您现在的位置是:首页 >其他 >springcloud:新一代分布式定时任务框架——PowerJob网站首页其他
springcloud:新一代分布式定时任务框架——PowerJob
0. 引言
之前我们讲解过主流的分布式定时任务框架xxl-job,随着技术的迭代更新,更多的定时任务框架也开始出现,今天我们来看一看新一代的定时任务框架PowerJob
1. PowerJob简介
PowerJob是基于java开发的企业级的分布式任务调度平台,与xxl-job一样,基于web页面实现任务调度配置与记录,使用简单,上手快速,因此迅速得到用户的欢迎。
相对于其他定时任务框架具有无锁化设计,更强悍的性能支撑,我们通过官网的产品对比可以了解详情。
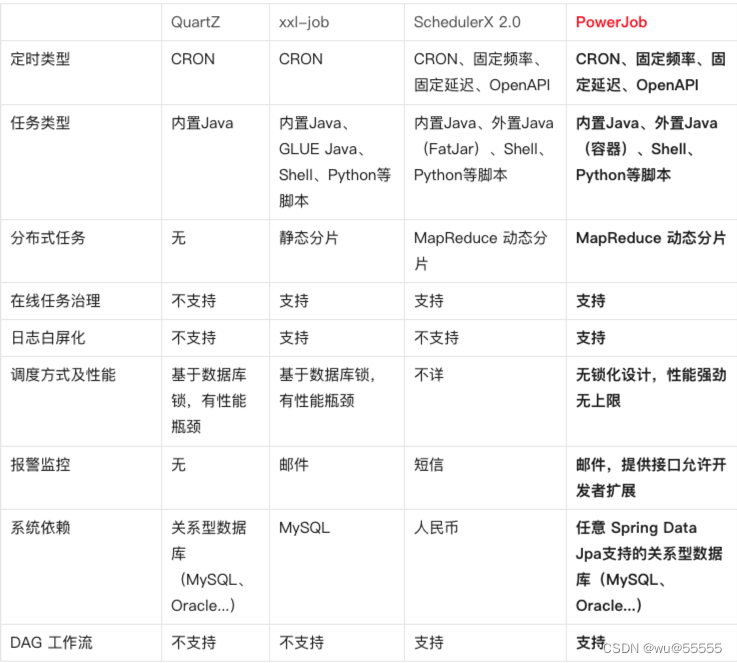
官网文档:http://www.powerjob.tech/
定时任务类型
与传统的定时任务框架对比,powerJob支持更多的定时任务类型:
-
API: 通过客户端提供的api接口触发,服务端不会主动调度,适用于与业务服务上下连接或只调度一次的业务场景
-
CRON: 通过cron表达式调度,这是多数定时任务框架都支持的
-
固定频率:每隔多少毫秒执行一次。
-
固定延迟:延迟多少毫秒执行一次
-
工作流:配合工作流进行调度,服务端不会主动调度,当工作流节点执行到该任务时运行。
2. PowerJob安装
PowerJob支持两种安装方式,一是通过jar包运行,一是通过docker安装
docker的安装较为简单,且官网有详细说明,这里就不单独讲解了,大家可参考官方文档:
我们讲解通过jar形式运行的,
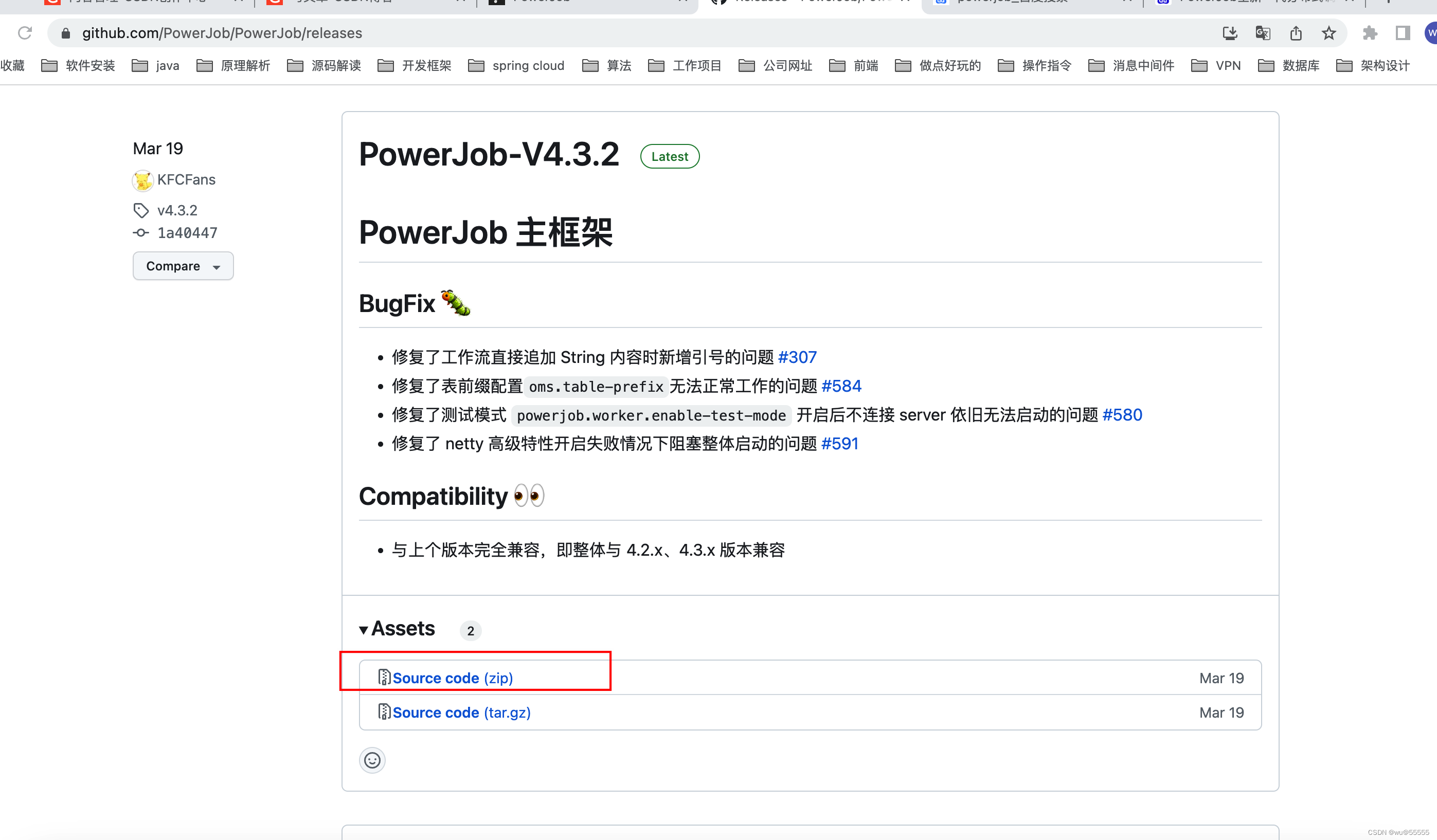
1、首先我们可以在github上下载源码,可以自己编译打包
https://github.com/PowerJob/PowerJob
可以在releases中下载指定版本,这里我们直接下载当前最新版
2、在IDE中打开后,我们powerjob-server就是我们要的服务端源码,可以直接编译,而powerjob-worker-samples就是springboot下的使用示例
3、在运行编译服务端之前,我们需要先创建数据库,在指定的数据库下创建即可
CREATE DATABASE IF NOT EXISTS `powerjob-daily` DEFAULT CHARSET utf8mb4
4、然后将powerjob-server/powerjob-server-starter下的application-daily.properties配置文件中的数据库配置改成你服务器的
其中daily,pre,product 表示日常、预生产、生产环境下的配置,与我们常见的dev, test, prod类似,可以根据需要进行调整
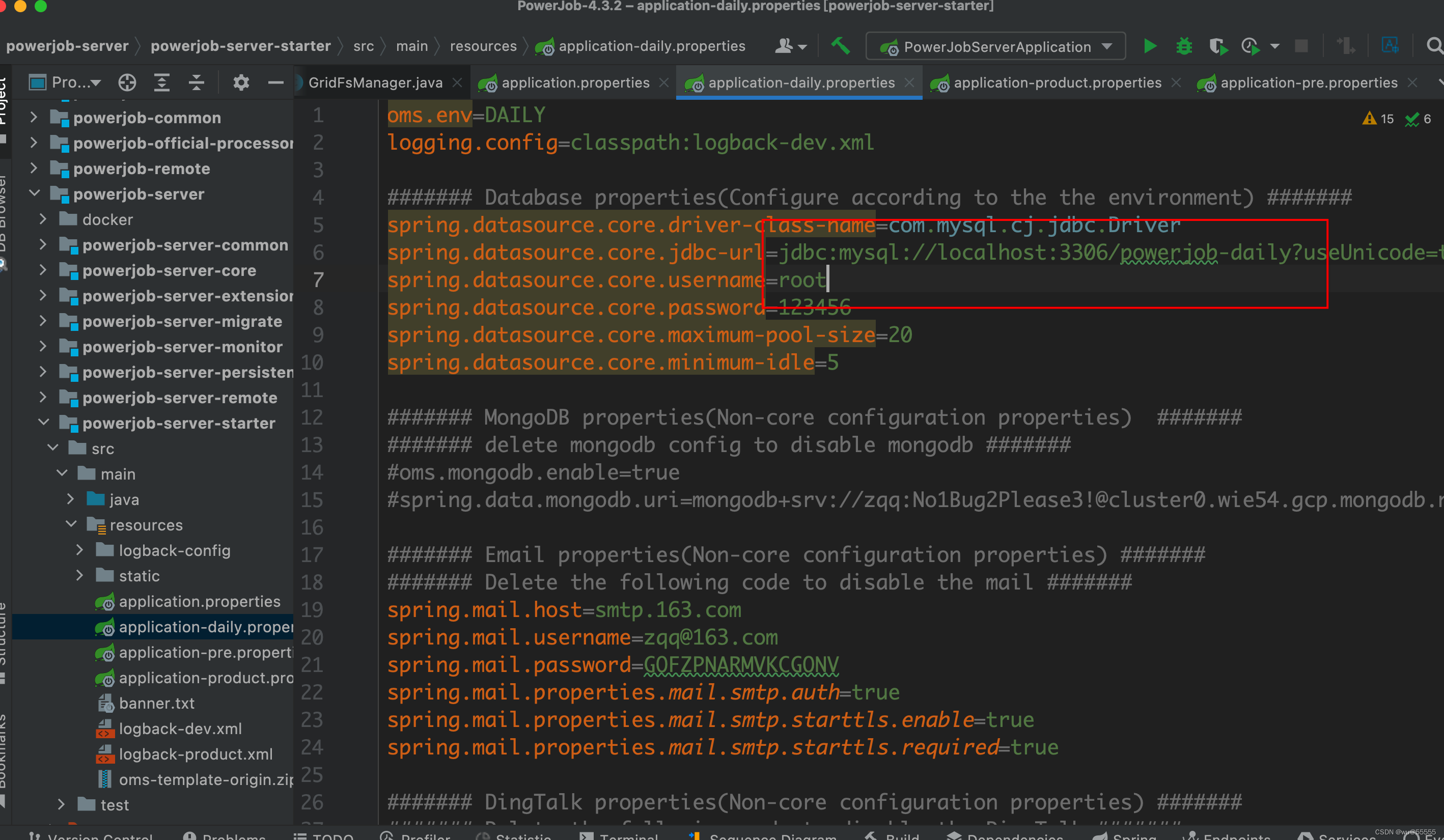
其中还有邮箱及其他配置,如果有需要也可以调整,服务端的参数配置可参考官网文档:
https://www.yuque.com/powerjob/guidence/bdvp1u
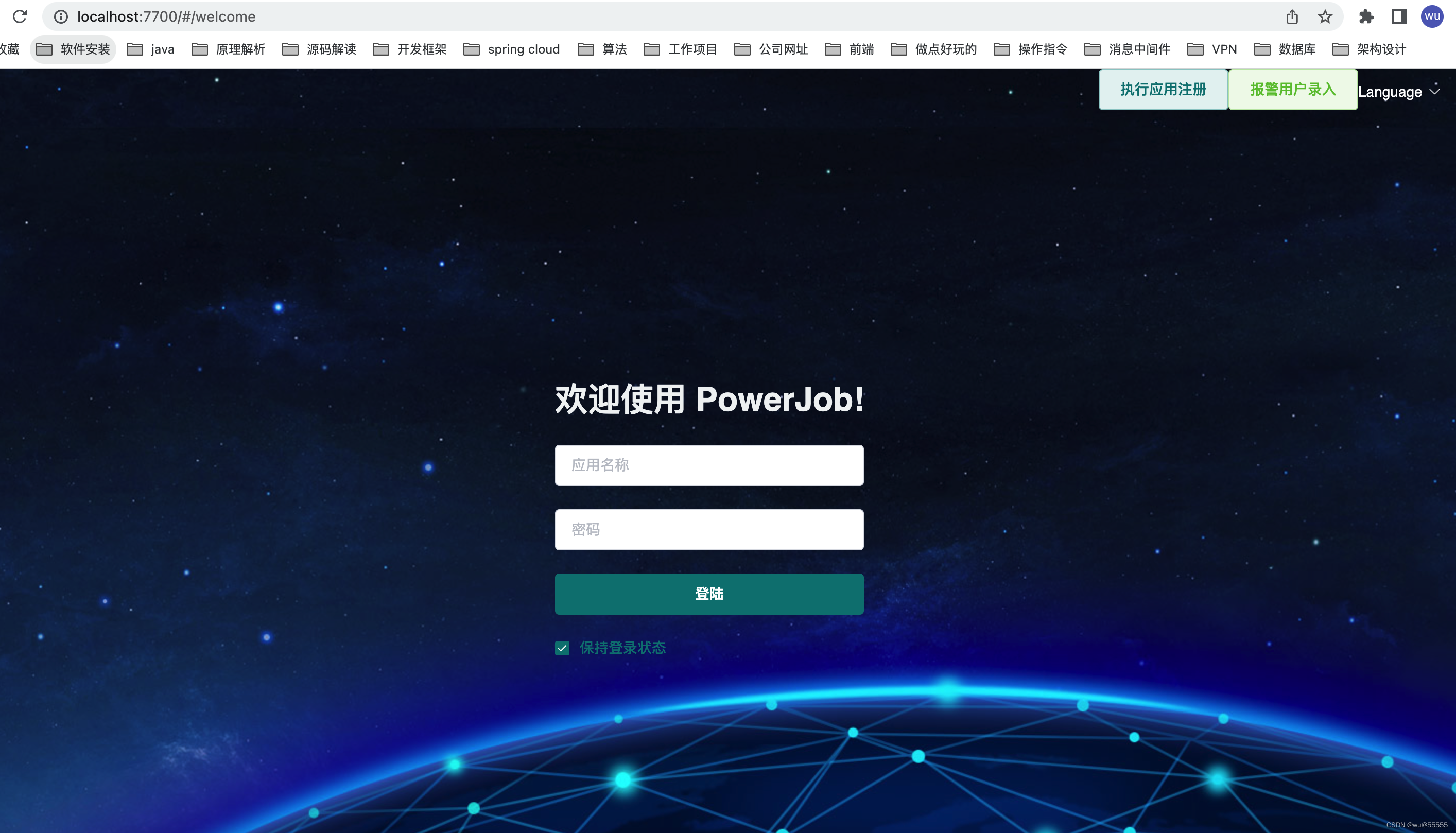
5、我们先来本地运行启动类PowerJobServerApplication一下试试,启动成功后,访问http://localhost:7700,出现登陆页则说明运行成功
6、先注册一个执行器,注意这里的应用名称不能顺便取,下文在客户端的配置的app-name要与该名称保持一致
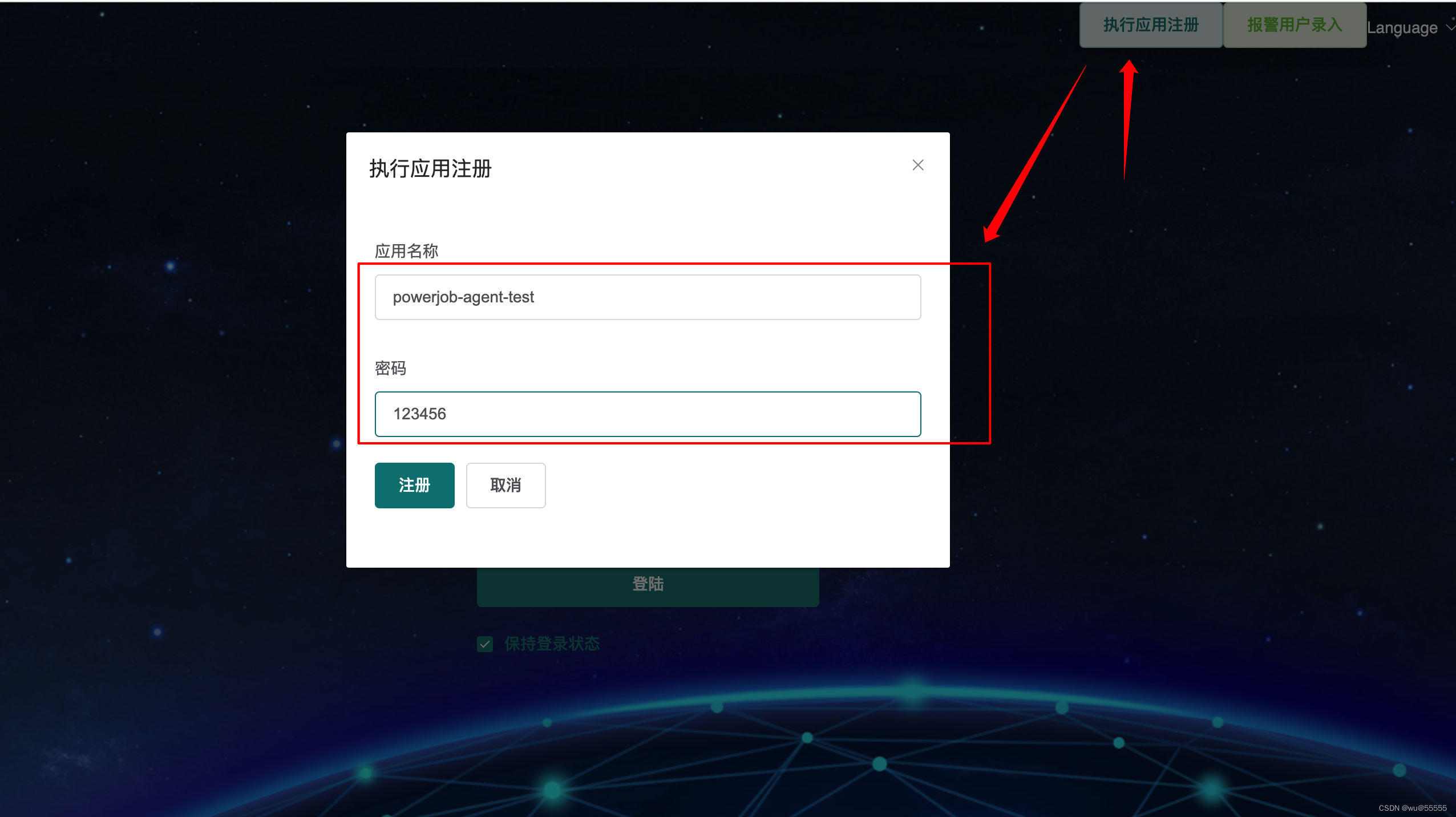
7、然后用该执行器名和密码登录

8、如下,我们就登录成功了
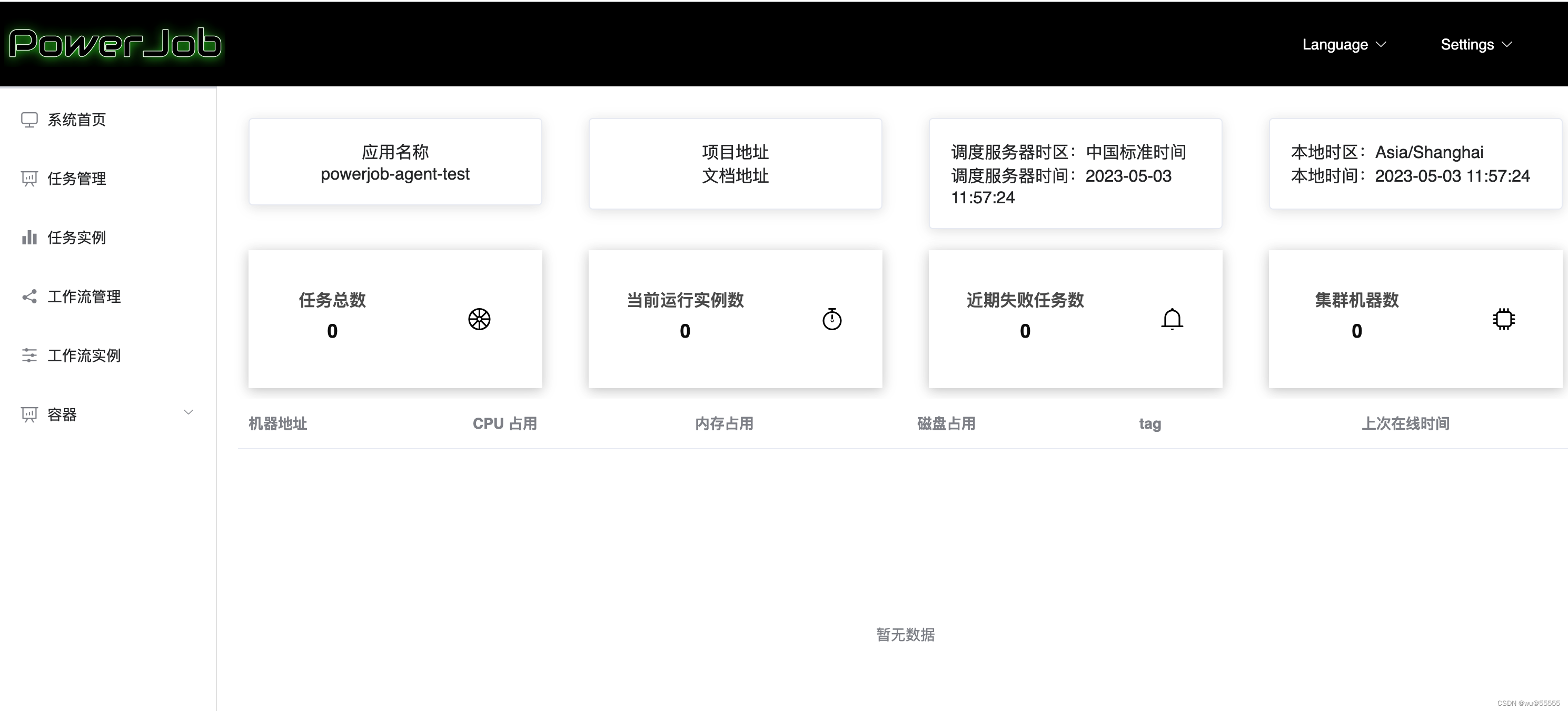
9、如果需要发布到服务器或虚拟机上运行,可以进行编译打包操作:
(1)点击mvn install 将依赖包打包到本地仓库
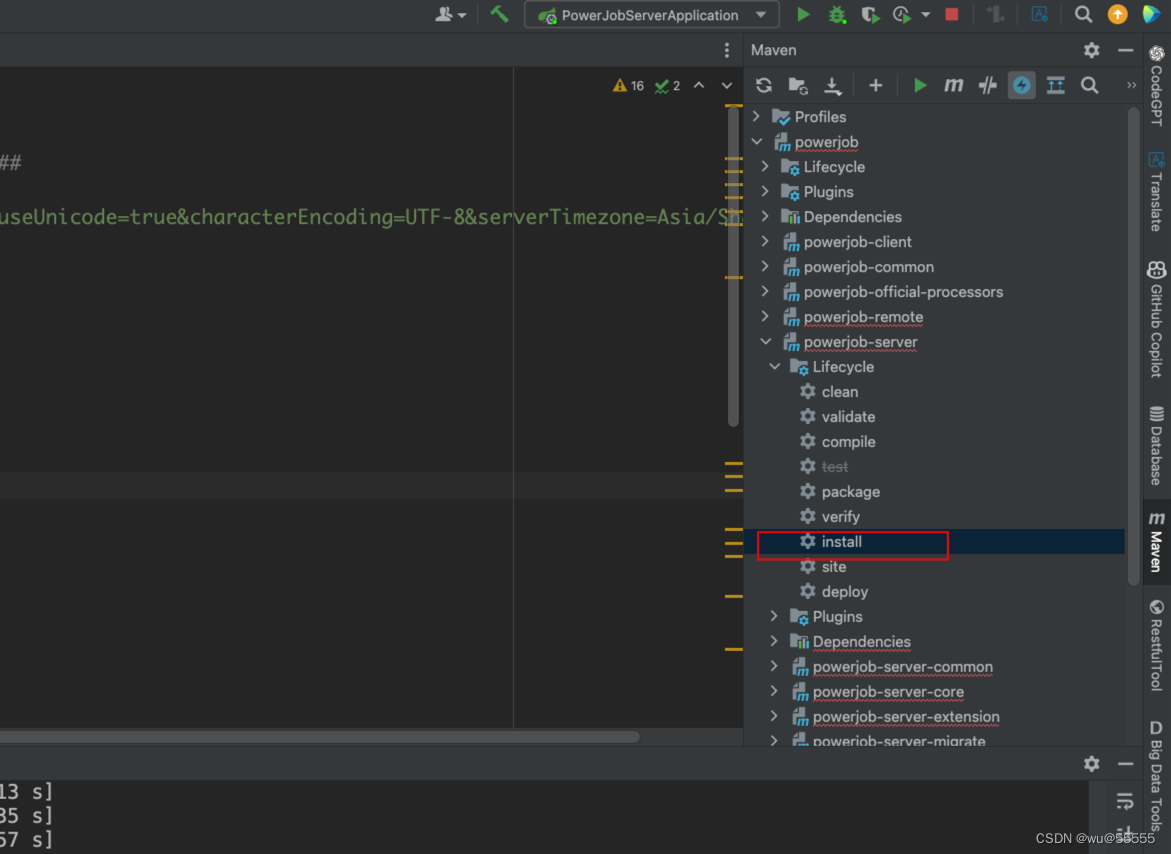
注意,如果这里报错 Please refer to /Library/project/study/java/PowerJob-4.3.2/powerjob-server/powerjob-server-starter/target/surefire-reports for the individual test results. 那么可以将maven的健康检查关闭
点击如图所示按钮,并且看到test置灰,则表示关闭
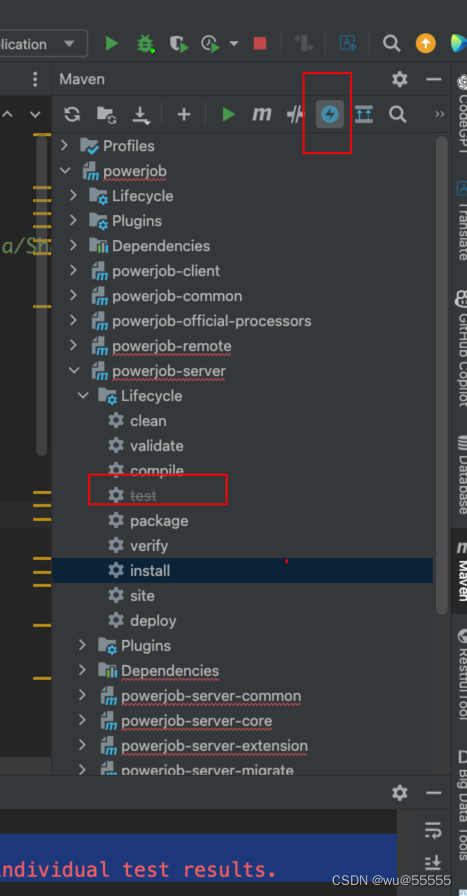
(2)执行mvn package打包项目
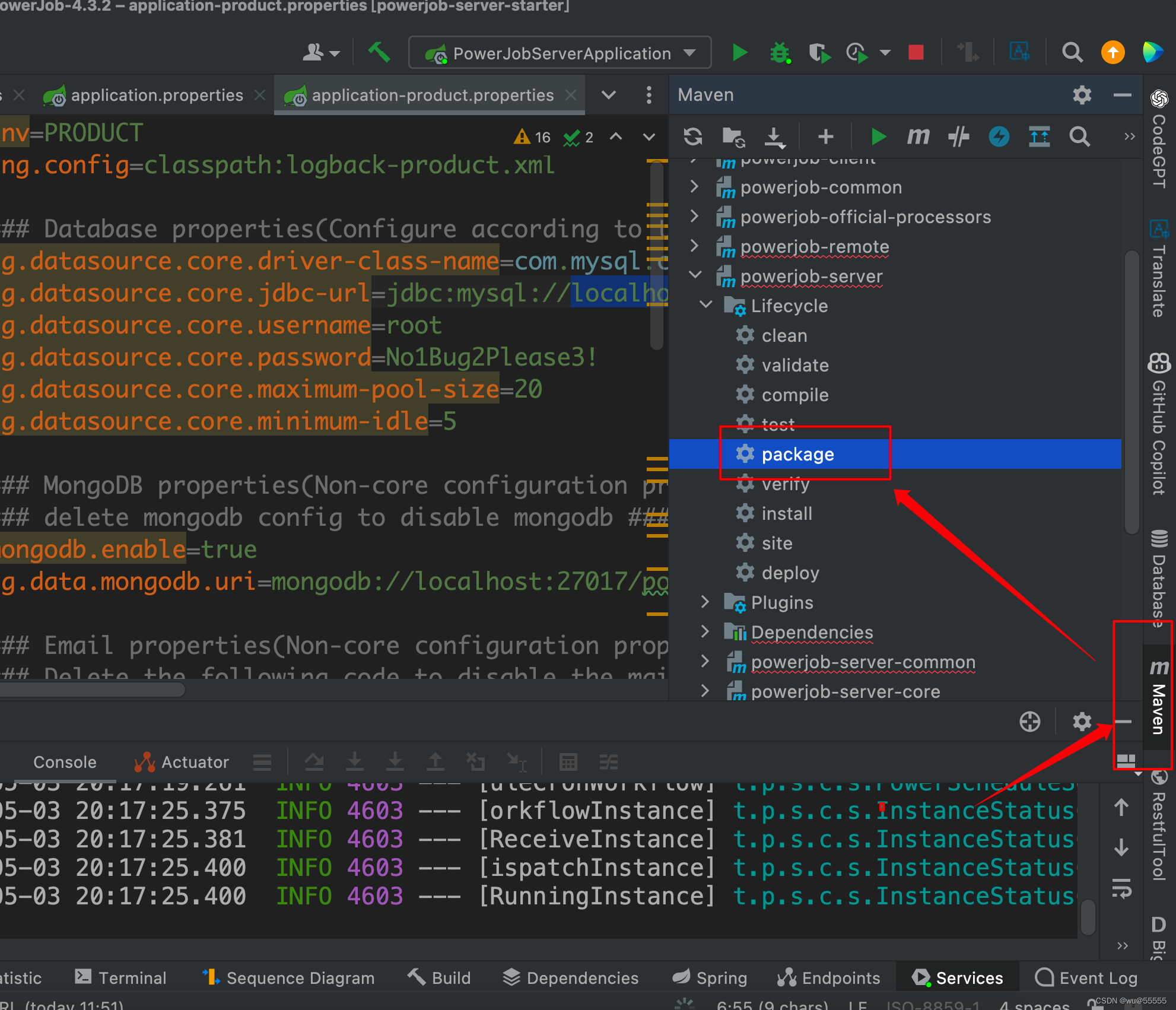
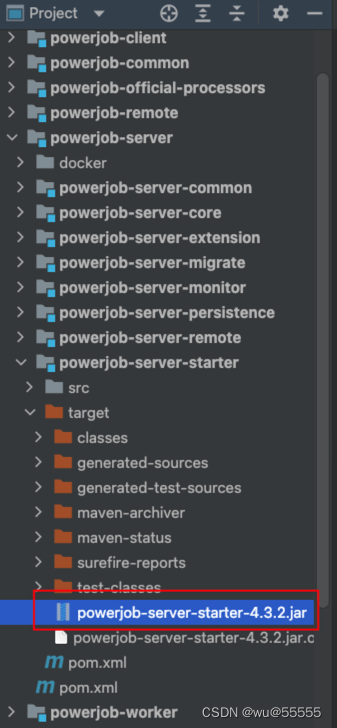
10、在powerjob-server-starter的target目录下即可看到打包出来的jar,将其上传到指定服务器,通过java -jar指令即可运行
2. 定时任务创建
1、创建一个springboot项目,用于定时任务客户端,引入客户端依赖,如果是spring或其他java项目引入,可参考官网文档:https://www.yuque.com/powerjob/guidence/ygonln
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-worker-spring-boot-starter</artifactId>
<version>4.3.2</version>
</dependency>
2、修改配置文件
powerjob:
worker:
enabled: true
enable-test-mode: false
# 数据传输端口,默认27777
port: 27777
# 应用名称,与服务端创建的应用账号的名称保持一致
app-name: powerjob-agent-test
# 服务端地址,多个用,隔开
server-address: 127.0.0.1:7700
# 通讯协议,4.3.0之后支持http和akka,4.3.0之前仅支持akka,官方推荐http
protocol: http
# 任务返回结果信息的最大长度,超过该值将被截断
max-result-length: 4096
# 同时运行的轻量级任务数量上限
max-lightweight-task-num: 1024
# 同时运行的重量级任务数量上限
max-heavy-task-num: 64
3、启动类上添加注解@EnableScheduling
4、通过申明BasicProcessor接口,实现process方法来书写一个简单的定时任务示例类,注意要声明为bean
/**
* @author benjamin_5
* @Description 简单任务执行器
* @date 2023/5/3
*/
@Component
public class SimpleJobServer implements BasicProcessor {
@Override
public ProcessResult process(TaskContext taskContext) throws Exception {
String jobParams = taskContext.getJobParams();
System.out.println("参数: " + jobParams);
System.out.println("定时任务执行");
return new ProcessResult(true, "定时任务执行成功");
}
}
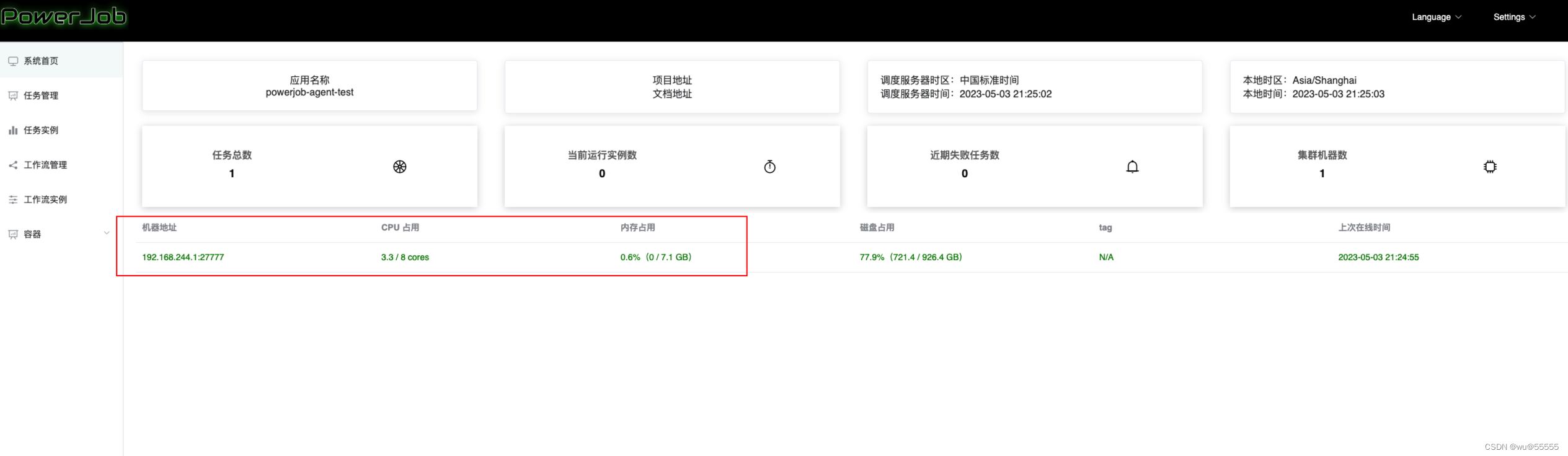
5、启动客户端项目,运行成功后,可以在服务端首页看到机器实例
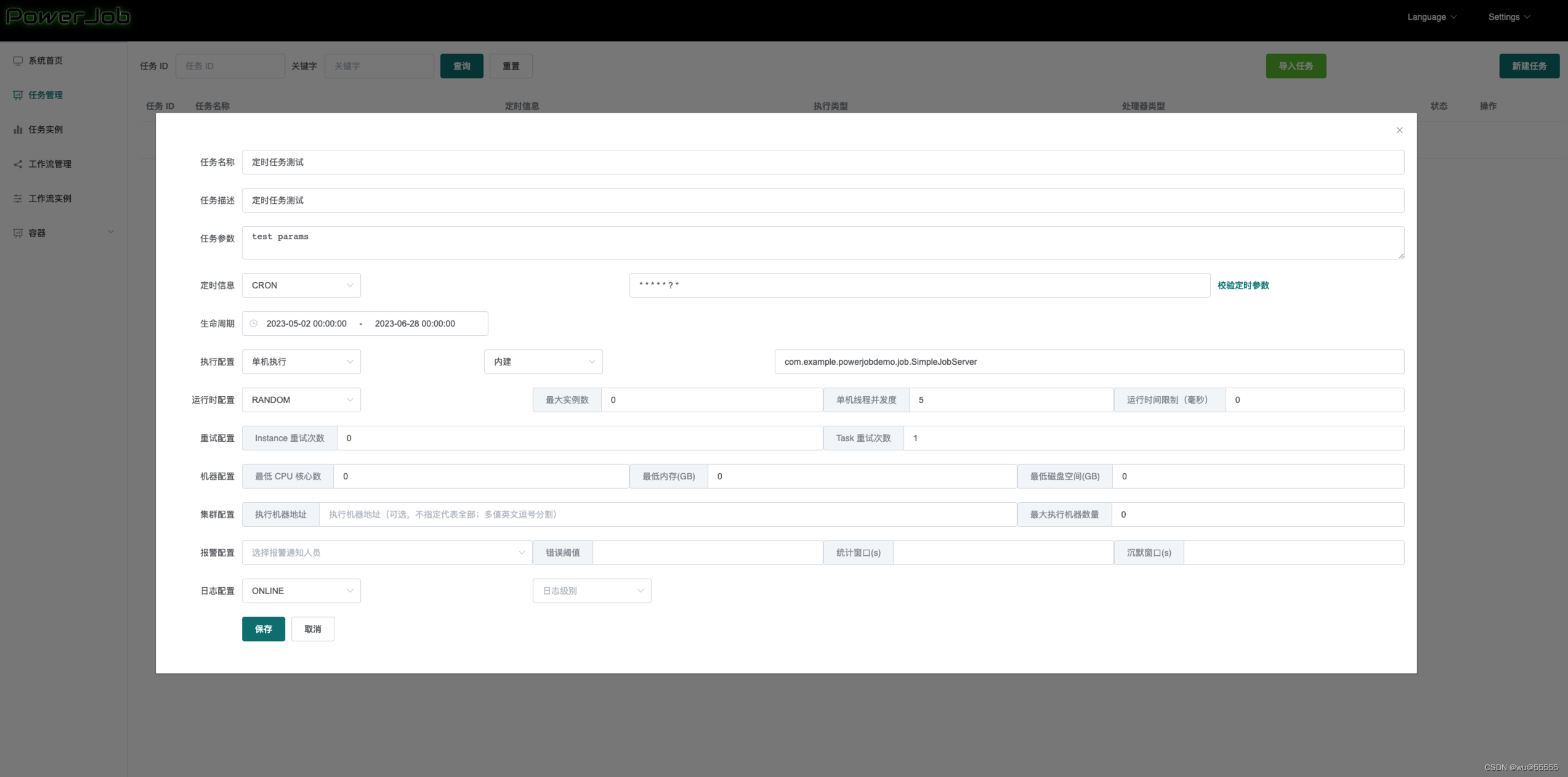
6、服务端任务管理点击新建任务
其中处理器配置是通过书写处理器的全类路径名来声明的,比如我这里是com.example.powerjobdemo.job.SimpleJobServer
7、创建成功后,可以在列表看到新建的任务
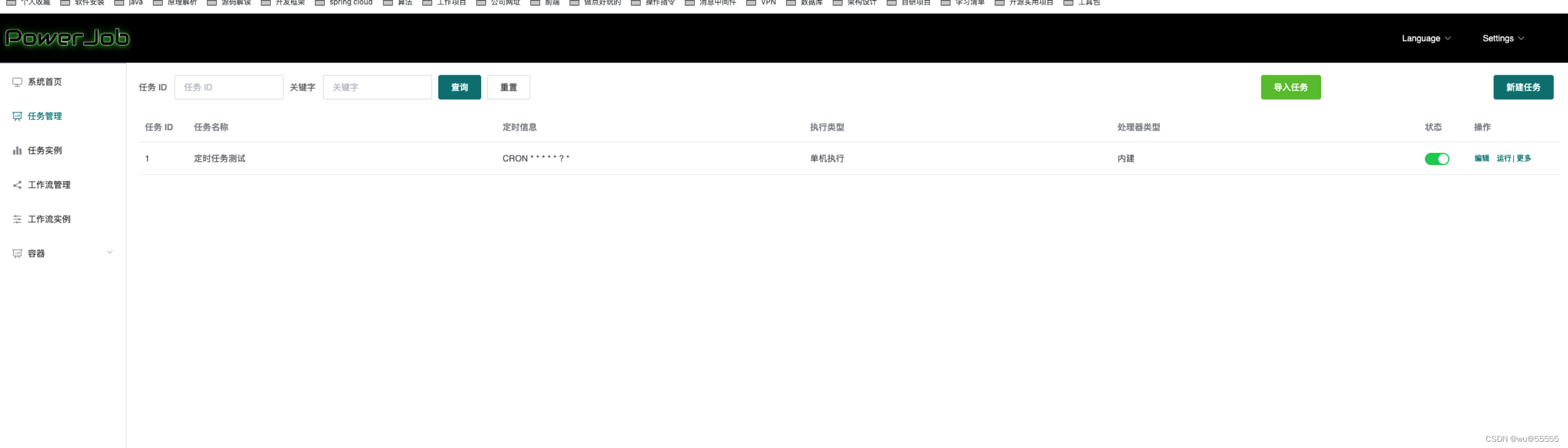
8、打开客户端控制台,也能看到输出的参数和执行打印,说明任务执行成功

9、同时我们可以在运行记录中看到执行日志
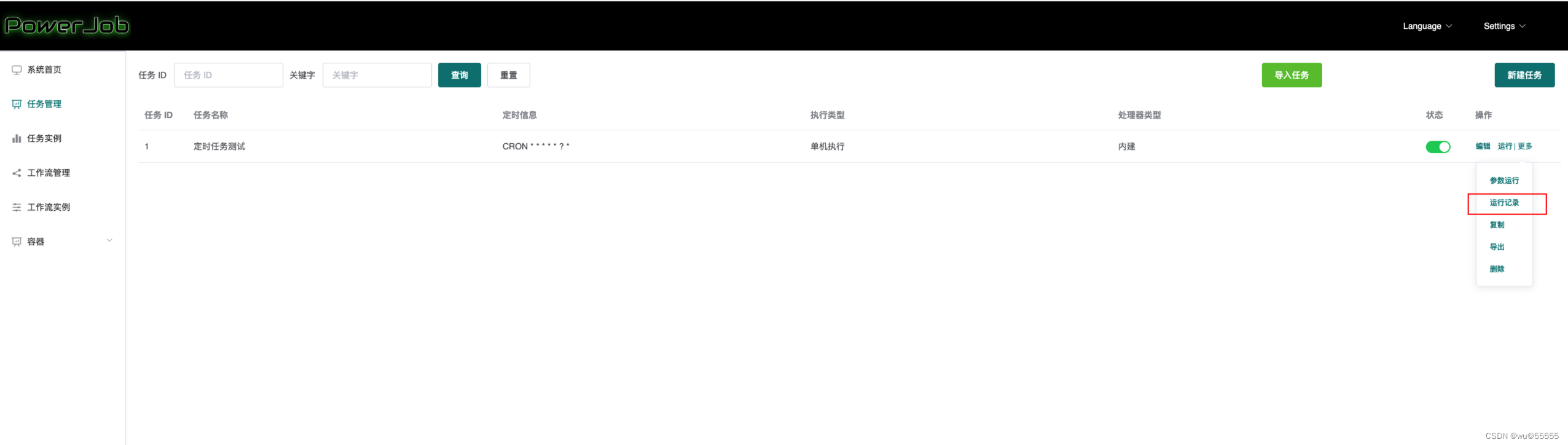
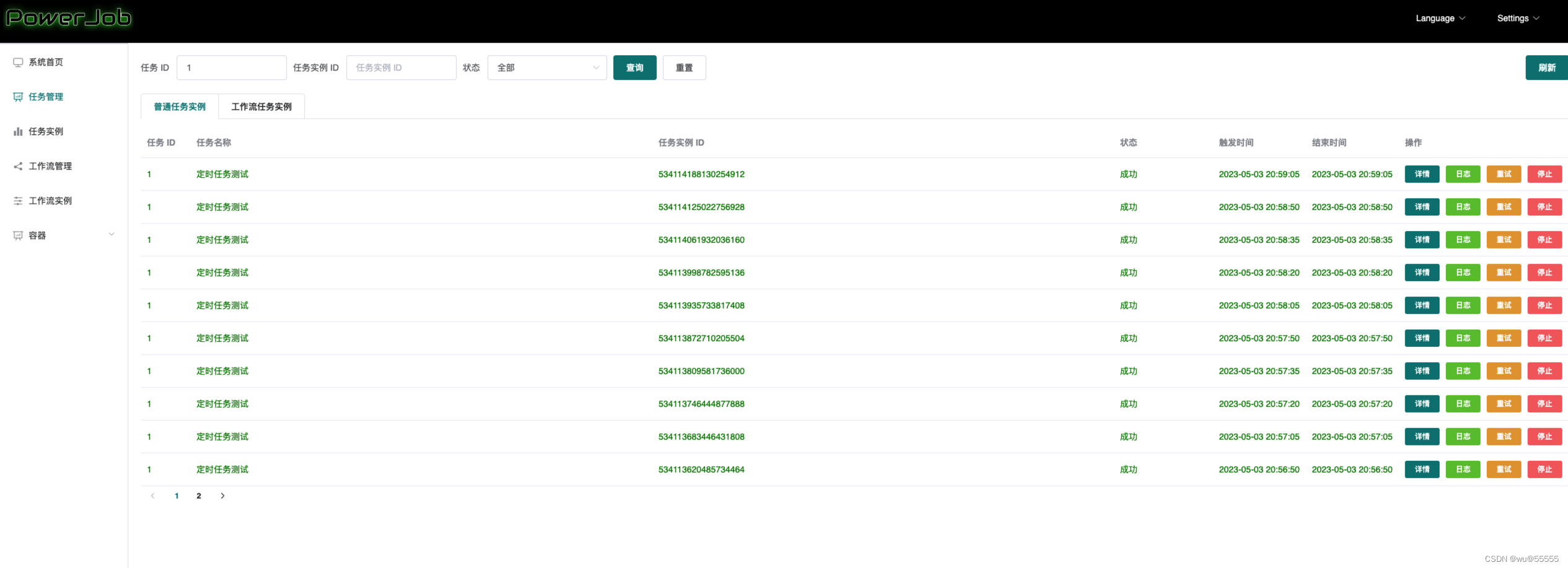
至此,针对powerjob的最简单使用就完成了,接下来我们继续来看关于powjob的配置详解
3. 任务配置参数详解
创建任务时我们可以看到如下图所示的配置:
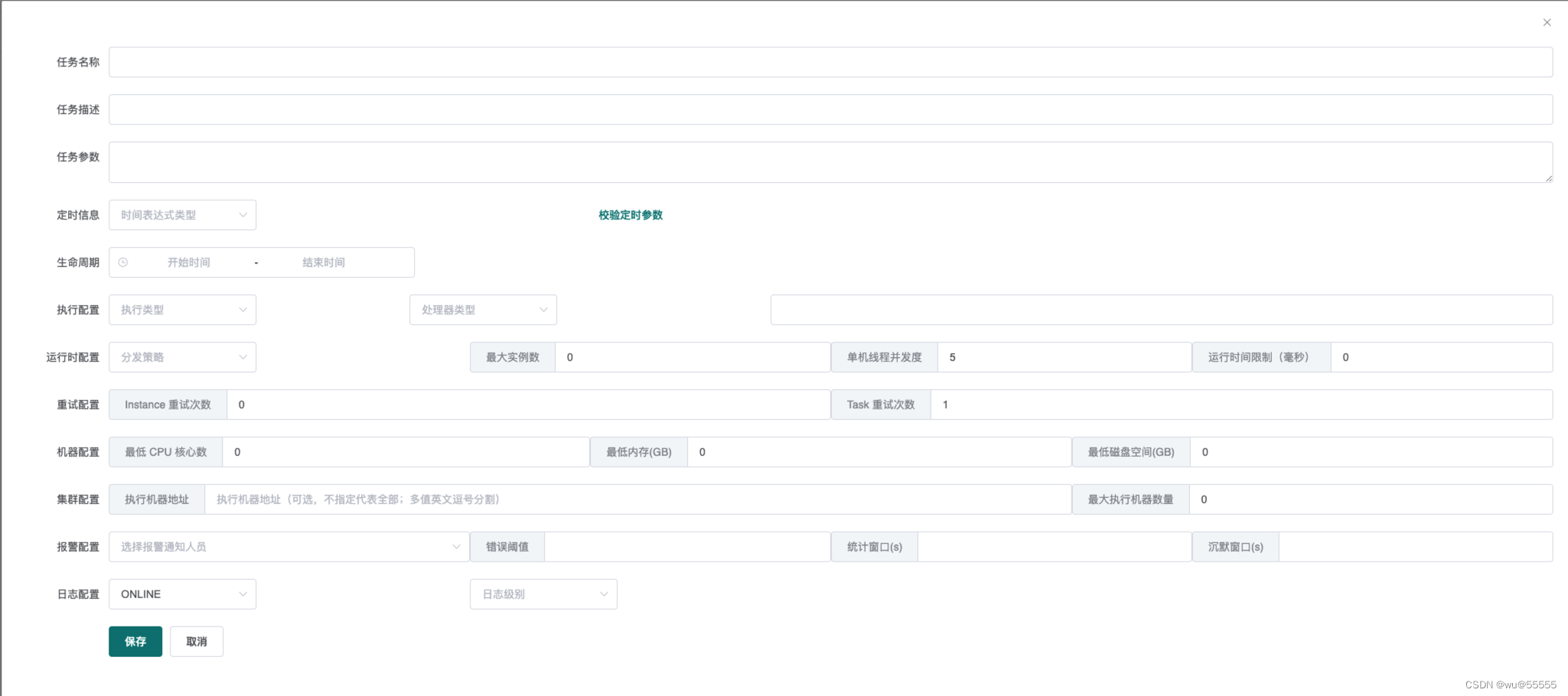
- 定时信息:
主要选择定时任务类型,支持API, CRON,固定频率、固定延迟、工作流、每日固定间隔等几种定时任务类型。
- 生命周期:
这是比其他任务框架更便捷的功能,指定了任务的生效周期,如果该任务是预定某时间段内执行的,可以通过该参数配置
- 执行配置:
执行类型支持单机执行、广播执行、Map执行、MapReduce执行
单机执行表示只需要有一个节点执行任务即可的场景
广播执行表示需要全部节点一同执行的场景,比如清除机器日志、各节点数据统计
Map与MapReduce执行都是表示分布式、分批执行,用来拆分计算量、耗时较大的任务,区别在于Map执行是一种简单的数据处理逻辑,特点是将输入数据拆分成多个子块,并交给多个分布式节点同时执行,以提高数据处理效率,适用于简单的数据处理场景
MapReduce执行是一种大数据处理框架,处理逻辑是将复杂的数据处理拆分成Map和Reduce阶段进行处理,通过数据分组计算后合并来提供数据处理效率,更适合复杂的大数据场景
- 运行时配置:
支持HEALTH_FIRST和RANDOM,即第一个健康节点和随机,用于选择执行处理器节点的策略。
最大实例数用于控制处理器节点数量,线程并发度用于控制并发,运行时间限制
更多说明,可在官方文档中查看:https://www.yuque.com/powerjob/guidence/ysug77







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结