您现在的位置是:首页 >技术教程 >二十二、SQL 数据分析实战(案例1~案例10)网站首页技术教程
二十二、SQL 数据分析实战(案例1~案例10)
文章目录
案例1:用户信息表 stu_table
stu_table 表如下所示:
mysql> SELECT * FROM `stu_table`;
-- id:用户ID name:姓名 class:区域 sex:性别
+----+--------+-------+------+
| id | name | class | sex |
+----+--------+-------+------+
| 1 | 王小凤 | 一区 | 女 |
| 10 | 李春山 | 三区 | 男 |
| 2 | 刘诗迪 | 一区 | 女 |
| 3 | 李思雨 | 一区 | 女 |
| 4 | 张文华 | 二区 | 男 |
| 5 | 张青云 | 二区 | 女 |
| 6 | 徐文杰 | 二区 | 男 |
| 7 | 李智瑞 | 三区 | 男 |
| 8 | 徐雨秋 | 三区 | 男 |
| 9 | 孙皓然 | 三区 | 男 |
+----+--------+-------+------+
10 rows in set (0.00 sec)
【练习1】查询每个区域的用户数。运行结果如下表所示:
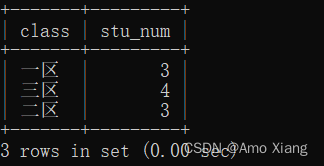
【解析1】首先对区域进行分组group by,然后对每个组内的用户进行计数聚合运算count,然后参考如下代码:
mysql> SELECT class,count( id ) AS stu_num FROM stu_table GROUP BY class;
【练习2】查询每个区域的男女用户数。运行结果如下表所示:
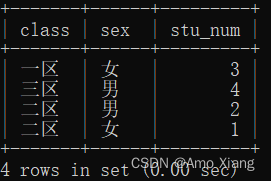
【解析2】主要考察的就是按照多列进行分组聚合的知识,直接在group by后面指明要分组的列名即可,且列名与列名之间用逗号隔开,然后参考如下代码:
mysql> SELECT
-> class,
-> sex,
-> COUNT(id) AS stu_num
-> FROM
-> stu_table
-> GROUP BY class,
-> sex;
【练习3】查询姓张的用户数。运行结果如下表所示:
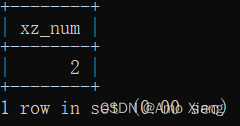
【解析3】首先需要思考怎么判断用户是否姓张,可以使用like关键字或者是使用正则表达式,接下来使用where将这些用户筛选出来,最后使用count针对筛选出来的用户进行计数,参考如下代码:
mysql> SELECT COUNT(*) AS xz_num FROM stu_table WHERE `name` LIKE '张%';
mysql> SELECT COUNT(id) AS xz_num FROM stu_table WHERE `name` REGEXP '^张';
案例2:员工绩效表 score_table
score_table 表如下所示:
mysql> select * from score_table;
-- name: 姓名 group: 部门 score: 绩效得分
+----+--------+-------+-------+
| id | name | group | score |
+----+--------+-------+-------+
| 1 | 王小凤 | 一部 | 88 |
| 2 | 刘诗迪 | 一部 | 70 |
| 3 | 李思雨 | 一部 | 92 |
| 4 | 张文华 | 二部 | 55 |
| 5 | 张青云 | 二部 | 77 |
| 6 | 徐文杰 | 二部 | 77 |
| 7 | 李智瑞 | 三部 | 56 |
| 8 | 徐雨秋 | 三部 | 91 |
| 9 | 孙皓然 | 三部 | 93 |
| 10 | 李春山 | 三部 | 57 |
+----+--------+-------+-------+
10 rows in set (0.00 sec)
【练习4】筛选出绩效不达标的员工(绩效得分小于60分)。运行结果如下表所示:
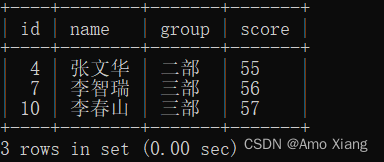
【解析4】需要知道不达标的标准是什么,然后利用where来限定不达标的条件即可,参考如下代码:
mysql> SELECT * FROM score_table WHERE score < 60;
【练习5】筛选出姓张且绩效不达标的员工(绩效得分小于60分)。运行结果如下表所示:
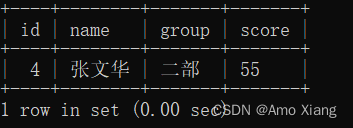
【解析5】这里主要用到了多条件筛选的知识点,多个条件之间用and进行关联,然后将关联后的代码放在where后面即可,参考如下代码:
mysql> SELECT * FROM score_table WHERE `name` LIKE '张%' AND score < 60;
mysql> SELECT * FROM score_table WHERE `name` REGEXP '^张' AND score < 60;
案例3:销售冠军信息表 month_table
month_table 表记录了每月的销售冠军信息,如下所示:
mysql> select * from month_table;
-- name: 姓名 month_num: 月份
+------+--------+-----------+
| id | name | month_num |
+------+--------+-----------+
| E002 | 王小凤 | 1 |
| E001 | 张文华 | 2 |
| E003 | 孙皓然 | 3 |
| E001 | 张文华 | 4 |
| E002 | 王小凤 | 5 |
| E001 | 张文华 | 6 |
| E004 | 李智瑞 | 7 |
| E002 | 王小凤 | 8 |
| E003 | 孙皓然 | 9 |
+------+--------+-----------+
9 rows in set (0.00 sec)
【练习6】查询获得销售冠军的次数超过2次的人及其获得销售冠军的次数。运行结果如下表所示:
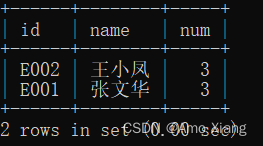
【解析6】要查询获得销售冠军的次数超过2次的人及其获得销售冠军的次数,首先需要获取每个人获得销售冠军的次数,对id列和name列进行group by,然后在组内对month_num列进行计数就可以得到每个人获得销售冠军的次数,接着利用having对分组聚合后的结果进行条件筛选,参考代码如下:
mysql> SELECT
-> `id`,
-> `name`,
-> COUNT(month_num) AS 'num'
-> FROM
-> month_table
-> GROUP BY `id`,
-> `name`
-> HAVING COUNT(month_num) > 2;
案例4:月销售额记录表 sale_table
月销售额记录表 sale_table,这张表记录了某部门2018年和2019年某几个月的销售额,sale_table 表如下所示:
mysql> select * from sale_table;
-- year_num: 年份 month_num: 月份 sales: 销售额
+----------+-----------+-------+
| year_num | month_num | sales |
+----------+-----------+-------+
| 2019 | 1 | 2854 |
| 2019 | 2 | 4772 |
| 2019 | 3 | 3542 |
| 2019 | 4 | 1336 |
| 2019 | 5 | 3544 |
| 2018 | 1 | 2293 |
| 2018 | 2 | 2559 |
| 2018 | 3 | 2597 |
| 2018 | 4 | 2363 |
+----------+-----------+-------+
9 rows in set (0.00 sec)
【练习7】查询2019年的月销售额最高涨幅是多少。运行结果如下表所示:
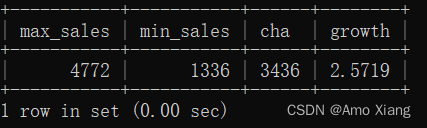
【解析7】要查询2019年的月销售额最高涨幅,首先需要通过where把2019年的每月销售额筛选出来,然后在2019年的月销售额中寻找最大和最小的销售额,对两者做差并进行相应计算,就是我们想要的结果,参考代码如下:
mysql> SELECT
-> MAX(sales) AS max_sales,
-> MIN(sales) AS min_sales,
-> MAX(sales) - MIN(sales) AS cha,
-> (MAX(sales) - MIN(sales)) / MIN(sales) AS growth
-> FROM
-> sale_table
-> WHERE year_num = 2019;
案例5:每季度员工绩效得分表 score_info_table
每季度员工绩效得分表 score_info_table 记录了每位员工每个季度的绩效得分,score_info_table 表如下所示:
mysql> SELECT * FROM `score_info_table`;
+------+--------+----------+-------+
| id | name | subject | score |
+------+--------+----------+-------+
| 1 | 王小凤 | 第一季度 | 88 |
| 1 | 王小凤 | 第二季度 | 55 |
| 1 | 王小凤 | 第三季度 | 72 |
| 3 | 徐雨秋 | 第一季度 | 92 |
| 3 | 徐雨秋 | 第二季度 | 77 |
| 3 | 徐雨秋 | 第三季度 | 93 |
| 2 | 张文华 | 第一季度 | 70 |
| 2 | 张文华 | 第二季度 | 77 |
| 2 | 张文华 | 第三季度 | 91 |
+------+--------+----------+-------+
9 rows in set (0.00 sec)
【练习8】查询每个季度绩效得分都大于70分的员工。运行结果如下表所示:
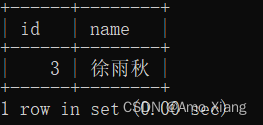
【解析8】要查询每个季度绩效得分都大于70分的员工,只要能够保证每个季度每位员工的最小绩效得分是大于70分的,就可以说明这位员工的每个季度绩效得分都大于70分。所以第一步需要查询每位员工的最小绩效得分,先对id列和name列进行group by 分组,然后在组内求最小值,接着将最小绩效得分大于70分的员工通过having筛选出来即可,参考代码如下:
-- 写法1:
mysql> SELECT
-> `id`,
-> `name`
-> -- min(score)
-> FROM
-> score_info_table
-> GROUP BY `id`,
-> `name`
-> HAVING MIN(score) > 70;
-- 写法2
mysql> SELECT
-> `id`,
-> `name`
-> -- count (id)
-> FROM
-> score_info_table
-> WHERE score > 70
-> GROUP BY `id`,
-> `name`
-> HAVING COUNT(id) > 2;
案例6:员工信息表 stu_info_table
现在有一张员工信息表 stu_info_table,这张表包含id、name(姓名)、t_1(一级部门)和 t_2(二级部门)四个字段,stu_info_table 表如下所示:
mysql> SELECT * FROM `stu_info_table`;
+----+--------+------------+----------+
| id | name | t_1 | t_2 |
+----+--------+------------+----------+
| 1 | 王小凤 | 产品技术部 | B端产品 |
| 2 | 刘诗迪 | 产品技术部 | C端产品 |
| 3 | 李思雨 | 产品技术部 | B端产品 |
| 4 | 张文华 | 销售运营部 | 销售管理 |
| 5 | 张青云 | 销售运营部 | 数据分析 |
| 6 | 徐文杰 | 销售运营部 | 销售管理 |
| 7 | 李智瑞 | 产品技术部 | B端产品 |
| 8 | 徐雨秋 | 销售运营部 | 销售管理 |
| 9 | 孙皓然 | 产品技术部 | B端产品 |
+----+--------+------------+----------+
9 rows in set (0.00 sec)
【练习9】获取该公司一级部门及二级部门的信息,即哪些一级部门下包含哪些二级部门。运行结果如下表所示:
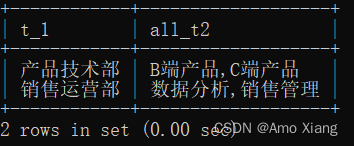
【解析9】查询一级部门下包含哪些二级部门,可以先对一级部分进行分组,然后使用group_concat函数将分组产生的同一个分组中的值连接起来,返回一个字符串结果。参考代码如下:
mysql> SELECT t_1,GROUP_CONCAT(DISTINCT t_2) AS all_t2 FROM stu_info_table GROUP BY t_1;
-- 删除重复值的操作除了可以用distinct,还可以用group by
-- 获取公司一级部门及二级部门的信息
SELECT DISTINCT t_1,t_2 FROM stu_info_table;
SELECT t_1,t_2 FROM stu_info_table GROUP BY t_1,t_2;
案例7:行列互换 row_col_table
row_col_table 表如下所示,这张表中每年每月的销量是一行数据。
mysql> SELECT * FROM `row_col_table`;
+----------+-----------+-------+
| year_num | month_num | sales |
+----------+-----------+-------+
| 2019 | 1 | 100 |
| 2019 | 2 | 200 |
| 2019 | 3 | 300 |
| 2019 | 4 | 400 |
| 2020 | 1 | 200 |
| 2020 | 2 | 400 |
| 2020 | 3 | 600 |
| 2020 | 4 | 800 |
+----------+-----------+-------+
8 rows in set (0.00 sec)
【练习10】需要把row_col_table表所示的纵向存储数据的方式改成如下表所示的横向存储数据的方式。

【解析10】要把纵向数据表转换成横向数据表,首先要把多行的年数据转化为一年是一行,可以通过group by实现,group by一般需要与聚合函数一起使用,现在不需要对所有数据进行聚合,所以我们通过case when来对指定月份的数据进行聚合。参考代码如下:
mysql> SELECT year_num,
-> SUM(CASE WHEN month_num = 1 THEN sales ELSE 0 END) AS m1,
-> SUM(CASE WHEN month_num = 2 THEN sales ELSE 0 END) AS m2,
-> SUM(CASE WHEN month_num = 3 THEN sales ELSE 0 END) AS m3,
-> SUM(CASE WHEN month_num = 4 THEN sales ELSE 0 END) AS m4
-> FROM
-> row_col_table
-> GROUP BY
-> year_num;
案例8:多列比较 col_table
现在 col_table 表中有 col_1、col_2、col_3 三列数据,col_table 表如下所示:
mysql> SELECT * FROM `col_table`;
+-------+-------+-------+
| col_1 | col_2 | col_3 |
+-------+-------+-------+
| 5 | 10 | 7 |
| 1 | 10 | 6 |
| 9 | 3 | 5 |
| 5 | 2 | 9 |
| 10 | 4 | 3 |
| 5 | 2 | 9 |
| 5 | 8 | 6 |
| 8 | 8 | 6 |
+-------+-------+-------+
8 rows in set (0.00 sec)
【练习11】根据col_table表中的三列数据生成一列结果列,结果列的生成规则为:如果col_1列大于col_2列,则结果为col_1列的数据;如果col_2列大于col_3列,则结果为col_3列的数据,否则结果为col_2列的数据,运行结果如下表所示:
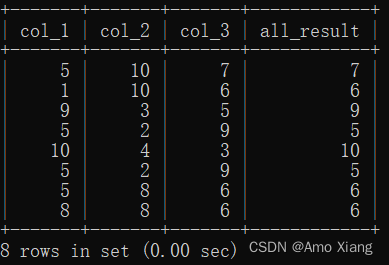
【解析11】多列比较其实就是一个多重判断的过程,借助case when即可实现,先判断col_1列和col_2列的关系,然后判断col_2列和col_3列的关系。这里需要注意的是,判断的执行顺序是先执行第一行case when,然后执行第二行case when,参考代码如下:
mysql> SELECT *,
-> (CASE WHEN col_1 > col_2 THEN col_1
-> ELSE (CASE WHEN col_2 > col_3 THEN col_3 ELSE col_2 END)
-> END) AS all_result
-> FROM col_table;
案例9:学生成绩表 subject_table
学生成绩表 subject_table 包含id、score(成绩)两个字段,如下所示:
mysql> SELECT * FROM `subject_table`;
+----+-------+
| id | score |
+----+-------+
| 1 | 56 |
| 2 | 91 |
| 3 | 67 |
| 4 | 54 |
| 5 | 56 |
| 6 | 69 |
| 7 | 61 |
| 8 | 83 |
| 9 | 99 |
+----+-------+
9 rows in set (0.00 sec)
【练习12】查询60分以下(不包含60分),60~80分(不包含80分)、80~100分三个成绩段内分别有多少个学生,运行结果如下表所示:
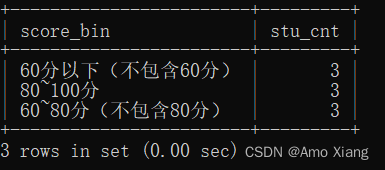
【解析12】现在想知道每个成绩段内的学生数,需要做的第一件事就是对成绩进行分组,利用的是case when,完成成绩分段以后再对分段结果进行group by,接着在组内计数获得每个成绩段内的学生数,参考代码如下:
mysql> SELECT
-> (CASE WHEN score < 60 THEN '60分以下(不包含60分)'
-> WHEN score < 80 THEN '60~80分(不包含80分)'
-> WHEN score <= 100 THEN '80~100分' END
-> ) AS score_bin,
-> COUNT(id) AS stu_cnt
-> FROM subject_table
-> GROUP BY
-> (CASE WHEN score < 60 THEN '60分以下(不包含60分)'
-> WHEN score < 80 THEN '60~80分(不包含80分)'
-> WHEN score <= 100 THEN '80~100分' END
-> );
-- mysql中可以将group by后改写为别名
mysql> SELECT
-> (CASE WHEN score < 60 THEN '60分以下(不包含60分)'
-> WHEN score < 80 THEN '60~80分(不包含80分)'
-> WHEN score <= 100 THEN '80~100分' END
-> ) AS score_bin,
-> COUNT(id) AS stu_cnt
-> FROM subject_table
-> GROUP BY score_bin;
案例10:学生科目表 course_table
现在有一张学生科目表 course_table,这张表存储了id、name(姓名)、grade(年级)和 course(选修课程)四个字段,course_table 如下表所示:
mysql> SELECT * FROM `course_table`;
+----+----------+--------+----------+
| id | name | grade | course |
+----+----------+--------+----------+
| 1 | 王小凤 | 一年级 | 心理学 |
| 2 | 刘诗迪 | 二年级 | 心理学 |
| 3 | 李思雨 | 三年级 | 社会学 |
| 4 | 张文华 | 一年级 | 心理学 |
| 5 | 张青云 | 二年级 | 心理学 |
| 6 | 徐文杰 | 三年级 | 计算机 |
| 7 | 李智瑞 | 一年级 | 心理学 |
| 8 | 徐雨秋 | 二年级 | 计算机 |
| 9 | 孙皓然 | 三年级 | 社会学 |
| 10 | 李春山 | 一年级 | 社会学 |
| 11 | 李易峰 | 一年级 | 会计学 |
| 12 | 张杰 | 一年级 | 会计学 |
| 13 | 何灵 | 一年级 | 管理学 |
| 14 | 蔡徐坤 | 一年级 | 管理学 |
| 15 | 赵丽颖 | 一年级 | 人工智能 |
| 16 | 章子怡 | 一年级 | 人工智能 |
| 17 | 古力娜扎 | 一年级 | 人工智能 |
| 18 | 刘诗诗 | 一年级 | 人工智能 |
| 19 | 迪丽热巴 | 一年级 | 人工智能 |
| 20 | 陈都灵 | 三年级 | 人工智能 |
| 21 | 范冰冰 | 三年级 | 人工智能 |
| 22 | 杨颖 | 三年级 | 人工智能 |
| 23 | 安以轩 | 三年级 | 人工智能 |
| 24 | 刘亦菲 | 三年级 | 管理学 |
| 25 | 关晓彤 | 二年级 | 会计学 |
| 26 | 景田 | 二年级 | 会计学 |
| 27 | 江疏影 | 二年级 | 会计学 |
| 28 | 佟丽娜 | 二年级 | 会计学 |
| 29 | 王楚然 | 二年级 | 会计学 |
| 30 | 柳岩 | 二年级 | 人工智能 |
| 31 | 张钧甯 | 二年级 | 人工智能 |
| 32 | 林允儿 | 二年级 | 人工智能 |
| 33 | 孙怡 | 二年级 | 人工智能 |
| 34 | 窦骁 | 四年级 | 哲学 |
| 35 | 陈伟霆 | 四年级 | 哲学 |
| 36 | 鹿晗 | 四年级 | 哲学 |
| 37 | 黄子韬 | 四年级 | 哲学 |
| 38 | 杨洋 | 四年级 | 哲学 |
| 39 | 易烊千玺 | 四年级 | 哲学 |
| 40 | 肖战 | 四年级 | 哲学 |
| 41 | 周杰伦 | 四年级 | 哲学 |
| 42 | 胡歌 | 四年级 | 哲学 |
| 43 | 陈晓 | 四年级 | 哲学 |
| 44 | 靳东 | 四年级 | 哲学 |
| 45 | 薛之谦 | 四年级 | 哲学 |
| 46 | 任嘉伦 | 四年级 | 哲学 |
+----+----------+--------+----------+
46 rows in set (0.00 sec)
【练习13】筛选最受欢迎的课程,运行结果如下图所示:
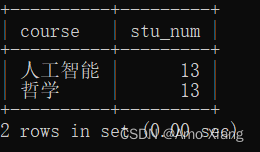
【解析13】需要把选择人数最多的对应的最值算出来,这里利用子查询来生成,最后利用having对分组后的结果进行筛选,从而得到最受欢迎的课程,参考代码如下:
mysql> SELECT course, COUNT(id) AS stu_num FROM course_table GROUP BY course
-> HAVING COUNT(id) = (SELECT MAX(stu_num) FROM (SELECT course, COUNT(id) AS stu_num FROM course_table GROUP BY course) a);
【练习14】筛选出每个年级最受欢迎的三门课程,运行结果如下图所示:
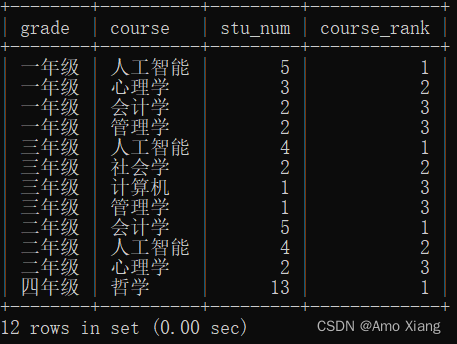
【解析14】典型组内排名问题,对于这个问题可以利用窗口函数来实现,先生成每门课程的报名人数,然后利用rank()函数生成每个年级内每门课程的排序结果,最后通过排序结果筛选出我们所需要的数据,参考代码如下:
mysql> SELECT * FROM (SELECT *,RANK() OVER(PARTITION BY grade ORDER BY a.stu_num DESC) AS course_rank FROM
-> (SELECT grade,course,COUNT(id) AS stu_num FROM course_table GROUP BY grade,course) a) AS b WHERE b.course_rank<4;
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结