您现在的位置是:首页 >技术教程 >【Linux】文件系统网站首页技术教程
【Linux】文件系统
文章目录
📕 分区、分组
我们知道,磁盘空间是可以通过分区来便于管理的。每个分区的管理方式都是一样的。如下图的左上,将500GB的磁盘分区,第一块区域是 150GB。
但是一个分区的空间还是有些大,于是就要把分区再划分,这就是分组,如图中左下角。每一个分组的管理方法 都是一样的。
如下图的右边,一个分组对应一个 Bloc Group(即分组我们叫做块)。我们学习如何管理磁盘,只需要学习到如何管理一个分组即可。因为一个分组的管理方法知道了,也就知道了一个分区内所有分组的管理方法,那么这个分区的管理方法也就知道,其他分区的管理方法同理。
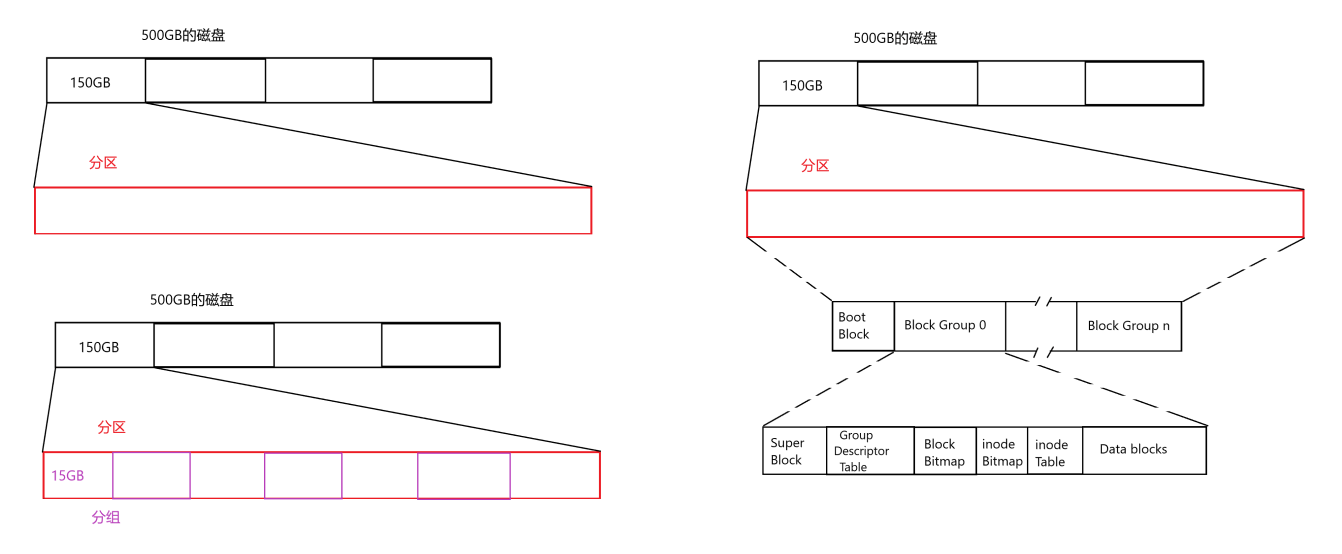
📕 Block Group
分区里面,第一个 Boot Block 块,重点保存和操作系统相关的内容,比如分区表、操作系统镜像的地址等等。如果这一块的数据有误或者丢失,操作系统就很可能启动失败。
Boot Block 是和开机相关的块,其余的 Block Group 就是保存数据的块。
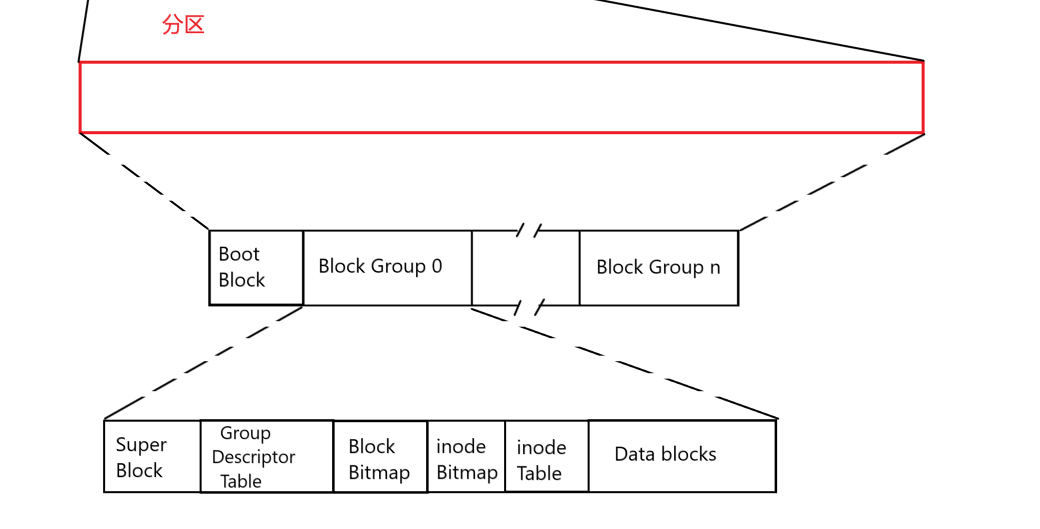
Super Block
这块内容保存的是文件系统的所有属性信息。例如,文件系统的类型、整个分组的情况等等。
可是,这样子整体上的信息,按道理来讲是应该可以和 Boot Block 并列的,将其放在具体的 Block Group 里面,是为了防止 Super Block 坏掉!!
在各个块(Block Group)中都可能存储 Super Block,并且这些 Super Block 里面存储的信息完全一样,并且是统一更新的!就是为了防止 Super Block 区域出现故障,因为其只要故障,那么整个分区都不可以使用。
例如,Block Group 0 这一块的 Super Block 坏掉了,就可以从 Block Group 1 这一块中,拷贝其 Super Block 的数据,放到 Blcok Gruop 0 里面,这就是多副本来保证分区安全的策略!
可是,为什么只把 Super Block 这样存储,不把 Boot Block 也这样存储呢?
假设 Boot Block坏掉了,那么顶多是开不了机,后面 Block Group 里面存储的数据还在。
但如果 Super Blcok 坏掉了,那就是整个分区无法使用,几百G的数据完全用不了,这是绝对不能发生的!
GDT
Group Describtion Table :组描述符 – 该组内的详细统计等等数据信息。
inode Table & Data Block
文件 = 内容+属性。两者是分开存储的。
一般而言,一个文件内部所有的属性集合,都要存储在一个 inode 节点(128字节)里面,一个文件对应一个 inode ,一个 inode 只在一个分区内有效。
一个分区,里面会有大量的文件,即有大量的 inode 节点,一个 分组(Block Group)也有很多的文件,需要有一个区域来专门存放该分组里面的所有文件的 inode 节点。这块区域就是 inode Table(inode 表)。
但是,分组内部既然有多个inode,那必然是要作出区分的,依据就是每个 inode 自己的编号!!这个编号也属于对应文件的属性 id 。
而文件的内容,是变化的,大小不一定。我们使用数据块(Data Block)来对文件的内容进行访存,所以一个文件要保存内容,就需要至少一个 Data Block。一个Data Block 的大小是 4KB。
所以,在一个分组里面,文件的属性是保存在 inode 里面的,文件的内容是保存在 Data Block 里面的。
那么,Linux 环境下要查找一个文件,就是根据 inode 的编号,先找到 inode,拿到文件的属性,根据属性找到文件的数据块是哪些,将这些数据块的内容 加载到内存,那么就可以读取这个文件的内容了!
一个分组里面,绝大部分的空间都是 Data Block。
例如下方是一个 inode 结构体,里面存储了文件的属性,其中 int datablcok[NUM] 就是存储数据块编号的数组,可以根据它来找到当前文件的数据块!
但是, inode 的大小是固定的,128字节,那么 datablock 数组的大小也是有限的,那就只能存储有限的数据。假设数组大小为 16,最多只能存储16个数据块的编号,即 16*4kb 的数据,但是有些文件甚至有好几个 G,这是怎么做到的呢?实际上,是依靠多级索引!
struct inode
{
int inode number;
int ref_count;
mode_t mode;
int uid;
int gid;
int size;
……
int datablock[NUM];
};
inode Bitmap & Block Bitmap
可是,虽然 inode Table 里面有很多的 inode 节点,我们是如何知道哪些 inode 被使用,哪些 inode 没有被使用的呢?这就要依赖于 inode Bitmap ,它是位图的结构,每一个比特位表示一个 inode 是否被使用,1 被使用、0未被使用。
例如, inode Bitmap 假设是一个数据块大小的空间,也就是 4KB,4KB= 4096*8 比特位,即一个数据块有三万多的比特位,也就可以标识三万多个 inode 的使用情况。
同理,我们要知道哪些 Data Block 是否被使用,就要依靠 Block Bitmap。一个比特位标识一个数据块是否被使用。
📕 重新认识目录
上面所说的 inode 编号,使用 ls 指令是可以查看到的,要加一个 " i " 选项。原则上一个文件匹配一个 inode 编号(因为一个inode 对应一个文件,而一个 inode 编号对应一个 inode)。
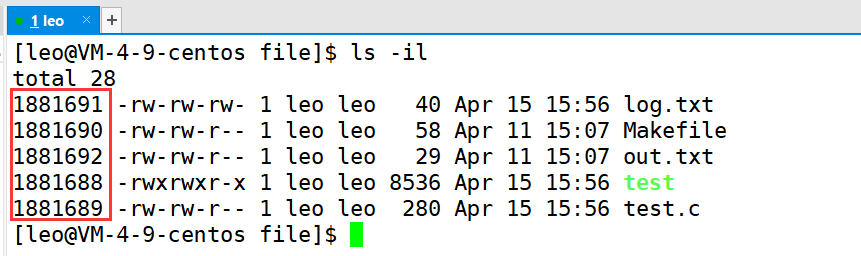
Linux 系统只认 inode 编号,在一个文件的属性里面,是不包含文件名的!!文件名只是给用户使用的。那么如何完成 文件名到 inode 编号的转换,这就依靠目录!!
首先,我们要知道,Linux 下一切皆文件,那么目录也是一个文件!那么目录也有属性和内容!
目录的内容无疑也是存在数据块里面的,目录的 Data Block 实际上存储的就是该目录下,文件名和文件 inode 编号对应的映射关系,在目录内,文件名和 inode 编号互为 key 值。
例如, cat log.txt ,执行这个指令,我们要现在当前目录下,找到 log.txt 的 inode 编号。目录是一个文件,那么就隶属于一个分区,结合目录的 inode ,在分区中找到分组,在该分组中的 inode Table 中,找到 log.txt 的 inode,通过 inode 找到文件的数据块,加载到内存,并输出到显示器!
📕 文件的增删查改
删除
如果我从 U 盘里面拷贝一个 10 GB的电影到自己的电脑上,那么可能需要好一会,但是如果电影看完后,将其删除,那么删除电影是一下子就完成了。这种速度的差异,实际上就是电脑删除文件的方法的一种体现。
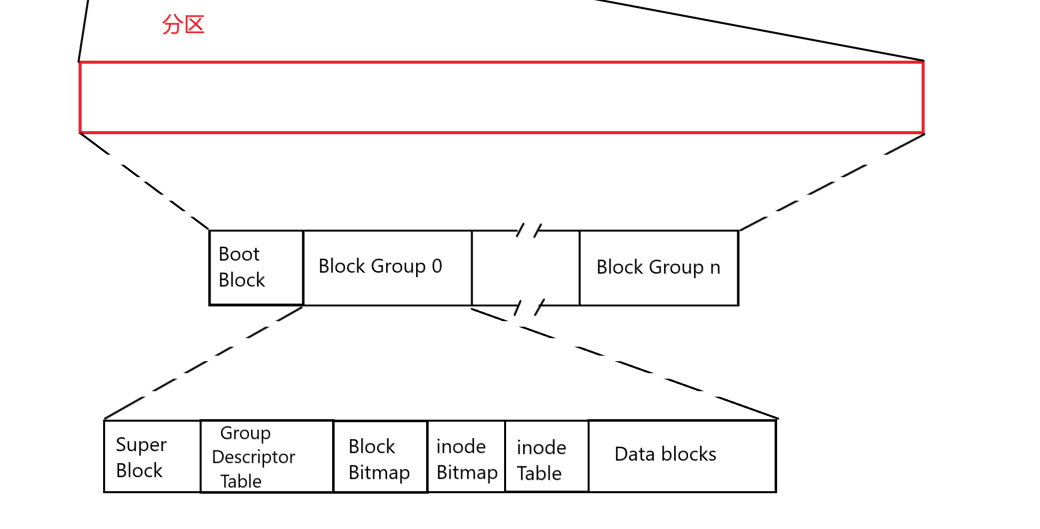
还是这张图,当我们执行 rm -f log.txt 的时候。
- 系统首先要根据当前目录的 inode ,找到其数据块,再从数据块中,找到 log.txt 对应的 inode 编号。
- 根据 log.txt 的inode 编号,找到 log.txt 的 inode,继而根据 inode ,可以知道 log.txt 使用了哪些数据块,将 Block Bitmap 中对应的位置修改为0。
- 然后根据 inode 编号,将 inode Bitmap 中对应的位置修改为0。
- 删除当前目录下, log.txt 和其 inode 编号的映射关系。
至此完成删除文件,实际上就是修改了 Block Bitmap 和 inode Bitmap。
创建、写入文件
创建文件也很好理解,先在根据创建文件的目录找到所在分组,然后找到分组里的 inode Bitmap,找到未使用的 inode(同时得到 inode 编号),分配给新文件,然后将文件的默认属性填到 inode 里面。然后向当前所处的目录的数据库里面,追加一条新文件和 inode 编号的对应关系。
对文件作修改、写入,就很简单了。拿着文件名,找到 inode 编号,继而找到文件的 inode,然后分配 Data Block,由操作系统计算出来要存储的数据有多大,计算出对应数量的 Data Block,然后扫描 Block Bitmap,将对应的比特位置为1,并将这些块的编号存储到 inode 里面,最后向数据块里面写入数据。
📕 软硬链接
软连接
ln -s < source filename > < dest filename>
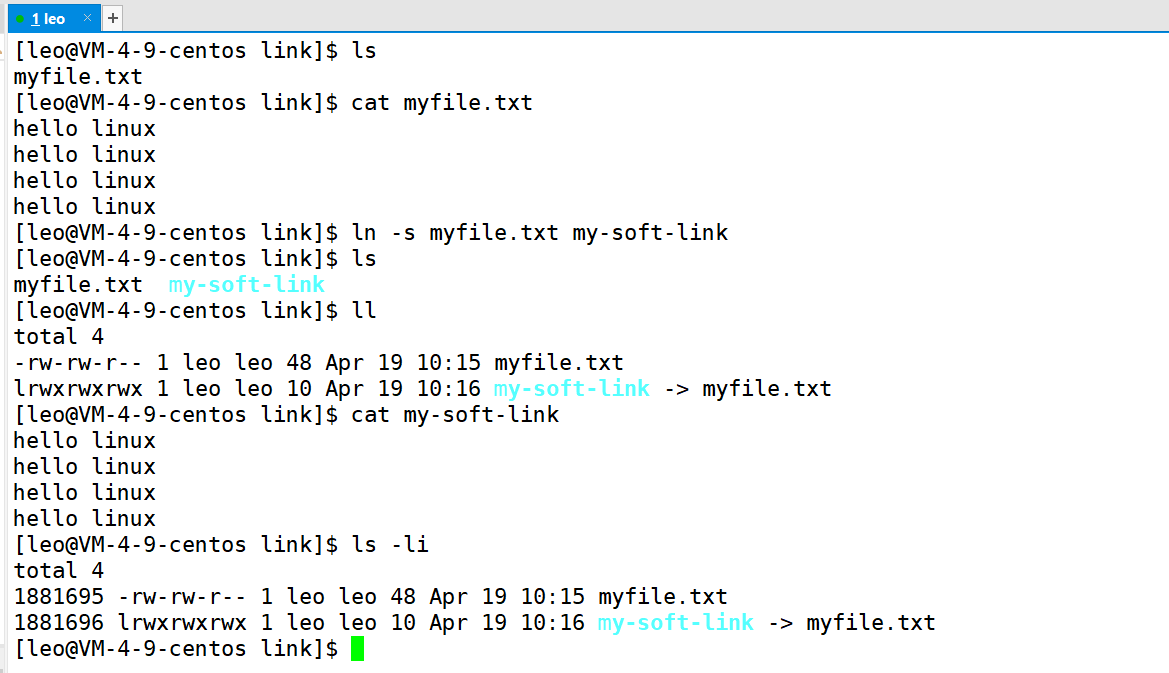
如下,是软链接的过程,通过 ll 指令可以看出,生成 my-soft-link 是一个链接文件,其文件类型是 “l” ,而通过 ls -li 可以看出,myfile.txt 和 my-soft-link 的文件 inode 编号是不一样的,所以 my-soft-link 是一个独立的文件。
软链接生成的文件,是独立的,该文件的数据块存储的信息,是链接对象的路径。(类似于 Windows 里面的快捷方式)
硬链接
ln < source filename > < dest filename >
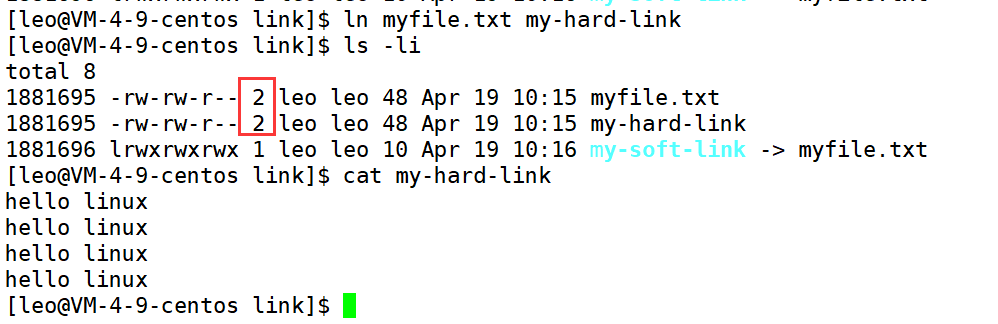
如下,是硬链接的过程,我们发现,硬链接生成的 my-hard-link ,其 inode 编号和 myfile.txt 是一样的,那么硬链接生成的文件,就是和源文件使用同一个 inode 的!并且 下图中红色方框内的数字,从原本的 1 变成了 2。
可是,硬链接没有独立的 inode ,那么它做了什么事情呢?其实,它在当前目录下,建立了新的文件名,和旧的 inode 编号的映射关系,它修改的是目录的数据块的内容!
红色方框内的数据,其实代表的是硬链接数,本质上是一种引用计数!它是 inode 里面的一个属性,代表着有多少个文件名指向这个 inode。
此外,我们需要去理解 . 和 … ,本质上这两个都是硬链接,如下,其 inode 一摸一样!!
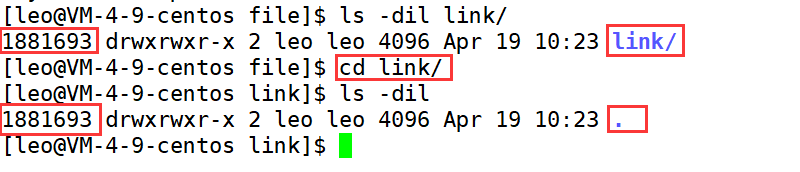
可是,需要注意的是,我们自己是无法给目录添加硬链接的,因为这样会造成环路路径问题!!给目录添加硬链接只能由操作系统完成,对于操作系统而言 . 和 … 这两个硬链接,一方面层数不深,另一方面,是操作系统自己添加的,可以识别,所以没有什么大问题。

📕 文件的 acm 时间
使用 stat < filename > 可以查看文件的 acm 时间,其含义如下。
- Access 最后访问时间
- Modify 文件内容最后修改时间
- Change 属性最后修改时间
对文件的 acm 时间的解释,其中 文件内容、属性 修改时间,是即时的,也就是说,只要对其内容作出修改,其 Modify 时间就会改变,Change 同理。
但是,Access 却不是如此,对于绝大多数文件,在 增删查改 这四个操作里面,我们最常用的操作是查,所以,如果每访问一次文件,都要修改其 Access 时间,就会造成频繁的磁盘IO(将 Access 时间写到文件存储的磁盘上),这样会大量消耗资源,所以操作系统一般都有自己的策略,可能几次访问文件,才会修改一次 Access 时间。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结