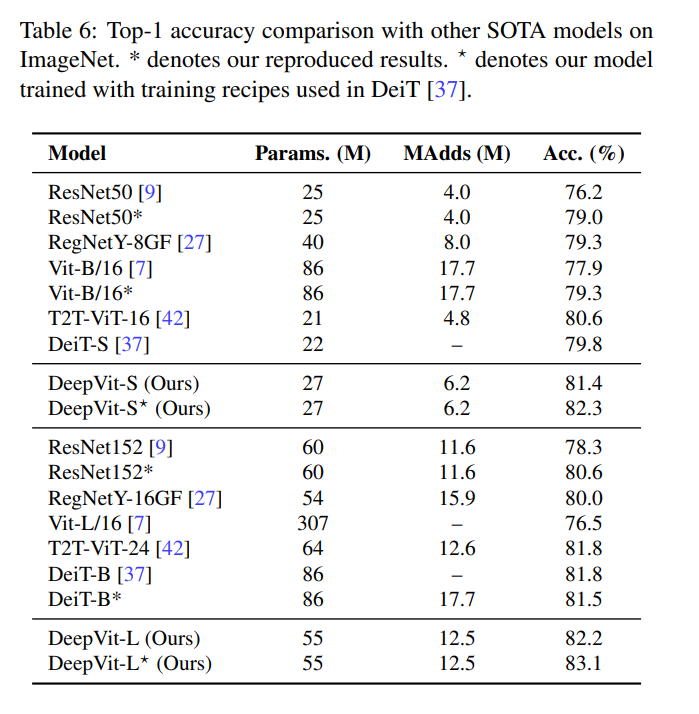
最后与SOTA进行比较,结果如下表所示:
个人体会
个人觉得该论文的亮点主要分为两方面:
(1)对于Transformer模块的细致分析,从发现问题开始将发现的问题定义为attention collapse,然后一步一步对每一层Transformer模块中的attention map/feature map 进行分析,并且还分析了multi-head attention 每个头捕获到的特征(解决了上周的一个小疑问)。
(2)使用re-attention替换multi-head attention中的self-attention。此处的新颖之处是在改变self-attention 结构解决attention collapse问题时只定义了一个可学习参数、使用了LayerNorm, 并没有扩充Transformer占用的内存资源。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“500”获取更多经典高分论文
码字不易,欢迎大家点赞评论收藏!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结